词法分析程序功能:根据输入的字符串,按照种别码分类识别出对应的单词符号;
符号与种别码对照表
|
单词符号 |
种别码 |
单词符号 |
种别码 |
|
begin |
1 |
: |
17 |
|
if |
2 |
:= |
18 |
|
then |
3 |
< |
20 |
|
while |
4 |
<= |
21 |
|
do |
5 |
<> |
22 |
|
end |
6 |
> |
23 |
|
l(l|d)* |
10 |
>= |
24 |
|
dd* |
11 |
= |
25 |
|
+ |
13 |
; |
26 |
|
- |
14 |
( |
27 |
|
* |
15 |
) |
28 |
|
/ |
16 |
# |
0 |
用文法描述词法规则
<字母>:S→a|b|c|…|X|Y|Z
<数字>:S→0|1|2|…|9
<整数常数>:B→0|1|2|...|9
S→B|SB
<标识符>: A→B|AB|AS
B→a|b|c|…|X|Y|Z|_
S→0|1|2|...|9
<关键字>: S→const|var|procedure|begin|end|odd|if|then|call|while|do|read|write
<运算符>: S→+|-|*|/|=|#|<|<=|>|>=|!=
<界符>: S→(|)|,|;|.
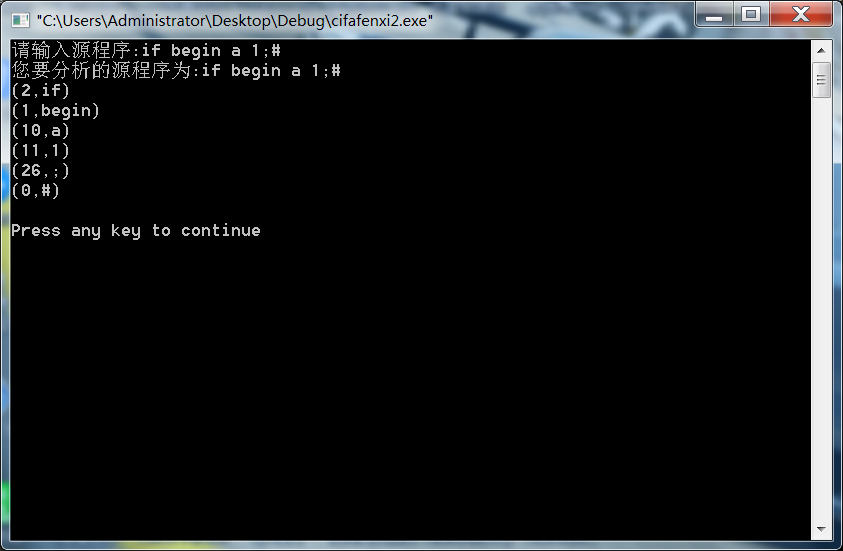
运行代码及截图
#include<stdio.h> #include<string.h> void Fenxi(char c,char b); void word(char a[]); void number(char a[]); int i; int s=1; main(){ char a[50]; printf("请输入源程序:"); gets(a); printf("您要分析的源程序为:"); printf("%s",a); printf(" "); for(i=0;(a[i]!='�')&&(i<50)&&s==1;i++) { if((a[i]>='a' && a[i]<='z')||(a[i]>='A' && a[i]<='Z')) word(a); else if(a[i]>='0' && a[i]<='9') number(a); else Fenxi(a[i],a[i+1]); } printf(" "); } void number(char a[]) { char b[50]; int m,k=0,t; m=i; while(a[m]>='0' && a[m]<='9') { b[k]=a[m]; k++; m++; } i=m-1; printf("(11,"); for(t=0;t<k;t++) printf("%c",b[t]); printf(")"); printf(" "); } void word(char a[]) { int k=0,m,flag=0,t; char b[50]; char *key[6]={"begin","if","then","while","do","end"}; m=i; while((a[m]>='a'&&a[m]<='z')||(a[m]>='A'&&a[m]<='Z')) { b[k]=a[m]; k++; m++; b[k]='�'; } i=m-1; for(t=0;t<6;t++) { if(strcmp(b,key[t])==0) { printf("(%d,%s)",t+1,key[t]); flag=1; printf(" "); } } if(flag==0) { printf("(10,%s)",b); printf(" "); } } void Fenxi(char c,char b) { switch(c){ case ' ': break; case '+': printf("(13,+) "); break; case '-': printf("(14,-) "); break; case '*': printf("(15,*) "); break; case '/': printf("(16,/) "); break; case ':': if(b=='=') { i++; printf("(18,:=) "); } else printf("(17,:) "); break; case '<': if(b=='>') { i++; printf("(21,<>) "); } else if(b=='=') { i++; printf("(22,<=) "); } else printf("(20,<) "); break; case '>': if(b=='=') { printf("(24,>=) "); i++; } else printf("(23,>) "); break; case '=': printf("(25,=) "); break; case ';': printf("(26,;) "); break; case '(': printf("(27,() "); break; case ')': printf("(28,)) "); break; case '#': printf("(0,#) "); break; default: { printf(" 存在字符 '%c',无法继续识别! ",c); s=0; break; } } }