在StandardForLoop函数中,我们利用标准的for循环,遍历了employeeData中的每一个数据,并对数据进行了处理。普通的for循环是串行的,只能运行在CPU的一个运算核心上,如果这段程序运行在多核CPU上,在程序执行for循环的时候,你会发现CPU只有一个运算核心在工作,其他基本上都处于空闲状态。这是对宝贵的CPU资源的极大浪费。
面对这种简单独立的for循环,我们可以利用TPL提供的Parallel.For将其并行化,以充分利用多核CPU的运算能力。我们利用Parallel.For将上面的普通for循环改写如下:
// 添加相应的名字空间
using System.Threading;
//…
// 并行的for循环
private static void ParallelForMethod()
{
Start("ParallelForMethod");
// 并行的for循环
Parallel.For(0, employeeData.Count, i =>
{
Console.WriteLine("Starting process for employee id {0}",
employeeData[i].EmployeeID);
decimal span = Employee.Process(employeeData[i]);
Console.WriteLine("Completed process for employee id {0}",
employeeData[i].EmployeeID);
Console.WriteLine();
});
End("ParallelForMethod");
}
为了使用Parallel类,我们首先需要声明System.Threading名字空间,Parallel类就在这个名字空间中。Parallel.For实际上是Parallel类提供的一个静态方法,它的第3个参数是类型为Action的委托,在这段代码中,我们直接使用Lambda表达式来将一个匿名函数直接“内联”作为Parallel.For方法的参数。从上面的代码我们也可以看出,将一个普通的串行的for循环改造为一个并行的for循环非常的容易,只要按照相应的规则调用Parallel.For函数就可以了,而运行时中的任务调度器会自己去进行任务的调度,硬件的分配等复杂而繁琐的事情,开发者则坐享其成。
通过使用Parallel.For对程序进行改写,可以充分利用多核CPU的运算能力,让应用程序的性能有大幅度的提升。在我的双核CPU上测试的结果是,程序性能有将近两倍的提升。

图1,Parallel.For所带来的性能提升
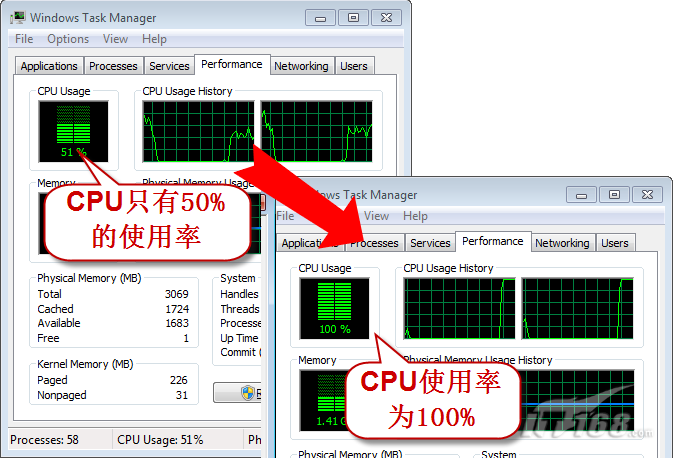
图2,充分利用CPU的计算能力
在Parallel.For中访问共享变量
使用Parallel.For需要注意的是,Parallel.For循环中的循环次序是乱的,并不像标准的for循环那样按照从小到大或者从大到小的顺序执行。从上面的截图中我们也可以发现,Parallel.For所处理的Emplee的ID是混乱的,并不像标准for循环那样从0到20的顺序处理。这一点我们在使用Parallel.For循环的时候要特别注意,如果你的循环对次序有要求,上一次循环是下一次循环的输入,或者是每次循环之间有相同的数据要处理,那么就不能简单地使用Parallel.For循环来并行化程序,需要做一些特殊的处理。比如,我们要统计某一个数据范围内的所有素数的个数,利用串行算法,我们可以实现如下:
// 判断某一个数是否是素数 static bool IsPrime(int valueToTest) { int upperBound = (int)Math.Sqrt(valueToTest); for (int i = 2; i <= upperBound; i++) { if (valueToTest % i == 0) return false; } return true; } // 获取素数的数量 private static void GetPrimeCount() { // 定义范围 const int UPPER_BOUND = 4000000; while (true) { int totalPrimes = 0; var sw = System.Diagnostics.Stopwatch.StartNew(); for (int i = 2; i < UPPER_BOUND; i++) { if (IsPrime(i)) totalPrimes++; } // 输出耗时 Console.WriteLine("Sequential: {0} found in {1}", totalPrimes, sw.Elapsed); Console.ReadLine(); } }
根据我们前面的示例代码,以上的并行化代码是不是看起来都很正确呢?当我们编译执行这个应用程序的时候,才会发现结果不对。这是因为程序并行化之后,多个执行单元访问同一个共享变量,当其中某一个执行单元在修改这个共享变量时,如果这时另外一个执行单元也恰好想访问这个变量,第二个执行单元的访问就会失败。针对这种情况,我们需要使用Interlocked类(或者其他的类)的函数来访问相应的共享变量,修改共享变量的值,就不会有这个问题了。我们将算法修改如下:
Parallel.For(2, UPPER_BOUND, i => { // 正确的共享变量访问方式 if (IsPrime(i)) Interlocked.Increment(ref totalPrimes); });
经过这样的修改,我们就可以得到正确的计算结果了。