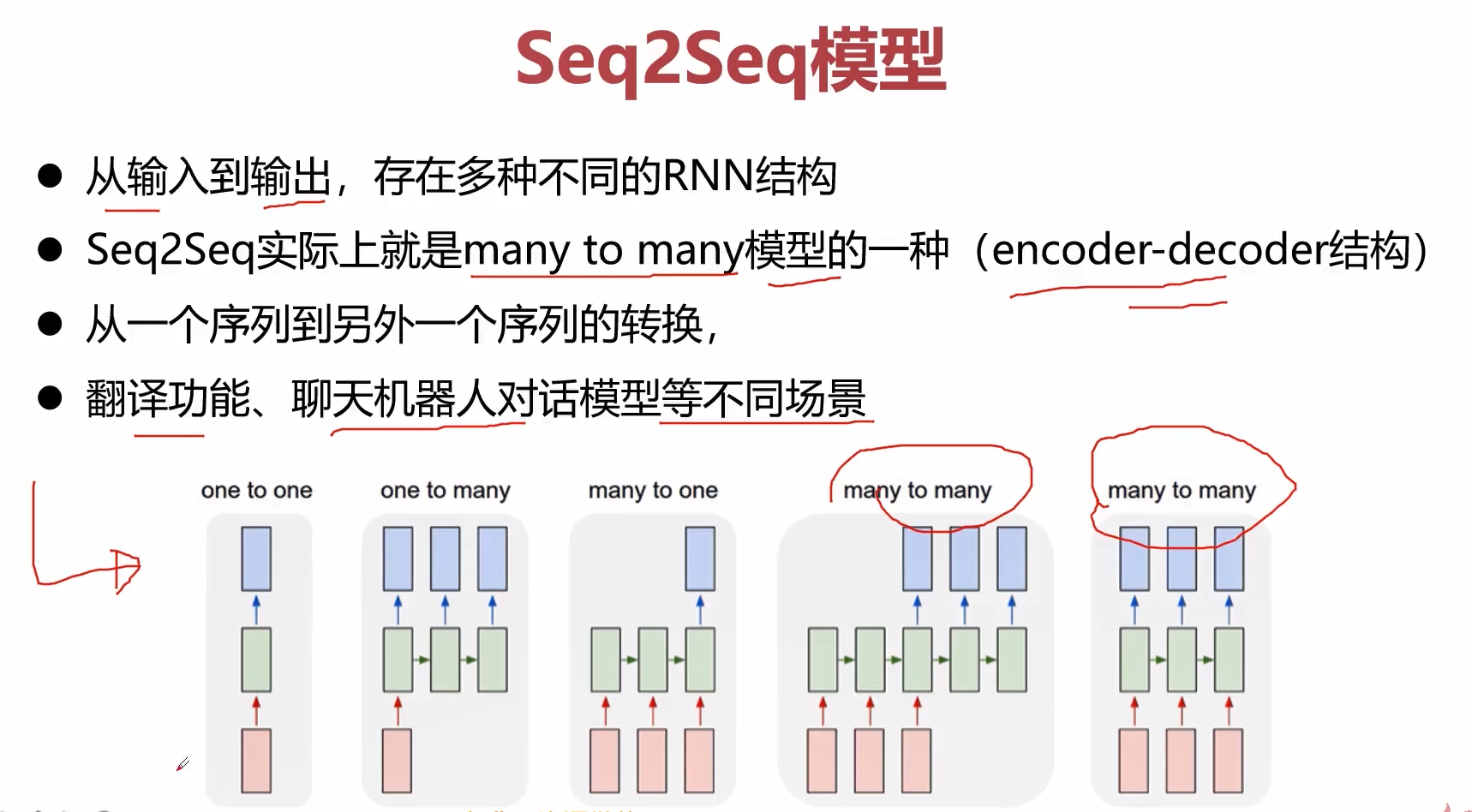
使用注意力机制的seq2seq
attention机制是在RNN中经常被使用到的一个机制。

对于attention这样一个机制,为什么会出现呢?主要就是我们采用传统的encoder-decoder来搭建RNN模型的时候,通常会存在一些问题。
问题一:无论输入的序列有多长,都会被编码成一个固定的向量表示,那么必然会损失非常多的信息。
问题二:当输入的序列比较长,模型的性能会很差。

如何解决呢?那就需要引入attention的机制。
通过attention机制来对输入的信息进行选择性的学习,建立序列之间的联系,也就是我们在输入层和输出层这两个序列中,去计算元素和元素之间的相关性,这个相关性就是attention。
序列和序列之间的attention,非常成功的一个架构就是seq2seq+attention。
上面的示意图,就是先见过encoder进行编码,然后在给到decoder进行解码。
加入attention在seq2seq结构中,就是在decoder中加入attention的单元,这个attention单元描述了当前节点和输入层节点的关系,也即是所谓权值。(c_1)描述了当前这个节点和(x_1,x_2,x_3,x_4)的相关性,(c_2)描述了当前这个节点和(x_1,x_2,x_3,x_4)的相关性,这样我们就可以利用attention机制对输入信息进行有选择性的学习,这也是非常符合人类认知客观世界,来理解客观世界的这样一个规律。
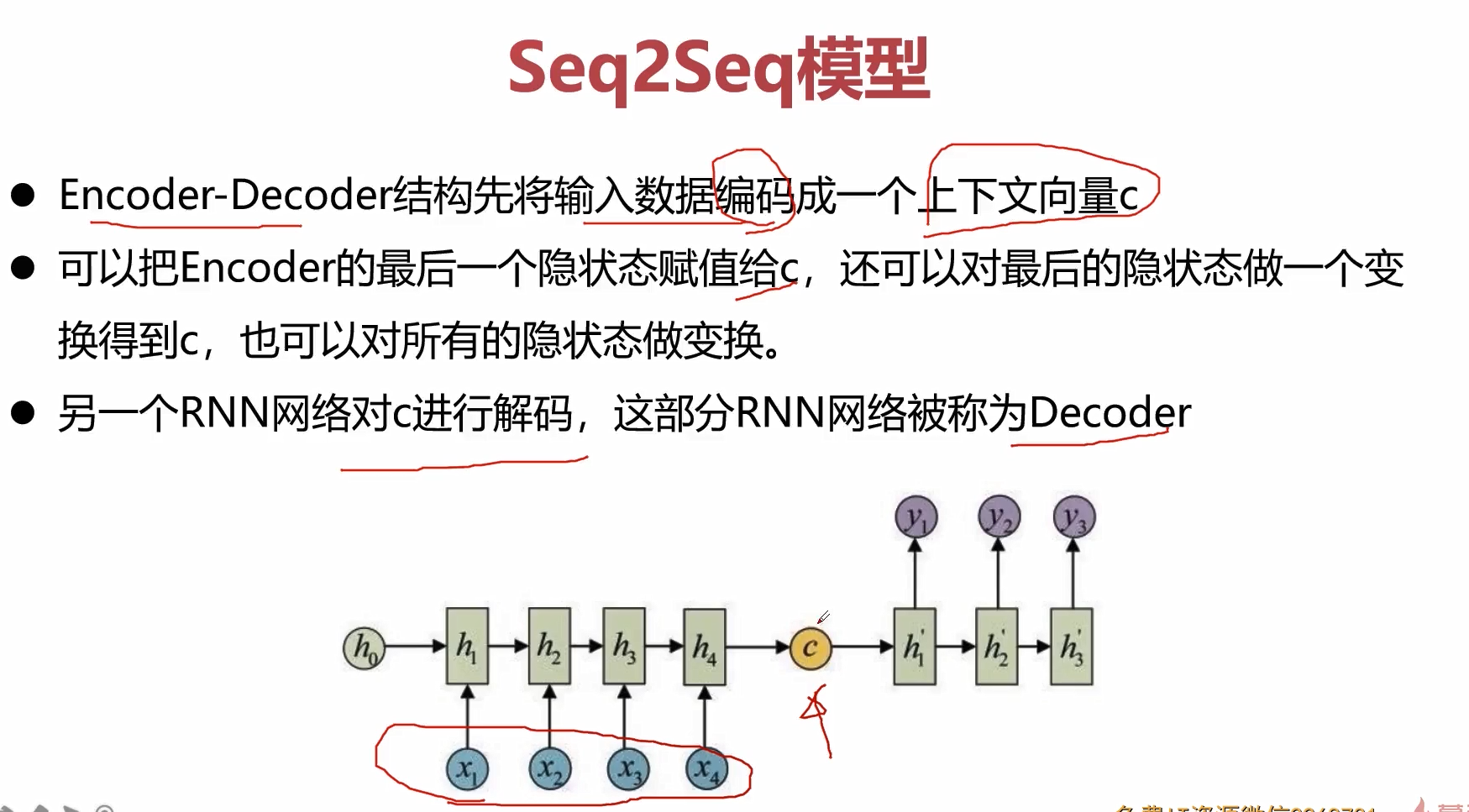
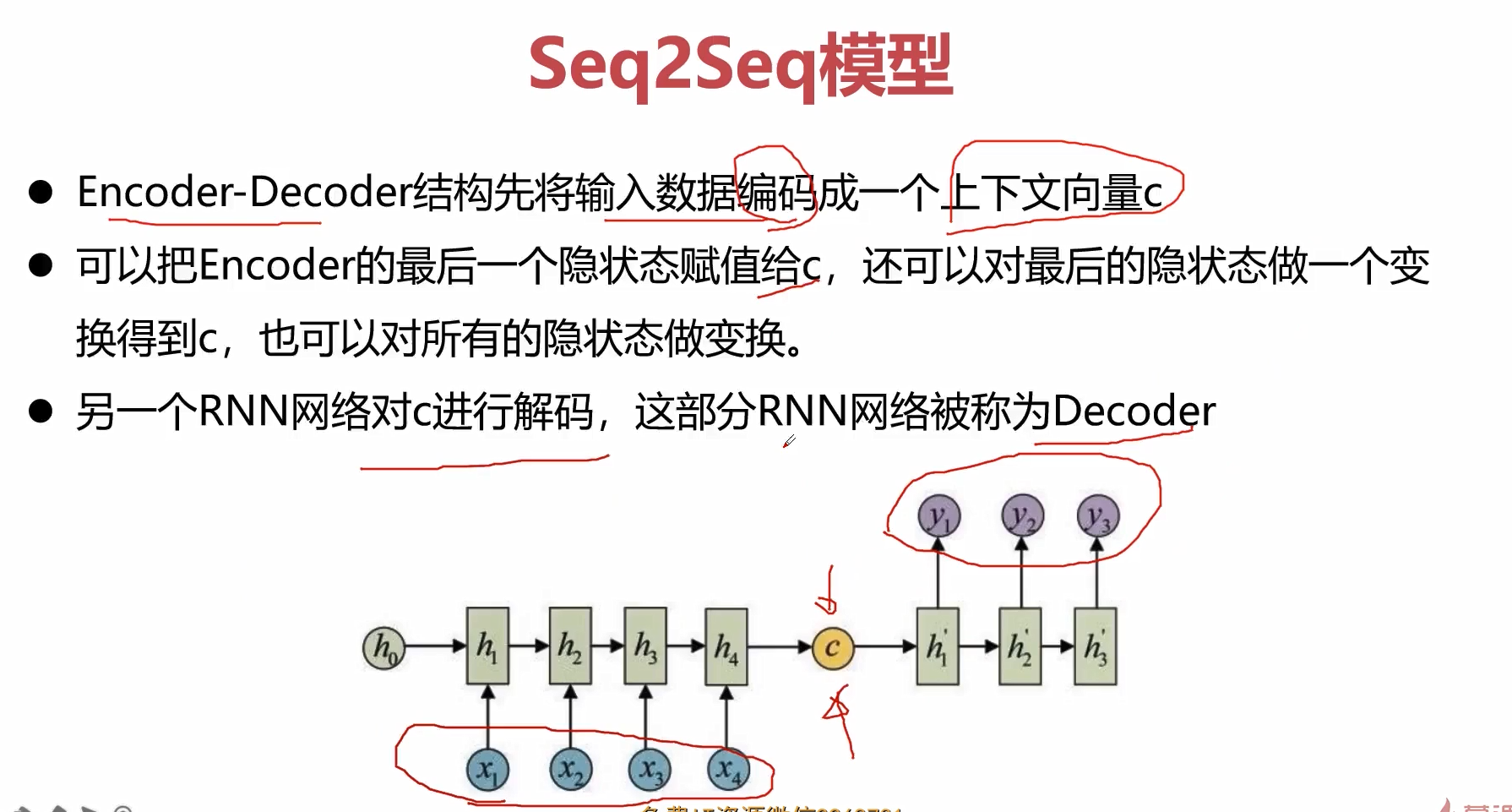
原始的encoder将所有的信息都压缩到一个隐藏状态c中,这样会损失非常多的信息。
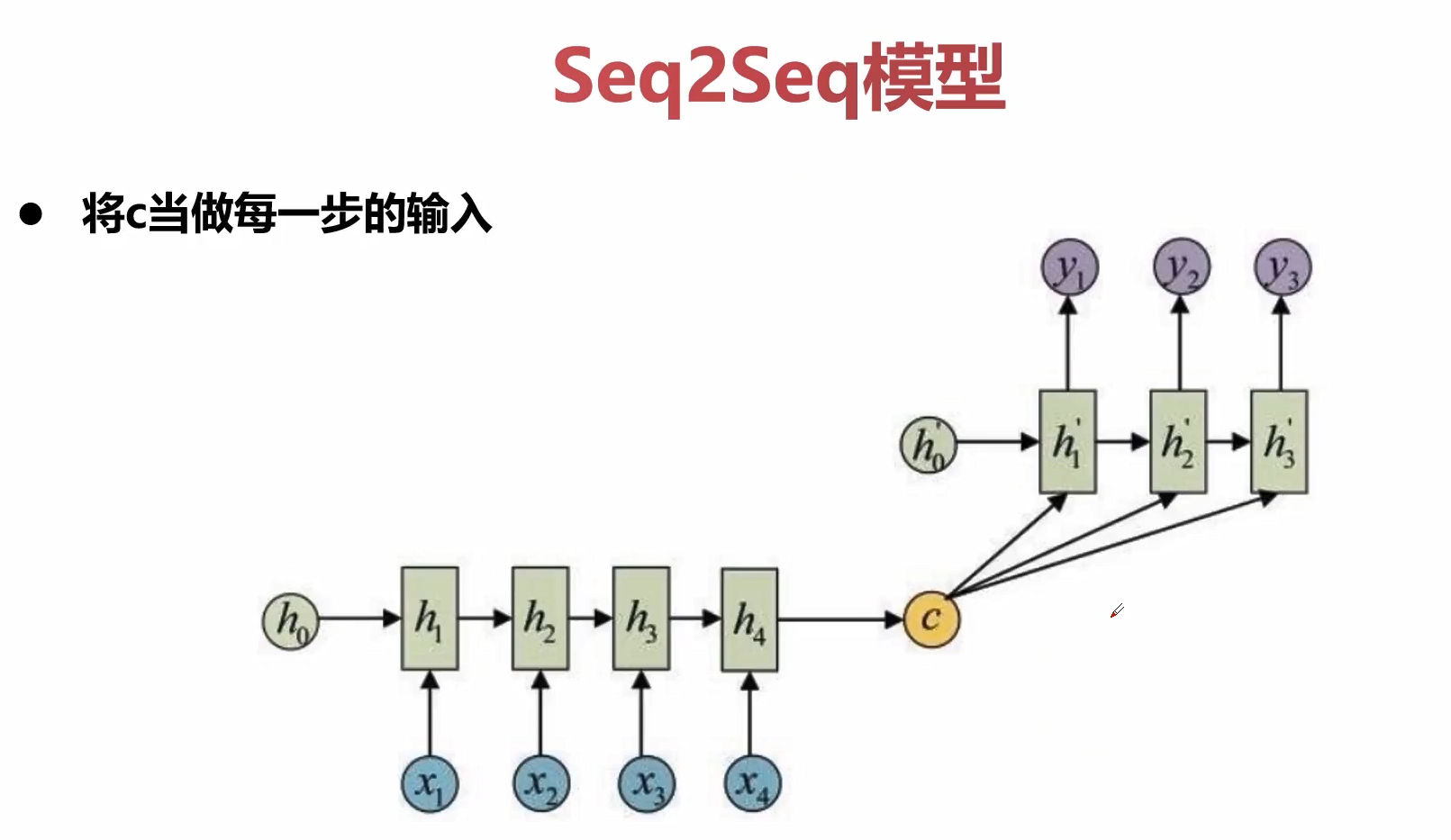
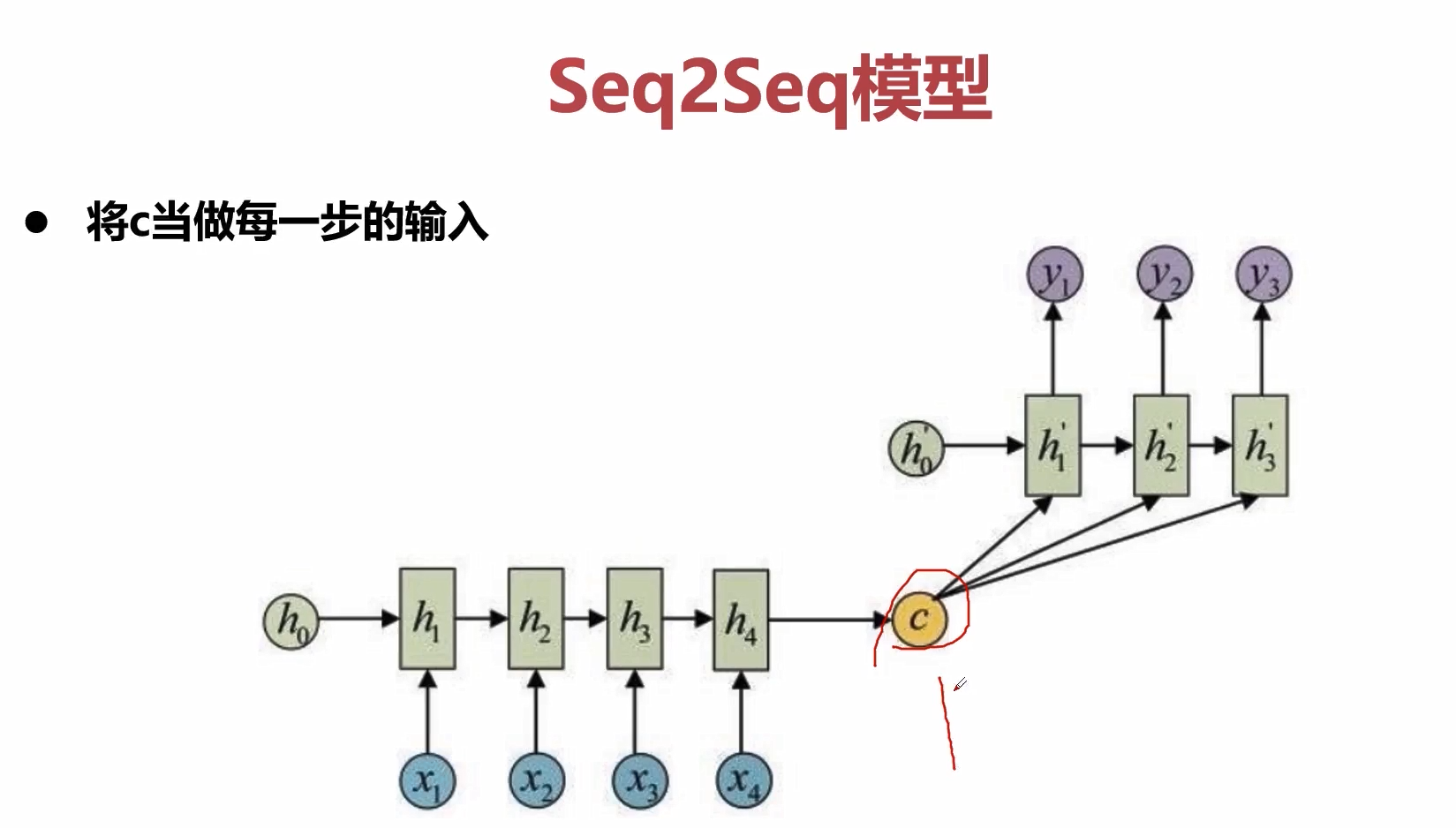
一种解决方法就是可以把c在decoder的时候作为每一步的输入。但是我们在编码的时候依然只是编码出一个c。
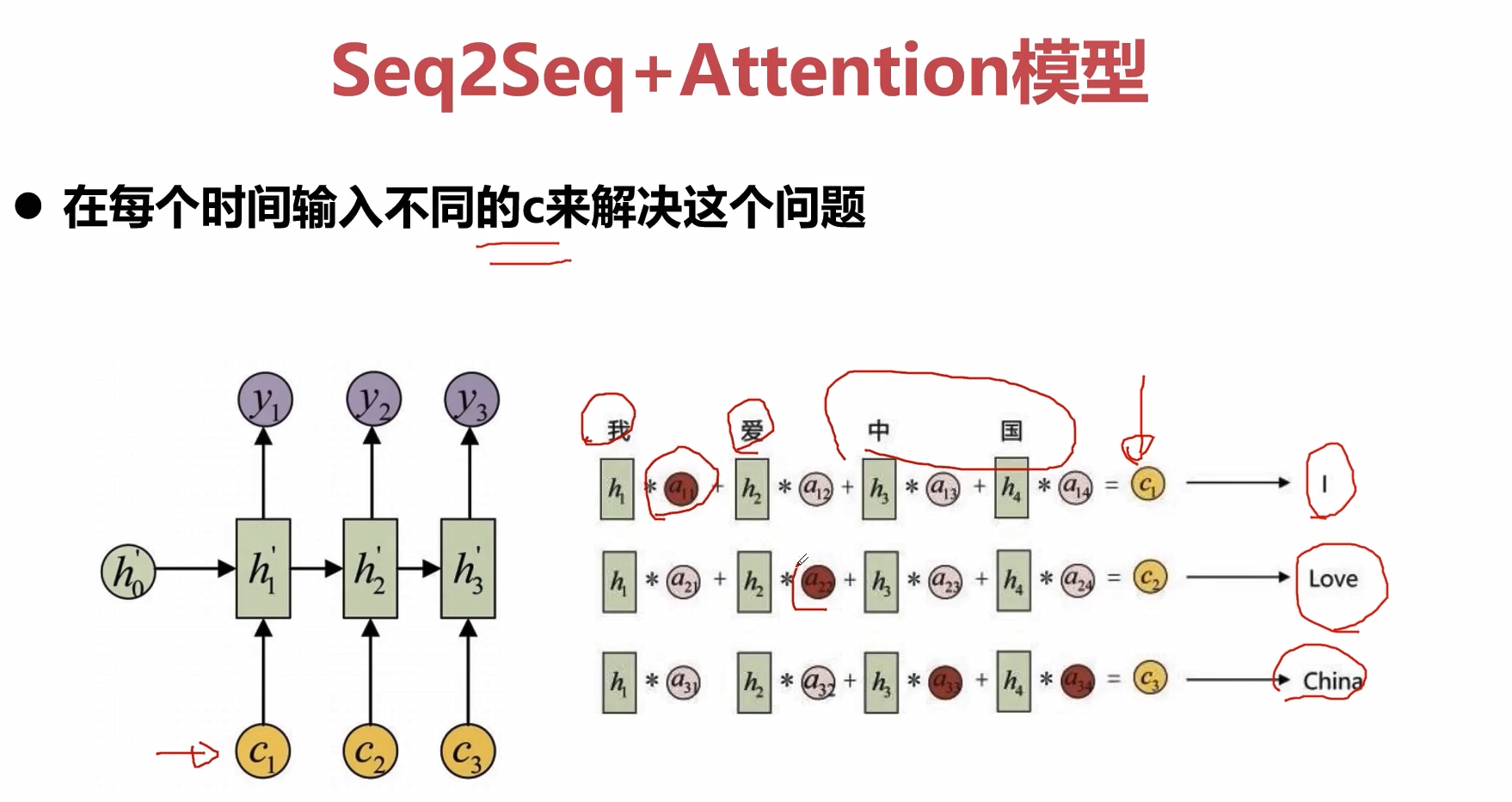
解决方法可以考虑不用的时刻来定义不同的c,达到一个attention的效果。
非常典型的例子就是上图所展示的例子,输入序列“我爱中国”,输出序列“I lov China”。 其中“I”和“我”输出的相关性就非常高,“爱”和“love”的相关性是比较高的,“中国”和“China”的相关性是高的。基于此,我们去定义不同时间片上的不同权重,

seq2seq+attention基本就是业界的baseline的方法。

注意力在NLP中的应用,这个也是最早的工作之一。
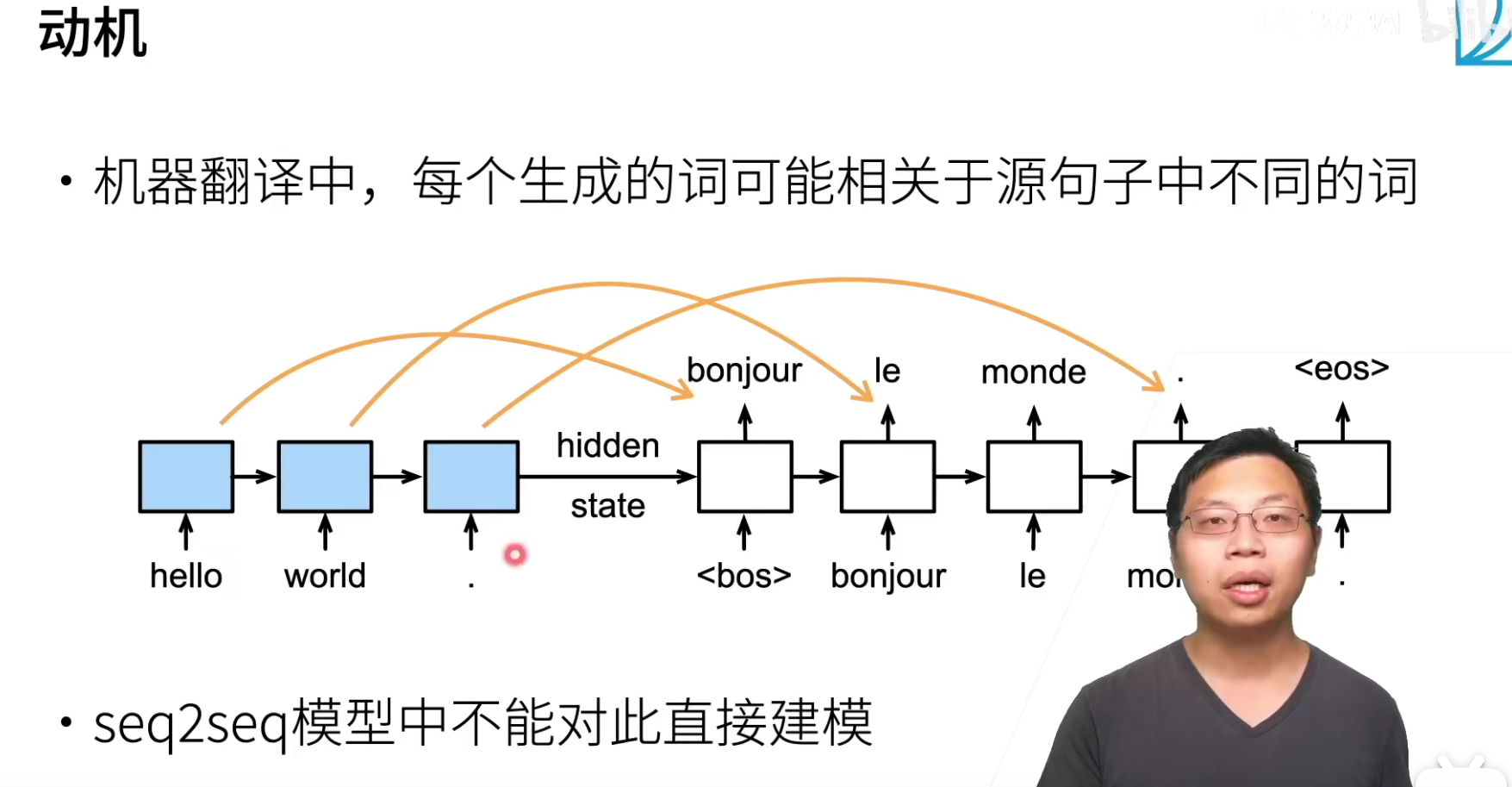
seq2seq是只讲最后一个状态传递了出去,无法实现翻译的时候将注意力关注原来句子中的对应位置。
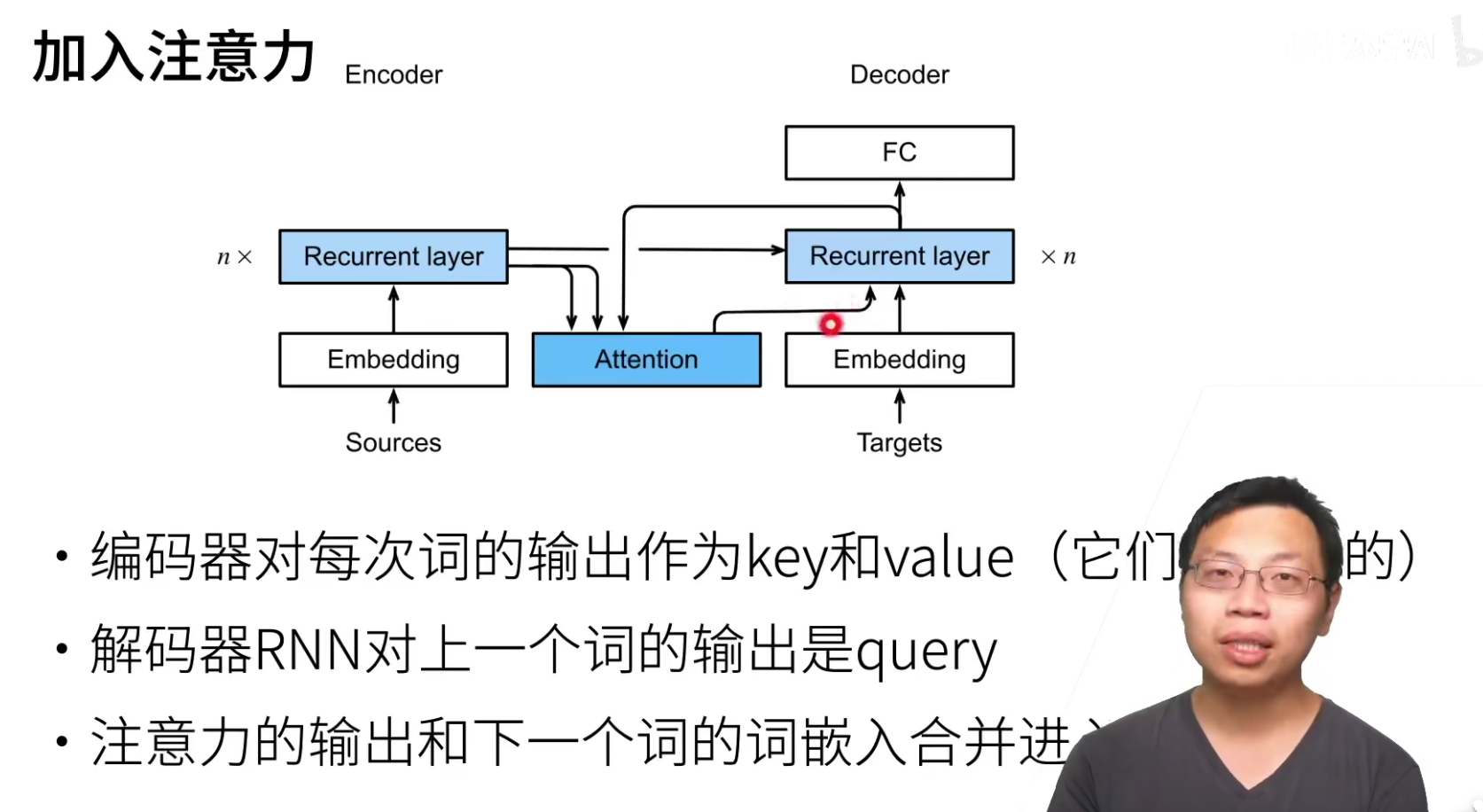
attention在这里怎么操作呢?就是将encoder对应每个词的输出作为key-value,就是如果英语句子长度为3,那么就会有3个key-value pair,也就是第i个词RNN的输出。
query是decoder对上一个词的预测作为query。

代码
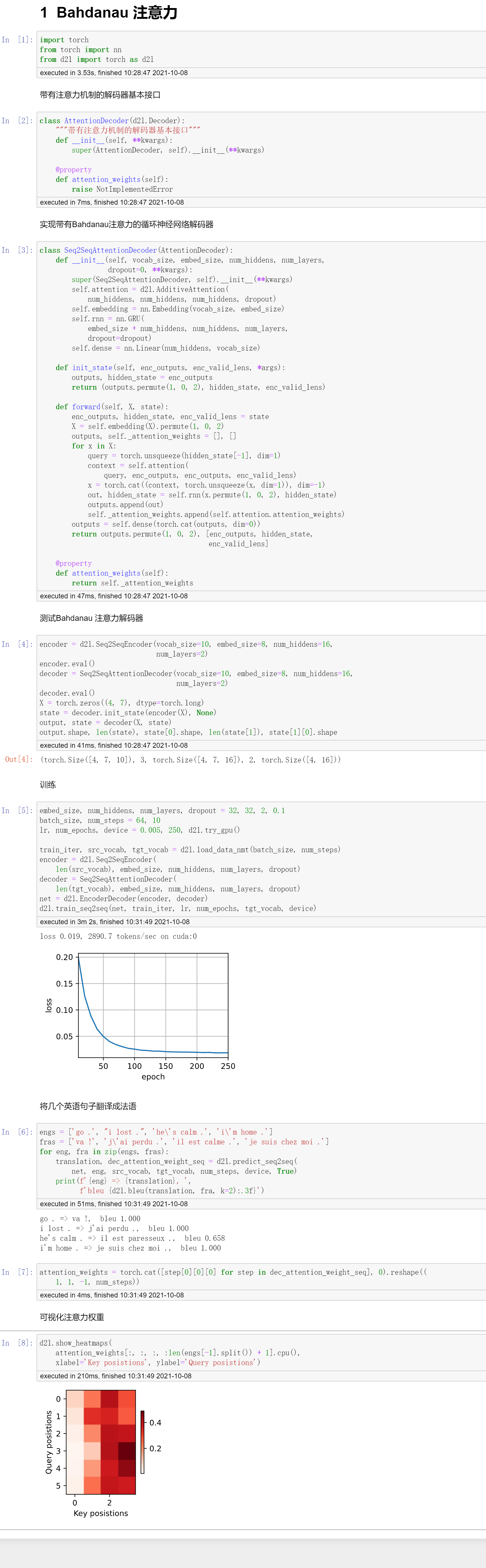
QA
- query是decoder的输出,那第一次query是怎么得来的?
encoder的最后一个时间步的最上层隐藏层的输出作为deocder第一次的query。
- 一般都是在decoder加入注意力吗?不可以在encoder加入吗?
当然可以。
seq2seq是在decoder加入attention的。
bert是在encoder加入attention的。
- 能大概说一下图像attention吗?
沐神:其实我没有打算讲图像attention,
图像attention是self-attention,可以认为图像里面要抽取很多词出来,就是怎么把一个图片变成一些序列或者一些key-value pair呢?就是从图片中扣很多子图出来,一个子图就是一个key-value。
卷积经典的注意力结构
这里描述CNN中attention的这样一个概念,attention概念在RNN中使用的会比较多一些,但在CNN中,attention的概念同样有着非常重要的作用。
在介绍具体的网络之前,我们先来看attention的机制。

attention机制是非常容易的理解的,就是在给定一个全局区域的时候,人的注意力会聚焦或重点关注在一些特殊的目标区域,而这些焦点,这些关注的区域就是attention区域。
比如上图,画出来的深色区域就是我们会重点关注的区域。
使用注意力机制的思想应用在神经网络的设计中,就是attention的结构。
那么如何来表示我们重点关注的这些区域呢?=》实际就是对这些区域进行加权。
我们对不同的区域,予以不同的权重,这种想法就是对attention机制在CNN中的实现的一种重要手段。那么具体如何对区域进行加权呢?这就分为了:
- one-hot分布 & hard-attention
- soft的软分布 & soft-attention
hard-attention就是0,1的离散值,1就表示是attention的重要区域,否则就不是。而soft-attention则是使用了实数[0,1]来表示注意力的权重范围。
当然attention我们不要只关注与怎么看图像,还可以进行延展,就是对信息进行局部加权操作。可以是特征图,可以使尺度空间,可以是channel尺度,可以是不同的历史特征(LSTM、RNN、GRU)。
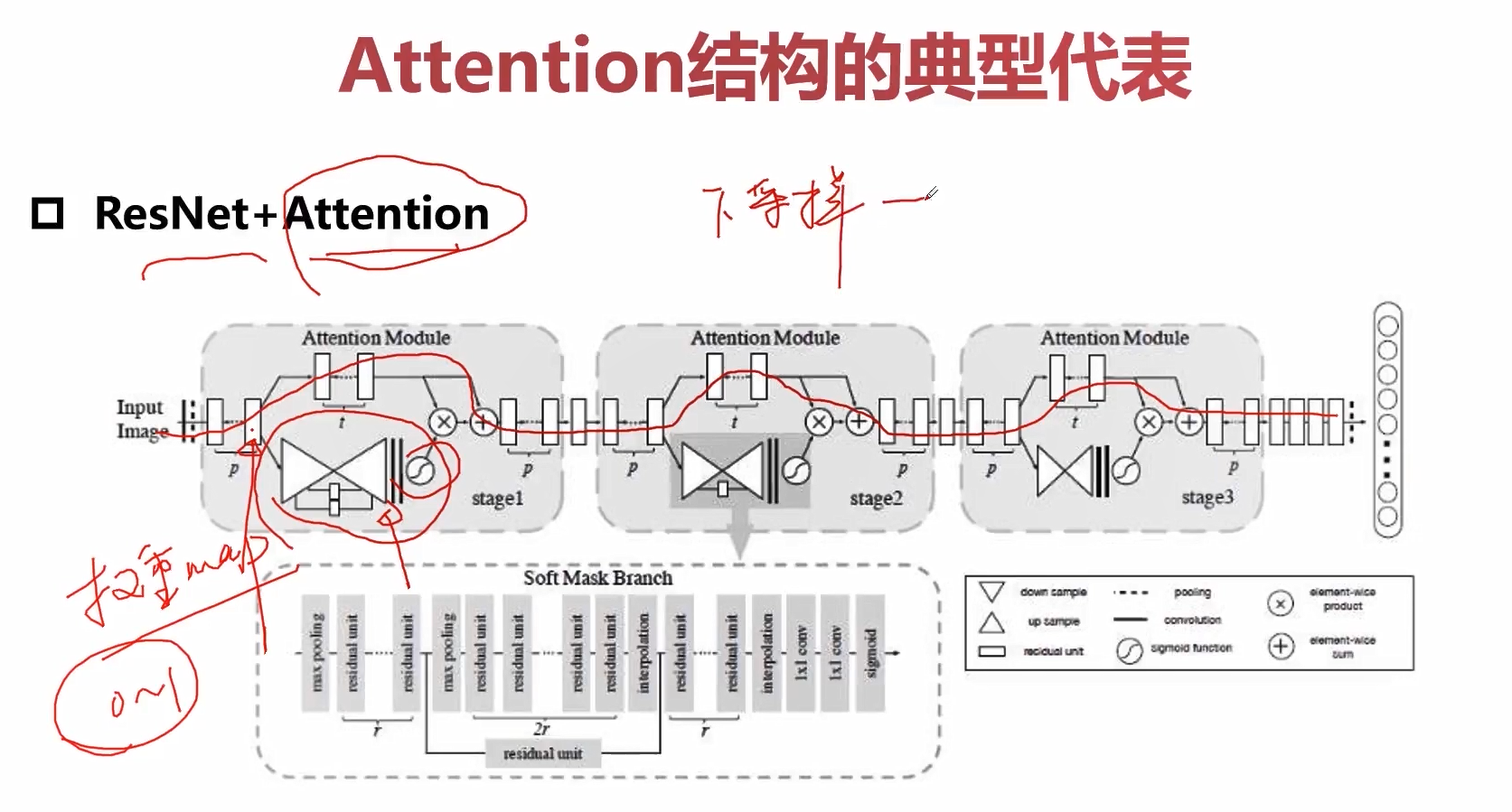
我们可以在feature_map上做attention,比如我们对ResNet+attention的结构进行一个改造。
示意图的上半部分就是标准的ResNet网络,然后我们将attention的结构添加其子模块中。我们在输入的某个feature map上进行分叉,其中上半段的feature map我们继续进行卷积操作,而下部分的feature map,首先先进行下采样,然后再进行上采样,这样我们可以拿到一个相同尺度相同大小的一个权重图,然后通过一个sigmoid函数将这个权重图归一化的[0,1],然后权重图的[0,1]就对应了feature map上的每一个权重,然后再进行乘加操作,实现了在特征图上进行加权的这样一种操作。
这里的attention操作是通过一个下采样+上采样来完成。
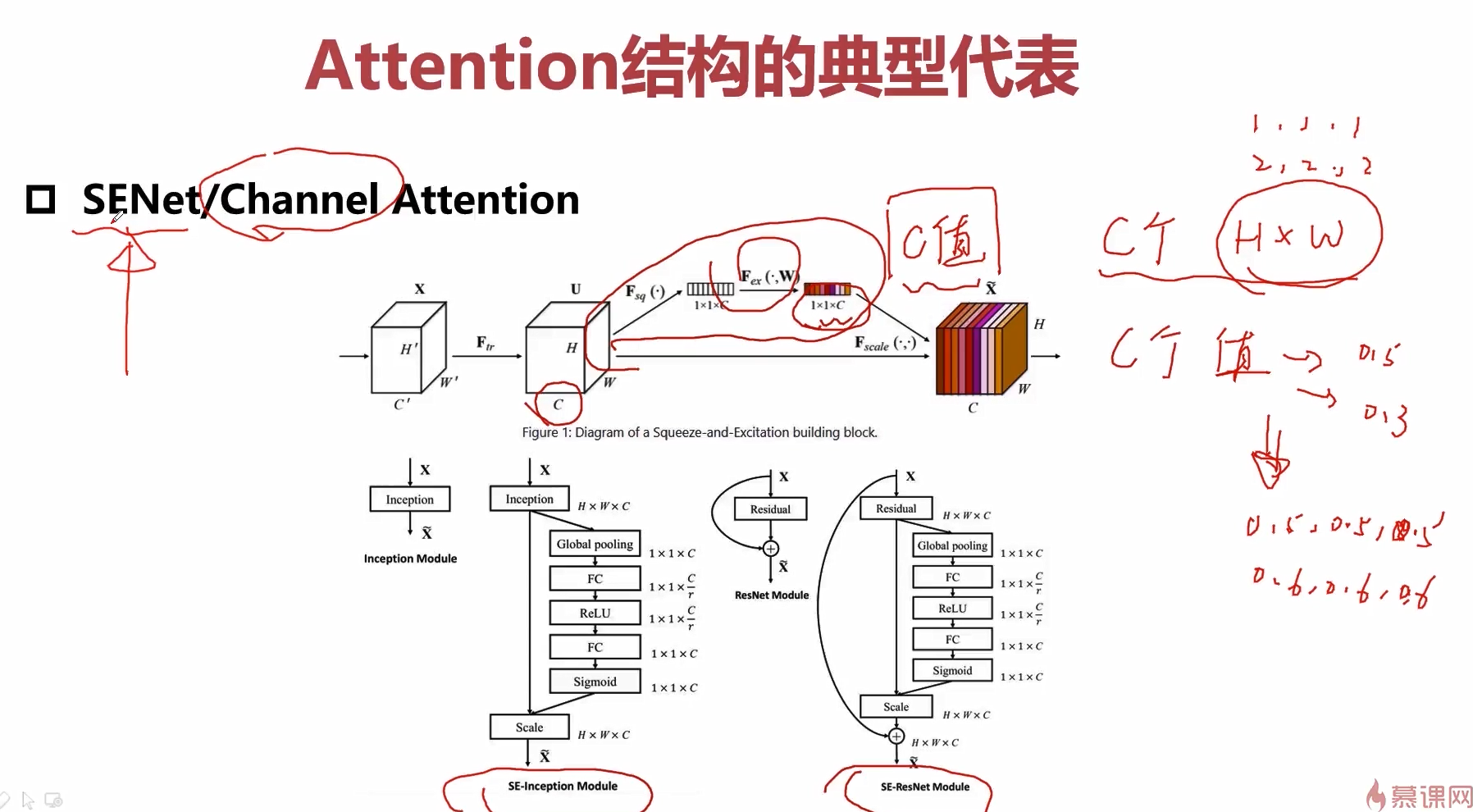
还可以将attention作用在channel上。
比如这里实现加权的方式就是学习一个(1*1*c)的向量,这里的c就是channel的数量。