从全连接到卷积
卷积是深度学习中最重要的概念之一,今天就学习下卷积的基本知识。

36M*100=3.6B。
使用MLP来处理图片会遇到权重参数过多的问题。
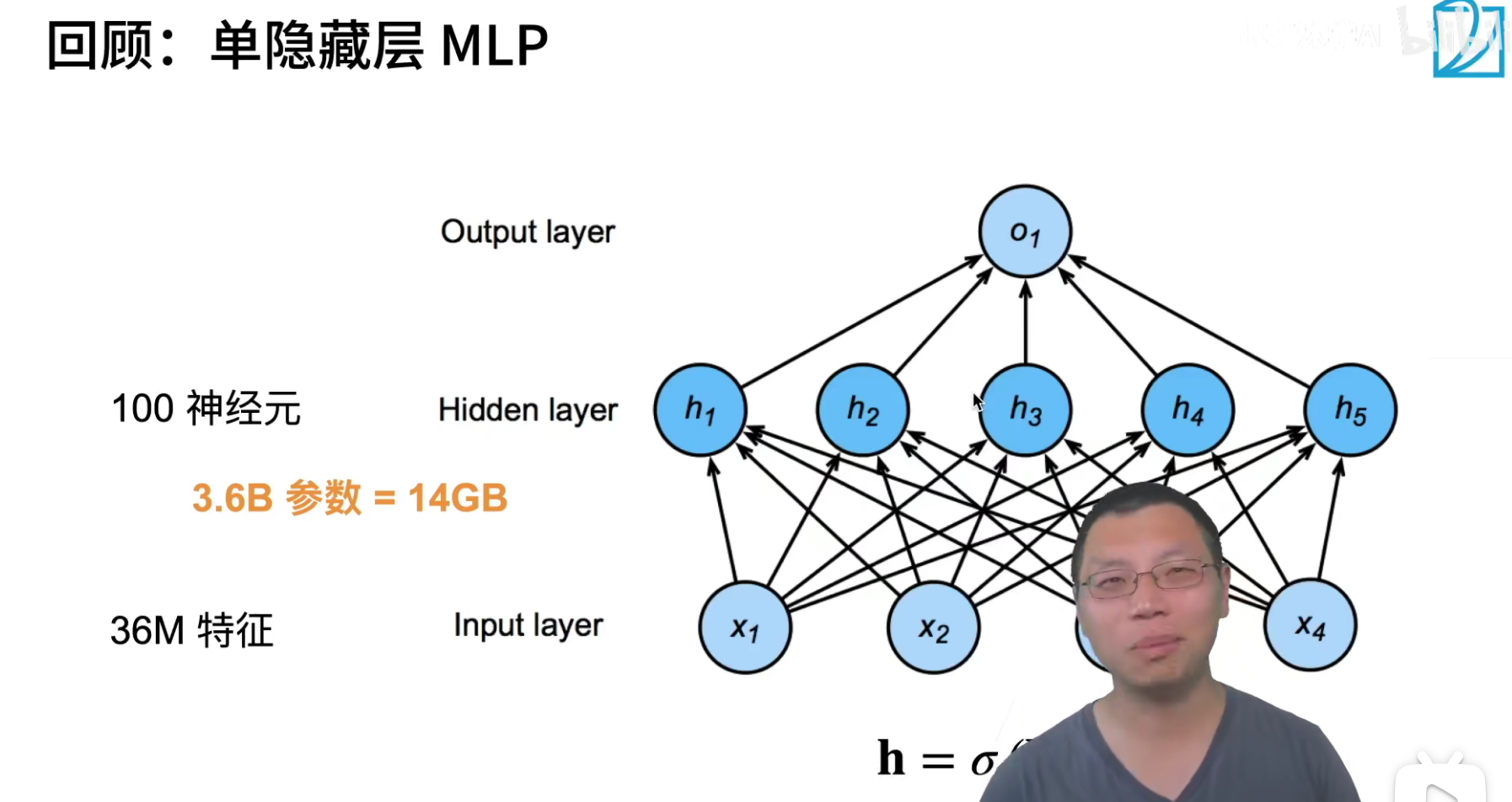
就是100个单元的单隐层,这里的权重都需要 3.6*1e9 * 4 / 1024 / 1024 / 1024 = 13.4GB的内存,这就需要很好的GPU才可以存储的下来,现在还没有涉及运算,这肯定是不对的。


对图片中的信息查找有两个原则:
- 平移不变形
对于图片中的方框,不管是在图片中的哪个位置,都应该要能够被识别出来,不能因为方框出现的像素位置不同而改变。
- 局部性
就是要找到方框中的内容,其实不用看的太远,只需要看到局部的信息,不需要看到全局的信息。
这两个在图片中找模式的原则,可以启发我们之后的整个设计。

我现在来看,怎么从MLP出发,利用上述两个原则,得到卷积。所以也可以说卷积是一个特殊的全连接层。
如果图片要输入MLP,那么我们会将其重置成一维,这样会丢失空间信息。这里输入是以矩阵的形式输入(为了保留空间信息)

(看不懂公式推导)这里其实权值共享。
一张图片会有多个卷积核,然后这些卷积核就是这张图片共用的(不会因为位置的改变而改变卷积核中的参数),卷积核的权值共享就保证了平移不变形。

局部性就是,这个点的话,我不会看的太远,一般都是选小卷积核。

对全连接层使用平移不变性和局部性得到卷积层。
卷积层

刚才我们讲的是卷积这个操作子,我们现在讲讲卷积层是个什么东西。

下面是卷积操作的动图,Kernel的Weight是不会发生改变的。
卷积操作(也叫做交叉相关运算):kernel的对应元素相乘再sum()。
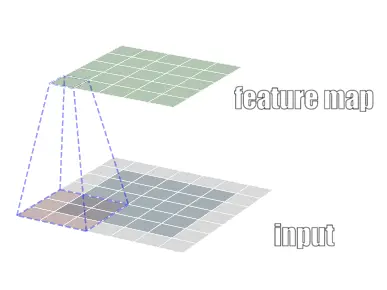

经过卷积操作之后,输出会变小,其实也可以认为是进行了一次特征的提取。
(Y_{shape}=(n_h-k_h+1) imes (n_w-k_w+1)),

我们可以看到,不同卷积核的weight可以带来不同的效果(这里是有关数字图像处理的内容)

交叉相关和卷积其实是没有太多区别的,实际使用中没有区别。
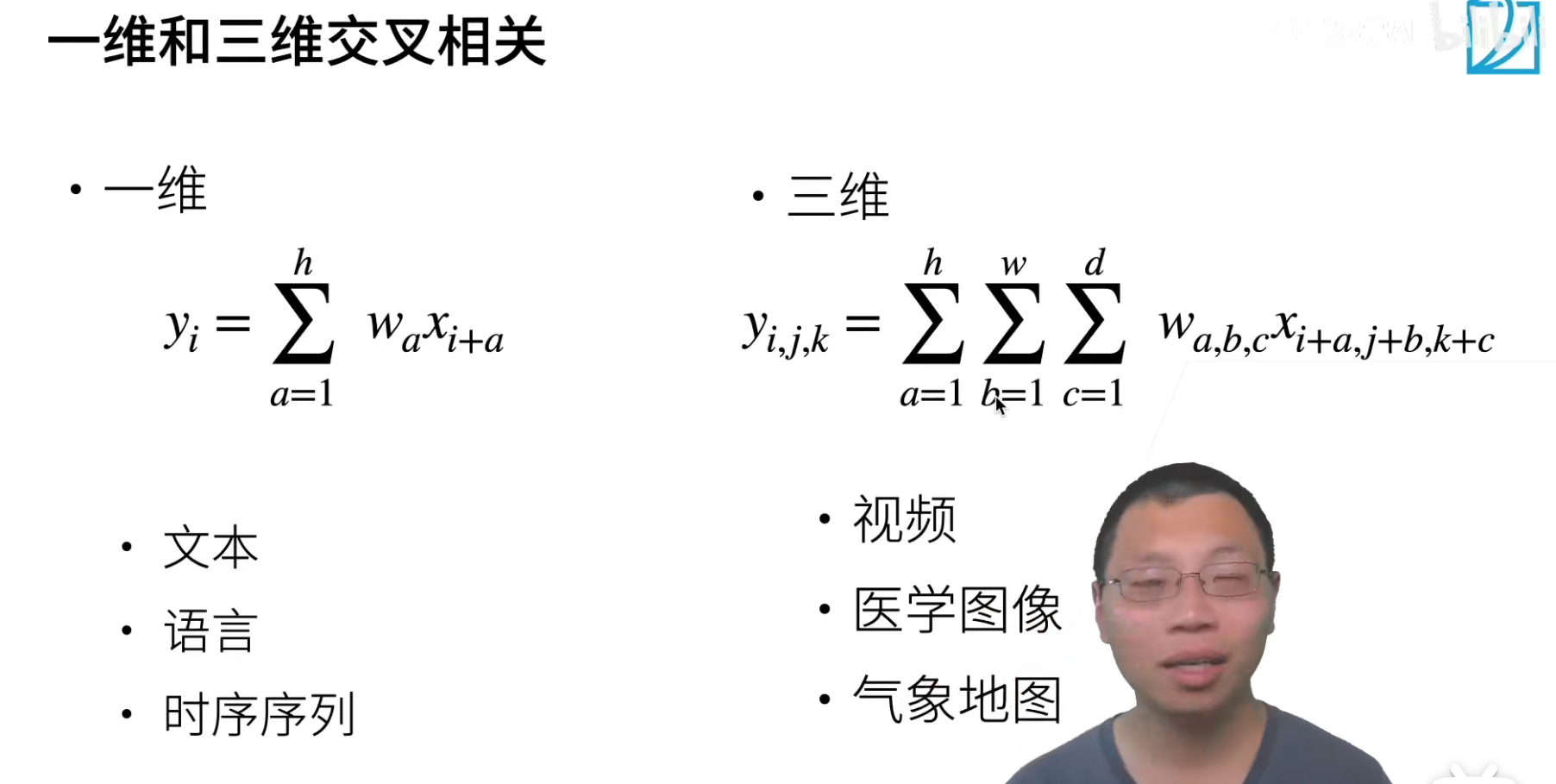
- 一维卷积 conv-1d
我们之后会讲用CNN来做文本,效果其实也挺好的。文本也好,语言也好,都是一个一维的向量。
- 二维卷积 conv-2d
像图片就是一个二维的卷积。
- 三维卷积 conv-3d
像视频(图像+时间),医学图像,气象地图

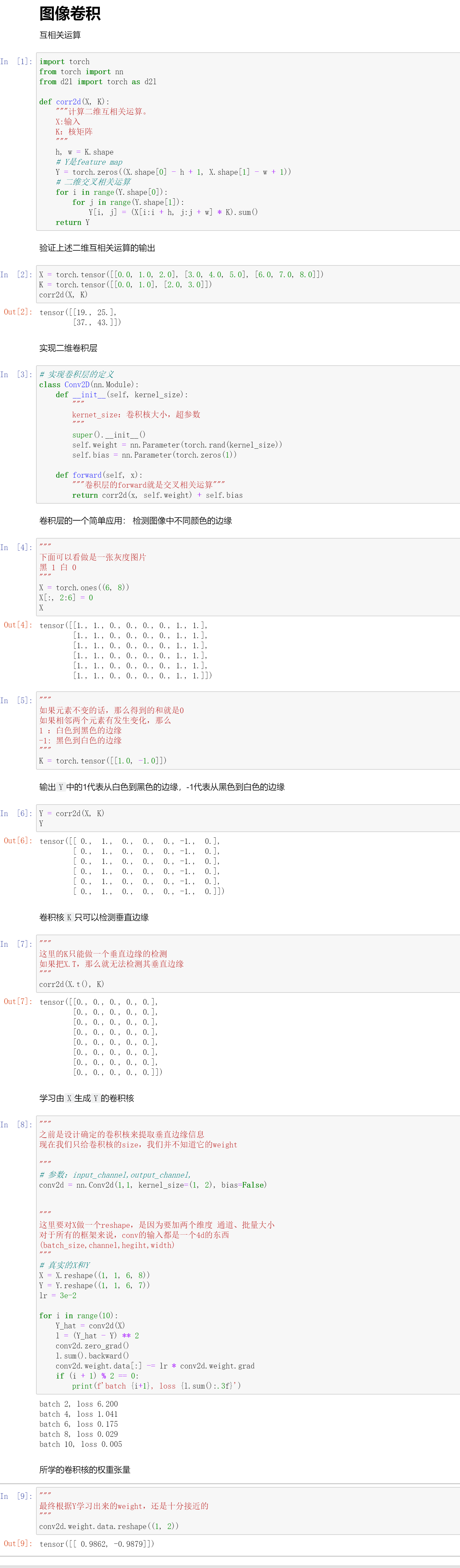
代码
QA
- 不应该看那么远?感受野不是越大越好吗?
其实这个问题和“为什么宽一点,浅一点的MLP效果没有窄一点,然后深一点的MLP效果好”,其实对于卷积神经网也是一样的。
而且有理论根据,小卷积核是可以等价替换大卷积核的感受野的。还有感受野相同的情况下,核越小,计算量越小。
- 二维卷积核,有没有可能同时使用两个尺寸的Kernel进行计算,然后再计算出一个更合适的Kernel,从而提高特征提取的性能?
这个idea是很好的,如果早5年,GoogleNet那篇论文就是你的了。这个就是Inception的设计思路。
- 怎么理解卷积是反过来走的?卷积公式里面有负号的原因?
卷积其实是从傅里叶变换,也就是从信号处理那边过来的,只不过深度学习拿来用了,数学上就是这么定义的。
- 卷积核的大小对应了局部性,那什么体现了平移不变形呢?
还是可以通过找Waldo来进行理解,找Waldo的那个核是不会改变的,就是同一个核(权值共享),那么就和Waldo具体在图片中的哪个位置无关了,这就体现了平移不变形。
- (1,2)这个核大小是怎么确定的?
因为我们有先验知识,知道核的大小就是应该(1,2),这样就可以提取垂直的边缘信息。
- 自己训练的模型,loss抖动很厉害怎么办?
其实抖动并不要紧,如果只抖动但是不下降,这个问题就很大了。
如果抖动剧烈的话,建议:调小学习率 & 增加批量大小。
- mlp和卷积神经网关于图片处理参数量大小差别?
mlp(假设单隐层,100个神经元)的参数量是随着输入的大小线性增加的!
但是卷积的话,kernel的大小固定了,那么卷积最终就是为了得到一个feature_map,其大小为(Y_{shape}=(n_h-k_h+1) imes (n_w-k_w+1))。所以现对于mlp,卷积神经网的参数量真的降低了很多很多。