模型选择


我们其实关心的是泛化误差,并不太关心训练误差。
训练误差:模拟考试成绩。
泛化误差:真实考试成绩。

所以我们会来计算我们训练误差和泛化误差呢?一般会有两种数据集,一个叫做验证集,一个叫做测试集。
一个常犯的错误:验证集和训练集混在一起。
经常在代码中的出现的test_dataset其实并不是真正的测试集,而是一个验证集,因为测试数据集你是不会知道这个数据的,而且只用一次会不会再使用,这样才能对模型起到了考试的作用。
而且验证数据集上的表现结果也有可能是虚高的,因为超参数很有可能就是在验证数据集上调出来的。验证数据集的精度并不能真正代表模型在新数据上的泛化能力。

经常的情况下,我们是没有足够的数据来使用。比如银行贷款只有100个人的信息,然后要一般训练,一般验证,这个就划不来了。
K-折交叉验证就是为了尽可能的使用样本来进行训练,但是缺点就是这样比较贵,需要进行K次训练。
通过K折的误差来判断一个超参数的好坏。
最后,通过对K次实验的结果取平均来估计训练和验证误差。

过拟合和欠拟合
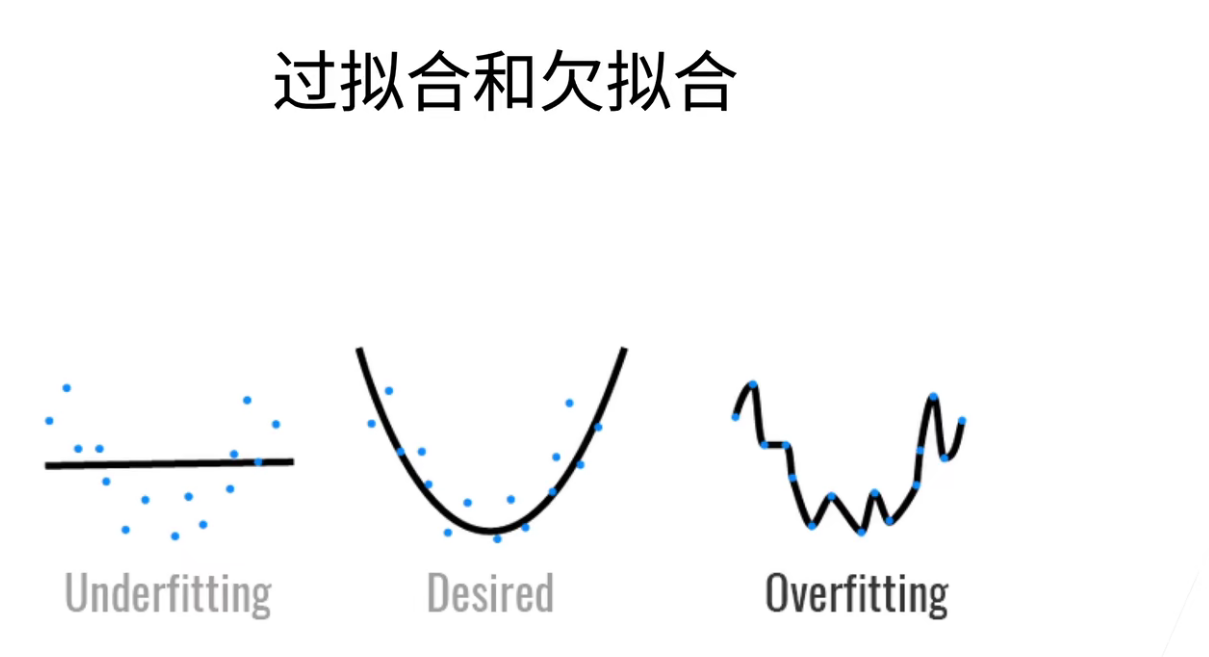

上图的两种情况都是不好的,一个是欠拟合(不能很好的拟合数据),一个是过拟合(拟合的太好,把噪音都拟合进去了)
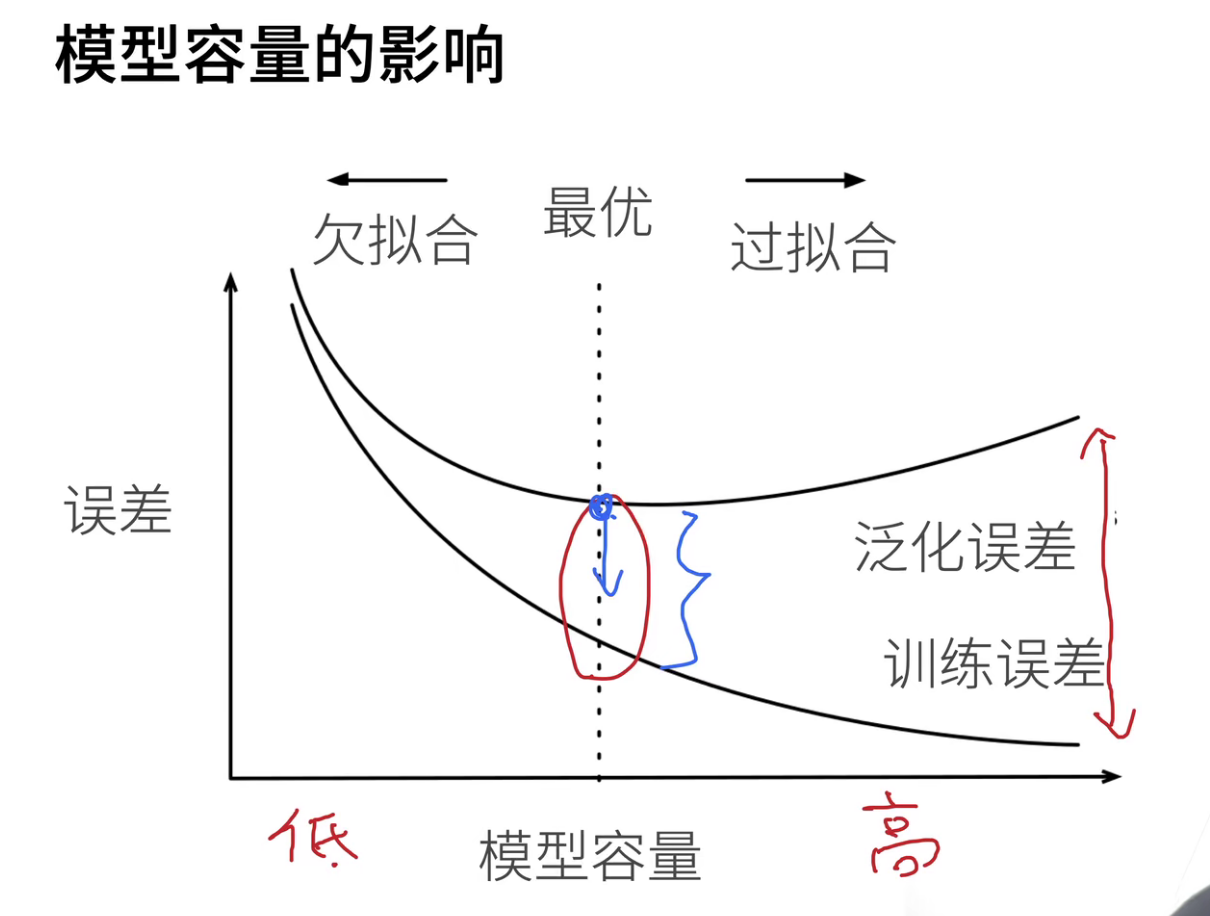
模型容量低,那么一开始的训练误差和泛化误差都是比较高的。但是随着模型容量增大,训练误差可以被一直降低,甚至降低到0(这样就是过拟合了!),因为不管数据多少,网络都可以记住。但是不是记住所有数据就是好的,数据里面有大量的噪音。
随着模型容量增大,泛化误差一开始会下降,然后开始上升。这是因为后面模型容量大了,关注的细节太多,会被困扰。
所以最优应该是在红色圈的那个地方,而且我们希望把蓝色的点往下拉。所有有时候会发现,我为了把泛化误差往下降,我不得不承受一定程度的过拟合。过拟合本质上不是一件很坏的事情,首先你的模型容量要够大(不大根本就没有什么前途),然后再去控制它的容量,使得其泛化误差可以往下降。

注意:横坐标是epochs,一个横坐标是模型容量。随着epoch次数增多,那么loss肯定是会下降的,然后其中对应的点就是在模型容量上的一个点。

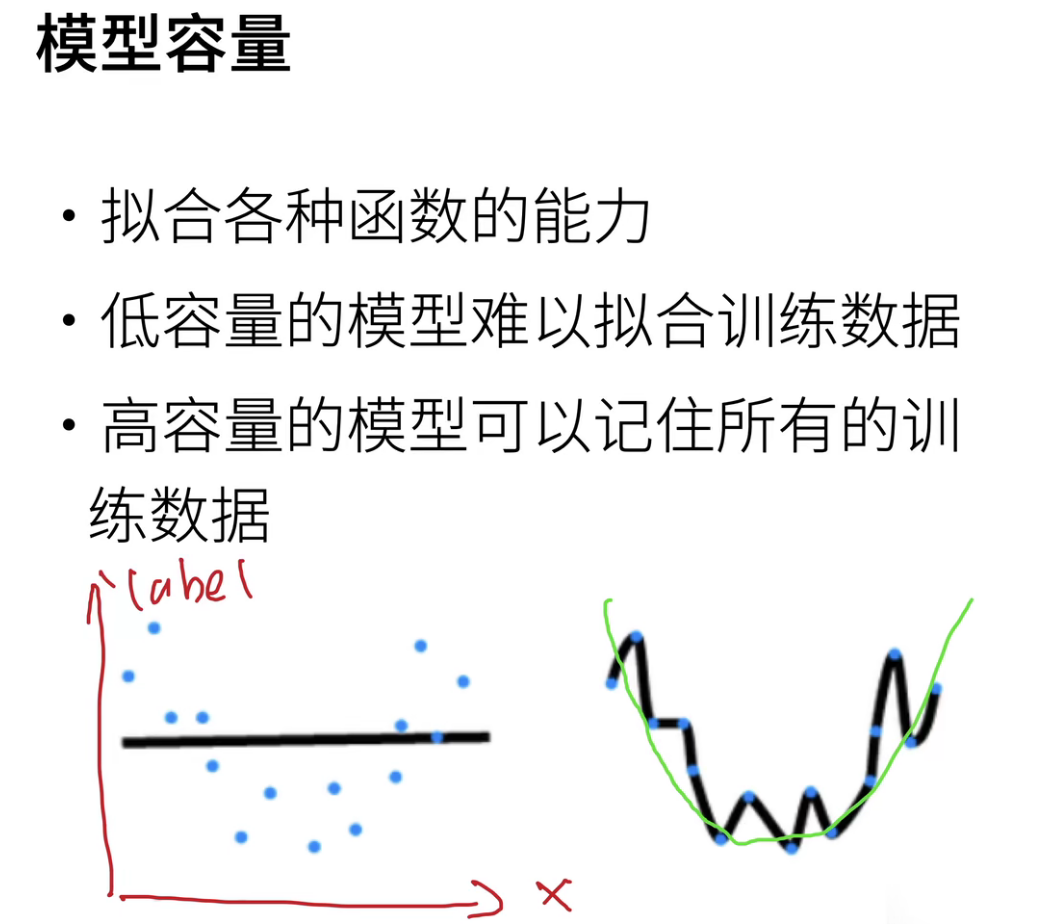
估计模型容量:
- 参数的个数
- 参数值的选择范围

目前统计学习在深度学习上很少用... (统计学习方法.. 先放着吧,目前解释不了的,只能大概猜测)

QA
- SVM和神经网络相比,有什么优缺点?
神经网络相对于SVM,前者的可编程性会高很多。比如用不同的layer等等。相比而言,SVM的可编程性基本等于没有。
- train,test,validate桑格数据集的划分比例和标准是什么?如果是比赛的话,不知道测试数据集的分布,怎么设计验证机和测试集?有什么知道原则吗?
在比赛中,比如房价预测,可能train给的是3~5月的,validate给的是6~7月的,(私有的数据集)test给的是8~10月的。那么确实可能会出现validate和test的数据集的数据分布是不一样的,如果是用过去的数据来训练模型,去预测明天的事情,很有可能这个事件会发生变化。(这是一个很大的问题,就是分布会发生变化,这里就假设数据是一个独立同分布的情况)其实只要验证数据集够大,基本也不会有太多的问题。
一般的处理方式是30%test,70%train,然后在70%trian上做一个5折交叉验证(就是每次拿其中的20%作为验证集 做5次训练)
- 如果是时序序列上的数据,验证集和测试集可能有自相关,这时候应该如何处理?
一般是这个星期作为validete,然后前一个星期作为train。
- 验证数据集和测试数据集的数据清洗(如异常值处理)和特征构建(如标准化)是否需要放在一起处理?
一般在trian上算均值,算方差,然后把这个均值和方差作用到验证数据集上。
- 深度学习一般训练集比较大,所以K折交叉验证在深度学习中是不是没什么应用?训练成本太高了吧?
是的!K折交叉验证因为要训练K次,所以在比较大的数据集上我们很少用(一般深度学习训练一次就要一个星期了!)K折交叉验证使用的前提是数据不够!在传统机器学习我们一般是会用K折交叉验证的,但是在深度学习上确实用的不多,因为比较昂贵。
- K折交叉验证中的k怎么确定?有什么方法吗?
主要看你能承受的计算成本,k当然是越大越好,但是计算量也是线性的增加。
- 所以是出现了overfitting或者underfitting才需要hyperparameter training吗?
不是的,overfitting和underfitting是告诉你哪些参数是好的,他们是反应模型性能的一个指标。
- 如何有效设计超参数?是不能只能搜索?
一般就是看经验了(老中医抓药)
或者用随机,随机个100组,然后看哪一组效果是好的,就是去尝试。
当然现在也在发展AutoML了。
- K折交叉验证的目的是确定超参数吗?然后还要用这个超参数再训练一遍全数据吗?
- 第一种,K折交叉验证就是来确定一个超参数,确定好之后,我在整个数据集上在重新训练一次,几乎是最常见的一个做法。
- 第二种,就是不在重新训练了,就找到精度最好的那一折模型出来。优点就是少训练了,缺点就是少看了一些训练集。
- 第三种,将K折模型都拿下来,然后预测的时候都跑一次,最后取均值。优点就是稳定,缺点就是预测的代价就变成了K倍了。
- SVM和神经网络的发展?
其实学术界就是一个时尚界,这些潮流的都是一波一波的!
像编程语言,也是这个火几年,那个火几年;现在厉害的公司,可能10年前都是不厉害的。
这是一个发展的眼光,神经网络虽然没有很好的理论,但是它的表现效果是好的。
- 数据集中噪声比例多少最好?还是清除所有噪音?
数据集中最好有噪音!
有噪音什么的,应该是自己给模型加入的,而不是存在于数据集中。