前言
上文已经介绍了与Spark 息息相关的MapReduce计算模型,那么相对的Spark的优势在哪,有哪些适合大数据的生态呢?
Spark对比MapReduce,Hive引擎,Storm流式计算引擎
1.如果数据超过1T了基本就不能用spark了,还是会选择MapReduce,MapReduce利用磁盘的高I/O操作实现并行计算确实在处理海量数据是无法取代的,但它在迭代计算中性能不足。(如果数据过大,OOM内存溢出等等,spark的程序就无法运行了,直接就会报错挂掉了,这个很坑爹是吧,虽然MapReduce运行数据相对spark很慢,但是至少他可以慢慢的跑不是吗?再慢至少能跑完。
2.Storm实时的流式计算的处理上也是无法取代的(Storm支持在分布式流式计算程序( Topology) 在运行过程中, 可以动态地调整并行度, 从而动态提高并发处理能力。而Spark Streaming是无法动态调整并行度的。当然Spark Streaming也有其优点是storm不具备的,
首先Spark Streaming由于是基于batch进行处理的, 因此相较于Storm基于单条数据 进行处理, 具有数倍甚至数十倍的吞吐量。
此外Spark Streaming由于也身处于Spark生态圈内, 因此Spark Streaming可以与Spark Core、 Spark SQL, 甚至是 Spark MLlib、 Spark GraphX进行无缝整合。【业务场景的话:通常在对实时性要求特别高, 而且实时数据量不稳定, 比如在白天有高峰期的情况下, 可以选择 使用Storm。 但是如果是对实时性要求一般, 允许1秒的准实时处理使用Spark Streaming。在数据清洗的时候用的Storm】。
3.海量数据的查询,hive肯定也是不可取代的,(很多人认为Spark SQL完全能够替代Hive的查询引擎,我认为肯定是不行的,因为Hive是一种基于HDFS的数据仓库, 并且提供了基于SQL模型的, 针对 存储了大数据的数据仓库, 进行分布式交互查询的查询引擎,有少量的Hive支持的高级特性,Spark SQL暂时还不支持。当然Spark SQL相较于Hive查询引擎来说, 就是速度快,原因还是因为hive底层基于MapReduce,Spark SQL相对于hive还有另一个优势:就是支持大量不同的数据源, 包括hive、 json、 parquet、 jdbc等等。)
Spark 的优点与特点
1. 高效性
运行速度提高100倍。
Apache Spark使用最先进的DAG(Directed Acyclic Graph)调度程序,查询优化程序和物理执行引擎,实现批量和流式数据的高性能。
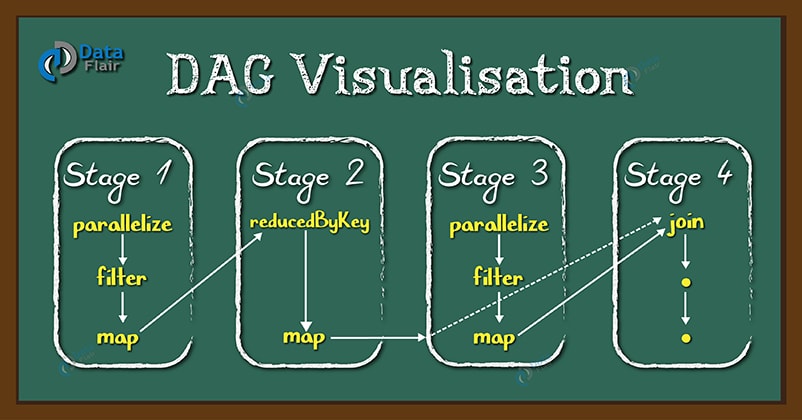
DAG的过程如下图:
DAG 是一组顶点和边的组合。顶点代表了 RDD(Resilient Distributed Dataset 抽象弹性分布式数据集), 边代表了对 RDD 的一系列操作。
DAG Scheduler 会根据 RDD 的 transformation 动作,将 DAG 分为不同的 stage,每个 stage 中分为多个 task,这些 task 可以并行运行。
思考: 也就是说每个任务分成了一系列的子任务可以并行,然后按顺序join到最终的stage任务进行shuffling归纳,这无疑是非常高效的分布式思想
2. 易用性
Spark支持Java、Python和Scala的API,还支持超过80种高级算法,使用户可以快速构建不同的应用。而且Spark支持交互式的Python和Scala的shell,可以非常方便地在这些shell中使用Spark集群来验证解决问题的方法。
举例Java调用scala 脚本测试类的一个Spark Demo:
//编写scala测试类
object MyTest { def main(args: Array[String]): Unit = { val conf = new SparkConf() conf.setAppName("MyTest") conf.setMaster("local") val sc = new SparkContext(conf) val input = sc.textFile("file:///F:/sparktest/catalina.out") val count = input.filter(_.contains("java.lang.NullPointerException")).count System.out.println("空指针异常数" + count) sc.stop() } }
public class SubmitScalaJobToSpark { public static void main(String[] args) { String[] arg0 = new String[]{ "--master", "spark://node101:7077", "--deploy-mode", "client", "--name", "test java submit job to spark", "--class", "MyTest",//指定spark任务执行函数所在类 "--executor-memory", "1G",//运行内存 "E:\其他代码仓库\spark\out\artifacts\unnamed\unnamed.jar",//jar包路径 }; SparkSubmit.main(arg0); } }
Python调用Spark数据类型:

3. 通用性
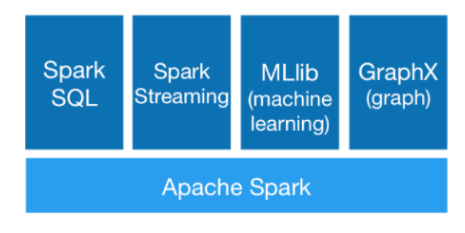
Spark提供了统一的解决方案。Spark可以用于批处理、交互式查询(Spark SQL)、实时流处理(Spark Streaming)、机器学习(Spark MLlib)和图计算(GraphX)。这些不同类型的处理都可以在同一个应用中无缝使用。Spark统一的解决方案非常具有吸引力,毕竟任何公司都想用统一的平台去处理遇到的问题,减少开发和维护的人力成本和部署平台的物力成本。
4. 兼容性
Spark可以非常方便地与其他的开源产品进行融合。比如,Spark可以使用Hadoop的YARN和Apache Mesos作为它的资源管理和调度器,并且可以处理所有Hadoop支持的数据,包括HDFS、HBase和Cassandra等。这对于已经部署Hadoop集群的用户特别重要,因为不需要做任何数据迁移就可以使用Spark的强大处理能力。Spark也可以不依赖于第三方的资源管理和调度器,它实现了Standalone作为其内置的资源管理和调度框架,这样进一步降低了Spark的使用门槛,使得所有人都可以非常容易地部署和使用Spark。此外,Spark还提供了在EC2上部署Standalone的Spark集群的工具。
Mesos:Spark可以运行在Mesos里面(Mesos 类似于yarn的一个资源调度框架)
standalone:Spark自己可以给自己分配资源(master,worker)
YARN:Spark可以运行在yarn上面
Kubernetes:Spark接收 Kubernetes的资源调度
Spark的组成与运行过程
Spark组成(BDAS):全称伯克利数据分析栈,通过大规模集成算法、机器、人之间展现大数据应用的一个平台。也是处理大数据、云计算、通信的技术解决方案。
它的主要组件有:
SparkCore:将分布式数据抽象为弹性分布式数据集(RDD),实现了应用任务调度、RPC、序列化和压缩,并为运行在其上的上层组件提供API。
SparkSQL:Spark Sql 是Spark来操作结构化数据的程序包,可以让我使用SQL语句的方式来查询数据,Spark支持 多种数据源,包含Hive表,parquest以及JSON等内容。
SparkStreaming: 是Spark提供的实时数据进行流式计算的组件。
MLlib:提供常用机器学习算法的实现库。
GraphX:提供一个分布式图计算框架,能高效进行图计算。
BlinkDB:用于在海量数据上进行交互式SQL的近似查询引擎。
Tachyon:以内存为中心高容错的的分布式文件系统。
运行流程:
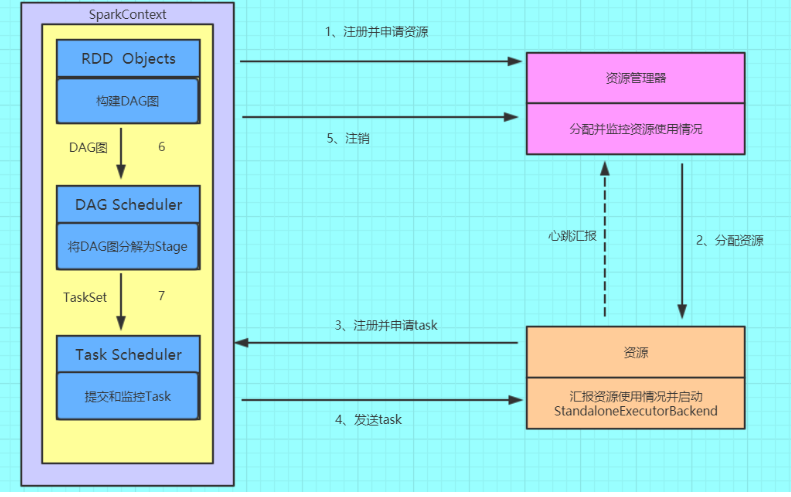
(1)构建Spark Application的运行环境(启动Driver),Driver向资源管理器(可以是Standalone、Mesos或YARN)注册并申请运行Executor资源;
(2)资源管理器分配Executor资源并启动StandaloneExecutorBackend,Executor运行情况将随着心跳发送到资源管理器上;
(3)Driver构建成DAG图,将DAG图分解成Stage,并把Taskset发送给Task Scheduler。Executor向SparkContext申请Task
(4)Task Scheduler将Task发放给Executor运行同时Driver将应用程序代码发放给Executor。
(5)Task在Executor上运行,运行完毕释放所有资源。
Spark 的运用
腾讯大数据精准推荐借助Spark快速迭代的优势,实现了在“数据实时采集、算法实时训练、系统实时预测”的全流程实时并行高维算法,最终成功应用于广点通pCTR投放系统上。
优酷土豆将Spark应用于视频推荐(图计算)、广告业务,主要实现机器学习、图计算等迭代计算。