1 Background
NVMe协议
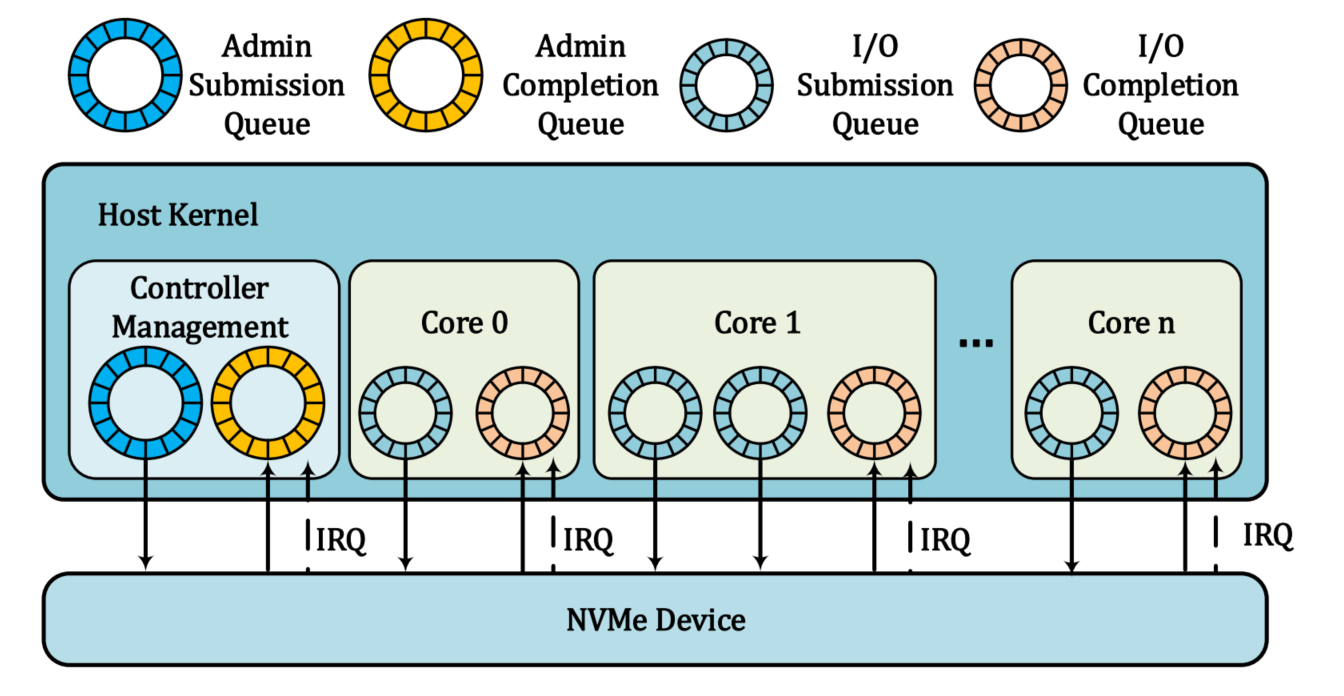
传统的SATA接口已经不能满足现在对更高的吞吐量的IO需求,而NVMe协议中正是使用PCIe接口设计和开发的,可以满足当前的IO需求,PCIe接口取代了SATA接口。NVMe中含有多个IO(SQ&CQ)队列对,将传统的串行存储改为并行存储,很大程度上提高了吞吐量,降低了延时。在NVMe SSDs设备的应用场景中,如在数据密集型的数据中心存储、系统存储与PCIe设备之间的加速(如GPUs)都有着不错的表现。而通常情况下NVMe设备的IO性能均未被充分利用,而虚拟机制可以填补这一遗憾。
IO Virtualization
IO虚拟化是云计算的关键部分,此处理方式有着很多优势:1.提升底层设备的利用率;2.简化存储管理;3.为复杂的功能提供简单且相容的接口。前面提到NVMe的设备的利用率不高,因此在虚拟化的环境中可以提升该底层设备的利用率。
NVMe Virtualization(总结别人已有工作)
前人在NVMe的虚拟化中做了一些工作:
Blind Mode:在设备管理器中实现了SCSI到NVMe的转换层;
Virtual Mode:通过在(托管的)VM之间分配I/O队列来获得纯虚拟NVMe堆栈;
Physical Mode:每个虚拟功能使用基于NVMe的控制器。
NVMe Mainstream Virtualization
VirtIO&Userspace driver in QEMU:与本机驱动程序相比,VirtIO和QEMU的用户空间驱动的性能很差;
SPDK:必须使用大表存储,从而加重了内存存储的压力。
2 Motivation
高性能的NVMe虚拟化的需求
1.高吞吐量:NVMe设备已经满足这一条件,所以在添加虚拟机制后底层设备的性能不能大打折扣;
2.低延时:虚拟之后大量的上下文切换会带来延时的负载;
3.设备共享:大量的虚拟机会共享有限的NVMe设备,且要满足VM之间不能互相干扰;
4.底层设备优势保留
5.支持实时迁移:支持实时迁移在虚拟化中十分重要。
注:虚拟机实时迁移是虚拟化技术的一个重要特征,对于近年来不断兴起的数据中心的负载均衡和灾难恢复有非常重大的意义。通过虚拟机的实时迁移,把虚拟机从源物理主机硬件平台迁移到目的物理主机硬件平台上,不仅可以快速消除源物理机上虚拟机之间的资源竞争,还可以通过合并操作大大减少激活的物理机数目,显著提高计算的效率。
不同NVMe设备的比较
virtio:虽然实现了存储设备的虚拟化但大量软件层的存在,严重影响了NVMe设备性能的发挥,本文提到其性能限制了一半;
VFIO:采用 direct pass-through 方式,虽然加速了运行速度,实现了高吞吐量和低延时,没有限制底层设备的发挥,但是这种方式下,NVMe虚拟信息无法写入管理程序,不支持虚拟机的实时迁移,因此在虚拟化方面有不足。
注:
VFIO是一个可以安全的把设备I/O、中断、DMA等暴露到用户空间(userspace),从而可以在用户空间完成设备驱动的框架。
得益于vfio低开销的用户空间直接设备访问,虚拟机设备分配(device assignment)、高性能应用等可以获得更高的I/O性能。
MDev-NVMe:在VFIO的基础上进行设计,为其增加虚拟化功能。VFIO-pci不支持虚拟化,改为VFIO-MDev(模拟PCI),这样可以支持多个VM共享设备。将原始的NVMe驱动程序转化为Linux内核中的MDev-NVMe驱动程序,这样可以尽可能多的传递IO操作单元。而且在该模式下这些物理机和虚拟机上的队列状态信息都有所保留,因此支持虚拟化。该模式绕开了FS,因此也减少了大量软件栈的负载。因此该模式可以满足NVMe虚拟化的所有需求。
Mediated Pass-through(MPT)
介于直接传输和设备完全虚拟化之间,无需修改OS内核,可以直接使用NVMe驱动程序。
3 Design & Implementation
3.1 Architecture
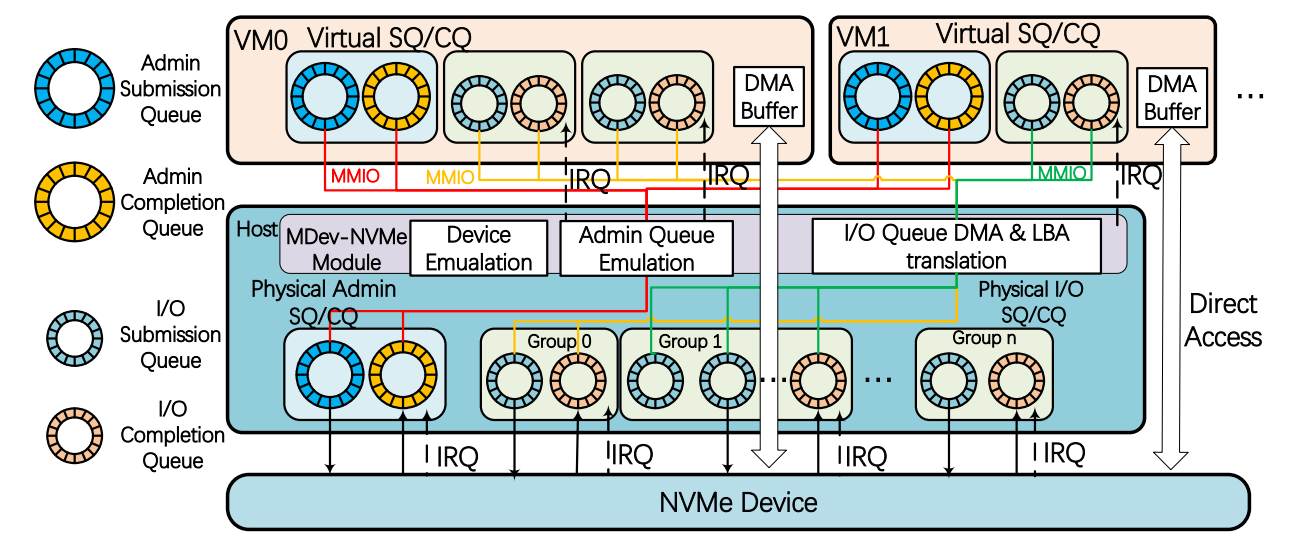
基于 Virtio and VFIO 改进构建了MDev-NVMe。主要提供了三种重要的功能:1.PCI仿真;2.管理队列仿真;3.IO队列的shadow机制。目的是在发挥底层设备的高性能的同时可以实现物理设备在多个虚拟机上的共享。
Device Emulation 该模式下可以不修改操作系统内核,即可通过PCIe总线连接NVMe设备,这样可以保证底层设备的功能最大化发挥;
Admin Queue Emulation NVMe协议中规定仅仅有一对Admin SQ和CQ,本文中虚拟多个队列对(每个VM中有一对),可以确保每个用户调控自己设备的IO操作;
I/O Queue Shadow 用至多64K个IO队列代替原来的一个IO队列对,因此无需设备仿真;VM中的IO队列经过DMA & LBA转换为相应的物理队列。这种操作不等于设备虚拟化,因此不用考虑虚拟化带来的负载;
DMA Buffer Access 主机DMA可以直接管理guest NVMe设备上DMA缓冲区的内存地址,该模式避免了在频繁的IO操作中CPU过多的进行虚拟机和物理设备间地址转换的操作负载。
3.2 Queue Handling
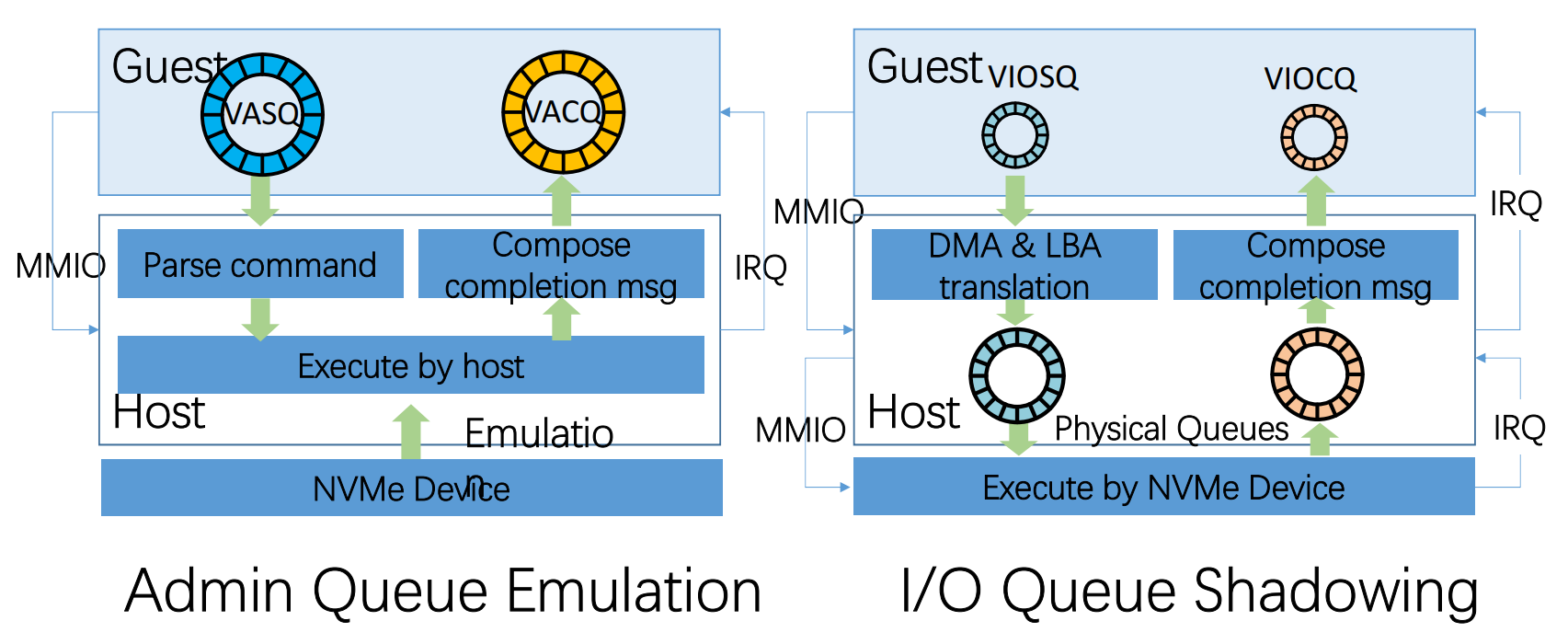
大量的Admin队列的操作均在VM初始化的时候创建,因此,Admin的虚拟化不会成为瓶颈;
Queue shadow: 实现虚拟设备与物理设备的直通。因为NVMe设备中不止一个IO SQ CQ 队列,因此这种方案可行。
服务端物理内核绑定IO队列且每个IO提交完成后,中断都会被相应的内核捕获,因此加速了IO操作。
shadow机制中虚拟机上的中断处理实际上是相应的直通链接的物理机上的中断处理,这种操作加速了中断处理。
3.3 DMA & LBA translation
本文提出的 guest IO 队列(虚拟机上)可以通过 DMA & LBA 转换的方式与物理机上的IO队列直接相连,这样可以达到更好的IO性能以及实现资源划分。转化后的虚拟机IO队列与物理机上的IO队列相绑定,且转换结果存储在host内核中。此转化过程基于EPT,可以实现在多个虚拟机创建的大量IO队列并共享物理机设备时对转换表进行维护。这种转换基于静态分区策略(各个虚拟机在初始化阶段分配得到NVMe设备连续内存的一部分),转换单元是指向DMA缓冲区的数据指针。MDev-NVMe 模式将客户物理地址转换为主机的物理地址,并且将DMA缓存内容直接写入主存中,保证了多个虚拟设备之间的隔离性。如果虚拟机没有在初始化时分配地址则不会与对应的物理机地址相绑定,此过程也是被MDev-NVMe机制严格控制且被EPT保护,保护了不同VM之间的安全性。Start Logical Block Address (SLBA) 单元在guest上的IO命令可以在申请空间偏移时被更改并复制到主机IO队列中。
3.4 2-Way Polling Mode
虽然对比之前的设计(Virtio)性能提升了,但是在虚拟设备对比本地物理机在性能上还是有明显的断层。因为IO命令中频繁的SQ与CQ导致了IO瓶颈的产生。
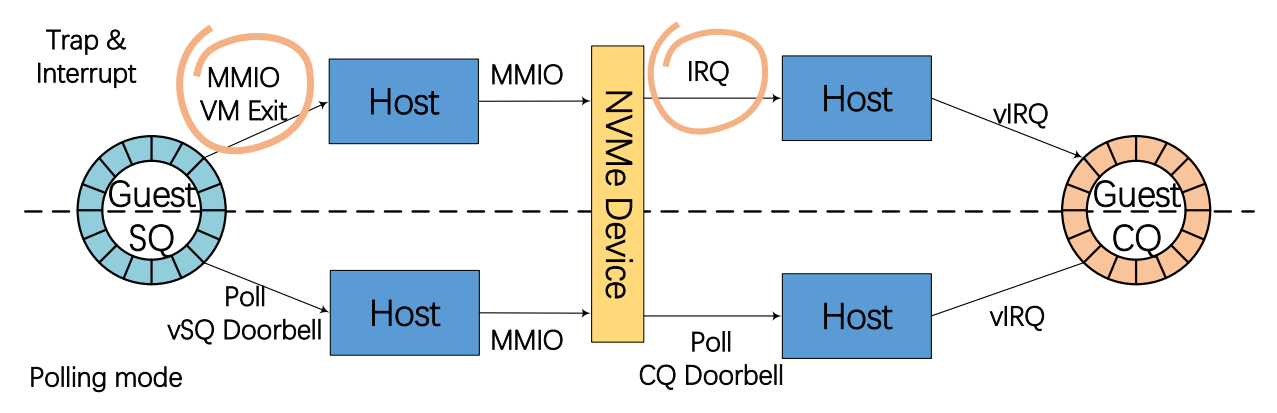
Host kernel -> NVMe devices 小于10us,因此这是不足以成为IO瓶颈的。
然而guest中的IO命令会经过两个方面的负载:1. guest IO命令转换和提交时;2. 处理由物理设备产生的中断时(更新门铃寄存器)。为了解决上述两种时间开销,本文将中断内陷转换为主动轮训机制。
1.将guest的SQ和CQ的门铃存储在主机的主存中,因此系统可以更直接的管理guest中的IO操作,通过轮询机制,轮询guest写入shadow 门铃而不是在主机中产生一个MMIO。轮询线程可以直接获取并立即更新SQ和CQ队列。本文中采用了3线程主动轮询,3线程分别处理shadow 门铃的 SQ 尾部,shadow 门铃的 CQ 头部和主机的CQ集合,这样可以获得甚至高于本地平台的主机内核。这些线程可以达到充分利用主机服务器上3个内核且保证轮询线程可以在VM之间共享的目的。