提出动机
训练层面
- CNN对见过的样本有好的泛化能力,而没见过的样本则比较差(例:看过正脸很难识别侧脸)。这就是CNN的归纳偏置(inductive bias)。
- 为了取得对大部分情况都好的泛化能力,需要各种情况的训练样本,这样大大增加训练代价。
- Capsule希望能够学习到一些潜在表示,利用这些潜在表示可以很简单的推理出样本的各种情况,让模型能够泛化得更广,这样解决CNN的归纳偏置问题。
- 由于Capsule能够利用潜在表示推断各种情况,可以大大减少训练样本。
原理层面
- CNN不懂图片中的物体,它仅仅是提取了像素之间的复杂关系。
- Capsule希望更加关注图片的实体,通过解释与描述实体来正确的认识图片。
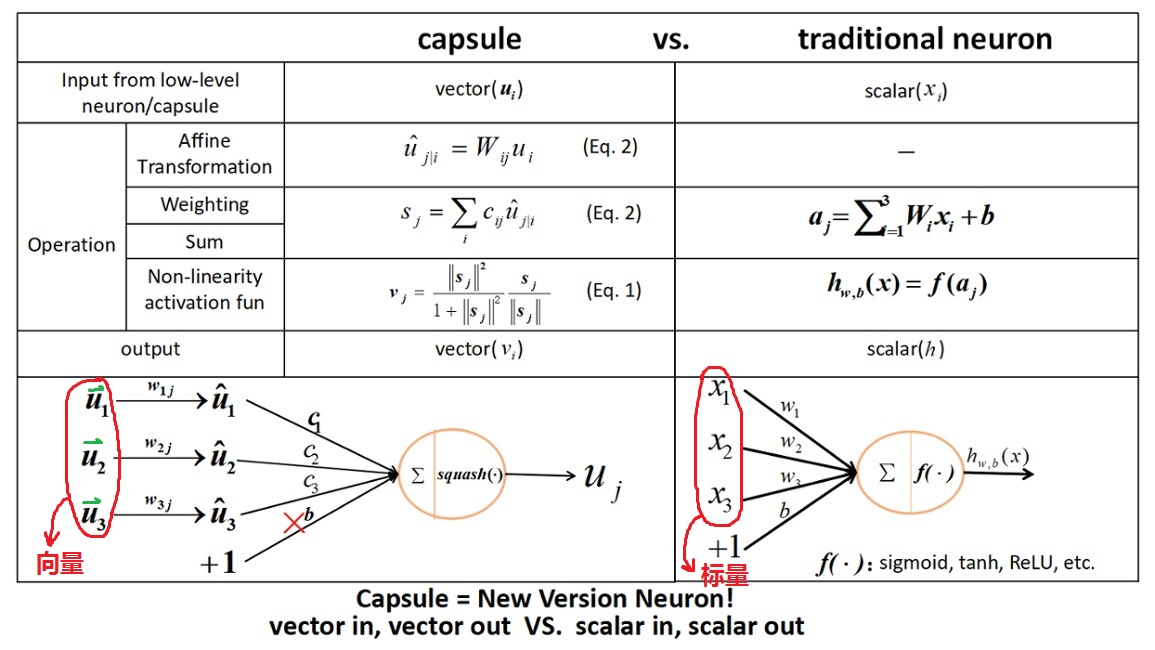
CNN与Capsule的区别
- CNN对于输入具有 invariant 。就是同一类别样本有着相同的输出(特征向量或者类别预测)。而Capsule对输入具有 equivariant 。就是同一类别样本有着不同的输出(但是进一步对输出进行normalize可以进行分类)
- CNN输入是一组标量,而Capsule输入是一组向量。