一、先说说编解码问题
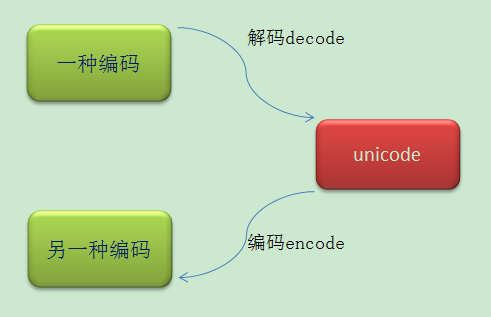
编码转换时,通常需要以unicode作为中间编码,即先将其他编码的字符串解码(decode)成unicode,再从unicode编码(encode)成另一种编码。
Eg:
|
1
2
|
str1.decode('gb2312') #将gb2312编码的字符串转换成unicode编码str2.encode('gb2312') #将unicode编码的字符串转换成gb2312编码 |
python2.7 idle GUI界面打印中文会出现乱码,这是idle本身问题:
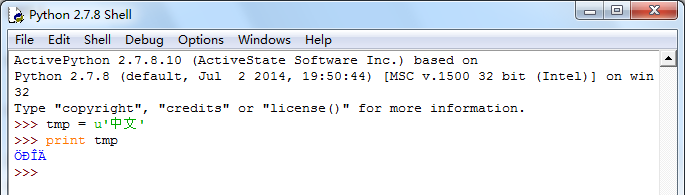
cmd界面的python2.7则是正常的:

注意事项:
- s='中文' 如果是在utf8的文件中,该字符串就是utf8编码,如果是在gb2312的文件中,则其编码为gb2312。这种情况下,要进行编码转换,都需要先用decode方法将其转换成unicode编码,再使用encode方法将其转换成其他编码。
- 在没有指定特定的编码方式时,都是使用的系统默认编码创建的代码文件。
- 如果字符串是这样定义: s=u'中文' 则该字符串的编码就被指定为unicode了,即python的内部编码,而与代码文件本身的编码无关。只需要直接使用encode方法将其转换成指定编码即可
- 如果一个字符串已经是unicode了,再进行解码则将出错,因此通常要对其编码方式是否为unicode进行判断isinstance(s, unicode) #用来判断是否为unicode
二、查看文本编码的方式
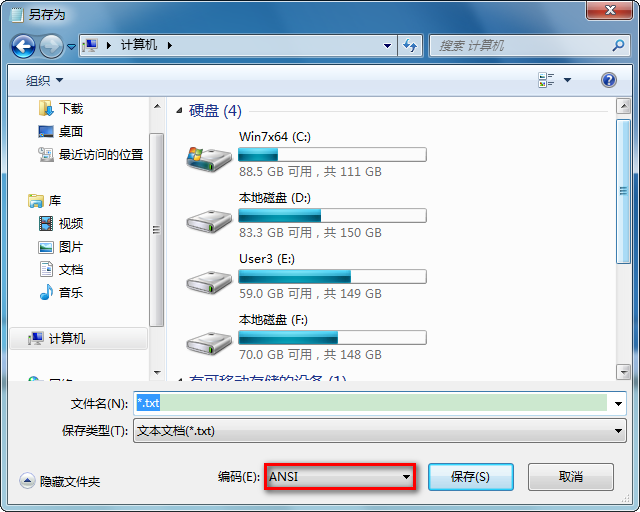
1. notepad
对于我们经常使用的记事本,“文件” -> “另存为”,可查看到当前的编码方式:
2.notepad++
点击“菜单栏” -> “格式”可以查看到:

还可直接对其进行转换,转换完成后保存文件。
3.UltraEdit
不同编码的文本,是根据文本的前两个字节来定义其编码格式的,定义如下:
ANSI: 无格式定义;
Unicode: 前两个字节为FFFE;
Unicode big endian: 前两字节为FEFF;
UTF-8: 前两字节为EFBB;
这样通过前面两个字节就可以判定出文件的具体格式了。
三、系统中常见的编码方式
1.ASCII编码
上世纪70年代,美国国家标准协会(American National Standard Institute , ANSI )制订了ASCII码(American Standard Code for Information Interchange,美国标准信息交换码)
使用7 位二进制数共128个组合来表示所有的大写和小写字母,数字0 到9、标点符号, 以及在美式英语中使用的特殊控制字符。
第0~32号及第127号(共34个)是控制字符或通讯专用字符,如控制符:LF(换行)、CR(回车)、FF(换页)、DEL(删除)、BEL(振铃)等
第33~126号(共94个)是字符,其中第48~57号为0~9十个阿拉伯数字;65~90号为26个大写英文字母,97~122号为26个小写英文字母,其余为一些标点符号、运算符号等。
最高位(b7)用作奇偶校验位,所谓奇偶校验,是指在代码传送过程中用来检验是否出现错误的一种方法,一般分奇校验和偶校验两种:
- 奇校验规定:正确的代码一个字节中1的个数必须是奇数,若非奇数,则在最高位b7添1
- 偶校验规定:正确的代码一个字节中1的个数必须是偶数,若非偶数,则在最高位b7添1
2.扩展的ASCII编码
一个字节中的后7位总共只能表示128个不同的字符,英语用这些字符已经足够了,可是要表示其他语言却是不够。比如,在法语中,字母上方有注音的符号,就无法用ASCII表示。于是,一些国家就利用了字节中闲置的最高位编入新的符号。这样一来,就可以表示最多256个符号,这就是扩展ASCII 码,所以现在有7位和8位的两种ASCII码,扩展的ASCII 码允许将每个字符的第8 位用于确定附加的128 个特殊符号字符、外来语字母和图形符号。但是,不管怎样,0~127表示的字符是一样的,不同的只是128~255.
3.ANSI编码
也是美国国家标准协会(American National Standard Institute , ANSI )制订的标准。为使计算机支持更多语言,通常使用 0x80~0xFF 范围的 2 个字节来表示 1 个字符。比如:汉字 '中' 在中文操作系统中,使用 [0xD6,0xD0] 这两个字节存储。
不同的国家和地区制定了不同的标准,由此产生了 GB2312, BIG5, JIS 等各自的编码标准。这些使用 2 个字节来代表一个字符的各种汉字延伸编码方式,称为 ANSI 编码。
- 在简体中文系统下,ANSI 编码代表 GB2312 编码
- 在日文操作系统下,ANSI 编码代表 JIS 编码
不同 ANSI 编码之间互不兼容,当信息在国际间交流时,无法将属于两种语言的文字,存储在同一段 ANSI 编码的文本中。
ANSI编码表示英文字符时用一个字节,表示中文用两个字节,而unicode不管表示英文字符还是中文都是用两个字节来表示。
4.Unicode编码
Unicode字符集编码是Universal Multiple-Octet Coded Character Set 通用多八位编码字符集的简称,是国际组织制定的可以容纳世界上所有文字和符号的字符编码方案。
但即使扩展到256个符号也不够用,比如汉字据统计有10万个以上,而且同一个数值在各国的语言中表示的却不同,比如130在法语里面é,而在希腊语里面则代表Gimel,于是UNICODE应运而生。
Unicode是一种在计算机上使用的字符编码。它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。Unicode 标准始终使用十六进制数字,而且在书写时在前面加上前缀“U+”,例如字母“A”的编码为 004116 和字符“?”的编码为 20AC16。所以“A”的编码书写为“U+0041”。但Unicode只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。
5.UTF8编码
事实证明,对可以用ASCII表示的字符使用UNICODE并不高效,因为UNICODE比ASCII占用大一倍的空间,而对ASCII来说高字节的0对 他毫无用处。为了解决这个问题,就出现了一些中间格式的字符集,他们被称为通用转换格式,即UTF(Universal Transformation Format)。目前存在的UTF格式有:UTF-7, UTF-7.5, UTF-8, UTF-16, 以及 UTF-32。
UTF-8(8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码(定长码),也是一种前缀码。它可以用来表示Unicode标准中的任何字符,且其编码中的第 一个字节仍与ASCII兼容,这使得原来处理ASCII字符的软件无须或只须做少部份修改,即可继续使用。因此,它逐渐成为电子邮件、网页及其他存储或传 送文字的应用中,优先采用的编码。
UTF-8用1~4个字节对Unicode进行编码。从Unicode到UTF-8的编码方式如下:
000000 - 00007F║0xxxxxxx
000080 - 0007FF║110xxxxx 10xxxxxx
000800 - 00FFFF║1110xxxx 10xxxxxx 10xxxxxx
010000 - 10FFFF║11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
对于0x00-0x7F之间的字符,UTF-8编码与ASCII编码完全相同;
带有附加符号的拉丁文、希腊文、西里尔字母、亚美尼亚语、希伯来文、阿拉伯文、叙利亚文及它拿字母则需要二个字节编码(Unicode范围由);
其他基本多文种平面(BMP)中的字符(这包含了大部分常用字)使用三个字节编码;
其他极少使用的Unicode 辅助平面的字符使用四字节编码;
UTF-8编码的最大长度是4个字节。从上表可以看出,4字节模板有21个x,即可以容纳21位二进制数字。Unicode的最大码位0x10FFFF也只有21位。
UTF-8解析算法:
如果字节(Byte)的第一位为0,则B为ASCII码,并且Byte独立的表示一个字符;
如果字节(Byte)的第一位为1,第二位为0,则Byte为一个非ASCII字符(该字符由多个字节表示)中的一个字节,并且不为字符的第一个字节编码;
如果字节(Byte)的前两位为1,第三位为0,则Byte为一个非ASCII字符(该字符由多个字节表示)中的第一个字节,并且该字符由两个字节表示;
如果字节(Byte)的前三位为1,第四位为0,则Byte为一个非ASCII字符(该字符由多个字节表示)中的第一个字节,并且该字符由三个字节表示;
如果字节(Byte)的前四位为1,第五位为0,则Byte为一个非ASCII字符(该字符由多个字节表示)中的第一个字节,并且该字符由四个字节表示。
6.ANSI与ASCII编码区别
- 字面上差异:ANSI指美国国家标准协会,ASCII指美国信息互换标准代码
- ANSI可以说是ASCII的扩展(为了支持非拉丁语系的语言)一方面,他将ascii码扩展到8bits,增加了0x80-0xff共128个字符。另一方面,在cjk(chinese japanese korean)系统中,ANSI在不同语言中有不同的具体标准,在简体中文系统下,ANSI 编码代表 GB2312 编码,在日文操作系统下,ANSI 编码代表 JIS 编码。
- ansi编码,就是一种未经国际标准化的编码(也没办法标准化,因为扩展部分的内码存在交集);而Unicode为国际化的编码。
7.GB2312
7.1 名称及制定时间
《信息交换用汉字编码字符集》是由中国国家标准总局1980年发布,标准号是GB 2312—1980,所以简称为GB2312。
7.2 编码格式
在使用GB2312的程序中,通常采用EUC储存方法,以便兼容于ASCII。浏览器编码表上的“GB2312”,通常都是指“EUC-CN”表示法。
每个汉字及符号以两个字节来表示。第一个字节称为“高位字节”(也称“区字节)”,第二个字节称为“低位字节”(也称“位字节”)。
“高位字节”使用了0xA1-0xF7(把01-87区的区号加上0xA0),“低位字节”使用了0xA1-0xFE(把01-94加上 0xA0)。 由于一级汉字从16区起始,汉字区的“高位字节”的范围是0xB0-0xF7,“低位字节”的范围是0xA1-0xFE,占用的码位是 72*94=6768。其中有5个空位是D7FA-D7FE。
例如“啊”字在大多数程序中,会以两个字节,0xB0(第一个字节) 0xA1(第二个字节)储存。区位码=区字节+位字节(与区位码对比:0xB0=0xA0+16,0xA1=0xA0+1)。
GB 2312标准共收录6763个汉字,其中一级汉字3755个,二级汉字3008个;同时,GB 2312收录了包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母在内的682个全角字符。
7.3 特点
GB 2312的出现,基本满足了汉字的计算机处理需要,它所收录的汉字已经覆盖中国大陆99.75%的使用频率。
对于人名、古汉语等方面出现的罕用字,GB 2312不能处理,这导致了后来GBK及GB 18030汉字字符集的出现。
8.GBK
8.1 名称及制定时间
GBK全称《汉字内码扩展规范》,全国信息技术标准化技术委员会1995年12月1日制订。
8.2 编码格式
GBK编码,是在GB2312-80标准基础上的内码扩展规范,使用了双字节编码方案,其编码范围从8140至FEFE(剔除xx7F),共23940个码位,共收录了21003个汉字,完全兼容GB2312-80标准,支持国际标准ISO/IEC10646-1和国家标准GB13000-1中的全部中日韩汉字,并包含了BIG5编码中的所有汉字。GBK编码方案于1995年10月制定, 1995年12月正式发布,目前中文版的WIN95、WIN98、WINDOWS NT以及WINDOWS 2000、WINDOWS XP、WIN 7等都支持GBK编码方案。
GBK 是 GB2312的扩展 ,除了兼容GB2312外,它还能显示繁体中文,还有日文的假名。
8.3 说明
GB2312是中国规定的汉字编码,也可以说是简体中文的字符集编码;GBK 是 GB2312的扩展 ,除了兼容GB2312外,它还能显示繁体中文,还有日文的假名。
9.Python idle默认编码方式
如下操作均在Python2.7 idle中实验


说明:1.'a'的编码仍然是'a',‘中'编码为0xd6和0xd0两个字节( 而且是0x80~0xFF 范围内),说明编码方式为扩展的ASCII(ANSI)
参考http://www.cnblogs.com/TsengYuen/archive/2012/05/22/2513290.html
http://wenku.baidu.com/link?url=DW_eaIYsVuh31R7FHY8nQa3jiyrtnH6rIc5zoseS8apT0vN9exCFteyfcAm30USuphTdKqsOSAwaU7QeqdpK7u4-Gpr2WULF8PLwlY3bafq
后续继续更新
四、Python模块之codecs
python对多国语言的处理是支持的很好的,它可以处理现在任意编码的字符,这里深入的研究一下python对多种不同语言的处理。
有一点需要清楚的是,当python要做编码转换的时候,会借助于内部的编码,转换过程请参考上文第一张图片。
Unicode编码有两种,一种是UCS-2,用两个字节编码,共65536个码位;另一种是UCS-4,用4个字节编码,共2147483648个码位。
python都是支持的,这个是在编译时通过--enable- unicode=ucs2或--enable-unicode=ucs4来指定的。那么我们自己默认安装的python有的什么编码怎么来确定呢?有一个 办法,就是通过sys.maxunicode的值来判断:
|
1
2
|
import sysprint sys.maxunicode |
如果输出的值为65535,那么就是UCS-2,如果输出是1114111就是UCS-4编码。
我们要认识到一点:当一个字符串转换为内部编码后,它就不是str类型了!它是unicode类型
|
1
2
3
4
|
a = " 风卷残云 "print type(a)b = unicode(a,‘gb2312')print type(b) |
运行结果:
|
1
2
|
<type 'str'><type 'unicode'> |
这个时候b可以方便的任意转换为其他编码,比如转换为utf-8
|
1
2
|
c = b.encode(’utf8')print c |
好了,该说说codecs模块了,它和我上面说的概念是密切相关的。codecs专门用作编码转换,当然,其实通过它的接口是可以扩展到其他关于代码方面的转换的,这个东西这里不涉及。
参考文档:
http://xanderzhang.iteye.com/blog/465992
http://jingyan.baidu.com/article/48b558e367b1fe7f38c09a87.html
http://blog.163.com/yang_jianli/blog/static/161990006201371451851274
http://san-yun.iteye.com/blog/1544123