php特级课---2、网站大数据如何存储
一、总结
一句话总结:
mysql主从,分库分表,mysql分区,mysql集群,Nosql
1、mysql主从服务器各自的功能是什么?
增删改,主服务器
查询,备份,从服务器
2、mysql能够负担得起几亿用户的访问么?
可以的,优化做好就好,比如淘宝,主从服务器,分库分表,数据库的负载均衡
3、mysql分库分表是怎么弄?
垂直分表,大表分成小表,每个小表几个字段或者几十个字段
水平分表,行数太多了,可以分成多个表
4、mysql数据库过度分库分表的缺点是什么,怎么解决?
维护成本太大
解决:mysql分区技术
5、mysql分区技术是什么?
名字是一样的,物理存储地址是一样的:其实相当于mysql给我们的分库分表做了维护
名字是一样的,物理存储地址是一样的
其实相当于mysql给我们的分库分表做了维护
水平分区技术将一个表拆成多个表,比较常用的方式
是将表中的记录按照某种Hash算法进行拆分,简单的
拆分方法如取模方式。同样,这种分区方法也必须对
前端的应用程序中的SQL进行修改方可使用。而且对
于一个SQL,它可能会修改两个表,那么你必须得写
成2个SQL语句从而可以完成一个逻辑的事务,使得程
序的判断逻辑越来越复杂,这样也会导致程序的维护
代价高,也就失去了采用数据库的优势。因此,分区
技术可以有力地避免如上的弊端,成为解决海量数据
存储的有力方法
6、mysql集群的作用是什么?
冗余备份
7、Nosql-Mongodb里面存储的数据的形式是怎样的?
是类似json的bjson格式
是类似json的bjson格式,
MongoDB是一个基于分布式文件存储的数据库。由
C++语言编写。旨在为WEB应用提供可扩展的高性能数
据存储解决方案。
MongoDB是一个介于关系数据库和非关系数据库
之间的产品,是非关系数据库当中功能最丰富,最像关
系数据库的。他支持的数据结构非常松散,是类似json
的bjson格式,因此可以存储比较复杂的数据类型。
Mongo最大的特点是他支持的查询语言非常强大,其语
法有点类似于面向对象的查询语言,几乎可以实现类似
关系数据库单表查询的绝大部分功能,而且还支持对数
据建立索引
二、MySQL主从复制技术的简单实现
配置环境:
主从服务器操作系统均为 ubuntu15.10
主从服务器MySQL版本均为 MySQL5.6.31
主服务器IP:192.168.0.178
从服务器IP:192.168.0.145
主从服务器之间都是相互能ping通的。
主服务器配置:
1、启用二进制日志,设置服务器唯一ID;

2、修改 /etc/mysql/my.cnf “bind-address = 0.0.0.0;” 使得MySQL允许远程连接;
3、进入终端,为用户backend赋予 REPLICATION SLAVE 权限,然后执行 “FLUSH PRIVILEGES;” 刷新权限;(我这里已经有该用户,没有的应该先创建一个用户并赋予 REPLICATION SLAVE 权限)该用户用于从服务器连接主服务器数据库。

4、重启MySQL并进入MySQL终端,执行 “show master status;” 查看mater的状态;
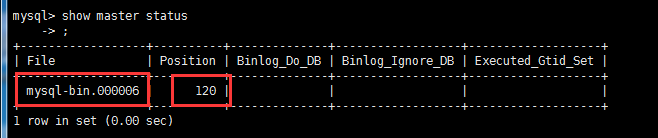
5、记录File 和 Position的值,因为配置从服务器时要用到。此时不要再动主数据库了,以免影响了Position的值。
从服务器配置:
1、像主服务一样配置启用二进制日志,设置服务器唯一ID;(主服务器的server-id=1,从服务器这里的server-id=2)

2、重启MySQL并进入MySQL终端;
3、执行以下语句并启动 slave 从库:
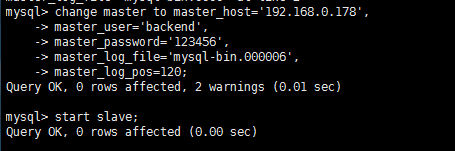
说明:这里的master_host是设置主服务器的IP,master_user是设置连接主服务器数据库的用户,master_password是该用户的密码,master_log_file和master_log_pos设置主服务器时记录下的文件和值;
4、执行 "show slave status;G" 查看slave从库状态:
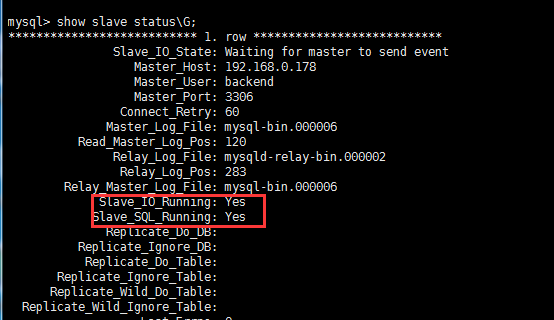
此时若Slave_IO_Running和Slave_SQL_Running都为Yes,那么说明主从配置成功了。
5、到 主数据库创建一个数据库 "create database test_master_slave;"
6、到从服务器执行 “show databases;” 发现也同时创建了数据库 test_master_slave;
注意:主从服务器和数据库版本可以不一样,但主从服务器中当前的数据库最好一致,不然后面可能会因数据库不一致而导致出现一些错误。如果出现错误,比如在主服务器删除了一个数据库,而从服务器上并没有这个数据库,那么从服务器的复制就会出错,此时应该先执行"stop slave"停止从库,然后执行“SET GLOBAL SQL_SLAVE_SKIP_COUNTER = 1;” 跳过一个事务,从而跳过那个错误。再执行“start slave”开启从库。从库便正常复制主库的操作。(SET GLOBAL SQL_SLAVE_SKIP_COUNTER = n;表示跳过n个让从库复制出错的事务)
参考:MySQL主从复制技术的简单实现 - LO-gin - 博客园
https://www.cnblogs.com/LO-gin/p/6121519.html