Autoencoders(自编码器)
一、总结
一句话总结:
a)、【无监督学习】:自编码器是一种能够通过无监督学习,学到输入数据高效表示的人工神经网络。
b)、【输出与输入数据相似生成模型】:此外,自编码器还可以随机生成与训练数据类似的数据,这被称作生成模型(generative model)。比如,可以用人脸图片训练一个自编码器,它可以生成新的图片。
1、Autoencoder 的基本概念?
①、机器学习中的监督学习和非监督学习,其中非监督学习简单来说就是学习人类没有标记过的数据。
②、对于没有标记的数据最常见的应用就是通过聚类(Clustering)的方式将数据进行分类。
③、对于这些数据来说通常有非常多的维度或者说Features。
④、如何降低这些数据的维度或者说“压缩”数据,从而减轻模型学习的负担,我们就要用到Autoencoder了。
2、Autoencoder在可视化方面的应用?
用Autoencoder 给数据“压缩”和降维不仅能够给机器“减压”,同时也有利于数据的可视化(人类只能看懂三维的数据)
3、Autoencoder和普通的神经网络的区别?
(a)、Autoencoder 实际上跟普通的神经网络没有什么本质的区别,分为输入层,隐藏层和输出层。
(b)、唯一比较特殊的是,输入层的输入feature的数量(也就是神经元的数量)要等于输出层。同时要保证输入和输出相等。看图易知。
4、Autoencoder 输入要等于输出理解?
(A)、因为输出要等于输入,所以中间的每一层都最大程度地保留了原有的数据信息,
(B)、但是由于神经元个数发生了变化,数据的维度也就发生了变化。比如上图的中间层(第三层)只有两个神经元,那么这一层输出的结果实际上就是二维的数据结构。
(C)、我们就可以用这一层的输出结果进行无监督学习分类,或者做视觉化的展示。
5、Autoencoder 的编码和解码过程?
(1)、对于Autoencoder从输入层到最中间层的数据处理过程叫做数据编码(Encode)过程,
(2)、从中间层到输出层则为解码(Decode)过程,最后保证输出等于输入。
6、Autoencoder 的3维降2维的例子说明?
一、Autoencoder 不是简单地去掉一个维度,而是通过编码的过程将数据“压缩”到二维。
二、上面只是一个非常简单的将三维数据通过Autoencoder降到二维空间,当数据的feature 太多的时候,通过Autoencoder 就可以在最大限度保留原数据的信息并降低源数据的维度。
二、Autoencoders(自编码器)
转自或参考:https://www.jianshu.com/p/eacb36e201df
Autoencoder 的基本概念
之前的文章介绍过机器学习中的监督学习和非监督学习,其中非监督学习简单来说就是学习人类没有标记过的数据。对于没有标记的数据最常见的应用就是通过聚类(Clustering)的方式将数据进行分类。对于这些数据来说通常有非常多的维度或者说Features。如何降低这些数据的维度或者说“压缩”数据,从而减轻模型学习的负担,我们就要用到Autoencoder了。
用Autoencoder 给数据“压缩”和降维不仅能够给机器“减压”,同时也有利于数据的可视化(人类只能看懂三维的数据)。
Autoencoder 实际上跟普通的神经网络没有什么本质的区别,分为输入层,隐藏层和输出层。唯一比较特殊的是,输入层的输入feature的数量(也就是神经元的数量)要等于输出层。同时要保证输入和输出相等。
结构大概就是如图所示
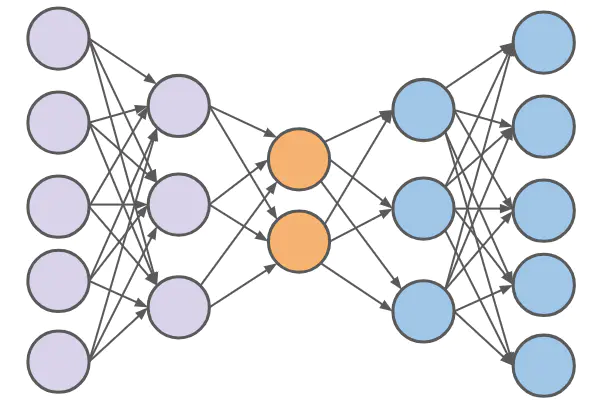
因为输出要等于输入,所以中间的每一层都最大程度地保留了原有的数据信息,但是由于神经元个数发生了变化,数据的维度也就发生了变化。比如上图的中间层(第三层)只有两个神经元,那么这一层输出的结果实际上就是二维的数据结构。我们就可以用这一层的输出结果进行无监督学习分类,或者做视觉化的展示。
简化的Autoencoder
对于Autoencoder从输入层到最中间层的数据处理过程叫做数据编码(Encode)过程,从中间层到输出层则为解码(Decode)过程,最后保证输出等于输入。
Autoencoder的隐藏层可以是多层也可以是单层,这里我用一个只有一层隐藏层的Autoencoder的实例来介绍Autoencoder.

Autoencoder实例代码
1、导入需要用到的库
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
2、创建一个三维的数据
这里用sklearn 的一个make_blobs的工具创造有两个聚集点的三维数据
from sklearn.datasets import make_blobs
data = make_blobs(n_samples=100, n_features=3,centers=2,random_state=101)
数据长这个样子

注意data[0]是100x3的数据(100个点,3个features(维度))
3. 搭建神经网络
下面用Tensorflow Layers来搭一个三层的全连接的神经网路,输入层,隐藏层和输出层的神经元个数分别是3,2,3。
import tensorflow as tf
from tensorflow.contrib.layers import fully_connected
num_inputs = 3 # 3 dimensional input
num_hidden = 2 # 2 dimensional representation
num_outputs = num_inputs # Must be true for an autoencoder!
learning_rate = 0.01
Placeholder,Layers,Loss Function 和 Optimizer
#Placeholder
X = tf.placeholder(tf.float32, shape=[None, num_inputs])
#Layers
hidden = fully_connected(X, num_hidden, activation_fn=None)
outputs = fully_connected(hidden, num_outputs, activation_fn=None)
#Loss Function
loss = tf.reduce_mean(tf.square(outputs - X)) # MSE
#Optimizer
optimizer = tf.train.AdamOptimizer(learning_rate)
train = optimizer.minimize( loss)
#Init
init = tf.global_variables_initializer()
4. 训练神经网络
num_steps = 1000
with tf.Session() as sess:
sess.run(init)
for iteration in range(num_steps):
sess.run(train,feed_dict={X: scaled_data})
# Now ask for the hidden layer output (the 2 dimensional output)
output_2d = hidden.eval(feed_dict={X: scaled_data})
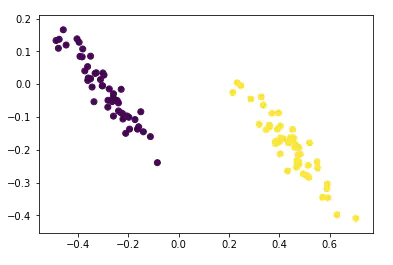
注意:output_2d就是中间层输出的结果,这是一个二维(100x2)的数据。
这个数据长这个样子
4.总结
从上面的例子可以看到,Autoencoder 不是简单地去掉一个维度,而是通过编码的过程将数据“压缩”到二维。这些数据通过解码过程可以再次在输出层输出三维的数据,并且保留了元数据的两个积聚点。
上面只是一个非常简单的将三维数据通过Autoencoder降到二维空间,当数据的feature 太多的时候,通过Autoencoder 就可以在最大限度保留原数据的信息并降低源数据的维度。