如何通过一顿饭来说明NumPy与pandas的功用
一、总结
一句话总结:
NumPy:大数据量的纯粹数组处理,以及复杂函数和线性代数等
Pandas:处理非纯粹的、混杂数组
虽然NumPy有着以上的种种出色的特性,其本身则难以独支数据分析这座大厦,这是一方面是由于NumPy几乎仅专注于数组处理,
另一方面则是数据分析牵涉到的数据特性众多,需要处理各种表格和混杂数据,远非纯粹的数组(NumPy)方便解决的,而这就是pandas发力的地方。
1、Numpy在数据分析方面的缺点?
数据分析牵涉到的数据特性众多需要处理各种表格和混杂数据,远非纯粹的数组(NumPy)方便解决的
虽然NumPy有着以上的种种出色的特性,其本身则难以独支数据分析这座大厦,这是一方面是由于NumPy几乎仅专注于数组处理,
另一方面则是数据分析牵涉到的数据特性众多,需要处理各种表格和混杂数据,远非纯粹的数组(NumPy)方便解决的,而这就是pandas发力的地方。
2、NumPy在大数组的数据处理方面进行的优化?
a、【连续的内存块】:NumPy是在一个连续的内存块中存储数据,独立于其他Python内置对象,如此便可以加速数据索引的速度。
b、【调用大量c语言算法库】:NumPy调用了大量的用C语言编写的算法库,使得其可以直接操作内存,不必进行Python动态语言特性所含有的前期类型检查工作,从而大大提高了运算速度。
c、【整数组直接计算】:NumPy所有独有的可以在整个数组上执行复杂的计算也能够大幅提高运算效率(基于NumPy的算法要比纯Python快10到100倍,甚至会快更多)。
3、上百G的数据如何处理?
Python处理几个G的数据绰绰有余,至于几十G也勉强可以,而上百G的数据这就算是Hadoop与Spark系列的任务,不是Python的NumPy与pandas可以应付的,也不是R语言某个第三方包可以处理的。
4、NumPy 的其它高级特性?
【广播功能快速对不同形状的矩阵进行计算】:指定数组存储的行优先或者列优先,广播功能从而快速的对不同形状的矩阵进行计算
【丢开循环】:ufunc类型的函数可以使得我们丢开循环而编写出更为简洁也更有效率的代码
【GPU计算】:使用开源项目Numba编写快速的NumPy函数,而Numba则是可以利用GPU进行运算的。
NumPy除了在相当程度上优化了Python计算过程,其自身还有较多的高级特性,如指定数组存储的行优先或者列优先、广播功能从而快速的对不同形状的矩阵进行计算、ufunc类型的函数可以使得我们丢开循环而编写出更为简洁也更有效率的代码、使用开源项目Numba编写快速的NumPy函数,而Numba则是可以利用GPU进行运算的。
5、pandas在数据操作方面的主要作用?
pandas 含有使数据清洗和分析工作变得更快更简单的数据结构与操作工具
6、pandas数据操作方面作用的形象比喻?
如果用做一餐饭来比喻,pandas于处理数据方面的功用则相当于将米洗好,将菜摘好洗好以及切好的过程,至于入锅添油加醋,锅铲捣腾,
做成一道菜则是依靠statsmodels、scikit-learn和matplotlib的功能。
7、pandas的时间序列类函数的意义?
A、pandas的时间序列类函数,可以说是pandas让处理时间序列数据变得得心应手。
B、第三方包datetime与dateutil能够将识别与处理多种时间格式,pandas自身可以生成指定频率的DatetimeIndex,也可以处理时区信息。
C、其移动窗口函数则是大大方便了时间序列分析,使得建立各种AR、MA、ARMA、ARIMA等等时间序列模型方便快捷,而这正是R语言的领地。
二、如何通过一顿饭来说明NumPy与pandas的功用
转自或参考:如何通过一顿饭来说明NumPy与pandas的功用
https://baijiahao.baidu.com/s?id=1611201377250719874&wfr=spider&for=pc
谈到数据分析,则离不开谈及R语言及R语言与Python在数据分析领域孰优孰劣之争。
首先R语言作为正统统计学软件,数据分析则是其应有之义,因而相比于Python这个在数据分析领域的新起之秀,R语言算是与Matlab、SAS在同一起跑线上。
后发优势毕竟是可观的,当Python开始涉足数据分析领域时,其便渐渐形成了与R语言分庭抗礼的趋势。而在这股势力中,其主角及成员便是NumPy、pandas、matplotlib以及scipy。本文要简单介绍的则是主力中的主力:NumPy与pandas。
诚然,R语言几乎专注于统计分析,其第三方包无数,有着统计学的深度以及各学科统计分析应用的广度,并且也在与Python的较量中不甘示弱。但是,有着更深的互联网基因的Python毕竟要比更有统计学深度的R语言更受互联网公司数据分析师的喜爱。

上图展示了NumPy、pandas(以及matplotlib)的历史总共下载量等信息。可以看出,两者总共有过近80万的下载量,如果按照市场价值计量,两者合计价值近1500万美元,但它们都可以免费使用。
纵然NumPy与pandas风靡于数据分析任务,人们对其的不足也多有指出,其中最主要的便是由于Python自身的动态语言特性而带来的运行速度方面的损失,其次便是Python在大数据处理方面(数G甚至几十上百G)的捉襟见肘。
对于前者,NumPy已经做了相当程度的优化,可以对大数组的数据进行高效处理。优化包括NumPy是在一个连续的内存块中存储数据,独立于其他Python内置对象,如此便可以加速数据索引的速度。其次,NumPy调用了大量的用C语言编写的算法库,使得其可以直接操作内存,不必进行Python动态语言特性所含有的前期类型检查工作,从而大大提高了运算速度。最后,NumPy所有独有的可以在整个数组上执行复杂的计算也能够大幅提高运算效率(基于NumPy的算法要比纯Python快10到100倍,甚至会快更多)。
而对于后者,经过合理的优化,Python处理几个G的数据绰绰有余,至于几十G也勉强可以,而上百G的数据这就算是Hadoop与Spark系列的任务,不是Python的NumPy与pandas可以应付的,也不是R语言某个第三方包可以处理的。
NumPy除了在相当程度上优化了Python计算过程,其自身还有较多的高级特性,如指定数组存储的行优先或者列优先、广播功能从而快速的对不同形状的矩阵进行计算、ufunc类型的函数可以使得我们丢开循环而编写出更为简洁也更有效率的代码、使用开源项目Numba编写快速的NumPy函数,而Numba则是可以利用GPU进行运算的。
虽然NumPy有着以上的种种出色的特性,其本身则难以独支数据分析这座大厦,这是一方面是由于NumPy几乎仅专注于数组处理,另一方面则是数据分析牵涉到的数据特性众多,需要处理各种表格和混杂数据,远非纯粹的数组(NumPy)方便解决的,而这就是pandas发力的地方。
pandas 这个名称来源于panel data(面板数据),从而可见其要处理的数据是多维度的而非单维度。pandas 含有使数据清洗和分析工作变得更快更简单的数据结构与操作工具。经常是和其他工具一起使用,如数值计算工具NumPy和SciPy,分析库statsmodels与scikit-learn,以及数据可视化库matplotlib。其中NumPy则是构建pandas的基础,后者大量借鉴了NumPy编码风格。
如果用做一餐饭来比喻,pandas于处理数据方面的功用则相当于将米洗好,将菜摘好洗好以及切好的过程,至于入锅添油加醋,锅铲捣腾,做成一道菜则是依靠statsmodels、scikit-learn和matplotlib的功能。
pandas功能特性广泛,其包含的函数类型也众多,数据结构有Series与DataFrame,函数类型有索引函数、汇总函数、加载以及保存众多文件格式函数、与数据库交互函数、字符串处理函数、缺失数据处理函数、合并重塑轴向旋转表格型数据函数、简单的绘图函数、数据聚合(groupby)分组运算(apply)函数、透视表交叉表函数以及时间序列处理方面的各种函数。
由于类型过多,不便历述,下面便从上述选择几个对象来说。其中Series处理的是单列数据,其格式如下所示:

0,1,2,3是索引,4,7,-5,3是值,索引可以自行指定的。
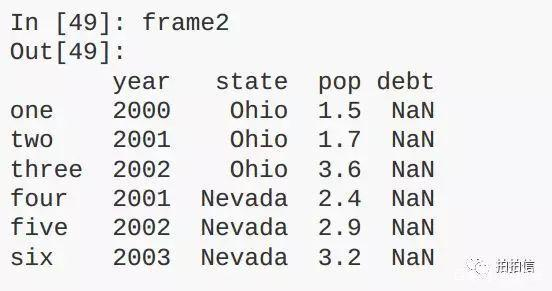
而DataFrame是一个表格型的数据结构,它含有一组有序的列,每一列可以是不同的值类型(数值、字符串布尔值等),DataFrame既有行索引也有列索引,可以被看做是由Series组成的字典(共用同一个索引),如:
pandas可以读取较多类型的文件格式,从简单的txt、csv、json到excel,hdf5、pickle再到sas、sql、stata等等文件格式都有得以支持。在读取数据时,函数会使用到若干技术将数据转换成DataFrame格式,如索引、类型推断和数据转换、日期解析、迭代与不规整数据问题等。
至于pandas与数据库交互,它可以通过特定的第三方包实现将SQL Server、 PostgreSQL和MySQL数据库中的数据加载到DataFrame中,然后进行各种处理分析。
pandas自带的绘图函数较为简陋,只有简单的plot函数,不过Series或者DataFrame格式的数据可以与matplotlib以及seaborn等绘图工具结合以绘制各类精致的图例。
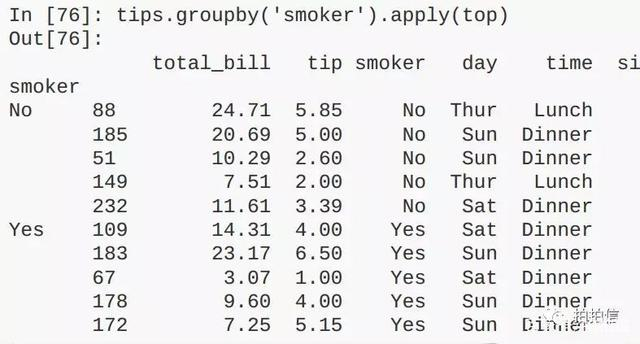
由于表格型数据往往是有类别属性的,如班级学生的各科成绩,班级、学生性别等都是类别属性,所以数据聚合(groupby)分组运算(apply)函数则是相当重要的,其使用示例如下:

最后分享的是pandas的时间序列类函数,可以说是pandas让处理时间序列数据变得得心应手。第三方包datetime与dateutil能够将识别与处理多种时间格式,pandas自身可以生成指定频率的DatetimeIndex,也可以处理时区信息。其移动窗口函数则是大大方便了时间序列分析,使得建立各种AR、MA、ARMA、ARIMA等等时间序列模型方便快捷,而这正是R语言的领地。
Python因为有了NumPy与pandas而不同于Java、C#等程序语言,Python也因为NumPy与pandas而又一次的焕发了光彩。NumPy与pandas也许多少借鉴了R语言的特性与功能,但它也的确做的了在某些方面青出于蓝胜于蓝。