pandas中Series和DataFrame的区别与联系(总结)
一、总结
一句话总结:
series,只是一个一维数据结构,它由index和value组成。
dataframe,是一个二维结构,除了拥有index和value之外,还拥有column。
二、pandas中Series()和DataFrame()的区别与联系(总结)
1、pandas中Series()和DataFrame()的区别与联系
区别:
series,只是一个一维数据结构,它由index和value组成。
dataframe,是一个二维结构,除了拥有index和value之外,还拥有column。
联系:
dataframe由多个series组成,无论是行还是列,单独拆分出来都是一个series。
1 import numpy as np 2 import pandas as pd 3 from pandas import Series, DataFrame 4 5 data = {'Country':['Belgium', 'India', 'Brazil'], 6 'Capital':['Brussels', 'New Delhi', 'Brasilia'], 7 'Population':[11190846, 1303171035, 207847528] 8 } 9 10 # Series 11 12 s1 = Series(data['Country']) 13 print(s1) 14 ''' 15 0 Belgium 16 1 India 17 2 Brazil 18 dtype: object 19 ''' 20 print(s1.values) # 类型: <class 'numpy.ndarray'> 21 ''' 22 ['Belgium' 'India' 'Brazil'] 23 ''' 24 print(s1.index) 25 ''' 26 RangeIndex(start=0, stop=3, step=1) 27 ''' 28 29 # 为Series指定index 30 s1 = Series(data['Country'], index=['A', 'B', 'C']) 31 print(s1) 32 ''' 索引更改 33 A Belgium 34 B India 35 C Brazil 36 dtype: object 37 ''' 38 39 40 # Dataframe 41 42 df1 = pd.DataFrame(data) 43 print(df1) 44 ''' 45 Capital Country Population 46 0 Brussels Belgium 11190846 47 1 New Delhi India 1303171035 48 2 Brasilia Brazil 207847528 49 ''' 50 51 print(df1['Capital']) # 类型: series 52 ''' 53 0 Brussels 54 1 New Delhi 55 2 Brasilia 56 Name: Capital, dtype: object 57 ''' 58 59 60 print(df1.iterrows()) # 返回 一个 生成器 <generator object DataFrame.iterrows at 0x7f226a67b728> 61 62 for row in df1.iterrows(): 63 print(row) 64 print(row[0], row[1]) 65 print(type(row[0]), type(row[1])) 66 break 67 ''' 68 print(row) 返回了一个元组 69 (0, Capital Brussels 70 Country Belgium 71 Population 11190846 72 Name: 0, dtype: object) 73 ''' 74 ''' 75 print(row[0], row[1]) 的返回值 76 0 Capital Brussels 77 Country Belgium 78 Population 11190846 79 Name: 0, dtype: object 80 ''' 81 ''' 82 print(type(row[0]), type(row[1])) 83 <class 'int'> <class 'pandas.core.series.Series'> 84 85 row[1] 是一个 series,而且原来的列名,现在变成了现在的索引名, 86 由此可见,dataframe是由多个行列交错的series组成。 87 ''' 88 89 # 现在可以 构建几个series 90 s1 = pd.Series(data['Country']) 91 s2 = pd.Series(data['Capital']) 92 s3 = pd.Series(data['Population']) 93 df_new = pd.DataFrame([s1, s2, s3], index=['Country', 'Captital', 'Population']) 94 print(df_new) 95 ''' 96 0 1 2 97 Country Belgium India Brazil 98 Captital Brussels New Delhi Brasilia 99 Population 11190846 1303171035 207847528 100 101 可以看到,行 和 列 都是颠倒的,因此需要进行一下转置 102 ''' 103 104 print(df_new.T) 105 ''' 106 Country Captital Population 107 0 Belgium Brussels 11190846 108 1 India New Delhi 1303171035 109 2 Brazil Brasilia 207847528 110 111 ''' 112 113 ''' 114 总结: 115 series, 就是一个 一维 的数据结构,它是由 index 和 value 组成。 116 dataframe, 是一个 二维 数据结构,它由多个 series 构成。 117 '''
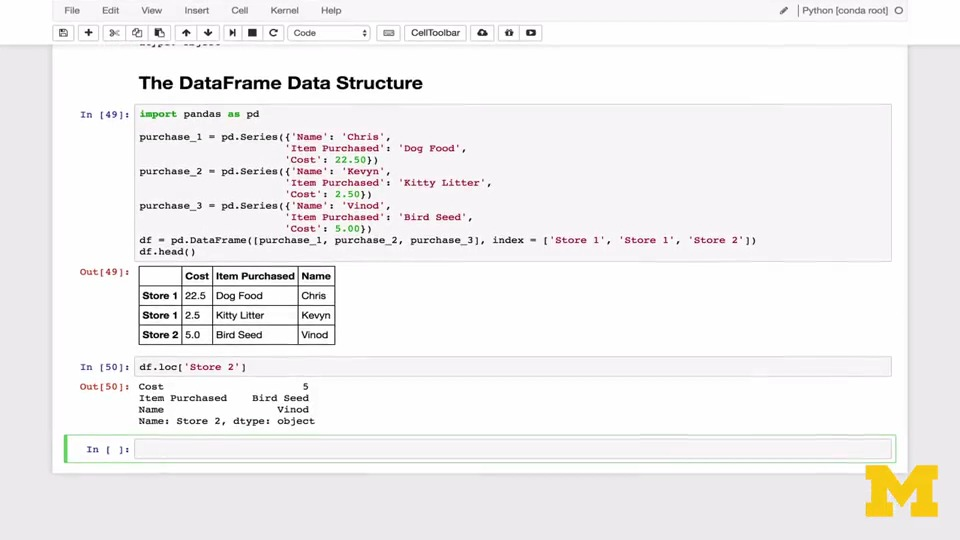
2、结合图更加直观 的理解

series结构有索引,和列名组成,如果没有,那么程序会自动赋名为None
series的索引名具有唯一性,索引可以数字和字符,系统会自动将他们转化为一个类型object。

dataframe由索引和列名组成,索引不具有唯一性,列名也不具有唯一性
参考:
pandas中series和dataframe之间的区别 - 月下林白 - 博客园
https://www.cnblogs.com/shadow1/p/10235543.html
pandas中Series()和DataFrame()的区别与联系
https://blog.csdn.net/missyougoon/article/details/83301712
https://blog.csdn.net/missyougoon/article/details/83301712