举个简单的例子,当我们要实现一个这样的计算图时:

用TensorFlow是这样的:
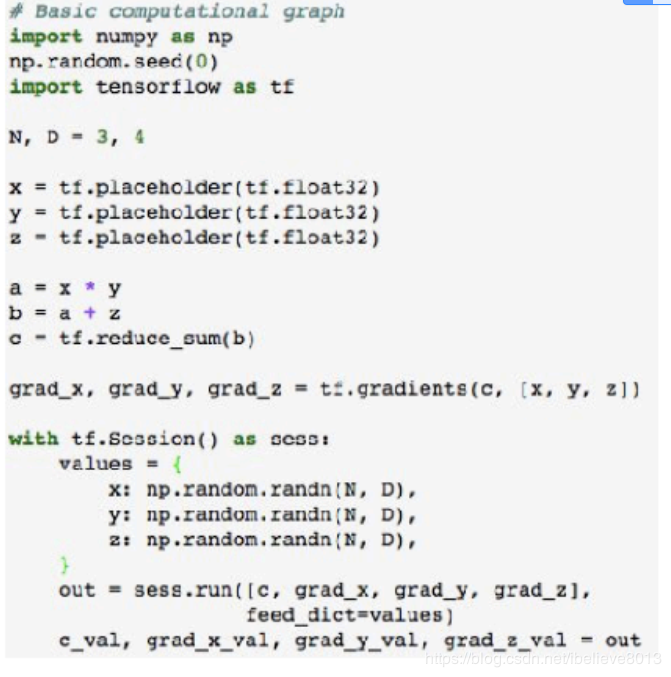
而用pytorch是这样的:

当然,里面都包含了建立前向计算图,传入变量数据,求梯度等操作,但是显而易见,pytorch的代码更为凝练。TensorFlow我也用得比较少,我本文重点说说pytorch的一些学习心得,一是总结,而是若有缘人能看见此文,也能当个参考。
其实一个好的框架应该要具备三点:对大的计算图能方便的实现;能自动求变量的导数;能简单的运行在GPU上;pytorch都做到了,但是现在很多公司用的都是TensorFlow,而pytorch由于比较灵活,在学术科研上用得比较多一点。鄙人认为可能,Google可能下手早一些,而Facebook作后来者,虽然灵活,但是很多公司已经入了TensorFlow的坑了,要全部迁移出来还是很费功夫;而且,TensorFlow在GPU的分布式计算上更为出色,在数据量巨大时效率比pytorch要高一些,我觉得这个也是一个重要的原因吧。
好的,不闲扯了。pytorch的一些心得,我总结一下:
首先,pytorch包括了三个层次:tensor,variable,Module。tensor,即张量的意思,由于是矩阵的运算,十分适合在GPU上跑。但是这样一个tensor为什么还不够呢?要搞出来一个variable,其实variable只是tensor的一个封装,这样一个封装,最重要的目的,就是能够保存住该variable在整个计算图中的位置,详细的说:能够知道计算图中各个变量之间的相互依赖关系。什么,你问这有什么用?当然是为了反向求梯度了;而Module,是一个更高的层次,如果使用这个Module,那可厉害了,这是一个神经网络的层次,可以直接调用全连接层,卷积层,等等神经网络。
转自:https://blog.csdn.net/ibelieve8013/article/details/84261482