快速幂
50. Pow(x, n)
实现 pow(x, n) ,即计算
x的n次幂函数(即,xn)。
快速幂解析(分治法角度):
快速幂实际上是分治思想的一种应用。

观察发现,当 n 为奇数时,二分后会多出一项 x 。
-
幂结果获取:

-
转化为位运算:
向下整除 n // 2等价于 右移一位 n>>1 ;
取余数 n%2 等价于 判断二进制最右位 n&1 ;
代码如下:
public double myPow(double x, int n) {
// 快速幂,二分分治法
if (n == 0) {
return (double)1;
}
// 因为n是[-2147483648,2147483647],所以如果k<0,转成正数之后就超出了范围,所以转成long类型
long k = n;
double res = 1.0;
if (k < 0) {
k = -k;
x = 1/x;
}
while (k > 0) {
if ((k & 1) == 1) {
res *= x;
}
x *= x;
k = k >> 1;
}
return res;
}
矩阵
73. 矩阵置零
给定一个
*m* x *n*的矩阵,如果一个元素为 0 ,则将其所在行和列的所有元素都设为 0 。请使用 原地 算法。
- 第一个思路是遇到0把该行该列所有不是0的都变成唯一的额外值,然后遍历完之后把所有的变成0即可;但是这里的是整形不好转成一个额外的唯一值
- 第二个思路:先二重循环通过hashSet记录0所在的行和列,然后把这些行和列的值都变成0,空间复杂度O(m+n)
- 第三个思路:通过第一行和第一列来当做标记数组,通过两个标记位标记第一个行第一列是否有0,然后遍历第一行第一列之外的行列,如果对应有0,反向对标技数组标记位0,然后再利用标记数组对对应的行列赋值
我使用的第二个思路:
代码如下:
public void setZeroes(int[][] matrix) {
// 第一个思路是遇到0把该行该列所有不是0的都变成唯一的额外值*,然后遍历完之后把所有的*变成0即可;但是这里的是整形不好转成一个额外的唯一值
// 第二个思路:先二重循环通过hashSet记录0所在的行和列,然后把这些行和列的值都变成0,空间复杂度O(m+n)
// 第三个思路:通过第一行和第一列来当做标记数组,通过两个标记位标记第一个行第一列是否有0,然后遍历第一行第一列之外的行列,如果对应有0,反向对标技数组标记位0,然后再利用标记数组对对应的行列赋值
int m = matrix.length;
int n = matrix[0].length;
Set<Integer> rowSet = new HashSet<>();
Set<Integer> colSet = new HashSet<>();
// 这里利用第二个思路:先二重循环通过hashSet记录0所在的行和列,然后把这些行和列的值都变成0,空间复杂度O(m+n)
for (int i = 0;i < m;i++) {
for (int j = 0;j < n;j++) {
if (matrix[i][j] == 0) {
rowSet.add(i);
colSet.add(j);
}
}
}
for (int row:rowSet) {
Arrays.fill(matrix[row],0);
}
for (int col:colSet) {
for (int k = 0;k < m;k++) {
matrix[k][col] = 0;
}
}
}
79. 单词搜索
给定一个 m x n 二维字符网格 board 和一个字符串单词 word 。如果 word 存在于网格中,返回 true ;否则,返回 false 。
单词必须按照字母顺序,通过相邻的单元格内的字母构成,其中“相邻”单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母不允许被重复使用。
思路:
回溯,DFS,利用visited数组标记已访问的位置,防止重复访问
代码如下:
class Solution {
boolean[][] visited;
char[] wordCopy;
char[][] boardCopy;
int[][] dierction = {{-1,0},{0,1},{1,0},{0,-1}};
int m,n;
public boolean exist(char[][] board, String word) {
m = board.length;
n = board[0].length;
int index = 0;
visited = new boolean[m][n];
wordCopy = word.toCharArray();
boardCopy = board;
for (int i = 0;i < m;++i) {
for (int j = 0;j < n;++j) {
if (backTrack(i,j,0)) {
return true;
}
}
}
return false;
}
// 利用回溯算法,begin:当前指向的word的位置
private boolean backTrack(int x,int y,int begin) {
// 递归结束条件:指向到了word的末尾
if (begin == wordCopy.length - 1) {
return boardCopy[x][y] == wordCopy[begin];
}
if (boardCopy[x][y] != wordCopy[begin]) {
return false;
}
// 通过visited数组标记已访问过,防止重复访问
visited[x][y] = true;
// 遍历四个方向的选择
for (int i = 0;i < dierction.length;i++) {
int newX = x + dierction[i][0];
int newY = y + dierction[i][1];
if (!isValid(newX,newY,m,n) || visited[newX][newY]) {
continue;
}
if (backTrack(newX,newY,begin+1)) {
return true;
}
}
// 访问过后如果找不到正确的路线,重新标记为未访问过
visited[x][y] = false;
return false;
}
// 判断是否越界
private boolean isValid(int x,int y,int m,int n) {
return ((x >= 0 && x < m) && (y >= 0 && y < n));
}
}
48. 旋转图像
给定一个 n × n 的二维矩阵 matrix 表示一个图像。请你将图像顺时针旋转 90 度。
你必须在 原地 旋转图像,这意味着你需要直接修改输入的二维矩阵。请不要 使用另一个矩阵来旋转图像。
思路:
先沿着对角线反转,然后反转每一行,就相当于顺时针翻转矩阵
代码如下:
public void rotate(int[][] matrix) {
// 思路:先沿着对角线反转,然后反转每一行,就相当于顺时针翻转矩阵
int n = matrix.length;
if (n == 1) {
return;
}
// 先沿着对角线反转
for (int i = 0;i < n;i++) {
for (int j = i;j < n;j++) {
int temp = matrix[i][j];
matrix[i][j] = matrix[j][i];
matrix[j][i] = temp;
}
}
// 翻转每一行
for (int[] row:matrix) {
reverse(row);
}
}
private void reverse(int[] row) {
int left = 0,right = row.length-1;
while (left < right) {
int temp = row[left];
row[left] = row[right];
row[right] = temp;
left++;
right--;
}
}
378. 有序矩阵中第 K 小的元素
给你一个 n x n 矩阵 matrix ,其中每行和每列元素均按升序排序,找到矩阵中第 k 小的元素。
请注意,它是 排序后 的第 k 小元素,而不是第 k 个 不同 的元素。
思路(二分查找)
总体思路:二分查找;矩阵左上角的值是最小值,矩阵右下角的值是最大值,取中间值,然后判断该中间值左上角的数的个数有没有超过k,如果超过,想要的数就在中间值的左上角,继续二分,否则就在中间值的右下角
判断该中间值左上角的数的个数有没有超过k的时候每次从左下角开始判断比较
代码如下:
public int kthSmallest(int[][] matrix, int k) {
// 总体思路:二分查找;矩阵左上角的值是最小值,矩阵右下角的值是最大值,取中间值,然后判断该中间值左上角的数的个数有没有超过k,如果超过,想要的数就在中间值的左上角,继续二分,否则就在中间值的右下角
int n = matrix.length;
// 矩阵左上角的值是最小值,矩阵右下角的值是最大值
int left = matrix[0][0];
int right = matrix[n - 1][n - 1];
while (left < right) {
int mid = left + (right - left) / 2;
// 判断该中间值左上角的数的个数有没有超过k
if (check(matrix,mid,k,n)) {
right = mid;
} else {
left = mid + 1;
}
}
return left;
}
private boolean check(int[][] matrix,int mid,int k,int n) {
// 判断该中间值左上角的数的个数有没有超过k
int num = 0;
// 每次从左下角开始判断比较
int i = n - 1;
int j = 0;
while(i >= 0 && j < n) {
// 如果当前值小于等于mid,那么该数值对应列的上边都比mid小
if (matrix[i][j] <= mid) {
num += i + 1;
j++;
} else {
// 如果当前值比mid大,那么就要看该数值上边的行做判断比较
i--;
}
}
return num >= k;
}
大顶堆,小顶堆
一个小顶堆可以搜索前k大的数,一个大顶堆可以搜索前k小的数
347. 前 K 个高频元素
给你一个整数数组 nums 和一个整数 k ,请你返回其中出现频率前 k 高的元素。你可以按 任意顺序 返回答案。
思路:
利用小顶堆,因为要统计最大前k个元素,只有小顶堆每次将最小的元素弹出,最后小顶堆里积累的才是前k个最大元素。先利用map统计频数,然后把map元素遍历放入到小顶堆里,这里要对PriorityQueue自定义排序规则,根据map的value正序排序
代码如下:
public int[] topKFrequent(int[] nums, int k) {
/**
利用小顶堆,因为要统计最大前k个元素,只有小顶堆每次将最小的元素弹出,最后小顶堆里积累的才是前k个最大元素。
*/
Map<Integer,Integer> map = new HashMap<>();
// 先利用map统计每个数出现的频率
for (int i = 0;i<nums.length;i++) {
map.put(nums[i],map.getOrDefault(nums[i],0)+1);
}
Set<Map.Entry<Integer,Integer> > entries = map.entrySet();
// 小顶堆,// 根据map的value值正序排,相当于一个小顶堆
PriorityQueue<Map.Entry<Integer, Integer>> pq = new PriorityQueue<>((o1,o2) -> o1.getValue() - o2.getValue());
for (Map.Entry<Integer,Integer> entry:entries) {
pq.offer(entry);
if (pq.size() > k) {
pq.poll();
}
}
int[] res = new int[k];
for (int i = 0;i<k;i++) {
res[i] = pq.poll().getKey();
}
return res;
}
4. 寻找两个正序数组的中位数
给定两个大小分别为 m 和 n 的正序(从小到大)数组 nums1 和 nums2。请你找出并返回这两个正序数组的 中位数 。
算法的时间复杂度应该为 O(log (m+n)) 。
思路:
通过两个优先级队列实现,大顶堆存放的数据要小于小顶堆存放的数据,只要保证小顶堆顶部的数据(最大值)小于小顶堆顶部的数据(最小值)就可以了;
同时要满足两个堆的数量差不能大于1,所以在插入的时候要判断K,如果是偶数,插入到小顶堆(先插入到大顶堆,然后poll出大顶堆的顶部数据,添加到小顶堆中);如果k是奇数,插入到大顶堆(先插入到小顶堆,然后poll出小顶堆的顶部数据,添加到大顶堆中),最后根据数组长度之和是否是偶数,如果是偶数取两个堆的顶部数据的一半,如果是奇数,取小顶堆的顶部数据,因为在最后一次遍历的时候k是偶数,然后k++之后k才是奇数退出循环,所以最后一次添加到的是小顶堆right
代码如下:
public double findMedianSortedArrays(int[] nums1, int[] nums2) {
// 通过两个优先级队列实现,大顶堆存放的数据要小于小顶堆存放的数据,只要保证小顶堆顶部的数据(最大值)小于小顶堆顶部的数据(最小值)就可以了
// 同时要满足两个堆的数量差不能大于1,所以在插入的时候要判断K,如果是偶数,插入到小顶堆(先插入到大顶堆,然后poll出大顶堆的顶部数据,添加到小顶堆中);如果k是奇数,插入到大顶堆(先插入到小顶堆,然后poll出小顶堆的顶部数据,添加到大顶堆中),最后根据数组长度之和是否是偶数,如果是偶数取两个堆的顶部数据的一半,如果是奇数,取小顶堆的顶部数据,因为在最后一次遍历的时候k是偶数,然后k++之后k才是奇数退出循环,所以最后一次添加到的是小顶堆right
// 大顶堆
PriorityQueue<Integer> left = new PriorityQueue<Integer>((o1,o2) ->(o2 - o1));
// 小顶堆,初始化默认是小顶堆
PriorityQueue<Integer> right = new PriorityQueue<Integer>();
int K = 0;
for (int i = 0;i < nums1.length;i++) {
// 如果是偶数,插入到小顶堆(先插入到大顶堆,然后poll出大顶堆的顶部数据,添加到小顶堆中)
if (K % 2 == 0) {
left.add(nums1[i]);
right.add(left.poll());
} else {
// 如果k是奇数,插入到大顶堆(先插入到小顶堆,然后poll出小顶堆的顶部数据,添加到大顶堆中)
right.add(nums1[i]);
left.add(right.poll());
}
K++;
}
for (int i = 0;i < nums2.length;i++) {
if (K % 2 == 0) {
left.add(nums2[i]);
right.add(left.poll());
} else {
right.add(nums2[i]);
left.add(right.poll());
}
K++;
}
if (K % 2 == 0) {
return (double) (left.peek() + right.peek()) / 2;
}
// 因为在最后一次遍历的时候k是偶数,然后k++之后k才是奇数退出循环,所以最后一次添加到的是小顶堆right
return right.peek();
}
378. 有序矩阵中第 K 小的元素
给你一个 n x n 矩阵 matrix ,其中每行和每列元素均按升序排序,找到矩阵中第 k 小的元素。
请注意,它是 排序后 的第 k 小元素,而不是第 k 个 不同 的元素。
思路
总体思路:利用小顶堆,先将每一行的第一个数存放到小顶堆里,然后每次从小顶堆里取堆顶的最小值,然后将该行的下一列的值放入队列里,直到拿到K-1个数,最后第K个数就是小顶堆的堆顶的数
代码如下:
class Solution {
public int kthSmallest(int[][] matrix, int k) {
// 总体思路:利用小顶堆,先将每一行的第一个数存放到小顶堆里,然后每次从小顶堆里取堆顶的最小值,然后将该行的下一列的值放入队列里,直到拿到K-1个数,最后第K个数就是小顶堆的堆顶的数
int m = matrix.length;
int n = matrix[0].length;
// 优先级队列里的数组array:array[0]存放数值,array[1]存放在矩阵中的行数,array[2]存放在矩阵中的列数
PriorityQueue<int[] > pq = new PriorityQueue<>((int[] a,int[] b) -> {
return a[0] - b[0];
});
for (int i = 0;i < m;i++) {
pq.offer(new int[]{matrix[i][0],i,0});
}
// 每次从小顶堆里取堆顶的最小值,然后将该行的下一列的值放入队列里,直到拿到K-1个数,最后第K个数就是小顶堆的堆顶的数,直接返回堆顶的数
for (int i = 0;i < k - 1;i++) {
int[] now = pq.poll();
// 如果该行已经到了最右边,就不往后移动不用考虑该行了
if (now[2] != n - 1) {
int nowI = now[1];
int nowJ = now[2];
pq.offer(new int[]{matrix[nowI][nowJ + 1],nowI,nowJ + 1});
}
}
// 最后第K个数就是小顶堆的堆顶的数,直接返回堆顶的数
return pq.poll()[0];
}
}
回文子串
5. 最长回文子串
双指针写法
代码如下:
public String longestPalindrome(String s) {
// 双指针写法
if (s.length() <= 1) {
return s;
}
int n = s.length();
String res = "";
for (int i = 0;i < n;i++) {
// 以 s[i] 为中心的最长回文子串
String s1 = palindrome(s,i,i);
// 以 s[i] 和 s[i+1] 为中心的最长回文子串
String s2 = palindrome(s,i,i+1);
// 获取最长的
res = res.length() < s1.length() ?s1:res;
res = res.length() < s2.length() ?s2:res;
}
return res;
}
// 返回以 s[left] 和 s[right] 为中心的最长回文串
private String palindrome(String s,int left,int right) {
// 利用双指针防止索引越界
while (left >= 0 && right < s.length() && s.charAt(left) == s.charAt(right)) {
// 向两边展开
left--;
right++;
}
return s.substring(left+1,right);
}
动态规划写法
代码如下:
public String longestPalindrome(String s) {
// 动态规划方法
if (s.length() <= 1) {
return s;
}
int n = s.length();
// dp[i][j] 表示i...j区间是否是回文子串
boolean[][] dp = new boolean[n][n];
for (int i = 0;i < n;i++) {
dp[i][i] = true;
}
// 因为dp[i][j] 会依赖于dp[i+1][j-1],所以要从下往上,从左往右遍历
for (int i = n-2;i >= 0;i--) {
for (int j = i+1;j < n;j++) {
// 如果i和j位置的字符相同,判断i和j是否相邻或者中间间隔一个元素,这样的情况i...j可以为回文子串,如果不满足前面的情况,但是i+1...j-1时回文子串,那i...j也是回文子串
if (s.charAt(i) == s.charAt(j)) {
if ((j == i + 1) || (j == i + 2) || (j > i + 2 && dp[i+1][j-1])) {
dp[i][j] = true;
}
}
}
}
int left = 0;
int right = 0;
// 比较计算最长的回文子串
for (int i = 0;i < n-1;i++) {
for (int j = i+1;j < n;j++) {
if (dp[i][j]) {
if (j - i > right - left) {
right = j;
left = i;
}
}
}
}
return s.substring(left,right+1);
}
双指针
75. 颜色分类
给定一个包含红色、白色和蓝色,一共 n 个元素的数组,原地对它们进行排序,使得相同颜色的元素相邻,并按照红色、白色、蓝色顺序排列。
此题中,我们使用整数 0、 1 和 2 分别表示红色、白色和蓝色。
思路:
双指针解法,时间复杂度O(n),p0表示指向0放置的最后位置的指针,p1表示指向1放置的最后位置的指针;
- 遇到1,将nums[i]和p1位置上的数值交换
- 遇到0,将nums[i]和p0位置上的数值交换;如果p0<p1,那么p0当前的位置上的值原来可能是1,上边把1交换到了nums[i]的位置上了,要把nums[i]上的1交换到p1的位置上,无论p0是否<p1,两个指针都要后移
代码如下:
public void sortColors(int[] nums) {
// Arrays.sort(nums);
// 双指针解法,时间复杂度O(n),p0表示指向0放置的最后位置的指针,p1表示指向1放置的最后位置的指针
int p0 = 0,p1 = 0;
for (int i = 0;i < nums.length;i++) {
// 遇到1,将nums[i]和p1位置上的数值交换
if (nums[i] == 1) {
int temp = nums[i];
nums[i] = nums[p1];
nums[p1] = temp;
p1++;
} else if (nums[i] == 0) {
// 遇到0,将nums[i]和p0位置上的数值交换
int temp = nums[i];
nums[i] = nums[p0];
nums[p0] = temp;
// 如果p0<p1,那么p0当前的位置上的值原来可能是1,上边把1交换到了nums[i]的位置上了,要把nums[i]上的1交换到p1的位置上
if (p0 < p1) {
temp = nums[i];
nums[i] = nums[p1];
nums[p1] = temp;
}
// 无论p0是否<p1,两个指针都要后移
p0++;
p1++;
}
}
}
三指针
88. 合并两个有序数组
给你两个按 非递减顺序 排列的整数数组 nums1 和 nums2,另有两个整数 m 和 n ,分别表示 nums1 和 nums2 中的元素数目。
请你 合并 nums2 到 nums1 中,使合并后的数组同样按 非递减顺序 排列。
思路:
思路的重点一个是从后往前确定两组中该用哪个数字;
三指针:分别从后往前遍历两个数组有真实数值的位置,如果nums1[i]大,就将nums1[i]的值放到nums[k]中,并且i--,如果nums2[j]的值大,将nums2[j]的值放到nums[k]中,j--;两种情况k都要减一,k表示nums1数组当前放置真实正确数值的指针
如果上述过程结束之后nums2的数组没有遍历完,这个时候此时nums1的i已经遍历到头了,还要将nums2的数组放置到nums1中
代码如下:
public void merge(int[] nums1, int m, int[] nums2, int n) {
// 三指针:分别从后往前遍历两个数组有真实数值的位置,如果nums1[i]大,就将nums1[i]的值放到nums[k]中,并且i--,如果nums2[j]的值大,将nums2[j]的值放到nums[k]中,j--;两种情况k都要减一,k表示nums1数组当前放置真实正确数值的指针
int i = m - 1;
int j = n - 1;
int k = m + n - 1;
while (i >= 0 && j >= 0) {
if (nums1[i] < nums2[j]) {
nums1[k] = nums2[j];
j--;
} else {
nums1[k] = nums1[i];
i--;
}
k--;
}
// 如果nums2的数组没有遍历完,还要将nums2的数组放置到nums1中,此时nums1的i已经遍历到头了
if (j >= 0) {
while (j >= 0) {
nums1[k] = nums2[j];
j--;
k--;
}
}
// int i = 0,j = 0;
// while (i < m && j < n ) {
// // 遇到nums1[i] > nums2[j]的情况,将i,j位置的数值交换,然后将j位置的数值一直往后移动,保证nums2的非递减顺序
// if (nums1[i] > nums2[j]) {
// int k = i;
// int t = j;
// // 将i,j位置的数值交换
// int temp = nums1[i];
// nums1[i] = nums2[j];
// nums2[j] = temp;
// t++;
// // 将j位置的数值一直往后移动,保证nums2的非递减顺序,这里要不停的交换数值保证非递减顺序
// while (t < n && temp > nums2[t]) {
// int temp2 = nums2[t - 1];
// nums2[t - 1] = nums2[t];
// nums2[t] = temp2;
// t++;
// }
// i++;
// } else {
// i++;
// }
// }
// i = m;
// while (i < m + n) {
// nums1[i] = nums2[i - m];
// i++;
// }
}
原地哈希
剑指 Offer 03. 数组中重复的数字
找出数组中重复的数字。
在一个长度为 n 的数组 nums 里的所有数字都在 0~n-1 的范围内。数组中某些数字是重复的,但不知道有几个数字重复了,也不知道每个数字重复了几次。请找出数组中任意一个重复的数字。
思路:
数组元素的 索引 和 值 是 一对多 的关系。
因此,可遍历数组并通过交换操作,使元素的 索引 与 值 一一对应(即 nums[i] = i)。因而,就能通过索引映射对应的值,起到与字典等价的作用。

原地哈希:将nums[i]作为索引的位置上的数值和nums[i]互换,保证nums[i]位置上的值是nums[i],这样最后如果有重复的,肯定会有nums[nums[i]] == nums[i]同时nums[i]不等于i,这样的nums[i]就是重复值
代码如下:
public int findRepeatNumber(int[] nums) {
// 原地哈希:将nums[i]作为索引的位置上的数值和nums[i]互换,保证nums[i]位置上的值是nums[i],这样最后如果有重复的,肯定会有nums[nums[i]] == nums[i]同时nums[i]不等于i,这样的nums[i]就是重复值
for (int i = 0;i < nums.length;i++) {
while (nums[nums[i]] != nums[i]) {
swap(nums,nums[i],i);
}
if (nums[i] != i && nums[nums[i]] == nums[i]) {
return nums[i];
}
}
return nums[nums.length - 1];
}
private void swap(int[] nums,int i,int j) {
int temp = nums[i];
nums[i] = nums[j];
nums[j] = temp;
}
448. 找到所有数组中消失的数字
给你一个含 n 个整数的数组 nums ,其中 nums[i] 在区间 [1, n] 内。请你找出所有在 [1, n] 范围内但没有出现在 nums 中的数字,并以数组的形式返回结果。
思路:
其实这道题和上边的题目类似,因为消失的数字就是用重复的数字来填充的,所以找到重复的数字所在的索引位置就找到了消失的数字
原地哈希:将nums[i]放置在nums[i] - 1作为索引的位置上,然后从头遍历,如果遇到nums[i] - 1 != i的情况,i+1就是消失的数字
代码如下:
public List<Integer> findDisappearedNumbers(int[] nums) {
// 原地哈希:将nums[i]放置在nums[i] - 1作为索引的位置上,然后从头遍历,如果遇到nums[i] - 1 != i的情况,i+1就是消失的数字
List<Integer> res = new ArrayList<>();
for (int i = 0;i < nums.length;i++) {
while (nums[nums[i] - 1] != nums[i]) {
swap(nums,nums[i] - 1,i);
}
}
for (int i = 0;i < nums.length;i++) {
if (nums[i] - 1 != i) {
res.add(i + 1);
}
}
return res;
}
private void swap(int[] nums,int i,int j) {
int temp = nums[i];
nums[i] = nums[j];
nums[j] = temp;
}
41. 缺失的第一个正数
给你一个未排序的整数数组
nums,请你找出其中没有出现的最小的正整数。请你实现时间复杂度为
O(n)并且只使用常数级别额外空间的解决方案。
思路:
原地哈希法:位置i的数值nums[i]应该放在索引位置为nums[i] - 1的位置上,对于数值为负数或者大于数组长度的不用交换直接跳过,在放置完之后,从头遍历,第一个不满足上述条件的位置+1就是缺失的第一个正数,相当于把每个数值哈希映射到对应的位置上去了
代码如下:
public int firstMissingPositive(int[] nums) {
// 原地哈希法:位置i的数值nums[i]应该放在索引位置为nums[i] - 1的位置上,在放置完之后,从头遍历,第一个不满足上述条件的位置+1就是缺失的第一个正数,相当于把每个数值哈希映射到对应的位置上去了
// nums = [3,4,-1,1]
for (int i = 0;i < nums.length;i++) {
while (nums[i] > 0 && nums[i] <= nums.length && nums[nums[i] - 1] != nums[i]) {
// 满足在指定范围内、并且没有放在正确的位置上,才交换
// 例如:数值 3 应该放在索引 2 的位置上
swap(nums,nums[i] - 1,i);
}
}
// [1, -1, 3, 4]
for (int i = 0;i < nums.length;i++) {
if (nums[i] - 1 != i) {
return i + 1;
}
}
// 都正确则返回数组长度 + 1
return nums.length + 1;
}
private void swap(int[] nums,int i,int j) {
int temp = nums[i];
nums[i] = nums[j];
nums[j] = temp;
}
排序
148. 排序链表
给你链表的头结点
head,请将其按 升序 排列并返回 排序后的链表 。进阶:你可以在
O(n log n)时间复杂度和常数级空间复杂度下,对链表进行排序吗?
插入排序时间复杂度O(n的平方),时间复杂度为O(N log N)的排序算法有:堆排序,归并排序,快速排序。
这里采用自顶向下的归并排序要不停递归,需要栈空间,空间复杂度为O(log N),所以采用自底向上的归并排序不用递归,空间复杂度可以满足O(N log N)
思路:
首先求得链表的长度 length,然后将链表拆分成子链表进行合并。
具体做法如下。
-
用 subLength 表示每次需要排序的子链表的长度,初始时 subLength=1。
-
每次将链表拆分成若干个长度为 subLength 的子链表(最后一个子链表的长度可以小于 subLength),按照每两个子链表一组进行合并,合并后即可得到若干个长度为subLength×2 的有序子链表(最后一个子链表的长度可以小于 subLength×2)。合并两个子链表仍然使用「21. 合并两个有序链表」的做法。
-
将 subLength 的值加倍,重复第 2 步,对更长的有序子链表进行合并操作,直到有序子链表的长度大于或等于 length,整个链表排序完毕。
代码如下:
public ListNode sortList(ListNode head) {
// 自底向上归并排序,先把链表分割成一个一个节点(分),然后两个节点两个节点通过(合并两个有序链表)进行合并,然后分割成两个两个节点,一次增大分割节点数到链表长度为止
if (head == null || head.next == null) {
return head;
}
int len = 0;
ListNode node = head;
// 先记录链表长度
while (node != null) {
len++;
node = node.next;
}
// dummy节点用来标记最终链表的头结点
ListNode dummy = new ListNode(-1);
dummy.next = head;
ListNode preNode = dummy;
// 分割节点数从1开始递增,一直递增到链表总长度为止
for (int subLen = 1;subLen < len;subLen <<= 1) {
preNode = dummy;
ListNode curNode = dummy.next;
// 在while循环里先分割成两个链表,然后合并两个链表,接入到之前的pre节点,然后curNode指向合并后的链表下一个节点,用来往后继续两两分割并合并,直到最末尾
while (curNode != null) {
ListNode head1 = curNode;
// 分割第一个有subLen个节点数的链表
for (int i = 1;i < subLen && curNode != null && curNode.next != null;i++) {
curNode = curNode.next;
}
ListNode head2 = curNode.next;
// 将第一个分割后的链表切断,用于合并
curNode.next = null;
curNode = head2;
// 分割第一个有subLen个节点数的链表
for(int i = 1;i < subLen && curNode != null && curNode.next != null;i++) {
curNode = curNode.next;
}
ListNode next = curNode;
if (curNode != null) {
// 这里next用于记录下一趟分割的首节点
next = curNode.next;
// 将第二个分割后的链表切断,用于合并
curNode.next = null;
}
// 合并两个有序链表
ListNode mergeList = mergeTwo(head1,head2);
// 接入到pre节点的下一节点
preNode.next = mergeList;
// pre节点往后遍历到当前合并过的链表的最后一个节点,用于拼接后边的合并链表
while (preNode.next != null) {
preNode = preNode.next;
}
// next用于记录下一趟分割的首节点,这里curNode指向该next节点用于下一趟分割合并
curNode = next;
}
}
return dummy.next;
}
// 合并两个有序链表
private ListNode mergeTwo(ListNode headA,ListNode headB) {
ListNode dummy = new ListNode(-1);
ListNode cur = dummy;
while (headA != null && headB != null) {
if (headA.val < headB.val) {
cur.next = headA;
headA = headA.next;
} else {
cur.next = headB;
headB = headB.next;
}
cur = cur.next;
}
if (headA != null) {
cur.next = headA;
}
if (headB != null) {
cur.next = headB;
}
return dummy.next;
}
二叉树经典难题
124. 二叉树中的最大路径和
路径 被定义为一条从树中任意节点出发,沿父节点-子节点连接,达到任意节点的序列。同一个节点在一条路径序列中 至多出现一次 。该路径 至少包含一个 节点,且不一定经过根节点。路径和 是路径中各节点值的总和。给你一个二叉树的根节点 root ,返回其 最大路径和 。
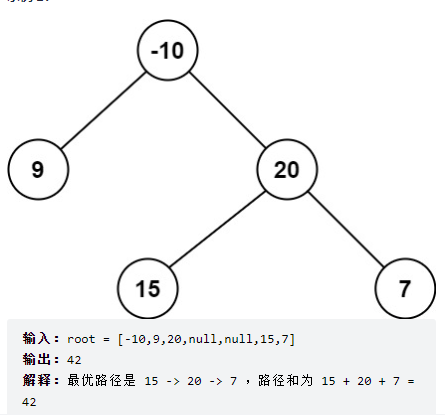
思路:
题目的意思的路径不只是父节点到子节点的路径,还包括左子节点到父节点右子节点
如果不包括(左子节点到父节点右子节点),可以直接用递归,这里要考虑这种情况,就要用全局最大值记录判断这里的情况
二叉树 abc,a 是根结点(递归中的 root),bc 是左右子结点(代表其递归后的最优解)。
最大的路径,可能的路径情况:
a
/ \
b c
1.b + a + c。
2.b + a + a 的父结点。
3.a + c + a 的父结点。
其中情况 1,表示如果不联络父结点的情况,或本身是根结点的情况。
这种情况是没法递归的,但是结果有可能是全局最大路径和。
情况 2 和 3,递归时计算 a+b 和 a+c,选择一个更优的方案返回,也就是上面说的递归后的最优解啦。
另外结点有可能是负值,最大和肯定就要想办法舍弃负值(max(0, x))(max(0,x))。
但是上面 3 种情况,无论哪种,a 作为联络点,都不能够舍弃。
所要做的就是递归,递归时记录好全局最大和,返回联络最大和。
代码如下:
int maxVal;
public int maxPathSum(TreeNode root) {
// 对于a父节点,有b作为左子节点,c作为右子节点,存在以下三种情况
// 1、b + a + c;2、b + a + a的父节点;3、c + a + a的父节点。
// 对第一种情况,无法做递归,所以需要全局的maxVal记录三种情况最大值
// 对第二三种情况,这里的b代表的是递归后的最优解,所以递归左子节点,递归右子节点然后判断两个大小
maxVal = Integer.MIN_VALUE;
getMaxPathSum(root);
return maxVal;
}
private int getMaxPathSum(TreeNode root) {
if (root == null) {
return 0;
}
// 递归左子节点,得到左子树的最优解
int leftVal = getMaxPathSum(root.left);
// 递归右子节点,得到右子树的最优解
int rightVal = getMaxPathSum(root.right);
// 比较左右子节点的最优解哪个大,然后加到父节点a上,然后返回给上一层去
int leftOrRight = root.val + Math.max(0,Math.max(leftVal,rightVal));
// 这里针对第一种情况,直接左子节点最优解加右子节点最优解加父节点,然后通过全局最大值记录
int mid = root.val + Math.max(0,leftVal) + Math.max(0,rightVal);
maxVal = Math.max(maxVal,Math.max(leftOrRight,mid));
// 返回的是第二三种情况的最大值
return leftOrRight;
}
}
摩尔投票法
169. 多数元素
给定一个大小为 n 的数组,找到其中的多数元素。多数元素是指在数组中出现次数 大于 ⌊ n/2 ⌋ 的元素。你可以假设数组是非空的,并且给定的数组总是存在多数元素。
思路
摩尔投票法:
核心就是对拼消耗。
玩一个诸侯争霸的游戏,假设你方人口超过总人口一半以上,并且能保证每个人口出去干仗都能一对一同归于尽。最后还有人活下来的国家就是胜利。
那就大混战呗,最差所有人都联合起来对付你(对应你每次选择作为计数器的数都是众数),或者其他国家也会相互攻击(会选择其他数作为计数器的数),但是只要你们不要内斗,最后肯定你赢。
最后能剩下的必定是自己人。
从第一个数开始count=1,遇到相同的就加1,遇到不同的就减1,减到0就重新换个数开始计数,总能找到最多的那个
代码如下:
class Solution {
public int majorityElement(int[] nums) {
//摩尔投票法,先假设第一个数过半数并设cnt=1;遍历后面的数如果相同则cnt+1,不同则减一,当cnt为0时则更换新的数字为候选数(成立前提:有出现次数大于n/2的数存在)
if (nums.length <= 1) {
return nums[0];
}
int count = 1;
int res = nums[0];
for (int i = 1;i < nums.length;i++) {
if (res == nums[i]) {
count++;
} else {
if (count > 0) {
count--;
} else {
count = 1;
// 更换新的数值作为候选数
res = nums[i];
}
}
}
return res;
}
}
匹配问题
44. 通配符匹配
给定一个字符串 (s) 和一个字符模式 (p) ,实现一个支持 '?' 和 '*' 的通配符匹配。
'?' 可以匹配任何单个字符。
'*' 可以匹配任意字符串(包括空字符串)。
两个字符串完全匹配才算匹配成功。说明:
s 可能为空,且只包含从 a-z 的小写字母。
p 可能为空,且只包含从 a-z 的小写字母,以及字符 ? 和 *。
思路
利用动态规划:dp[i] [j] 表示s的前i个字符能否匹配p的前j个字符


这里如果p[j]是 * 号,还有一种情况,考虑该 * 号匹配s中多个字符,具体实现看代码
代码如下:
public boolean isMatch(String s, String p) {
int m = s.length();
int n = p.length();
if (n <= 0) {
// 两个都为空返回true,p为空s不为空返回false
return m <= 0;
}
if (m <= 0) {
// s为空,如果p全是*字符,返回true
boolean flag = true;
for (char c:p.toCharArray()) {
if (c != '*') {
flag = false;
}
}
return flag;
}
// dp[i][j] 表示s的前i个字符能否匹配p的前j个字符
boolean[][] dp = new boolean[m + 1][n + 1];
// 初始化
dp[0][0] = true;
if (p.charAt(0) == '*') {
// 如果p前边的有很多连续的*,都要赋值true
int i = 0;
while (i < n && p.charAt(i) == '*') {
dp[0][i + 1] = true;
i++;
}
}
for (int i = 0;i < m;i++) {
for (int j = 0;j < n;j++) {
char c = s.charAt(i);
char t = p.charAt(j);
if (t == '*') {
// 该*号什么都不匹配
if (dp[i + 1][j]) {
dp[i + 1][j + 1] = true;
}
// 该*号匹配c,那就看前边的是否能匹配上
if (dp[i][j]) {
dp[i + 1][j + 1] = true;
}
// 该*号匹配c及其之前的多个字符,那就要对s往前遍历,看在i之前有没有一段子串(0...m ,m < i)可以匹配t之前的字符串,如果可以的话,那么*号就匹配[m+1,i]之间的子串
if (!dp[i + 1][j + 1]) {
int index = i - 1;
while (index + 1 >= 0) {
if (dp[index + 1][j]) {
dp[i +1][j + 1] = true;
break;
}
index--;
}
}
} else if (t == '?') {
// 该?号匹配c,那就看前边的是否能匹配上
if (dp[i][j]) {
dp[i + 1][j + 1] = true;
}
} else {
// c与t匹配,如果之前的能匹配,那么dp[i + 1][j + 1] = true
if (c == t) {
if (dp[i][j]) {
dp[i + 1][j + 1] = true;
}
}
}
}
}
return dp[m][n];
}
深度优先遍历(DFS)和广度优先遍历(BFS)
算法解析
深度优先遍历(Depth First Search, 简称 DFS) 与广度优先遍历(Breath First Search)是图论中两种非常重要的算法,生产上广泛用于拓扑排序,寻路(走迷宫),搜索引擎,爬虫等
深度优先遍历
主要思路是从图中一个未访问的顶点 V 开始,沿着一条路一直走到底,然后从这条路尽头的节点回退到上一个节点,再从另一条路开始走到底...,不断递归重复此过程,直到所有的顶点都遍历完成,它的特点是不撞南墙不回头,先走完一条路,再换一条路继续走。
树是图的一种特例(连通无环的图就是树),接下来我们来看看树用深度优先遍历该怎么遍历。
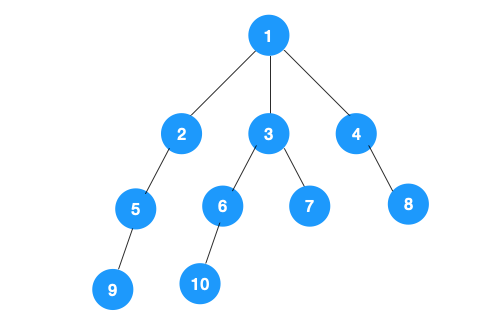
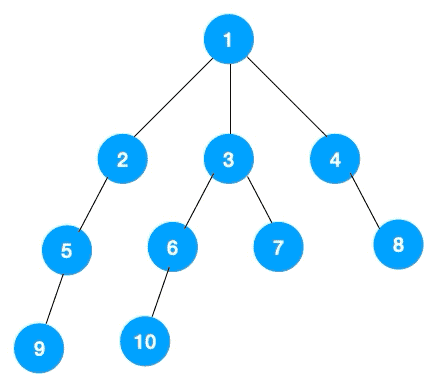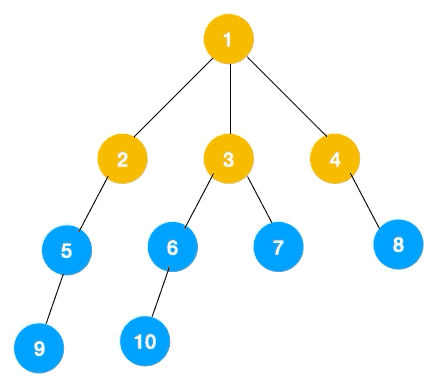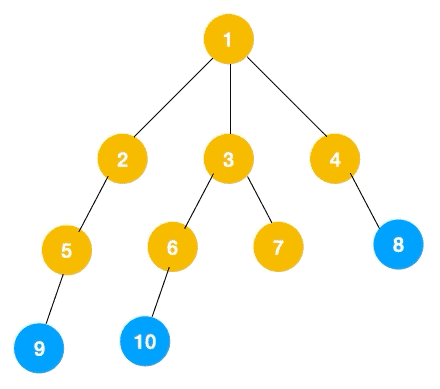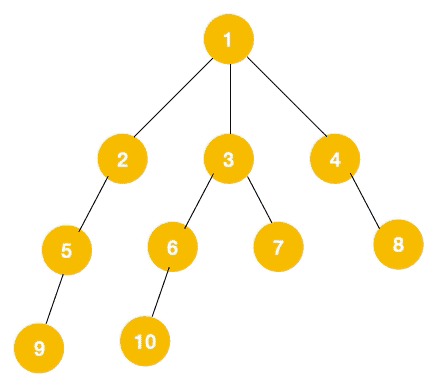
1、我们从根节点 1 开始遍历,它相邻的节点有 2,3,4,先遍历节点 2,再遍历 2 的子节点 5,然后再遍历 5 的子节点 9。
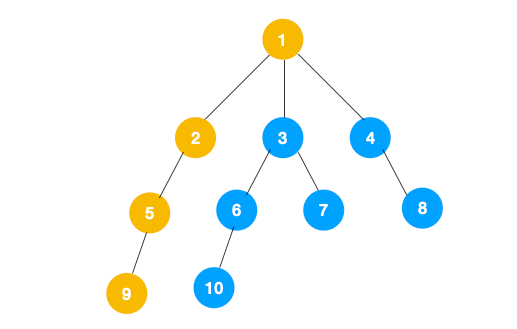
2、上图中一条路已经走到底了(9是叶子节点,再无可遍历的节点),此时就从 9 回退到上一个节点 5,看下节点 5 是否还有除 9 以外的节点,没有继续回退到 2,2 也没有除 5 以外的节点,回退到 1,1 有除 2 以外的节点 3,所以从节点 3 开始进行深度优先遍历,如下:
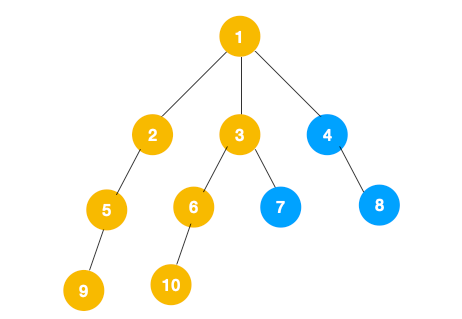
3、同理从 10 开始往上回溯到 6, 6 没有除 10 以外的子节点,再往上回溯,发现 3 有除 6 以外的子点 7,所以此时会遍历 7。
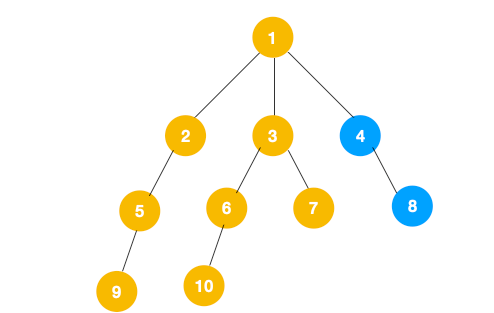
3、从 7 往上回溯到 3, 1,发现 1 还有节点 4 未遍历,所以此时沿着 4, 8 进行遍历,这样就遍历完成了。
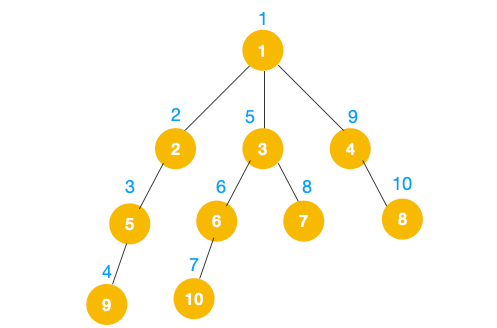
完整的节点的遍历顺序如下(节点上的的蓝色数字代表):
广度优先遍历
广度优先遍历,指的是从图的一个未遍历的节点出发,先遍历这个节点的相邻节点,再依次遍历每个相邻节点的相邻节点。
上文所述树的广度优先遍历动图如下,每个节点的值即为它们的遍历顺序。所以广度优先遍历也叫层序遍历,先遍历第一层(节点 1),再遍历第二层(节点 2,3,4),第三层(5,6,7,8),第四层(9,10)。
深度优先遍历用的是栈,而广度优先遍历要用队列来实现例如:二叉树的层次遍历.
BFS框架:
// 计算从起点 start 到终点 target 的最近距离
int BFS(Node start, Node target) {
Queue<Node> q; // 核心数据结构
Set<Node> visited; // 避免走回头路
q.offer(start); // 将起点加入队列
visited.add(start);
int step = 0; // 记录扩散的步数
while (q not empty) {
int sz = q.size();
/* 将当前队列中的所有节点向四周扩散 */
for (int i = 0; i < sz; i++) {
Node cur = q.poll();
/* 划重点:这里判断是否到达终点 */
if (cur is target)
return step;
/* 将 cur 的相邻节点加入队列 */
for (Node x : cur.adj())
if (x not in visited) {
q.offer(x);
visited.add(x);
}
}
/* 划重点:更新步数在这里 */
step++;
}
}
队列 q 就不说了,BFS 的核心数据结构;cur.adj() 泛指 cur 相邻的节点,比如说二维数组中,cur 上下左右四面的位置就是相邻节点;visited 的主要作用是防止走回头路,大部分时候都是必须的,但是像一般的二叉树结构,没有子节点到父节点的指针,不会走回头路就不需要 visited。
127. 单词接龙
字典 wordList 中从单词 beginWord 和 endWord 的 转换序列 是一个按下述规格形成的序列:
序列中第一个单词是 beginWord 。
序列中最后一个单词是 endWord 。
每次转换只能改变一个字母。
转换过程中的中间单词必须是字典 wordList 中的单词。
给你两个单词 beginWord 和 endWord 和一个字典 wordList ,找到从 beginWord 到 endWord 的 最短转换序列 中的 单词数目 。如果不存在这样的转换序列,返回 0。
思路:
「转换」意即:两个单词对应位置只有一个字符不同,例如 "hit" 与 "hot",这种转换是可以逆向的,因此,根据题目给出的单词列表,可以构建出一个无向(无权)图;
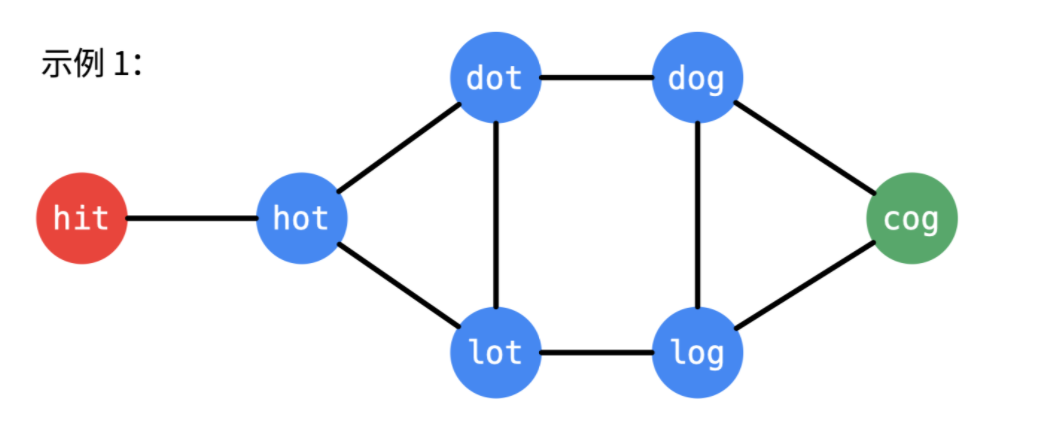
如果一开始就构建图,每一个单词都需要和除它以外的另外的单词进行比较,复杂度是O(NwordLen),这里 N是单词列表的长度;
为此,我们在遍历一开始,把所有的单词列表放进一个哈希表中,然后在遍历的时候构建图,每一次得到在单词列表里可以转换的单词,复杂度是 O(26×wordLen),借助哈希表,找到邻居与 NN 无关;
使用 BFS 进行遍历,需要的辅助数据结构是:
- 队列;
- visited 集合。说明:可以直接在 wordSet (由 wordList 放进集合中得到)里做删除。但更好的做法是新开一个哈希表,遍历过的字符串放进哈希表里。这种做法具有普遍意义。绝大多数在线测评系统和应用场景都不会在意空间开销。
单向广度优先遍历
广度优先遍历(BFS),一层一层的将队列里的字符串出队,然后遍历它可以修改字符后的字符串,查看能否变成endWord,如果不能就入队,并标记已访问
代码如下:
public int ladderLength(String beginWord, String endWord, List<String> wordList) {
// 广度优先遍历(BFS),一层一层的将队列里的字符串出队,然后遍历它可以修改字符后的字符串,查看能否变成endWord,如果不能就入队,并标记已访问
// 转换成set便于快速判断是否存在
Set<String> wordSet = new HashSet<>(wordList);
if (wordSet.size() <= 0 || !wordSet.contains(endWord)) {
return 0;
}
wordSet.remove(beginWord);
// 广度优先遍历一定要有队列和visited标记数组
Set<String> visited = new HashSet<>();
Queue<String> queue = new LinkedList<>();
// 先把第一个开始字符串加进来,标记已访问
queue.offer(beginWord);
visited.add(beginWord);
int step = 1;
while (!queue.isEmpty()) {
// 记录好目前队列长度,先把当前一层的遍历完,遍历过程会往队列里入队新字符串
int size = queue.size();
for (int i = 0;i < size;i++) {
String curWord = queue.poll();
// 取出队列里的字符串,然后进入下边的方法判断该字符串修改一个字符是否能变成endWord,如果是,直接返回
if (changeWordEveryOneLetter(curWord,endWord,queue,visited,wordSet)) {
return step + 1;
}
}
step++;
}
return 0;
}
// 判断curWord修改一个字符能否变成endword,如果能,返回true,不能,就把修改过后的字符串入队,并且标记已访问
private boolean changeWordEveryOneLetter(String curWord,String endWord,Queue<String> queue,Set<String> visited,Set<String> wordSet) {
char[] charArray = curWord.toCharArray();
// 对endWord的每一个位置对应搞curWord上来修改,看是否可以变成endWord
for (int i = 0;i < endWord.length();i++) {
char originChar = charArray[i];
for (char k = 'a';k <= 'z';k++) {
// 修改第i位,如果是本身的字符,跳过
if (originChar == k) {
continue;
}
charArray[i] = k;
String newStr = String.valueOf(charArray);
// 判断修改字符过后的字符串是否在哈希表里
if (wordSet.contains(newStr)) {
// 如果修改字符过后的字符串和endWord相等,直接返回true
if (newStr.equals(endWord)) {
return true;
}
// 如果修改字符过后的字符串和endWord不相等,如果没访问过,就入队,并且标记为已访问
if (!visited.contains(newStr)) {
queue.offer(newStr);
visited.add(newStr);
}
}
}
// 最后恢复该位置的字符,进行下一个位置的修改
charArray[i] = originChar;
}
return false;
}
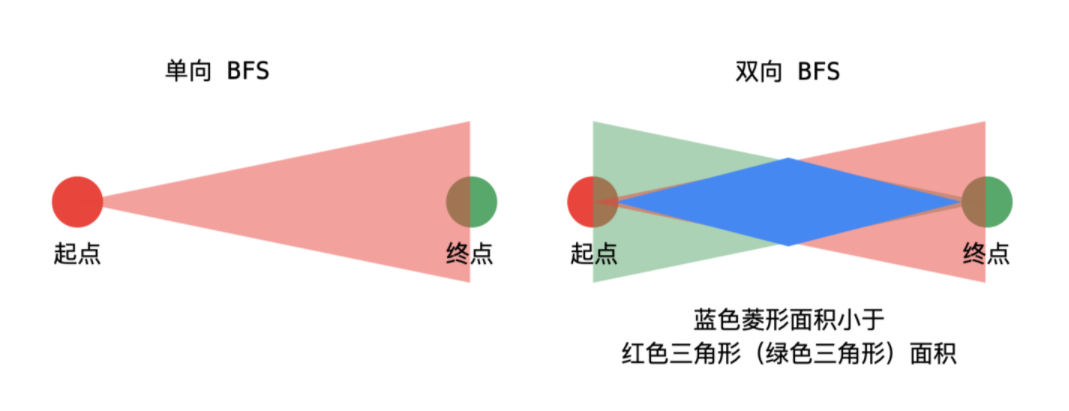
双向广度优先遍历
- 已知目标顶点的情况下,可以分别从起点和目标顶点(终点)执行广度优先遍历,直到遍历的部分有交集。这种方式搜索的单词数量会更小一些;
- 更合理的做法是,每次从单词数量小的集合开始扩散;
- 这里 beginVisited 和 endVisited 交替使用,等价于单向 BFS 里使用队列,每次扩散都要加到总的 visited 里。
代码如下:
// 双向广度优先遍历
public int ladderLength2(String beginWord, String endWord, List<String> wordList) {
// 双向广度优先遍历(BFS)分别从起点和目标顶点(终点)执行广度优先遍历,直到遍历的部分有交集。这种方式搜索的单词数量会更小一些;
// 更合理的做法是,每次从单词数量小的集合开始扩散;
// 第 1 步:先将 wordList 放到哈希表里,便于判断某个单词是否在 wordList 里
Set<String> wordSet = new HashSet<>(wordList);
if (wordSet.size() <= 0 || !wordSet.contains(endWord)) {
return 0;
}
// 这里 beginVisited 和 endVisited 交替使用,等价于单向 BFS 里使用队列,每次扩散都要加到总的 visited 里。
// 第 2 步:已经访问过的 word 添加到 visited 哈希表里
Set<String> visited = new HashSet<>();
// 分别用左边和右边扩散的哈希表代替单向 BFS 里的队列,它们在双向 BFS 的过程中交替使用
Set<String> beginVisited = new HashSet<>();
beginVisited.add(beginWord);
Set<String> endVisited = new HashSet<>();
endVisited.add(endWord);
// 第 3 步:执行双向 BFS,左右交替扩散的步数之和为所求
int step = 1;
while (!beginVisited.isEmpty() && !endVisited.isEmpty()) {
// 优先选择小的哈希表进行扩散,考虑到的情况更少,这里是把两个集合互换,这样就只用考虑beginVisited集合就可以了,保证beginVisited集合始终是最小的
if (beginVisited.size() > endVisited.size()) {
Set<String> temp = endVisited;
endVisited = beginVisited;
beginVisited = temp;
}
// 逻辑到这里,保证 beginVisited 是相对较小的集合,nextLevelVisited 在扩散完成以后,会成为新的 beginVisited
Set<String> nextLevelVisited = new HashSet<>();
for (String curWord:beginVisited) {
if (changeWordEveryOneLetter(curWord,endVisited,visited,wordSet,nextLevelVisited)) {
return step + 1;
}
}
// 原来的 beginVisited 废弃,从 nextLevelVisited 开始新的双向 BFS
beginVisited = nextLevelVisited;
step++;
}
return 0;
}
/**
* 尝试对 word 修改每一个字符,看看是不是能落在 endVisited 中,扩展得到的新的 word 添加到 nextLevelVisited 里
*
* @param curWord
* @param endVisited
* @param visited
* @param wordSet
* @param nextLevelVisited
* @return
*/
private boolean changeWordEveryOneLetter(String curWord,Set<String> endVisited,Set<String> visited,Set<String> wordSet,Set<String> nextLevelVisited) {
char[] charArray = curWord.toCharArray();
for (int i = 0;i < charArray.length;i++) {
char originChar = charArray[i];
for (char c = 'a';c <= 'z';c++) {
if (originChar == c) {
continue;
}
charArray[i] = c;
String newStr = String.valueOf(charArray);
if (wordSet.contains(newStr)) {
// 这里判断的是修改字符后的字符串是否落入endVisited里,如果是,说明出现了交集,直接返回true
if (endVisited.contains(newStr)) {
return true;
}
if (!visited.contains(newStr)) {
// nextLevelVisited记录curWord可以一步变成的字符串,最后用来更新beginVisited集合
nextLevelVisited.add(newStr);
visited.add(newStr);
}
}
}
// 恢复,下次再用
charArray[i] = originChar;
}
return false;
}
752.打开转盘锁
题目描述:
你有一个带有四个圆形拨轮的转盘锁。每个拨轮都有10个数字: '0', '1', '2', '3', '4', '5', '6', '7', '8', '9' 。每个拨轮可以自由旋转:例如把 '9' 变为 '0','0' 变为 '9' 。每次旋转都只能旋转一个拨轮的一位数字。
锁的初始数字为 '0000' ,一个代表四个拨轮的数字的字符串。
列表 deadends 包含了一组死亡数字,一旦拨轮的数字和列表里的任何一个元素相同,这个锁将会被永久锁定,无法再被旋转。
字符串 target 代表可以解锁的数字,你需要给出最小的旋转次数,如果无论如何不能解锁,返回 -1。
代码题解:
class Solution {
public int openLock(String[] deadends, String target) {
Queue<String> q = new LinkedList<>();
q.offer("0000");
// 记录转动过的数字,防止走回头路
Set<String> visited = new HashSet<>();
// 记录需要跳过的死亡密码
Set<String> deads = new HashSet<>();
for(String s:deadends) {
deads.add(s);
}
visited.add("0000");
// 从起点开始启动广度优先搜索
int dep = 0;
while(!q.isEmpty()) {
int size = q.size();
/* 将当前队列中的所有节点向周围扩散 */
for(int i=0; i<size;i++) {
String cur = q.poll();
if(cur.equals(target)) {
return dep;
}
if(deads.contains(cur)) {
continue;
}
/* 将一个节点的未遍历相邻的八个节点加入队列 */
for(int j=0;j<4;j++) {
String up = plusOne(cur,j);
if(!visited.contains(up)) {
visited.add(up);
q.offer(up);
}
String down = minusOne(cur,j);
if(!visited.contains(down)) {
visited.add(down);
q.offer(down);
}
}
}
dep++;
}
return -1;
}
String plusOne(String s,int j) {
//往上波动
char[] ch = s.toCharArray();
if(ch[j] == '9') {
ch[j] ='0';
}else {
ch[j] +=1;
}
return new String(ch);
}
String minusOne(String s,int j) {
//向下波动
char[] ch = s.toCharArray();
if(ch[j] == '0') {
ch[j] = '9';
}else {
ch[j]-=1;
}
return new String(ch);
}
}
双向BFS解法:
class Solution {
public int openLock(String[] deadends, String target) {
//双向BFS
// 用集合不用队列,可以快速判断元素是否存在
Set<String> q1 = new HashSet<>();
Set<String> q2 = new HashSet<>();
Set<String> visited = new HashSet<>();
Set<String> deads = new HashSet<>();
for(String s:deadends) {
deads.add(s);
}
//起点
q1.add("0000");
// 终点
q2.add(target);
int dep = 0;
while(!q1.isEmpty()&&!q2.isEmpty()) {
// 哈希集合在遍历的过程中不能修改,用 temp 存储扩散结果
Set<String> temp = new HashSet<>();
/* 将 q1 中的所有节点向周围扩散 */
for (String cur : q1) {
if(deads.contains(cur)) {
continue;
}
//这里判断双队列是否有交集,如果有交集,则找到最短路径
if(q2.contains(cur)) {
return dep;
}
visited.add(cur);
/* 将一个节点的未遍历相邻节点加入集合 */
for(int j=0;j<4;j++) {
String up = plusOne(cur,j);
if(!visited.contains(up)) {
temp.add(up);
}
String down = minusOne(cur,j);
if(!visited.contains(down)) {
temp.add(down);
}
}
}
//交换q1和q2
// temp 相当于 q1
// 这里交换 q1 q2,下一轮 while 就是扩散 q2
q1=q2;
q2=temp;
dep++;
}
return -1;
}
String plusOne(String s,int j) {
//往上波动
char[] ch = s.toCharArray();
if(ch[j] == '9') {
ch[j] ='0';
}else {
ch[j] +=1;
}
return new String(ch);
}
String minusOne(String s,int j) {
//向下波动
char[] ch = s.toCharArray();
if(ch[j] == '0') {
ch[j] = '9';
}else {
ch[j]-=1;
}
return new String(ch);
}
}
111.二叉树的最小深度
题目描述
给定一个二叉树,找出其最小深度。
最小深度是从根节点到最近叶子节点的最短路径上的节点数量。
说明:叶子节点是指没有子节点的节点。
代码题解:
class Solution {
public int minDepth(TreeNode root) {
if(root ==null) {
return 0;
}
Queue<TreeNode> q = new LinkedList<>();
q.offer(root);
int dep =1;
while(!q.isEmpty()) {
int size = q.size();
/* 将当前队列中的所有节点向四周扩散 */
for(int i = 0;i<size;i++) {
TreeNode t = q.poll();
if(t.left==null&&t.right==null) {
return dep;
}
/* 将 t 的相邻节点加入队列 */
if(t.left!=null) {
q.offer(t.left);
}
if(t.right!=null) {
q.offer(t.right);
}
}
dep++;
}
return dep;
}
}
网格类问题的 DFS 遍历方法
们所熟悉的 DFS(深度优先搜索)问题通常是在树或者图结构上进行的。而我们今天要讨论的 DFS 问题,是在一种「网格」结构中进行的。岛屿问题是这类网格 DFS 问题的典型代表。
网格问题是由 m \times nm×n 个小方格组成一个网格,每个小方格与其上下左右四个方格认为是相邻的,要在这样的网格上进行某种搜索。
岛屿问题是一类典型的网格问题。每个格子中的数字可能是 0 或者 1。我们把数字为 0 的格子看成海洋格子,数字为 1 的格子看成陆地格子,这样相邻的陆地格子就连接成一个岛屿。

在这样一个设定下,就出现了各种岛屿问题的变种,包括岛屿的数量、面积、周长等。不过这些问题,基本都可以用 DFS 遍历来解决。
DFS 的基本结构
网格结构要比二叉树结构稍微复杂一些,它其实是一种简化版的图结构。要写好网格上的 DFS 遍历,我们首先要理解二叉树上的 DFS 遍历方法,再类比写出网格结构上的 DFS 遍历。我们写的二叉树 DFS 遍历一般是这样的:
void traverse(TreeNode root) {
// 判断 base case
if (root == null) {
return;
}
// 访问两个相邻结点:左子结点、右子结点
traverse(root.left);
traverse(root.right);
}
可以看到,二叉树的 DFS 有两个要素:「访问相邻结点」和「判断 base case」。
第一个要素是访问相邻结点。二叉树的相邻结点非常简单,只有左子结点和右子结点两个。二叉树本身就是一个递归定义的结构:一棵二叉树,它的左子树和右子树也是一棵二叉树。那么我们的 DFS 遍历只需要递归调用左子树和右子树即可。
第二个要素是 判断 base case。一般来说,二叉树遍历的 base case 是 root == null。这样一个条件判断其实有两个含义:一方面,这表示 root 指向的子树为空,不需要再往下遍历了。另一方面,在 root == null 的时候及时返回,可以让后面的 root.left 和 root.right 操作不会出现空指针异常。
对于网格上的 DFS,我们完全可以参考二叉树的 DFS,写出网格 DFS 的两个要素:
首先,网格结构中的格子有多少相邻结点?答案是上下左右四个。对于格子 (r, c) 来说(r 和 c 分别代表行坐标和列坐标),四个相邻的格子分别是 (r-1, c)、(r+1, c)、(r, c-1)、(r, c+1)。换句话说,网格结构是「四叉」的。

其次,网格 DFS 中的 base case 是什么?从二叉树的 base case 对应过来,应该是网格中不需要继续遍历、grid[r][c] 会出现数组下标越界异常的格子,也就是那些超出网格范围的格子。
我们得到了网格 DFS 遍历的框架代码:
void dfs(int[][] grid, int r, int c) {
// 判断 base case
// 如果坐标 (r, c) 超出了网格范围,直接返回
if (!inArea(grid, r, c)) {
return;
}
// 访问上、下、左、右四个相邻结点
dfs(grid, r - 1, c);
dfs(grid, r + 1, c);
dfs(grid, r, c - 1);
dfs(grid, r, c + 1);
}
// 判断坐标 (r, c) 是否在网格中
boolean inArea(int[][] grid, int r, int c) {
return 0 <= r && r < grid.length
&& 0 <= c && c < grid[0].length;
}
如何避免重复遍历
网格结构的 DFS 与二叉树的 DFS 最大的不同之处在于,遍历中可能遇到遍历过的结点。这是因为,网格结构本质上是一个「图」,我们可以把每个格子看成图中的结点,每个结点有向上下左右的四条边。在图中遍历时,自然可能遇到重复遍历结点。
这时候,DFS 可能会不停地「兜圈子」,永远停不下来,如下图所示:

如何避免这样的重复遍历呢?答案是标记已经遍历过的格子。以岛屿问题为例,我们需要在所有值为 1 的陆地格子上做 DFS 遍历。每走过一个陆地格子,就把格子的值改为 2,这样当我们遇到 2 的时候,就知道这是遍历过的格子了。也就是说,每个格子可能取三个值:
0 —— 海洋格子
1 —— 陆地格子(未遍历过)
2 —— 陆地格子(已遍历过)
我们在框架代码中加入避免重复遍历的语句:
void dfs(int[][] grid, int r, int c) {
// 判断 base case
if (!inArea(grid, r, c)) {
return;
}
// 如果这个格子不是岛屿,直接返回
if (grid[r][c] != 1) {
return;
}
grid[r][c] = 2; // 将格子标记为「已遍历过」
// 访问上、下、左、右四个相邻结点
dfs(grid, r - 1, c);
dfs(grid, r + 1, c);
dfs(grid, r, c - 1);
dfs(grid, r, c + 1);
}
// 判断坐标 (r, c) 是否在网格中
boolean inArea(int[][] grid, int r, int c) {
return 0 <= r && r < grid.length
&& 0 <= c && c < grid[0].length;
}
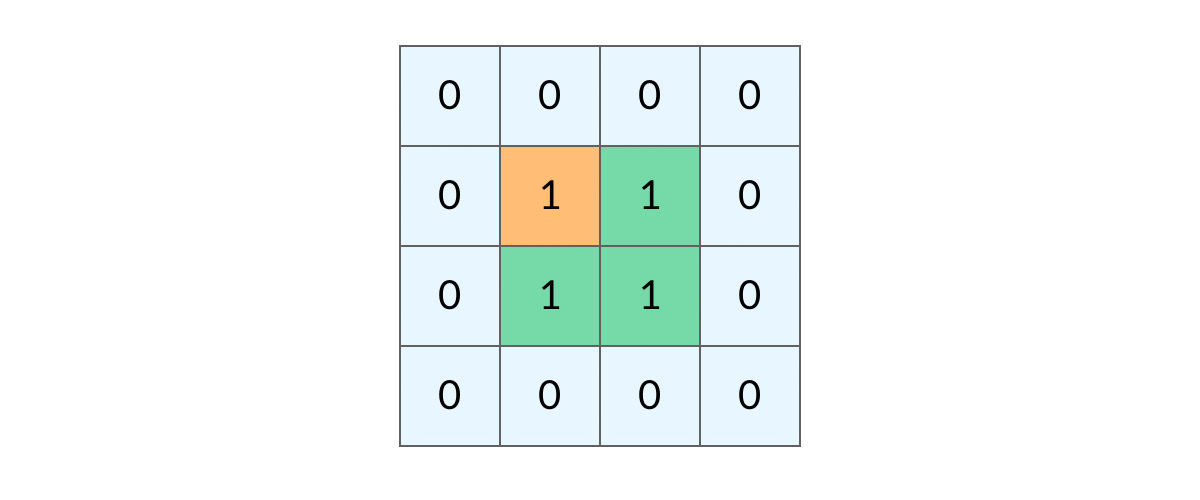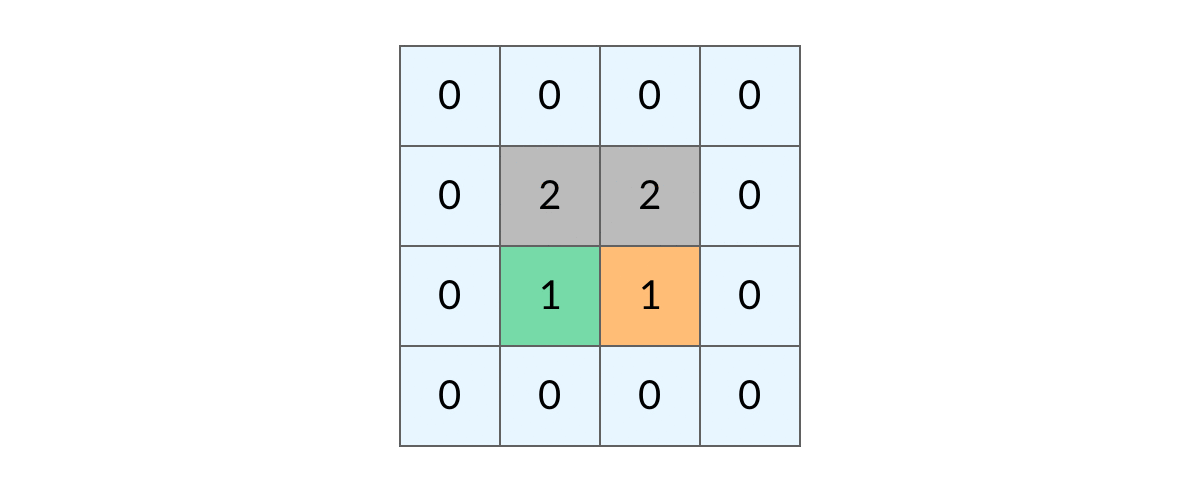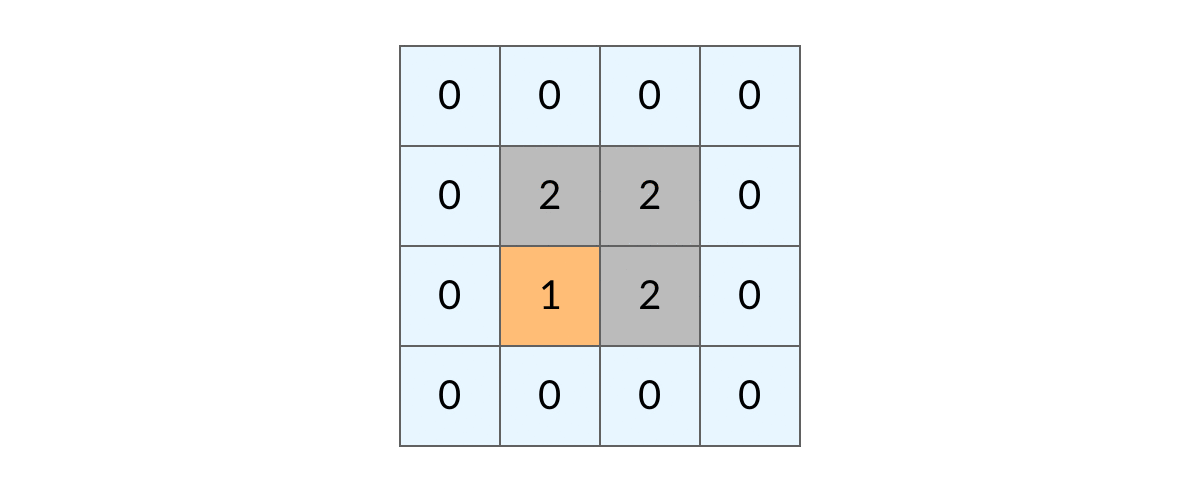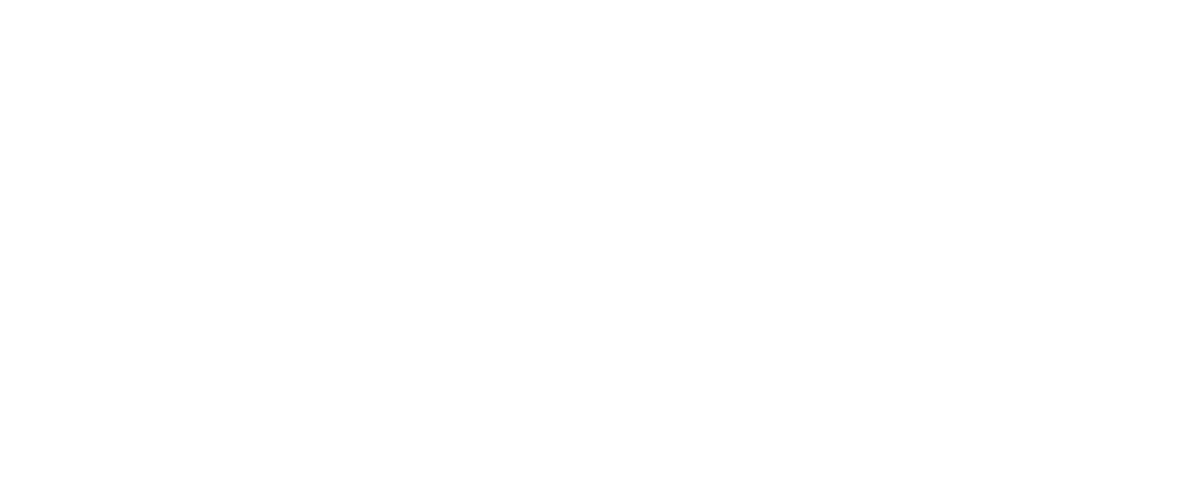
这样,我们就得到了一个岛屿问题、乃至各种网格问题的通用 DFS 遍历方法。
695. 岛屿的最大面积
给你一个大小为 m x n 的二进制矩阵 grid 。
岛屿 是由一些相邻的 1 (代表土地) 构成的组合,这里的「相邻」要求两个 1 必须在 水平或者竖直的四个方向上 相邻。你可以假设 grid 的四个边缘都被 0(代表水)包围着。
岛屿的面积是岛上值为 1 的单元格的数目。
计算并返回 grid 中最大的岛屿面积。如果没有岛屿,则返回面积为 0 。
代码如下:
class Solution {
public int maxAreaOfIsland(int[][] grid) {
int res = 0;
int m = grid.length;
int n = grid[0].length;
// 遇到'1'了就深度优先遍历网格,每一次的深度优先遍历都代表一个岛屿,所以res++
for (int i = 0;i < m;i++) {
for (int j = 0;j < n;j++) {
if (grid[i][j] == 1) {
int area = dfs(grid,i,j);
res = Math.max(res,area);
}
}
}
return res;
}
private int dfs(int[][] grid,int i,int j) {
// 深度优先遍历,判断是否到达了边界
if (!inArea(grid,i,j)) {
return 0;
}
// 如果当前格子不是岛屿就直接返回,没必要往非岛屿周围dfs了
if (grid[i][j] != 1) {
return 0;
}
grid[i][j] = 2;
return 1 + dfs(grid,i - 1,j) + dfs(grid,i,j+1) + dfs(grid,i+1,j) + dfs(grid,i,j-1);
}
private boolean inArea(int[][] grid,int i,int j) {
if (i >= 0 && i < grid.length && j >= 0 && j < grid[0].length) {
return true;
}
return false;
}
}
200. 岛屿数量
给你一个由 '1'(陆地)和 '0'(水)组成的的二维网格,请你计算网格中岛屿的数量。
岛屿总是被水包围,并且每座岛屿只能由水平方向和/或竖直方向上相邻的陆地连接形成。
此外,你可以假设该网格的四条边均被水包围。
思路
遇到'1'了就深度优先遍历网格,遍历过程把岛屿'0'变成2,标记为已访问的岛屿,每一次的深度优先遍历都代表一个岛屿,所以dfs一次就加一。
代码如下:
class Solution {
public int numIslands(char[][] grid) {
int res = 0;
int m = grid.length;
int n = grid[0].length;
// 遇到'1'了就深度优先遍历网格,每一次的深度优先遍历都代表一个岛屿,所以res++
for (int i = 0;i < m;i++) {
for (int j = 0;j < n;j++) {
if (grid[i][j] == '1') {
dfs(grid,i,j);
res++;
}
}
}
return res;
}
private void dfs(char[][] grid,int i,int j) {
// 深度优先遍历,判断是否到达了边界
if (!inArea(grid,i,j)) {
return;
}
// 如果当前格子不是岛屿就直接返回,没必要往非岛屿周围dfs了
if (grid[i][j] != '1') {
return;
}
// 访问过了直接标记为2表示已访问过
grid[i][j] = '2';
// 对当前格子的邻近四个格子进行dfs
dfs(grid,i-1,j);
dfs(grid,i,j+1);
dfs(grid,i+1,j);
dfs(grid,i,j-1);
}
private boolean inArea(char[][] grid,int i,int j) {
if (i >= 0 && i < grid.length && j >= 0 && j < grid[0].length) {
return true;
}
return false;
}
}
212. 单词搜索 II
给定一个 m x n 二维字符网格 board 和一个单词(字符串)列表 words,找出所有同时在二维网格和字典中出现的单词。
单词必须按照字母顺序,通过 相邻的单元格 内的字母构成,其中“相邻”单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母在一个单词中不允许被重复使用。
思路:dfs + 前缀树
前缀树(字典树)是一种树形数据结构,用于高效地存储和检索字符串数据集中的键。前缀树可以用 O(|S|)O(∣S∣) 的时间复杂度完成如下操作,其中 |S|∣S∣ 是插入字符串或查询前缀的长度:
-
向前缀树中插入字符串 word;
-
查询前缀串prefix 是否为已经插入到前缀树中的任意一个字符串 word 的前缀;
根据题意,我们需要逐个遍历二维网格中的每一个单元格;然后搜索从该单元格出发的所有路径,找到其中对应 words 中的单词的路径。因为这是一个回溯的过程,所以我们有如下算法:
-
遍历二维网格中的所有单元格。
-
深度优先搜索所有从当前正在遍历的单元格出发的、由相邻且不重复的单元格组成的路径。因为题目要求同一个单元格内的字母在一个单词中不能被重复使用;所以我们在深度优先搜索的过程中,每经过一个单元格,都将该单元格的字母临时修改为特殊字符(例如 #),以避免再次经过该单元格。
-
如果当前路径是 words 中的单词,则将其添加到结果集中。如果当前路径是 words 中任意一个单词的前缀,则继续搜索;反之,如果当前路径不是 wordswords 中任意一个单词的前缀,则剪枝。我们可以将 words 中的所有字符串先添加到前缀树中,而后用 O(∣S∣) 的时间复杂度查询当前路径是否为 words 中任意一个单词的前缀。
注意:
在回溯的过程中,我们不需要每一步都判断完整的当前路径是否是 wordswords 中任意一个单词的前缀;而是可以记录下路径中每个单元格所对应的前缀树结点,每次只需要判断新增单元格的字母是否是上一个单元格对应前缀树结点的子结点即可。
代码如下:
class Solution {
// 前缀树
private class Trie {
String word;
boolean isEnd;
Map<Character,Trie> children;
public Trie() {
word = "";
children = new HashMap<>();
}
public void insert(String word) {
Trie cur = this;
for (char c:word.toCharArray()) {
if (!cur.children.containsKey(c)) {
cur.children.put(c,new Trie());
}
cur = cur.children.get(c);
}
// 标记为叶子节点的word为整个路径的字符串
cur.word = word;
}
}
private int[][] direction ={{-1,0},{0,1},{1,0},{0,-1}};
public List<String> findWords(char[][] board, String[] words) {
Set<String> res = new HashSet<>();
Trie trie = new Trie();
// 先把所有单词都插入到前缀树里
for (String word:words) {
trie.insert(word);
}
for (int i = 0;i < board.length;i++) {
for (int j = 0;j < board[0].length;j++) {
dfs(board,i,j,trie,res);
}
}
return new ArrayList<String>(res);
}
private void dfs(char[][] board,int i,int j,Trie now,Set<String> res) {
// 如果当前前缀树的子节点不包含该字符就返回
if (!now.children.containsKey(board[i][j])) {
return;
}
char ch = board[i][j];
// 获取当前前缀树节点的字符对应的树节点
now = now.children.get(ch);
// 如果树节点到了叶子节点,说明有了一个完整的word的路径,添加单词进去
if (!"".equals(now.word)) {
res.add(now.word);
}
// 标记为已访问状态
board[i][j] = '#';
// 对当前单元格往四周前进
for (int k = 0;k < direction.length;k++) {
if (inArea(board,i + direction[k][0],j + direction[k][1])) {
dfs(board,i + direction[k][0],j + direction[k][1],now,res);
}
}
// 还原单元格的字符
board[i][j] = ch;
}
private boolean inArea(char[][] board,int i,int j) {
if (i >= 0 && i < board.length && j >= 0 && j < board[0].length) {
return true;
}
return false;
}
}
前缀树
https://mp.weixin.qq.com/s/hGrTUmM1zusPZZ0nA9aaNw
208. 实现 Trie (前缀树)
Trie(发音类似 "try")或者说 前缀树 是一种树形数据结构,用于高效地存储和检索字符串数据集中的键。这一数据结构有相当多的应用情景,例如自动补完和拼写检查。
请你实现 Trie 类:
Trie() 初始化前缀树对象。
void insert(String word) 向前缀树中插入字符串 word 。
boolean search(String word) 如果字符串 word 在前缀树中,返回 true(即,在检索之前已经插入);否则,返回 false 。
boolean startsWith(String prefix) 如果之前已经插入的字符串 word 的前缀之一为 prefix ,返回 true ;否则,返回 false
思路
类似于多叉树,这里是26叉树,每个子节点包含26个字符中的一个,并且通过isEnd标记是否是叶子节点,每次插入字符串就遍历字符串的每个字符然后依次插入到对应的数组的节点位置,如果本来为null就新建个树到对应数组的位置上。
代码如下:
public class Trie {
class TrieNode {
// 标记是否是叶子节点
private boolean isEnd;
TrieNode[] next;
public TrieNode() {
isEnd = false;
// 每个节点下都有26个节点,通过数组表示,每个节点表示一个字母,不为空说明该节点有对应字母出现
next = new TrieNode[26];
}
}
private TrieNode root;
public Trie() {
root = new TrieNode();
}
public void insert(String word) {
TrieNode trieNode = root;
// 插入就是遍历每个字符,然后新建到对应数组的节点上
for (char c:word.toCharArray()) {
if (trieNode.next[c - 'a'] == null) {
trieNode.next[c - 'a'] = new TrieNode();
}
trieNode = trieNode.next[c - 'a'];
}
trieNode.isEnd = true;
}
public boolean search(String word) {
TrieNode trieNode = root;
// 查询,要遍历字符串每个字符,直到能搜索到最后一个字符,并且最后一个字符是叶子节点
for (char c:word.toCharArray()) {
trieNode = trieNode.next[c - 'a'];
if (trieNode == null) {
return false;
}
}
if (trieNode.isEnd) {
return true;
}
return false;
}
public boolean startsWith(String prefix) {
TrieNode trieNode = root;
// 遍历字符串每个字符,直到能搜索到最后一个字符,同时不必要最后一个字符时叶子节点,因为是搜索前缀
for (char c:prefix.toCharArray()) {
trieNode = trieNode.next[c - 'a'];
if (trieNode == null) {
return false;
}
}
return true;
}
拓扑排序
207. 课程表
你这个学期必须选修 numCourses 门课程,记为 0 到 numCourses - 1 。
在选修某些课程之前需要一些先修课程。 先修课程按数组 prerequisites 给出,其中 prerequisites[i] = [ai, bi] ,表示如果要学习课程 ai 则 必须 先学习课程 bi 。
例如,先修课程对 [0, 1] 表示:想要学习课程 0 ,你需要先完成课程 1 。
请你判断是否可能完成所有课程的学习?如果可以,返回 true ;否则,返回 false 。
思路
本题可约化为: 课程安排图是否是 有向无环图(DAG)。即课程间规定了前置条件,但不能构成任何环路,否则课程前置条件将不成立。
思路是通过 拓扑排序 判断此课程安排图是否是 有向无环图(DAG) 。 拓扑排序原理: 对 DAG 的顶点进行排序,使得对每一条有向边 (u, v)(u,v),均有 uu(在排序记录中)比 vv 先出现。亦可理解为对某点 vv 而言,只有当 vv 的所有源点均出现了,vv 才能出现。
通过课程前置条件列表 prerequisites 可以得到课程安排图的 邻接表 adjacency
方法一:入度表(广度优先遍历)
算法流程:
1、统计课程安排图中每个节点的入度,生成 入度表 indegrees。
2、借助一个队列 queue,将所有入度为 00 的节点入队。
3、当 queue 非空时,依次将队首节点出队,在课程安排图中删除此节点 pre:
- 并不是真正从邻接表中删除此节点 pre,而是将此节点对应所有邻接节点 cur 的入度 -1−1,即 indegrees[cur] -= 1。
- 当入度 -1−1后邻接节点 cur 的入度为 00,说明 cur 所有的前驱节点已经被 “删除”,此时将 cur 入队。
4、在每次 pre 出队时,执行 numCourses--;
- 若整个课程安排图是有向无环图(即可以安排),则所有节点一定都入队并出队过,即完成拓扑排序。换个角度说,若课程安排图中存在环,一定有节点的入度始终不为 00。
- 因此,拓扑排序出队次数等于课程个数,返回 numCourses == 0 判断课程是否可以成功安排。

复杂度分析:
- 时间复杂度 O(N + M)O(N+M): 遍历一个图需要访问所有节点和所有临边,NN 和 MM 分别为节点数量和临边数量;
- 空间复杂度 O(N + M)O(N+M): 为建立邻接表所需额外空间,adjacency 长度为 NN ,并存储 MM 条临边的数据
代码如下:
/**
* 广度优先遍历方式:BFS
* @param numCourses
* @param prerequisites
* @return
*/
public boolean canFinish(int numCourses, int[][] prerequisites) {
// 课程邻接表
List<List<Integer> > adjacency = new ArrayList<>();
// 入度数组,inDegrees[i]表示课程i的前序课程的数量
int[] inDegrees = new int[numCourses];
for (int i = 0;i < numCourses;i++) {
adjacency.add(new ArrayList<>());
}
for (int i = 0;i < prerequisites.length;i++) {
// 后序课程的入度加一
inDegrees[prerequisites[i][1]] += 1;
// 在邻接表中记录两个课程的前后序关系
adjacency.get(prerequisites[i][0]).add(prerequisites[i][1]);
}
Queue<Integer> qu = new LinkedList<>();
// 把入度为0的课程先加入到队列里
for (int i = 0;i < numCourses;i++) {
if (inDegrees[i] == 0) {
qu.add(i);
}
}
while (!qu.isEmpty()) {
// 获取队列头结点,然后课程数目减一
int cur = qu.poll();
numCourses--;
// 获得该课程的后序课程的列表
List<Integer> nextList = adjacency.get(cur);
// 遍历该课程的后序课程,把每个课程的后序课程的入度减一
for (int next:nextList) {
inDegrees[next]--;
// 入度减一之后,如果后序课程的入度为0,加入到队列里
if (inDegrees[next] == 0) {
qu.add(next);
}
}
}
// 最后如果所有课程都经过了合法的验证,就是合法的课程表
return numCourses == 0;
}
方法二:深度优先遍历
原理是通过 DFS 判断图中是否有环。
算法流程:
1、借助一个标志列表 flags,用于判断每个节点 i (课程)的状态:
- 未被 DFS 访问:i == 0;
- 已被其他节点启动的 DFS 访问:i == -1;
- 已被当前节点启动的 DFS 访问:i == 1。
2、对 numCourses 个节点依次执行 DFS,判断每个节点起步 DFS 是否存在环,若存在环直接返回 FalseFalse。DFS 流程;
2.1 终止条件:
- 当 flag[i] == -1,说明当前访问节点已被其他节点启动的 DFS 访问,无需再重复搜索,直接返回 TrueTrue。
- 当 flag[i] == 1,说明在本轮 DFS 搜索中节点 i 被第 22 次访问,即 课程安排图有环 ,直接返回 FalseFalse。
2.2 将当前访问节点 i 对应 flag[i] 置 11,即标记其被本轮 DFS 访问过;
2.3 递归访问当前节点 i 的所有邻接节点 j,当发现环直接返回 False;
2.4 当前节点所有邻接节点已被遍历,并没有发现环,则将当前节点 flag 置为 -1−1 并返回 True。
3.若整个图 DFS 结束并未发现环,返回 TrueTru**e。
复杂度分析:
- 时间复杂度 O(N + M)O(N+M): 遍历一个图需要访问所有节点和所有临边,NN 和 MM 分别为节点数量和临边数量;
- 空间复杂度 O(N + M)O(N+M): 为建立邻接表所需额外空间,adjacency 长度为 NN ,并存储 MM 条临边的数据。
代码如下:
/**
* 深度优先遍历方式:dfs
* @param numCourses
* @param prerequisites
* @return
*/
public boolean canFinish(int numCourses, int[][] prerequisites) {
// 课程邻接表
List<List<Integer>> adjacency = new ArrayList<>();
// flags[i] == -1标记该课程是已经确定后边的课程都是没有环的
// flags[i] == 1标记在对i课程进行遍历后续课程的时候又遇到了该课程,说明遇到了环
int[] flags = new int[numCourses];
for (int i = 0;i < numCourses;i++) {
adjacency.add(new ArrayList<>());
}
for (int i = 0;i < prerequisites.length;i++) {
// 在邻接表中记录两个课程的前后序关系
adjacency.get(prerequisites[i][0]).add(prerequisites[i][1]);
}
// 遍历每一个课程,进行dfs查看该课程是否后续的课程存在环
for (int i = 0;i < numCourses;i++) {
if (!dfs(adjacency,flags,i)) {
return false;
}
}
return true;
}
private boolean dfs(List<List<Integer> > adjacency,int[] flags,int cur) {
// 如果当前课程的flag为1,说明在上一层递归中或者更上几层中,已经把该课程置为了1,即在本课程的dfs过程中又遇到了该课程,遇到了环,返回false
if (flags[cur] == 1) {
return false;
}
// 当前课程的flag为-1,说明该课程已经遍历了所有后续课程,并且没有出现环,直接返回true,不用再搜索了
if (flags[cur] == -1) {
return true;
}
// 先将当前课程flag标记为1,然后搜索该课程所有的后续课程,查看是否有环
flags[cur] = 1;
for (int next:adjacency.get(cur)) {
if (!dfs(adjacency,flags,next)) {
return false;
}
}
// 搜索该课程所有的后续课程结束之后,没有出现环,标记该课程flag为-1,后边操作在遇到该课程不用再对该课程进行搜索了,直接返回true
flags[cur] = -1;
return true;
}
210. 课程表 II
现在你总共有 numCourses 门课需要选,记为 0 到 numCourses - 1。给你一个数组 prerequisites ,其中 prerequisites[i] = [ai, bi] ,表示在选修课程 ai 前 必须 先选修 bi 。
例如,想要学习课程 0 ,你需要先完成课程 1 ,我们用一个匹配来表示:[0,1] 。
返回你为了学完所有课程所安排的学习顺序。可能会有多个正确的顺序,你只要返回 任意一种 就可以了。如果不可能完成所有课程,返回 一个空数组 。
思路
整体还是和上边的广度优先遍历思路一样,只不过在每次出队的时候把出队的课程放入到res列表里去
算法流程:
1、在开始排序前,扫描对应的存储空间(使用邻接表),将入度为 00 的结点放入队列。
2、只要队列非空,就从队首取出入度为 00 的结点,将这个结点输出到结果集中,并且将这个结点的所有邻接结点(它指向的结点)的入度减 11,在减 11 以后,如果这个被减 11 的结点的入度为 00 ,就继续入队。
3、当队列为空的时候,检查结果集中的顶点个数是否和课程数相等即可。
(思考这里为什么要使用队列?如果不用队列,还可以怎么做,会比用队列的效果差还是更好?)
在代码具体实现的时候,除了保存入度为 00 的队列,我们还需要两个辅助的数据结构:
4、邻接表:通过结点的索引,我们能够得到这个结点的后继结点;
5、入度数组:通过结点的索引,我们能够得到指向这个结点的结点个数。
这个两个数据结构在遍历题目给出的邻边以后就可以很方便地得到。
代码如下:
List<Integer> res;
public int[] findOrder(int numCourses, int[][] prerequisites) {
res = new LinkedList<>();
// [1,0] 0 -> 1
// 入度数组,inDegrees[i]表示课程i的前序课程的数量
int[] inDegrees = new int[numCourses];
// 课程邻接表
List<List<Integer> > adjacency = new ArrayList<>();
for (int i = 0;i < numCourses;i++) {
adjacency.add(new ArrayList<>());
}
for (int i = 0;i < prerequisites.length;i++) {
// 后序课程的入度加一
inDegrees[prerequisites[i][0]] += 1;
// 在邻接表中记录两个课程的前后序关系
adjacency.get(prerequisites[i][1]).add(prerequisites[i][0]);
}
Queue<Integer> qu = new LinkedList<>();
// 把入度为0的课程先加入到队列里
for (int i = 0;i < numCourses;i++) {
if (inDegrees[i] == 0) {
qu.add(i);
}
}
int noCircle = 0;
while (!qu.isEmpty()) {
// 获取队列头结点,然后noCircle加一,并且添加进res列表,因为该课程没有了前边的课程所以可以添加进res列表
int cur = qu.poll();
noCircle += 1;
res.add(cur);
// 获得该课程的后序课程的列表
for (int next:adjacency.get(cur)) {
// 遍历该课程的后序课程,把每个课程的后序课程的入度减一
inDegrees[next] -= 1;
// 入度减一之后,如果后序课程的入度为0,加入到队列里
if (inDegrees[next] == 0) {
qu.add(next);
}
}
}
if (noCircle != numCourses) {
return new int[]{};
}
return res.stream().mapToInt(Integer::intValue).toArray();
}
归并排序
剑指 Offer 51. 数组中的逆序对
在数组中的两个数字,如果前面一个数字大于后面的数字,则这两个数字组成一个逆序对。输入一个数组,求出这个数组中的逆序对的总数。
思路
利用归并排序,每一次在分治的治阶段,将两个分别排好序的数组进行比较,如果前面的数字比右边的当前数字大,那么逆序对的个数就等于mid - i + 1。
代码如下:
int[] temp;
public int reversePairs(int[] nums) {
// 利用归并排序,每一次在分治的治阶段,将两个分别排好序的数组进行比较,如果前面的数字比右边的当前数字大,那么逆序对的个数就等于mid - i + 1
temp = new int[nums.length];
return mergeSort(nums,0,nums.length - 1);
}
private int mergeSort(int[] nums,int left,int right) {
int res = 0;
if (left >= right) {
return 0;
}
int mid = (left + right) / 2;
// 分阶段,拆分为两个数组
int leftCount = mergeSort(nums,left,mid);
int rightCount = mergeSort(nums,mid + 1,right);
int mergeCount = merge(nums,left,mid,right);
return leftCount + rightCount + mergeCount;
}
private int merge(int[] nums,int left,int mid,int right) {
int res = 0;
int index = 0;
int i = left;
int j = mid + 1;
while (i <= mid && j <= right) {
if (nums[i] <= nums[j]) {
temp[index] = nums[i];
i++;
} else {
// 遇到nums[i] > nums[j]的情况,说明i...mid之间的数字都比nums[j]大,所以逆序对个数加mid - i + 1
temp[index] = nums[j];
res += mid - i + 1;
j++;
}
index++;
}
while (i <= mid) {
temp[index] = nums[i];
i++;
index++;
}
while (j <= right) {
temp[index] = nums[j];
j++;
index++;
}
index = 0;
for (int k = left;k <= right;k++) {
nums[k] = temp[index];
index++;
}
return res;
}
23. 合并K个升序链表
给你一个链表数组,每个链表都已经按升序排列。
请你将所有链表合并到一个升序链表中,返回合并后的链表。
思路
用分治的方法进行合并。将k个链表分成两组,然后递归再分别分成两组,直到最后剩下一个链表作为一组,然后再和另一个链表合并(mergeTwoList),然后返回递归上一层接着进行合并操作
代码如下:
public ListNode mergeKLists(ListNode[] lists) {
/**
* 用分治的方法进行合并。
* 将k个链表分成两组,然后递归再分别分成两组,直到最后剩下一个链表作为一组,然后再和另一个链表合并(mergeTwoList),然后返回递归上一层接着进行合并操作
*/
int len = lists.length;
// ListNode dummy = new ListNode(-1);
// ListNode curNode = dummy;
// boolean flag = false;
// ListNode[] nodes = new ListNode[len];
// for (int i = 0;i < len;i++) {
// nodes[i] = lists[i];
// }
// int minVal = Integer.MAX_VALUE;
// while (!flag) {
// minVal = Integer.MAX_VALUE;
// int minIndex = -1;
// for (int i = 0;i < len;i++) {
// if (nodes[i] != null && nodes[i].val < minVal) {
// minIndex = i;
// minVal = nodes[i].val;
// }
// }
// if (minIndex == -1) {
// break;
// }
// ListNode newNode = new ListNode(nodes[minIndex].val);
// curNode.next = newNode;
// curNode = curNode.next;
// nodes[minIndex] = nodes[minIndex].next;
// }
return merge(lists,0,len - 1);
}
private ListNode merge(ListNode[] lists,int left,int right) {
// 分治归并排序
if (left == right) {
return lists[left];
}
if (left > right) {
return null;
}
int mid = (left + right) / 2;
return mergeTwoLists(merge(lists,left,mid),merge(lists,mid + 1,right));
}
private ListNode mergeTwoLists(ListNode list1,ListNode list2) {
ListNode dummy = new ListNode(0);
ListNode curNode = dummy;
while (list1 != null && list2 != null) {
if (list1.val < list2.val) {
curNode.next = list1;
list1 = list1.next;
} else {
curNode.next = list2;
list2 = list2.next;
}
curNode = curNode.next;
}
if (list1 != null) {
curNode.next = list1;
}
if (list2 != null) {
curNode.next = list2;
}
return dummy.next;
}
单调栈
739. 每日温度
请根据每日 气温 列表,重新生成一个列表。对应位置的输出为:要想观测到更高的气温,至少需要等待的天数。如果气温在这之后都不会升高,请在该位置用 0 来代替。
例如,给定一个列表 temperatures = [73, 74, 75, 71, 69, 72, 76, 73],你的输出应该是 [1, 1, 4, 2, 1, 1, 0, 0]。
思路
通常是一维数组,要寻找任一个元素的右边或者左边第一个比自己大或者小的元素的位置,此时我们就要想到可以用单调栈了。
时间复杂度为$O(n)$。
例如本题其实就是找找到一个元素右边第一个比自己大的元素。
此时就应该想到用单调栈了。
单调栈的本质是空间换时间,因为在遍历的过程中需要用一个栈来记录右边第一个比当前元素的元素,优点是只需要遍历一次。
在使用单调栈的时候首先要明确如下几点:
- 单调栈里存放的元素是什么?
单调栈里只需要存放元素的下标i就可以了,如果需要使用对应的元素,直接T[i]就可以获取。
- 单调栈里元素是递增呢? 还是递减呢?
注意一下顺序为 从栈头到栈底的顺序,因为单纯的说从左到右或者从前到后,不说栈头朝哪个方向的话,大家一定会越看越懵。
这里我们要使用递增循序(再强调一下是指从栈头到栈底的顺序),因为只有递增的时候,加入一个元素i,才知道栈顶元素在数组中右面第一个比栈顶元素大的元素是i。
使用单调栈主要有三个判断条件。
- 当前遍历的元素T[i]小于栈顶元素T[st.top()]的情况
- 当前遍历的元素T[i]等于栈顶元素T[st.top()]的情况
- 当前遍历的元素T[i]大于栈顶元素T[st.top()]的情况
接下来我们用temperatures = [73, 74, 75, 71, 71, 72, 76, 73]为例来逐步分析,输出应该是 [1, 1, 4, 2, 1, 1, 0, 0]。
首先先将第一个遍历元素加入单调栈

加入T[1] = 74,因为T[1] > T[0](当前遍历的元素T[i]大于栈顶元素T[st.top()]的情况),而我们要保持一个递增单调栈(从栈头到栈底),所以将T[0]弹出,T[1]加入,此时result数组可以记录了,result[0] = 1,即T[0]右面第一个比T[0]大的元素是T[1]。

加入T[2],同理,T[1]弹出

加入T[3],T[3] < T[2] (当前遍历的元素T[i]小于栈顶元素T[st.top()]的情况),加T[3]加入单调栈。

加入T[4],T[4] == T[3] (当前遍历的元素T[i]等于栈顶元素T[st.top()]的情况),此时依然要加入栈,不用计算距离,因为我们要求的是右面第一个大于本元素的位置,而不是大于等于!

加入T[5],T[5] > T[4] (当前遍历的元素T[i]大于栈顶元素T[st.top()]的情况),将T[4]弹出,同时计算距离,更新result

T[4]弹出之后, T[5] > T[3] (当前遍历的元素T[i]大于栈顶元素T[st.top()]的情况),将T[3]继续弹出,同时计算距离,更新result

直到发现T[5]小于T[st.top()],终止弹出,将T[5]加入单调栈

加入T[6],同理,需要将栈里的T[5],T[2]弹出

同理,继续弹出

此时栈里只剩下了T[6]

加入T[7], T[7] < T[6] 直接入栈,这就是最后的情况,result数组也更新完了。

其实定义result数组的时候,就应该直接初始化为0,如果result没有更新,说明这个元素右面没有更大的了,也就是为0。
以上在图解的时候,已经把,这三种情况都做了详细的分析。
- 情况一:当前遍历的元素T[i]小于栈顶元素T[st.top()]的情况
- 情况二:当前遍历的元素T[i]等于栈顶元素T[st.top()]的情况
- 情况三:当前遍历的元素T[i]大于栈顶元素T[st.top()]的情况
代码如下:
/**
* 单调栈,栈内从栈顶到栈底顺序要么从大到小 要么从小到大,本题从栈顶到栈底从小到大
* <p>
* 入站元素要和当前栈内栈首元素进行比较
* 若大于栈首则 则与元素下标做差
* 若小于等于则放入
*
* @param temperatures
* @return
*/
public static int[] dailyTemperatures(int[] temperatures) {
Stack<Integer> stack = new Stack<>();
int[] res = new int[temperatures.length];
for (int i = 0; i < temperatures.length; i++) {
/**
* 取出下标进行元素值的比较
*/
while (!stack.isEmpty() && temperatures[i] > temperatures[stack.peek()]) {
int preIndex = stack.pop();
res[preIndex] = i - preIndex;
}
/**
* 注意 放入的是元素位置
*/
stack.push(i);
}
return res;
}
496.下一个更大元素 I
给你两个 没有重复元素 的数组 nums1 和 nums2 ,其中nums1 是 nums2 的子集。
请你找出 nums1 中每个元素在 nums2 中的下一个比其大的值。
nums1 中数字 x 的下一个更大元素是指 x 在 nums2 中对应位置的右边的第一个比 x 大的元素。如果不存在,对应位置输出 -1 。
思路
在 739. 每日温度 中是求每个元素下一个比当前元素大的元素的位置。
本题则是说nums1 是 nums2的子集,找nums1中的元素在nums2中下一个比当前元素大的元素。
看上去和 739. 每日温度就如出一辙了。
从题目示例中我们可以看出最后是要求nums1的每个元素在nums2中下一个比当前元素大的元素,那么就要定义一个和nums1一样大小的数组result来存放结果。
在遍历nums2的过程中,我们要判断nums2[i]是否在nums1中出现过,因为最后是要根据nums1元素的下标来更新result数组。
注意题目中说是两个没有重复元素 的数组 nums1 和 nums2。
没有重复元素,我们就可以用map来做映射了。根据数值快速找到下标,还可以判断nums2[i]是否在nums1中出现过。
预处理代码如下:
unordered_map<int, int> umap; // key:下标元素,value:下标
for (int i = 0; i < nums1.size(); i++) {
umap[nums1[i]] = i;
}
使用单调栈,首先要想单调栈是从大到小还是从小到大。
本题和739. 每日温度是一样的。
栈头到栈底的顺序,要从小到大,也就是保持栈里的元素为递增顺序。只要保持递增,才能找到右边第一个比自己大的元素。
接下来就要分析如下三种情况,一定要分析清楚。
- 情况一:当前遍历的元素T[i]小于栈顶元素T[st.top()]的情况
此时满足递增栈(栈头到栈底的顺序),所以直接入栈。
- 情况二:当前遍历的元素T[i]等于栈顶元素T[st.top()]的情况
如果相等的话,依然直接入栈,因为我们要求的是右边第一个比自己大的元素,而不是大于等于!
- 情况三:当前遍历的元素T[i]大于栈顶元素T[st.top()]的情况
此时如果入栈就不满足递增栈了,这也是找到右边第一个比自己大的元素的时候。
判断栈顶元素是否在nums1里出现过,(注意栈里的元素是nums2的元素),如果出现过,开始记录结果。
此时栈顶元素在nums2中右面第一个大的元素是nums2[i]即当前遍历元素。
代码如下:
while (!st.empty() && nums2[i] > nums2[st.top()]) {
if (umap.count(nums2[st.top()]) > 0) { // 看map里是否存在这个元素
int index = umap[nums2[st.top()]]; // 根据map找到nums2[st.top()] 在 nums1中的下标
result[index] = nums2[i];
}
st.pop();
}
st.push(i);
代码如下:
class Solution {
public int[] nextGreaterElement(int[] nums1, int[] nums2) {
Stack<Integer> temp = new Stack<>();
int[] res = new int[nums1.length];
Arrays.fill(res,-1);
HashMap<Integer, Integer> hashMap = new HashMap<>();
for (int i = 0 ; i< nums1.length ; i++){
hashMap.put(nums1[i],i);
}
temp.add(0);
for (int i = 1; i < nums2.length; i++) {
if (nums2[i] <= nums2[temp.peek()]) {
temp.add(i);
} else {
while (!temp.isEmpty() && nums2[temp.peek()] < nums2[i]) {
if (hashMap.containsKey(nums2[temp.peek()])){
Integer index = hashMap.get(nums2[temp.peek()]);
res[index] = nums2[i];
}
temp.pop();
}
temp.add(i);
}
}
return res;
}
}
503.下一个更大元素II
给定一个循环数组(最后一个元素的下一个元素是数组的第一个元素),输出每个元素的下一个更大元素。数字 x 的下一个更大的元素是按数组遍历顺序,这个数字之后的第一个比它更大的数,这意味着你应该循环地搜索它的下一个更大的数。如果不存在,则输出 -1。
思路:
这道题和 739. 每日温度 也几乎如出一辙。
不同的时候本题要循环数组了。
如何处理循环数组。
在遍历的过程中模拟走了两边nums。
代码如下:
class Solution {
public int[] nextGreaterElements(int[] nums) {
//边界判断
if(nums == null || nums.length <= 1) {
return new int[]{-1};
}
int size = nums.length;
int[] result = new int[size];//存放结果
Arrays.fill(result,-1);//默认全部初始化为-1
Stack<Integer> st= new Stack<>();//栈中存放的是nums中的元素下标
for(int i = 0; i < 2*size; i++) {
while(!st.empty() && nums[i % size] > nums[st.peek()]) {
result[st.peek()] = nums[i % size];//更新result
st.pop();//弹出栈顶
}
st.push(i % size);
}
return result;
}
}
42. 接雨水
给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。
示例 1:
- 输入:height = [0,1,0,2,1,0,1,3,2,1,2,1]
- 输出:6
- 解释:上面是由数组 [0,1,0,2,1,0,1,3,2,1,2,1] 表示的高度图,在这种情况下,可以接 6 个单位的雨水(蓝色部分表示雨水)。

思路:
- 首先单调栈是按照行方向来计算雨水,如图:

- 使用单调栈内元素的顺序
从大到小还是从小到大呢?
从栈头(元素从栈头弹出)到栈底的顺序应该是从小到大的顺序。
因为一旦发现添加的柱子高度大于栈头元素了,此时就出现凹槽了,栈头元素就是凹槽底部的柱子,栈头第二个元素就是凹槽左边的柱子,而添加的元素就是凹槽右边的柱子。
如图:

- 遇到相同高度的柱子怎么办。
遇到相同的元素,更新栈内下标,就是将栈里元素(旧下标)弹出,将新元素(新下标)加入栈中。
例如 5 5 1 3 这种情况。如果添加第二个5的时候就应该将第一个5的下标弹出,把第二个5添加到栈中。
因为我们要求宽度的时候 如果遇到相同高度的柱子,需要使用最右边的柱子来计算宽度。
如图所示:

- 栈里要保存什么数值
是用单调栈,其实是通过 长 * 宽 来计算雨水面积的。
长就是通过柱子的高度来计算,宽是通过柱子之间的下标来计算,
那么栈里有没有必要存一个pair<int, int>类型的元素,保存柱子的高度和下标呢。
其实不用,栈里就存放int类型的元素就行了,表示下标,想要知道对应的高度,通过height[stack.top()] 就知道弹出的下标对应的高度了。
所以栈的定义如下:
stack<int> st; // 存着下标,计算的时候用下标对应的柱子高度
明确了如上几点,我们再来看处理逻辑。
单调栈处理逻辑
先将下标0的柱子加入到栈中,st.push(0);。
然后开始从下标1开始遍历所有的柱子,for (int i = 1; i < height.size(); i++)。
如果当前遍历的元素(柱子)高度小于栈顶元素的高度,就把这个元素加入栈中,因为栈里本来就要保持从小到大的顺序(从栈头到栈底)。
代码如下:
if (height[i] < height[st.top()]) st.push(i);
如果当前遍历的元素(柱子)高度等于栈顶元素的高度,要跟更新栈顶元素,因为遇到相相同高度的柱子,需要使用最右边的柱子来计算宽度。
代码如下:
if (height[i] == height[st.top()]) { // 例如 5 5 1 7 这种情况
st.pop();
st.push(i);
}
如果当前遍历的元素(柱子)高度大于栈顶元素的高度,此时就出现凹槽了,如图所示:

取栈顶元素,将栈顶元素弹出,这个就是凹槽的底部,也就是中间位置,下标记为mid,对应的高度为height[mid](就是图中的高度1)。
此时的栈顶元素st.top(),就是凹槽的左边位置,下标为st.top(),对应的高度为height[st.top()](就是图中的高度2)。
当前遍历的元素i,就是凹槽右边的位置,下标为i,对应的高度为height[i](就是图中的高度3)。
此时大家应该可以发现其实就是栈顶和栈顶的下一个元素以及要入栈的三个元素来接水!
那么雨水高度是 min(凹槽左边高度, 凹槽右边高度) - 凹槽底部高度,代码为:int h = min(height[st.top()], height[i]) - height[mid];
雨水的宽度是 凹槽右边的下标 - 凹槽左边的下标 - 1(因为只求中间宽度),代码为:int w = i - st.top() - 1 ;
当前凹槽雨水的体积就是:h * w。
求当前凹槽雨水的体积代码如下:
while (!st.empty() && height[i] > height[st.top()]) { // 注意这里是while,持续跟新栈顶元素
int mid = st.top();
st.pop();
if (!st.empty()) {
int h = min(height[st.top()], height[i]) - height[mid];
int w = i - st.top() - 1; // 注意减一,只求中间宽度
sum += h * w;
}
}
代码如下:
class Solution {
public int trap(int[] height){
int size = height.length;
if (size <= 2) return 0;
// in the stack, we push the index of array
// using height[] to access the real height
Stack<Integer> stack = new Stack<Integer>();
stack.push(0);
int sum = 0;
for (int index = 1; index < size; index++){
int stackTop = stack.peek();
if (height[index] < height[stackTop]){
stack.push(index);
}else if (height[index] == height[stackTop]){
// 因为相等的相邻墙,左边一个是不可能存放雨水的,所以pop左边的index, push当前的index
stack.pop();
stack.push(index);
}else{
//pop up all lower value
int heightAtIdx = height[index];
while (!stack.isEmpty() && (heightAtIdx > height[stackTop])){
int mid = stack.pop();
if (!stack.isEmpty()){
int left = stack.peek();
int h = Math.min(height[left], height[index]) - height[mid];
int w = index - left - 1;
int hold = h * w;
if (hold > 0) sum += hold;
stackTop = stack.peek();
}
}
stack.push(index);
}
}
return sum;
}
}
84.柱状图中最大的矩形
给定 n 个非负整数,用来表示柱状图中各个柱子的高度。每个柱子彼此相邻,且宽度为 1 。
求在该柱状图中,能够勾勒出来的矩形的最大面积。

思路:
- 接雨水是找每个柱子左右两边第一个大于该柱子高度的柱子,而本题是找每个柱子左右两边第一个小于该柱子的柱子。
这里就涉及到了单调栈很重要的性质,就是单调栈里的顺序,是从小到大还是从大到小。
那么因为本题是要找每个柱子左右两边第一个小于该柱子的柱子,所以从栈头(元素从栈头弹出)到栈底的顺序应该是从大到小的顺序!
我来举一个例子,如图:

只有栈里从大到小的顺序,才能保证栈顶元素找到左右两边第一个小于栈顶元素的柱子。
所以本题单调栈的顺序正好与接雨水反过来。
此时大家应该可以发现其实就是栈顶和栈顶的下一个元素以及要入栈的三个元素组成了我们要求最大面积的高度和宽度
剩下就是分析清楚如下三种情况:
- 情况一:当前遍历的元素heights[i]小于栈顶元素heights[st.top()]的情况
- 情况二:当前遍历的元素heights[i]等于栈顶元素heights[st.top()]的情况
- 情况三:当前遍历的元素heights[i]大于栈顶元素heights[st.top()]的情况
代码如下:
单调栈
class Solution {
int largestRectangleArea(int[] heights) {
Stack<Integer> st = new Stack<Integer>();
// 数组扩容,在头和尾各加入一个元素
int [] newHeights = new int[heights.length + 2];
newHeights[0] = 0;
newHeights[newHeights.length - 1] = 0;
for (int index = 0; index < heights.length; index++){
newHeights[index + 1] = heights[index];
}
heights = newHeights;
st.push(0);
int result = 0;
// 第一个元素已经入栈,从下标1开始
for (int i = 1; i < heights.length; i++) {
// 注意heights[i] 是和heights[st.top()] 比较 ,st.top()是下标
if (heights[i] > heights[st.peek()]) {
st.push(i);
} else if (heights[i] == heights[st.peek()]) {
st.pop(); // 这个可以加,可以不加,效果一样,思路不同
st.push(i);
} else {
while (heights[i] < heights[st.peek()]) { // 注意是while
int mid = st.peek();
st.pop();
int left = st.peek();
int right = i;
int w = right - left - 1;
int h = heights[mid];
result = Math.max(result, w * h);
}
st.push(i);
}
}
return result;
}
}
剑指 Offer 33. 二叉搜索树的后序遍历序列
输入一个整数数组,判断该数组是不是某二叉搜索树的后序遍历结果。如果是则返回
true,否则返回false。假设输入的数组的任意两个数字都互不相同。
思路:
二叉搜索树的后序遍历倒序: [ 根节点 | 右子树 | 左子树 ] 。类似 先序遍历的镜像 ,即先序遍历为 “根、左、右” 的顺序,而后序遍历的倒序为 “根、右、左” 顺序。

根据以上特点,考虑借助单调栈 实现:
1、借助一个单调栈 stack存储值递增的节点;
2、每当遇到值递减的节点 ri,则通过出栈来更新节点 ri的父节点root;
3、每轮判断ri和root的值关系:
(1)如果ri>root,则说明不满足二叉搜索树定义,直接返回false
(2)如果ri<root,则说明满足二叉搜索树定义,则继续遍历
代码如下:
class Solution {
public boolean verifyPostorder(int[] postorder) {
// 整体思路:搜索树的后序遍历的倒叙类似于:根节点、右子树、左子树这样的结构
// 所以遍历过程中一定会遇到先升序后降序的过程,设计一个单调栈,栈顶到栈底递减,如果遇到小于栈顶的节点,
// 说明到了左子树的部分,这个时候不断的出栈,找到大于这个节点的数中最小的数(不断的出栈直到为空,这个数就是当前节点的父节点),最后再把当前节点入栈,之后再每次遍历过程中都要判断左子树的值是否比父节点小,如果不满足就返回false
Stack<Integer> st = new Stack<>();
// 初始化单调栈,父节点值 root =+∞ (初始值为正无穷大,可把树的根节点看为此无穷大节点的左孩子);
int rootValue = Integer.MAX_VALUE;
// 倒叙遍历该中序数组
for (int i = postorder.length - 1;i >= 0;i--) {
if (postorder[i] > rootValue) {
return false;
}
while (!st.isEmpty() && st.peek() > postorder[i]) {
rootValue = st.pop();
}
st.push(postorder[i]);
}
return true;
}
}