为什么大部分 hashcode 方法使用 31
在名著 《Effective Java》第 42 页就有对 hashCode 为什么采用 31 做了说明:
- 因为他是一个奇素数。如果乘数是偶数,并且乘法溢出的话,信息就会丢失,因为与2相乘等价于移位运算(低位补0)。使用素数的好处并不很明显,但是习惯上使用素数来计算散列结果。
- 31 有个很好的性能,即用移位和减法来代替乘法,可以得到更好的性能: 31 * i == (i << 5)- i, 现代的 VM 可以自动完成这种优化。这个公式可以很简单的推导出来。
通过实验对比,可以看出用31作为乘数,最终的碰撞率很小,效果很明显
HashMap 的 hash 算法为什么右移 16 位,为什么要使用 ^ 位异或)
首先,假设有一种情况,
对象 A 的 hashCode 为
1000010001110001000001111000000,
对象 B 的 hashCode 为
0111011100111000101000010100000。
如果数组长度是16,也就是 15 & (与运算)这两个数, 你会发现结果都是0。这样的散列结果太让人失望了。很明显不是一个好的散列算法。
但是如果我们将 hashCode 值右移 16 位,也就是取 int 类型的一半,刚好将该二进制数对半切开。并且使用位异或运算(如果两个数对应的位置相反,则结果为1,反之为0),这样的话,就能避免我们上面的情况的发生。
在HashMap源码里获取hashCode之后,还进行了一次扰动计算,(h = key.hashCode()) ^ (h >>> 16)。把哈希值右移 16 位,也就正好是自己长度的一
半,之后与原哈希值做异或运算,这样就混合了原哈希值中的高位和低位,增大了 随机性。

为什么hashmap的数组长度是2的倍数
要保证 & 中的二进制位全为 1 (len-1),才能最大限度的利用 hash 值,并更好的散列,只有全是1 ,才能有更多的散列结果,这样的数组长度才会出现一个 0111 除高位以外都是 1 的特征,如果是 1010,有的散列结果是永远都不会出现的,比如 0111,0101,1111,1110…,只要 & 之前的数有 0, 对应的 1 肯定就不会出现(因为只有都是1才会为1)。大大限制了散列的范围。
假设我们的数组长度是10,还是上面的公式:
1010 & 101010100101001001000
结果:1000 = 8
1010 & 101000101101001001001
结果:1000 = 8
1010 & 101010101101101001010
结果: 1010 = 10
1010 & 101100100111001101100
结果: 1000 = 8
这种散列结果,会导致这些不同的key值全部进入到相同的插槽中,形成链表,性能急剧下降。
HashMap的初始化容量和负载因子
在初始化 HashMap 的时候,如果传一个 17 个的值new HashMap<>(17);,它会怎么处理呢?
在 HashMap 的初始化中,有这样一段方法:
public HashMap(int initialCapacity, float loadFactor) {
...
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
- 阀值 threshold,通过方法 tableSizeFor 进行计算,是根据初始化来计算的
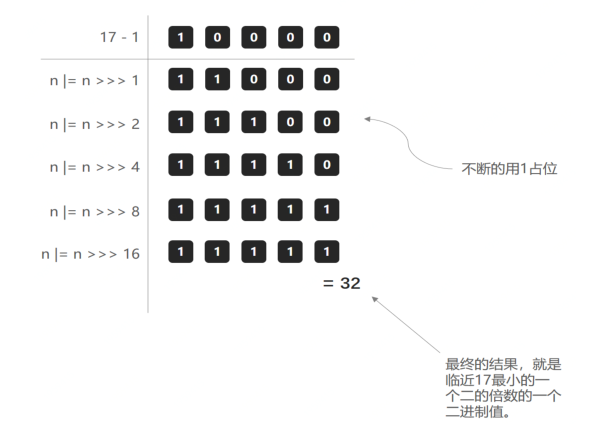
- 这个方法也就是要寻找比初始值大的,最小的那个 2 进制数值。比如传了 17,我应该找到的是 32。
计算阀值大小的方法:
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
- 向右移位1,2,4,8,16,主要是为了把二进制的各个位置都填上 1,当二进制的各个位置都是 1 以后,就是一个标准的 2 的倍数减 1 了,最后把结果加 1 再返回即可
以17作为初始化容量计算阈值的过程为例:
负载因子
负载因子,可以理解成一辆车可承重重量超过某个阀值时,把货放到新的车上
在 HashMap 中,负载因子决定了数据量多少了以后进行扩容,举一个例子,我们准备了 7 个元素,但是最后还有 3 个位置空余,2 个位置存放了 2 个元素。 所以可能即使你数据比数组容量大时也是不一定能正好的把数组占满的,而是在某些小标位置出现了大量的碰撞,只能在同一个位置用链表存放,那么这样就失去了 Map 数组的性能。
所以,要选择一个合理的大小下进行扩容,默认值 0.75 就是说当阀值容量占了3/4 时赶紧扩容,减少 Hash 碰撞。
扩容元素拆分
为什么扩容,因为数组长度不足了。那扩容最直接的问题,就是需要把元素拆分到新的数组中。拆分元素的过程中,原 jdk1.7 中会需要重新计算哈希值,但是到 jdk1.8 中已经进行优化,不在需要重新计算,提升了拆分的性能 。
随机使用一些字符串计算他们分别在 16 位长度和 32 位长度数组下的索引分配情况,看哪些数据被重新路由到了新的地址。
结果显示:原哈希值与扩容新增出来的长度 16,进行&运算,如果值等于 0,则下标位置不变。如果不为0,那么新的位置则是原来位置上加 16。这样一来,就不需要在重新计算每一个数组中元素的哈希值了