Abstract
Problem:
Neural networks : computationally intensive and memory intensive , difficult to deploy on embedded systems(嵌入式系统) with limited hardware resources.
Structure
Deep Compression ,three stage pipeline:pruning,trained quantization,Huffman coding
reduce the storage requirement of neural networks by 35× to 49× without affecting their accuracy.
Steps
1、prun the network by learning only the important connections.
2、quantize the weights to enforce weight sharing.
3、apply Huffman coding.
After the first two steps,retrain the network to fine tune the remaining connections and the quantized centroids.
Performance
Pruning reduces the number of connections by 9× to 13×
Quantization reduces the number of bits that represent each connection from 32 to 5.
On ImageNet dataset,this method reduced the storage required by AlexNet by 35×,from 240MB to 6.9MB,without loss of accuracy.
Reduced the size of VGG-16 by 49×from 552MB to 11.3MB, again with no loss of accuracy.
Allows fitting the model into on-chip SRAM cache rather than off-chip DRAM memory.
Facilitates the use of complex neural networks in mobile applications where application size and download bandwidth are constrained.
Benchmarked on CPU,GPU and mobile GPU,compressed network has 3× to 4× layerwise speedup and 3×to 7× better energy efficiency.
1 Intrucduction
Deep Neural Networks:the state-of-art technique for computer vision tasks.
The large number of weights consumes considerable storage and memory width. For example,the AlexNet Caffemodel is over 200MB, and the VGG-16 Caffemodel is over 500MB (BVLC).
This makes it difficult to deploy deep neural networks on mobile system.
Reason why it is difficult to deploy deep neural networks on mobile system:
STORAGE:First, some App Store has the restriction “apps above 100 MB will not download until you connect to Wi-Fi”.Although having deep neural networks running on mobile has many great features such as better privacy, less network bandwidth and real time processing, the large storage overhead prevents deep neural networks from being incorporated into mobile apps.
ENERGY CONSUMPTION:The second issue is energy consumption. Running large neural networks require a lot of memory bandwidth to fetch the weights and a lot of computation to do dot products—which inturn consumes considerable energy. Mobile devices are battery constrained, making power hungry applications such as deep neural networks hard to deploy.
Energy consumption is dominated by memory access.
Under 45nm CMOS technology, a 32 bit floating point add consumes 0.9pJ, a 32bit SRAM cache access takes 5pJ, while a 32bit DRAM memory access takes 640pJ, which is 3 orders of magnitude of an add operation. Large networks do not fit in on-chip storage and hence require the more costly DRAM accesses. Running a 1 billion connection neural network, for example, at 20fps would require (20Hz)(1G)(640pJ) = 12.8W just for DRAM access - well beyond the power envelope of a typical mobile device.
Goal:
To reduce the storage and energy required to run inference on such large networks so they can be deployed on mobile devices.
Method:
Deep Compression: a three-stage pipeline reduce the storage perserve the original accuracy
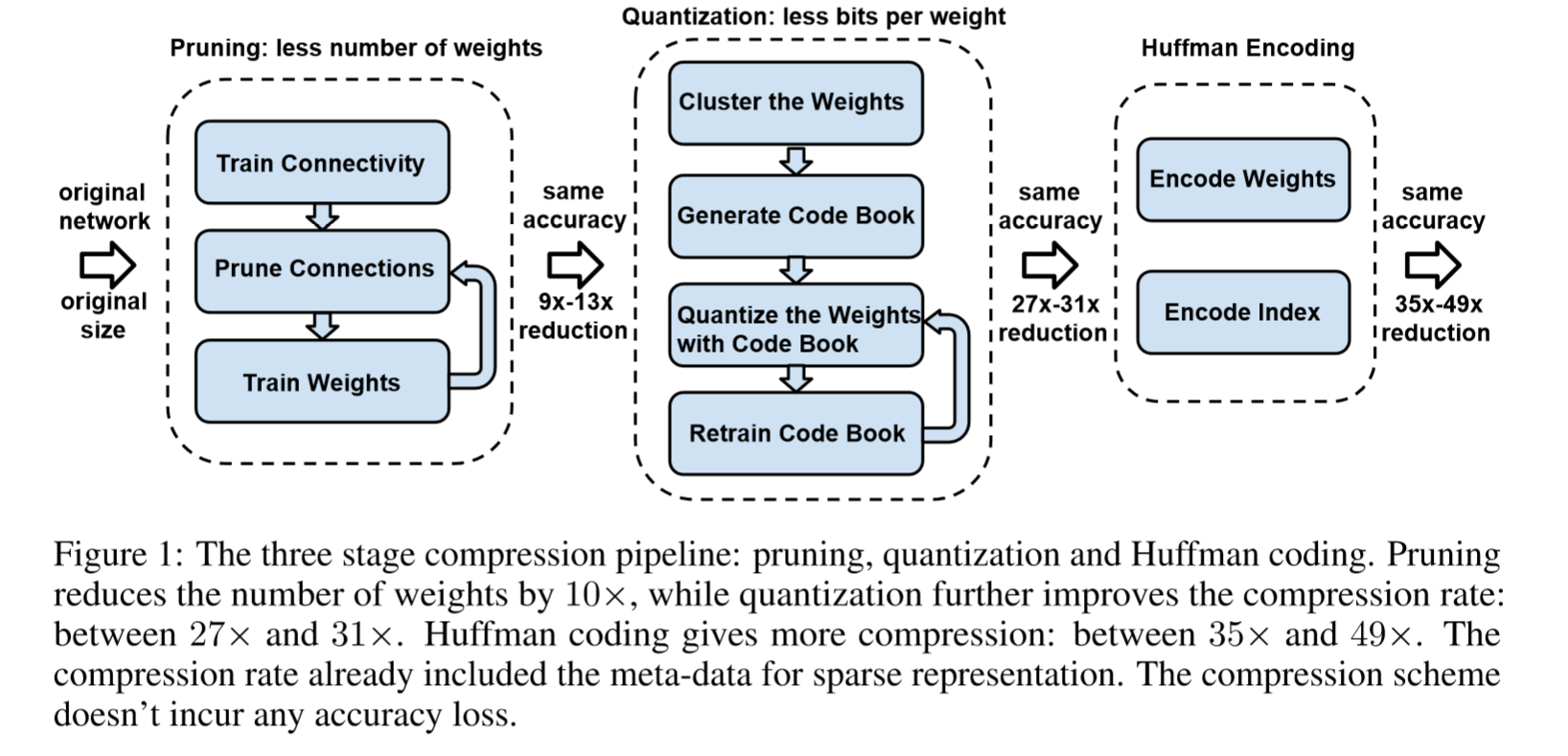
First,we prune the networking by removing the redundant connections , keeping only the most informative connections.
Next, the weights are quantized so that multiple connections share the same weight, thus only the codebook (effective weights) and the indices need to be stored.
Finally, we apply Huffman coding to take advantage of the biased distribution of effective weights.
Main Insight
pruning and trained quantization are able to compress the network without interfering each other,thus leading to surpringly high compression rate.
making the required storage so small(a few megabytes) that all weights can be cached on chip instead of going to off-chip DRAM which is energy consuming.
Hardware
Based on “deep compression”, the EIE hardware accelerator Han et al. (2016) was later proposed that works on the compressed model, achieving significant speedup and energy efficiency improvement.
2 Network Pruning
History
Network pruning has been widely studied to compress CNN models.
In early work, network pruning proved to be a valid way to reduce the network complexity and over-fitting (LeCun et al., 1989; Hanson & Pratt, 1989; Hassibi et al., 1993; Str¨om, 1997).
Recently Han et al. (2015) pruned state of-the-art CNN models with no loss of accuracy.
Our Work
Build on top of that approach.
Start by learning the connectivity via normal network training.
Next,prune the small-weight connections:all connections with weights below a threshold are removed from the network.
Finally,retrain the network to learn the final weights for the remaining sparse(稀疏) connections.
Pruning reduced the number of parameters by 9×and 13×for AlexNet and VGG-16 model.
How to Store the Weights and Index
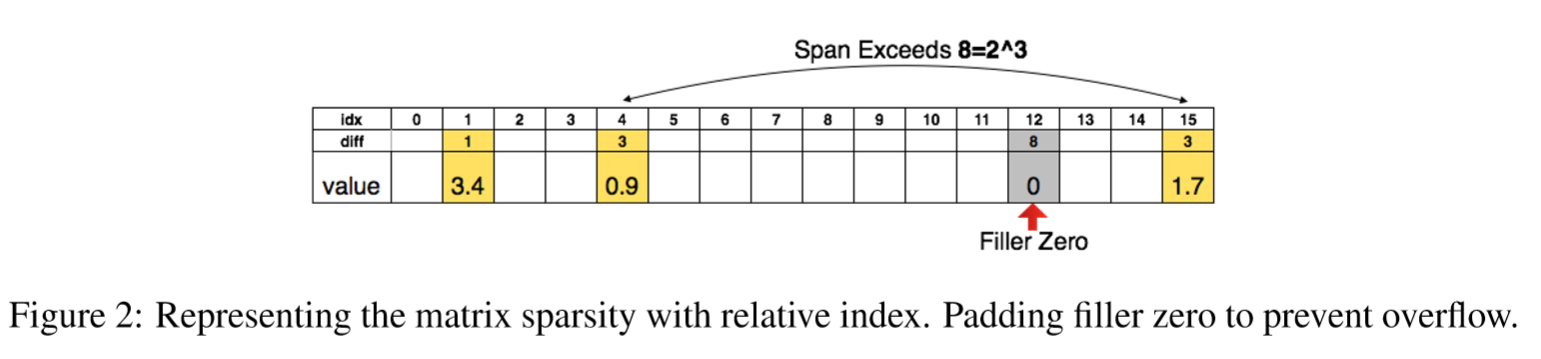
Store the sparse structure that results from pruning using compressed sparse row(CSR) or compressed sparce column(CSC) format,which requires 2a+n+1 numbers,where a is the number of non-zero elements and n is the number of rows or columns.
To compress further,we store the index difference instead of the absolute position,and encode this difference in 8 bits for conv layer and 5 bits for fc layer.
When we need an index difference larger than the bound, we the zero padding solution shown in Figure 2: in case when the difference exceeds 8, the largest 3-bit (as an example) unsigned number, we add a filler zero.
3 Trained Quantization and Weight Sharing
Principle:
Reduce the number of bits required to represent each weight.
Limit the number of effective weights need to store by having multiple connections share the same weights,and then fine tuned those shared weights.
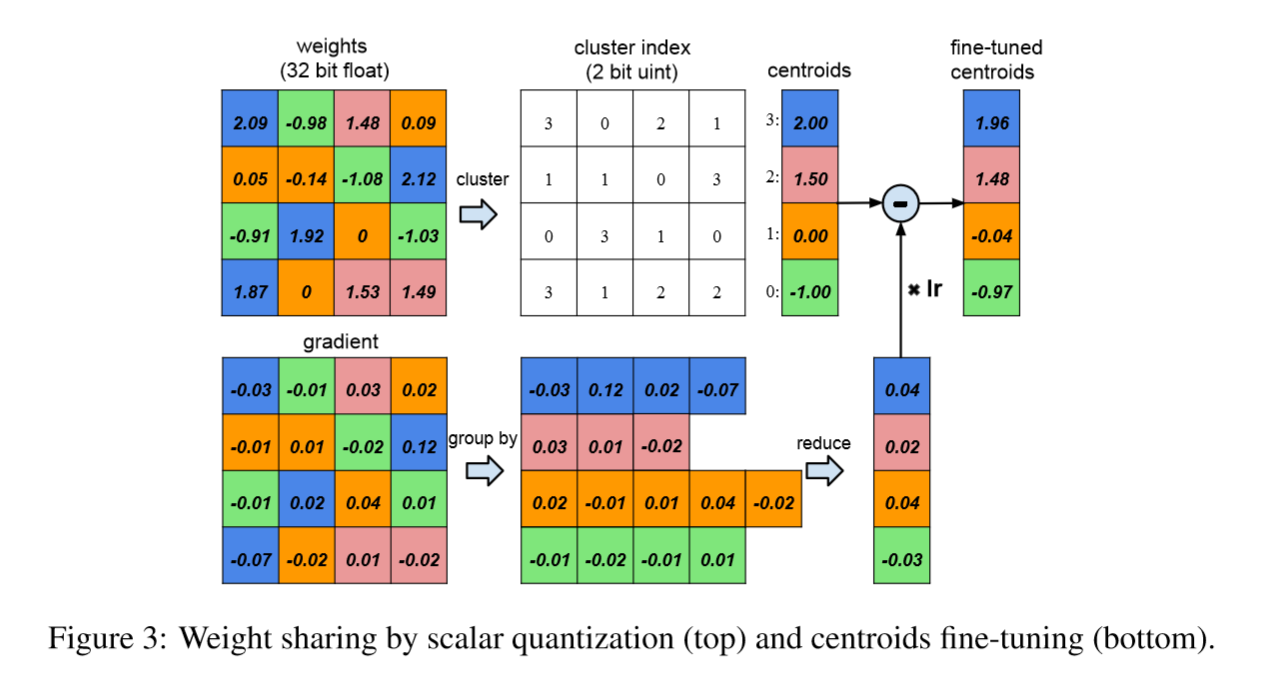
Details:
A layer with 4 input neurons and 4 output neurons,the weight is a 4×4 matrix
4×4 weight matrix and 4×4 gradient matrix
The weights are quantized to 4 bins (denoted with 4 colors), all the weights in the same bin share the same value, only store a small index into a table of shared weights.
During update, all the gradients are grouped by the color and summed together, multiplied by the learning rate and subtracted from the shared centroids from last iteration.
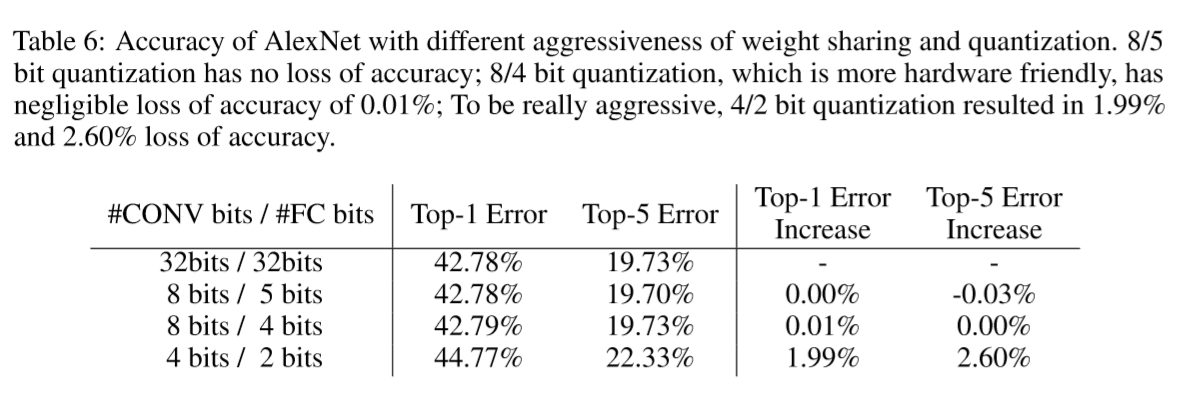
For pruned AlexNet, we are able to quantize to 8-bits (256 shared weights) for each CONV layers, and 5-bits (32 shared weights) for each FC layer without any loss of accuracy.
Compression Rate:
k clusters, need log2(k) bits to encode the index
A network with n connections and each connection is represented with b bits
[r = frac{{nb}}{{n{{log }_2}k + kb}}]
Example:
Figure 3 shows the weights of a single layer neural network with four input units and fouroutputunits. There are 4×4 = 16 weights originally but there are only 4 shared weights: similar weights are grouped together to share the same value. Originally we need to store 16 weights each has 32 bits, now we need to store only 4 effective weights (blue, green, red and orange), each has 32 bits, together with 16 2-bit indices giving a compression rate of 16∗32/(4∗32 + 2∗16) = 3.2
3.1 Weight Sharing
k-means clustering: identify the shared weights for each layer of a trained network,weights that fall into the same cluster will share the same weight.
Weights are not shared across layers.That means we need to use k-means clustering in every layer.
Partition n original weights W = {w1,w2,...,wn} into k clusters C = {c1,c2,...,ck} , n>>k, so as to minimize the within-cluster sum of squares (WCSS):
[mathop {arg min }limits_C sumlimits_{i = 1}^k {sumlimits_{omega in {c_i}} {{{left| {omega - {c_i}} ight|}^2}} } ]
Different from HashNet (Chen et al., 2015) where weight sharing is determined by a hash function before the networks sees any training data, our method determines weight sharing after a network is fully trained, so that the shared weights approximate the original network.
3.2 Initialization of Shared Weights
Centroid initialization impacts the quality of clustering and thus affects the network’s prediction accuracy.
Three initializaion methods: Forgy(random),Density-based,Linear initialization.
In Figure 4 we plotted the original weights’ distribution of conv3 layer in AlexNet(CDF,cumulative distribution function,PDF,probability density function) . The weights forms a bimodal distribution after network pruning. On the bottom it plots the effective weights (centroids) with 3 different initialization methods (shown in blue, red and yellow). In this example, there are 13 clusters.
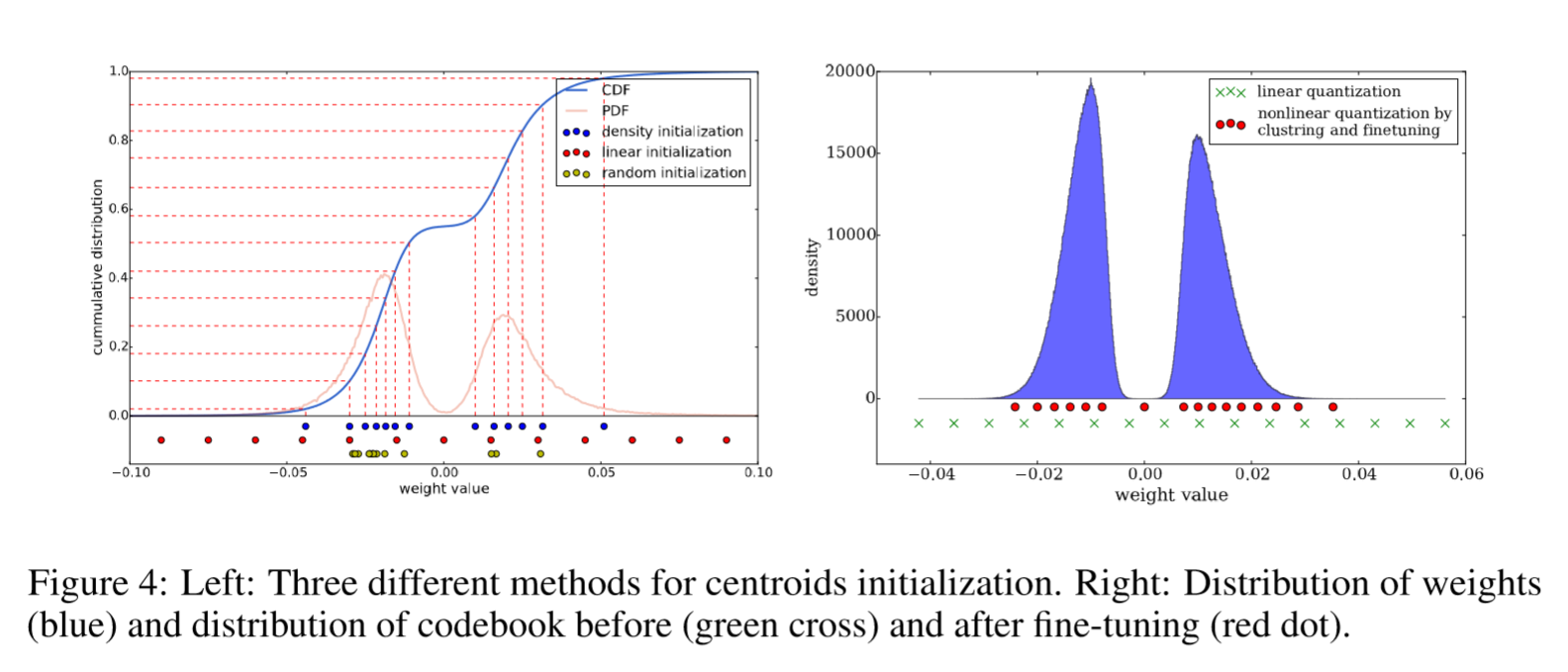
Forgy(random)Initialization
Randomly choose k observations from the data sets and uses these as the initial centroids.Since there are two peaks in the bimodal(两个峰) distribution,Forgy method tend to concentrate around those two peaks.
Density-based initialization
Linearly space the CDF of the weights in the y-axis, then finds the horizontal intersection with the CDF, and finally finds the vertical intersection on the x-axis, which becomes a centroid, as shown in blue dots. This method makes the centroids denser around the two peaks, but more scatted than the Forgy method.
Linear initialization
Linearly space the centroids between the [min, max] of the original weights.
Invariant to the distribution of weights.
Most scattered compared to with the former two methods.
Analysis
Larger weights play a more important role than smaller weights (Hanetal.,2015),but there are fewer of these large weights.
Thus for both Forgy initialization and density-based initialization, very few centroids have large absolute value which results in poor representation of these few large weights.
Linear initialization does not suffer from this problem.
The experiment section compares the accuracy of different initialization methods after clustering and fine-tuning, showing that linear initialization works best.
3.3 Feed-forward and Back-propagation
The centroids of the one-dimensional k-means clustering are the shared weights.
There is one level of indirection(一定的间接性) during feed forward phase and back-propagation phase looking up the weight table.
An index into the shared weight table is stored for each connection. During back-propagation, the gradient for each shared weight is calculated and used to update the shared weight. This procedure is shown in Figure 3.
We denote the loss by L, the weight in the i th column and j th row by Wij, the centroid index of element Wi,j by Iij , the kth centroid of the layer by Ck. By using the indicator function 1(.), the gradient of the centroids is calculated as:
[frac{{partial {cal L}}}{{partial {C_k}}}{ m{ = }}sumlimits_{i,j} {frac{{partial {cal L}}}{{partial {W_{ij}}}}frac{{partial {W_{ij}}}}{{{C_k}}} = } sumlimits_{i,j} {frac{{partial {cal L}}}{{partial {W_{ij}}}}} 1({I_{ij}} = k)]
4 Huffman coding
Huffman code:an optimal prefix code commonly used for lossless data compression.
use variable-length codewords to encode source symbols.
The table is derived from the occurrence probability for each symbol. More common symbols are represented with fewer bits.
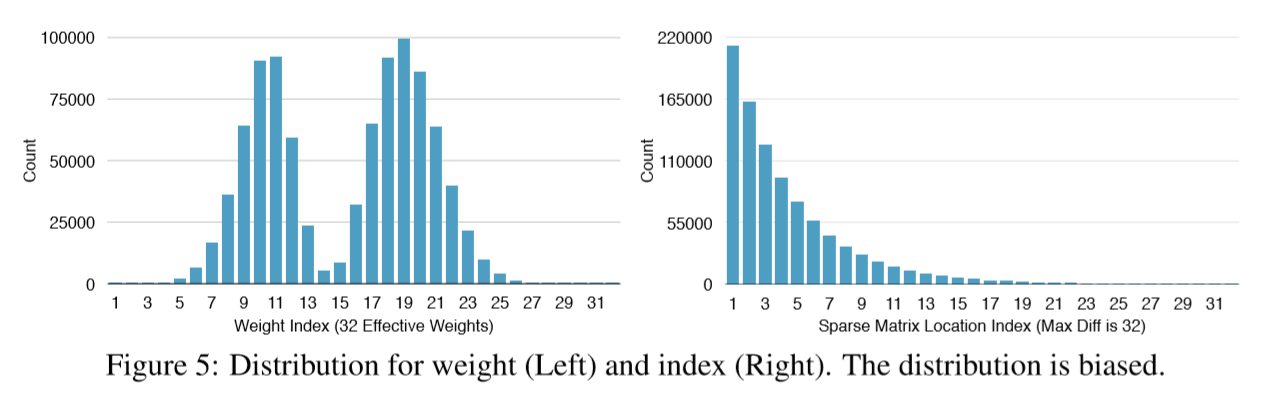
Figure 5 shows the probability distribution of quantized weights and the sparse matrix index of the last fully connected layer in AlexNet. Both distributions are biased: most of the quantized weights are distributed around the two peaks; the sparse matrix index difference are rarely above 20. Experiments show that Huffman coding these non-uniformly distributed values saves 20%−30% of network storage.
5 Experiments
We pruned, quantized, and Huffman encoded four networks: two on MNIST and two on ImageNet data-sets.
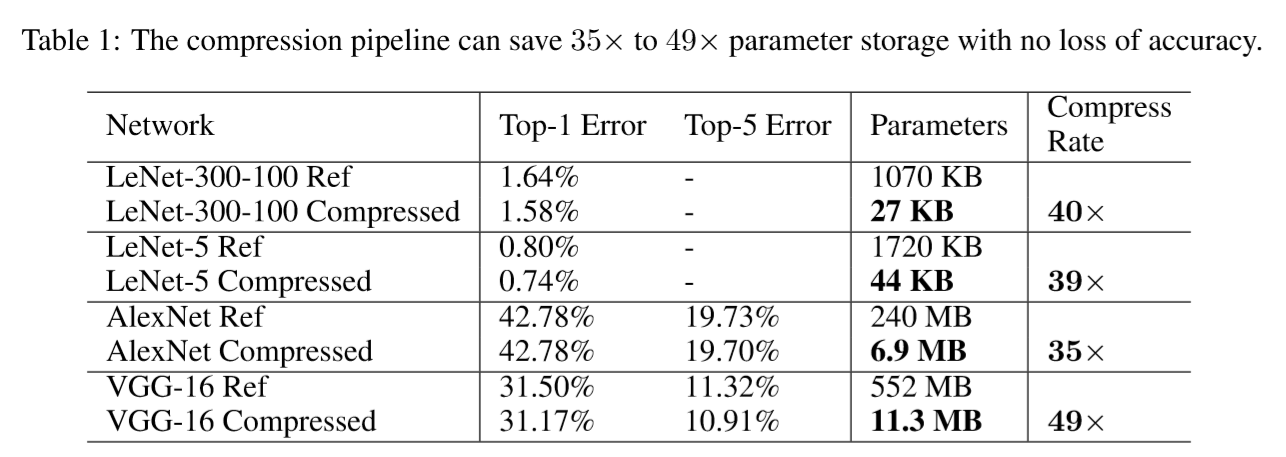
Table 1 shows the network parameters and accuracy before and after pruning.
The compression pipeline saves network storage by 35×to 49×across different networks without loss of accuracy.
The total size of AlexNet decreased from 240MB to 6.9MB, which is small enough to be put into on-chip SRAM, eliminating the need to store the model in energy-consuming DRAM memory.
Training is performed with the Caffe framework.
Pruning is implemented by adding a mask to the blobs to mask out the update of the pruned connections.
Quantization and weight sharing are implemented by maintaining a codebook structure that stores the shared weight, and group-by-index after calculating the gradient of each layer.
Each shared weight is updated with all the gradients that fall into that bucket. Huffman coding doesn’t require training and is implemented offline after all the fine-tuning is finished.
5.1 LeNet-300-100 and LeNet-5 on MNIST
We first experimented on MNIST dataset with LeNet-300-100 and LeNet-5 network.
LeNet-300-100 is a fully connected network with two hidden layers, with 300 and 100 neurons each, which achieves 1.6% error rate on Mnist.
LeNet-5 is a convolutional network that has two convolutional layers and two fully connected layers, which achieves 0.8% error rate on Mnist.
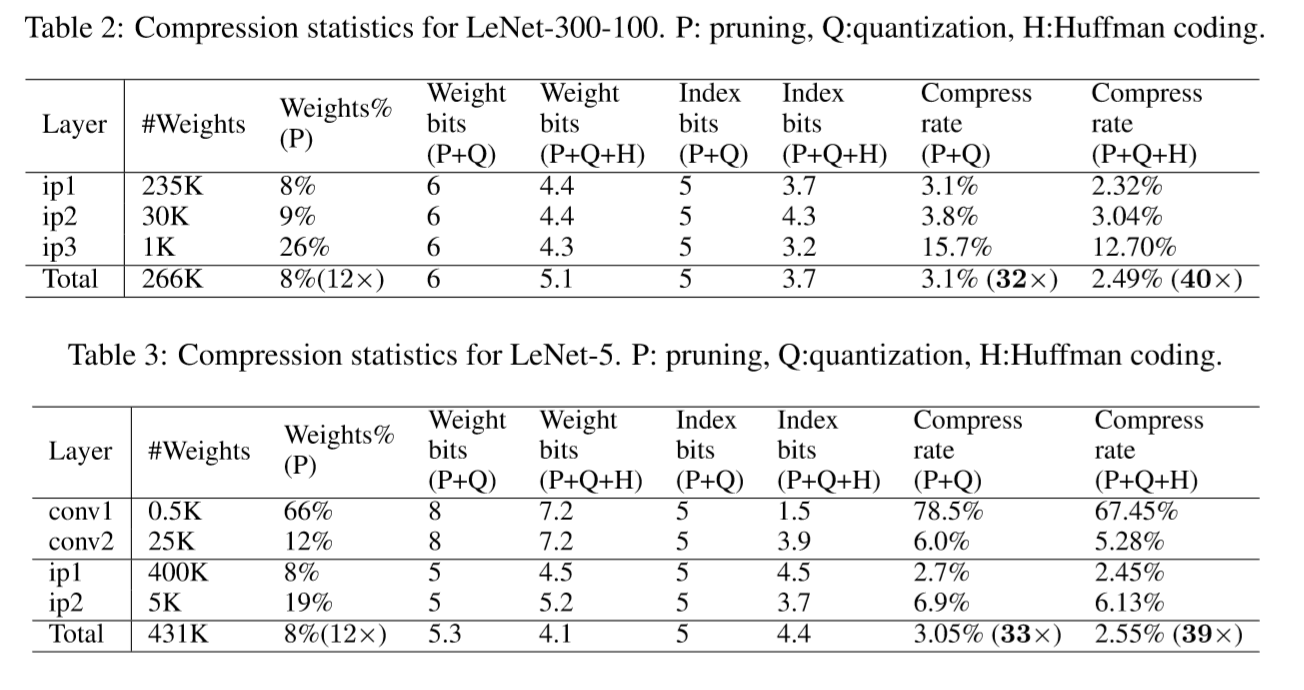
Table 2 and table 3 show the statistics of the compression pipeline.
The compression rate includes the overhead of the codebook and sparse indexes. Most of the saving comes from pruning and quantization (compressed 32×), while Huffman coding gives a marginal gain (compressed 40×)
5.2 AlexNet on ImageNet
Deep Compression on ImageNet ILSVRC-2012 dataset with 1.2M training examples and 50k validation examples.
Reference model:AlexNet Caffe model with 61 million parameters,achieving a top-1 accuracy of 57.2% and a top-5 accuracy of 80.3%.
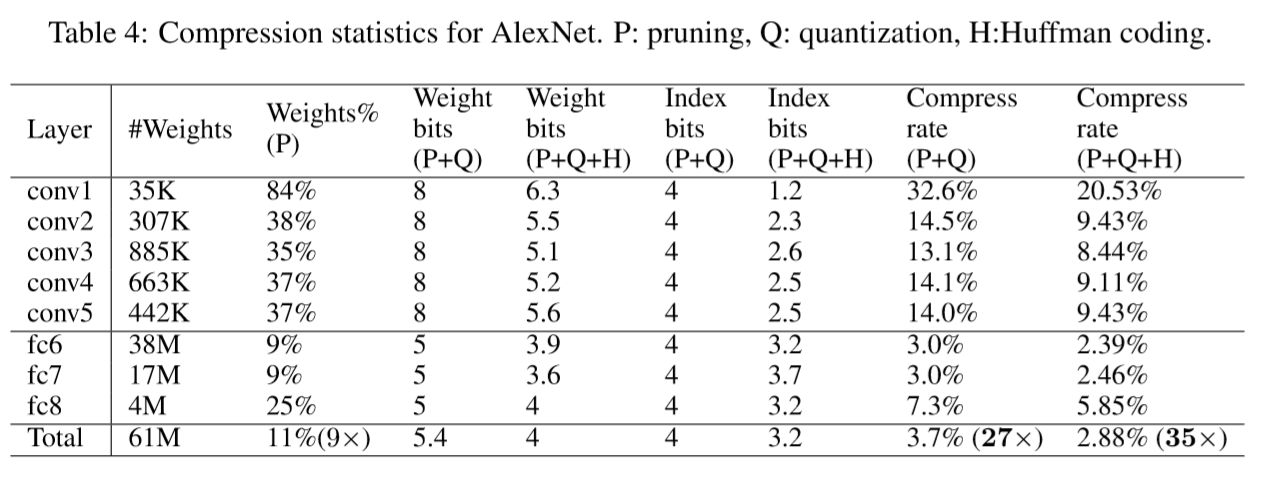
Table 4 shows that AlexNet can be compressed to 2.88% of its original size without impacting accuracy.
There are 256 shared weights in each CONV layer, which are encoded with 8 bits, and 32 shared weights in each FC layer, which are encoded with only 5 bits. The relative sparse index is encoded with 4 bits. Huffman coding compressed additional 22%, resulting in 35× compression in total.
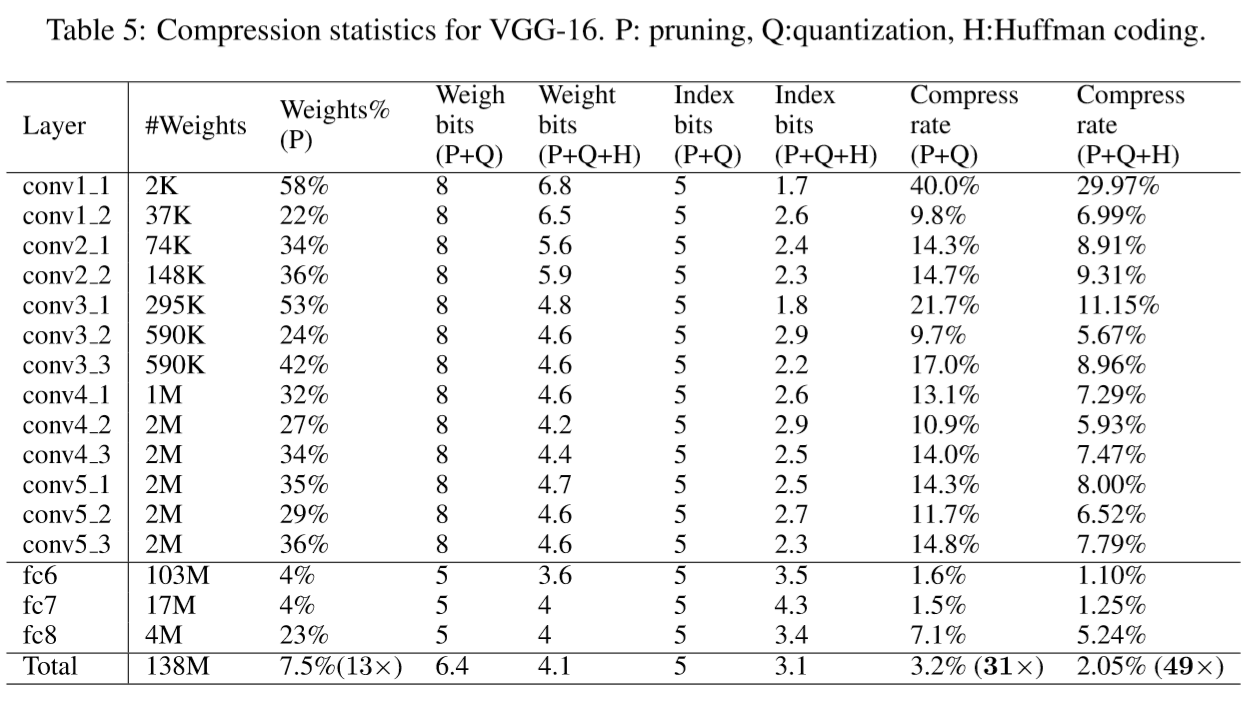
5.3 VGG-16 on ImageNet
With promising results on AlexNet, we also looked at a larger, more recent network, VGG-16, onthesameILSVRC-2012dataset.
VGG-16 has far more convolutional layers but still only three fully-connected-layers.
Following a similar methodology, we aggressively compressed both convolutional and fully-connected layers to realize a significant reduction in the number of effective weights, shown in Table 5.
The VGG16 network as a whole has been compressed by 49×. Weights in the CONV layers are represented with 8 bits, and FC layers use 5 bits, which does not impact the accuracy. The two largest fully-connected layers can each be pruned to less than 1.6% of their original size.
This reduction is critical for real time image processing, where there is little reuse of these layers across images (unlike batch processing). This is also critical for fast object detection algorithms where one CONV pass is used by many FC passes. The reduced layers will fit in an on-chip SRAM and have modest bandwidth requirements. Without the reduction, the bandwidth requirements are prohibitive.
6 Discussions
6.1 Pruning and Quantization Working Together
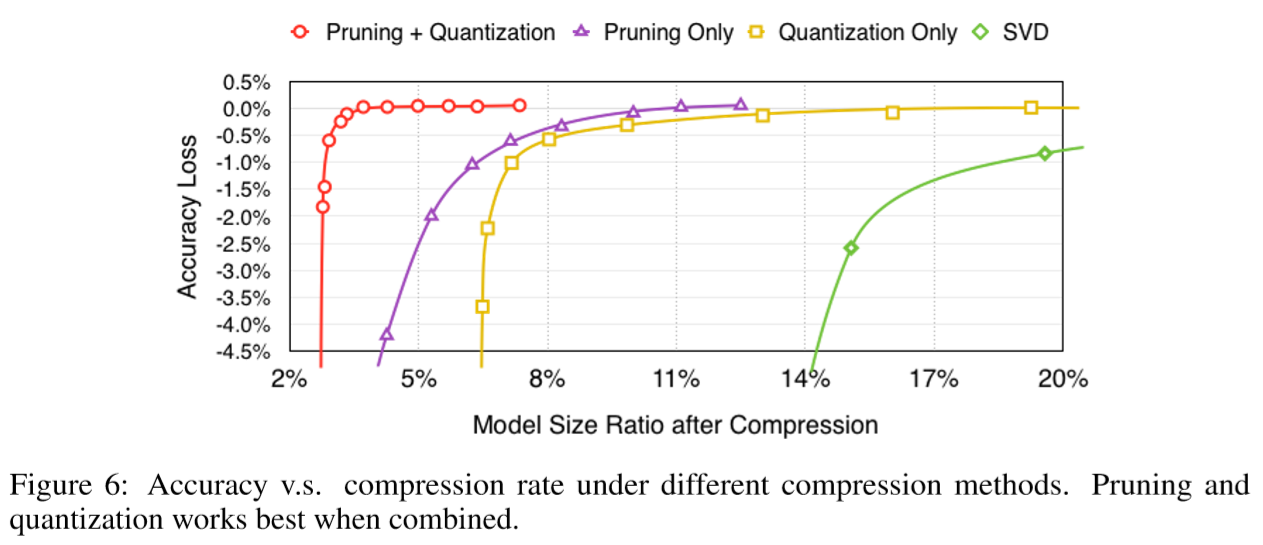
Figure 6 shows the accuracy at different compression rates for pruning and quantization together or individually. When working individually, as shown in the purple and yellow lines, accuracy of pruned network begins to drop significantly when compressed below 8% of its original size; accuracy of quantized network also begins to drop significantly when compressed below 8% of its original size. But when combined, as shown in the red line, the network can be compressed to 3% of original size with no loss of accuracy. On the far right side compared the result of SVD(奇异值分解), which is inexpensive but has a poor compression rate.
The three plots in Figure 7 show how accuracy drops with fewer bits per connection for CONV layers (middle), FC layers (left) and all layers (right). Each plot reports both top-1 and top-5 accuracy. Dashed lines only applied quantization but without pruning; solid lines did both quantization and pruning. There is very little difference between the two. This shows that pruning works well with quantization.
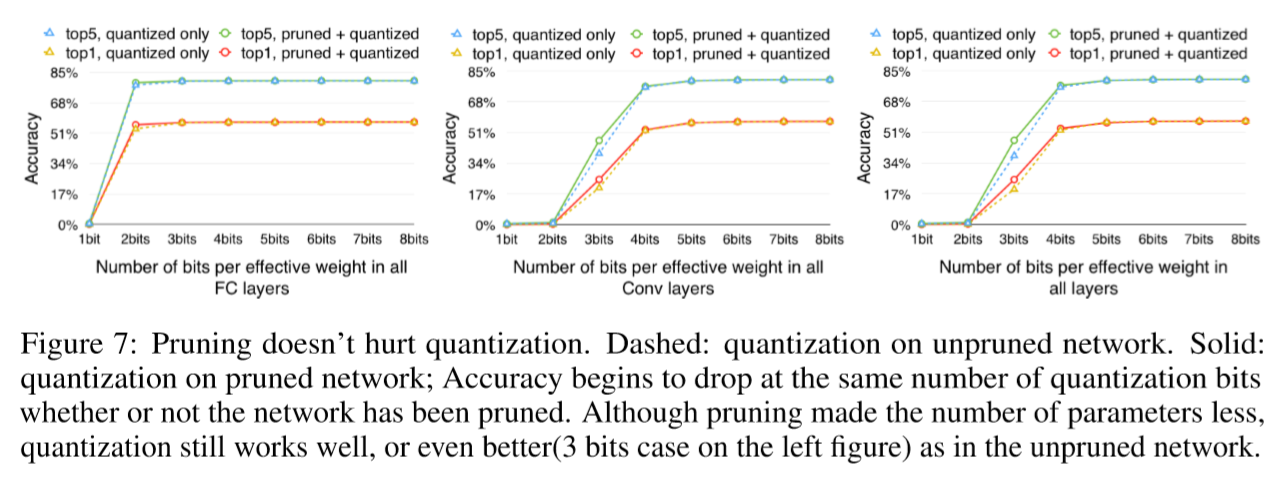
Quantization works well on pruned network because unpruned AlexNet has 60 million weights to quantize, while pruned AlexNet has only 6.7 million weights to quantize. Given the same amount of centroids, the latter has less error.
The first two plots in Figure 7 show that CONV layers require more bits of precision than FC layers. For CONV layers, accuracy drops significantly below 4 bits, while FC layer is more robust: not until 2 bits did the accuracy drop significantly.
6.2 Centroid Initialization
Figure 8 compares the accuracy of the three different initialization methods with respect to top-1 accuracy (Left) and top-5 accuracy (Right). The network is quantized to 2 ∼ 8 bits as shown on x-axis. Linear initialization outperforms the density initialization and random initialization in all cases except at 3 bits.
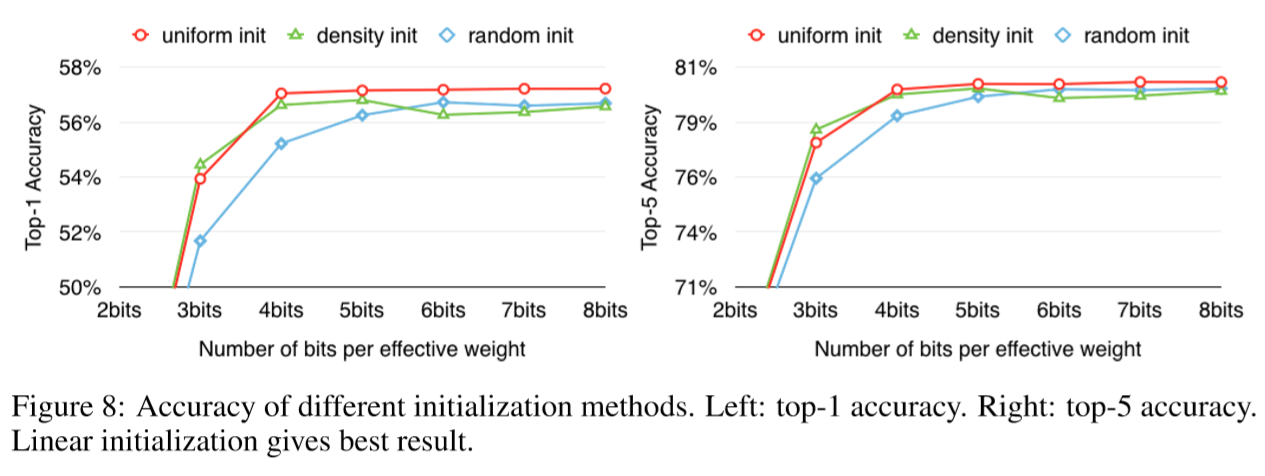
The initial centroids of linear initialization spread equally across the x-axis, from the min value to the max value. That helps to maintain the large weights as the large weights play a more important role than smaller ones, which is also shown in network pruning.
Neither random nor density-based initialization retains large centroids. With these initialization methods,large weights are clustered to the small centroids because there are few large weights. In contrast, linear initialization allows large weights a better chance to form a large centroid.
6.3 Speedup and Energy Efficiency
Deep Compression is targeting extremely latency-focused applications running on mobile, which requires real-time inference, such as pedestrian(行人) detection on an embedded processor inside an autonomous vehicle. Waiting for a batch to assemble significantly adds latency(延迟). So when benchmarking(基于) the performance and energy efficiency, we consider the case when batch size = 1. The cases of batching are given in Appendix A.
Fully connected layer dominates the model size (more than 90%) and got compressed the most by Deep Compression (96% weights pruned in VGG-16). In state-of-the-art object detection algorithms such as fast R-CNN (Girshick, 2015), upto 38% computation time is consumed on FC layers on uncompressed model. So it’s interesting to benchmark on FC layers, to see the effect of Deep Compression on performance and energy. Thus we setup our benchmark on FC6, FC7, FC8 layers of AlexNet and VGG-16. In the non-batched case, the activation matrix is a vector with just one column, so the computation boils down to(归结为) dense / sparse matrix-vector multiplication for original / pruned model, respectively. Since current BLAS library on CPU and GPU doesn’t support indirect look-up and relative indexing, we didn’t benchmark the quantized model.
We compare three different off-the-shelf hardware: the NVIDIA GeForce GTX Titan X and the Intel Corei75930K as desktop processors(same package as NVIDIA Digits Dev Box)and NVIDIA Tegra K1 as mobile processor. To run the benchmark on GPU, we used cuBLAS GEMV for the original dense layer. For the pruned sparse layer, we stored the sparse matrix in in CSR format, and used cuSPARSE CSRMV kernel, which is optimized for sparse matrix-vector multiplication on GPU. To run the benchmark on CPU, we used MKL CBLAS GEMV for the original dense model and MKL SPBLAS CSRMV for the pruned sparse model.
To compare power consumption between different systems, it is important to measure power at a consistent manner (NVIDIA, b).For our analysis, we are comparing pre-regulation power of the entire application processor(AP)/SOC and DRAM combined. On CPU,the benchmark is running on single socket with a single Haswell-E class Core i7-5930K processor. CPU socket and DRAM power are as reported by the pcm-power utility provided by Intel. For GPU, we used nvidia-smi utility to report the power of Titan X. For mobile GPU, we use a Jetson TK1 development board and measured the total power consumption with a power-meter. We assume 15% AC to DC conversion loss, 85% regulator efficiency and 15% power consumed by peripheral components (NVIDIA, a) to report the AP+DRAM power for Tegra K1.
The ratio of memory access over computation characteristic with and without batching is different. When the input activations are batched to a matrix the computation becomes matrix-matrix multiplication, where locality can be improved by blocking. Matrix could be blocked to fit in caches and reused efficiently. In this case, the amount of memory access is O(n2), and that of computation is O(n3), the ratio between memory access and computation is in the order of 1/n.
In real time processing when batching is not allowed, the input activation is a single vector and the computation is matrix-vector multiplication. In this case,the amount of memory accessis O(n2),and the computation is O(n2), memory access and computation are of the same magnitude (as opposed to 1/n). That indicates MV is more memory-bounded(内存限制) than MM. So reducing the memory footprint is critical for the non-batching case.
Figure 9 illustrates the speedup of pruning on different hardware. There are 6 columns for each benchmark, showing the computation time of CPU / GPU / TK1 on dense / pruned network. Time is normalized to CPU. When batch size = 1, pruned network layer obtained 3× to 4× speedup over the dense network on average because it has smaller memory footprint(内存占用) and alleviates(缓解) the data transferring overhead, especially for large matrices that are unable to fit into the caches. For example VGG16’s FC6 layer, the largest layer in our experiment, contains 25088×4096×4 Bytes ≈ 400MB data, which is far from the capacity of L3 cache.
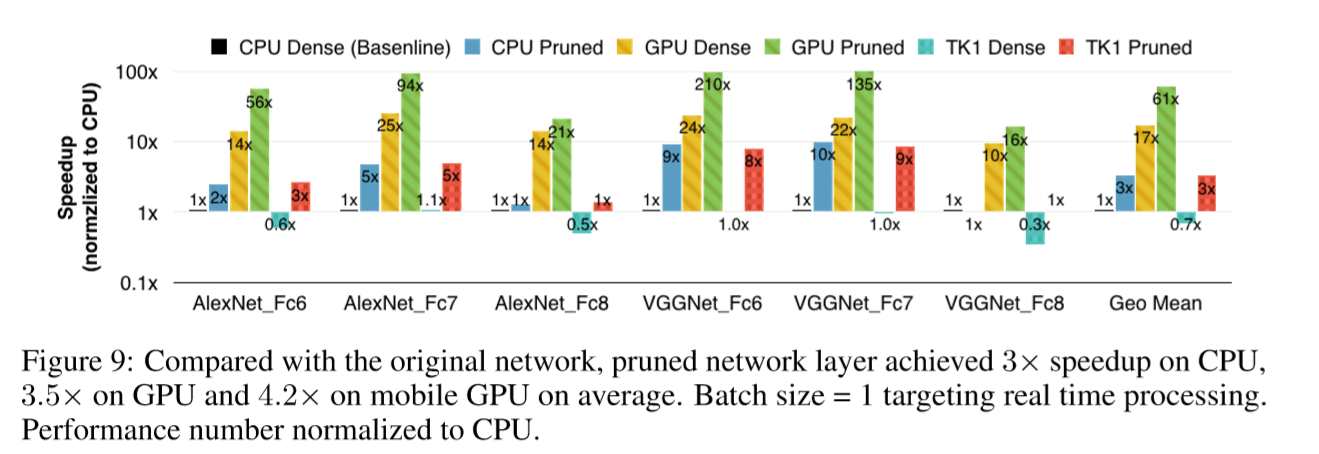
In those latency-tolerating applications , batching improves memory locality, where weights could be blocked and reused in matrix-matrix multiplication. In this scenario, pruned network no longer shows its advantage. We give detailed timing results in Appendix A.
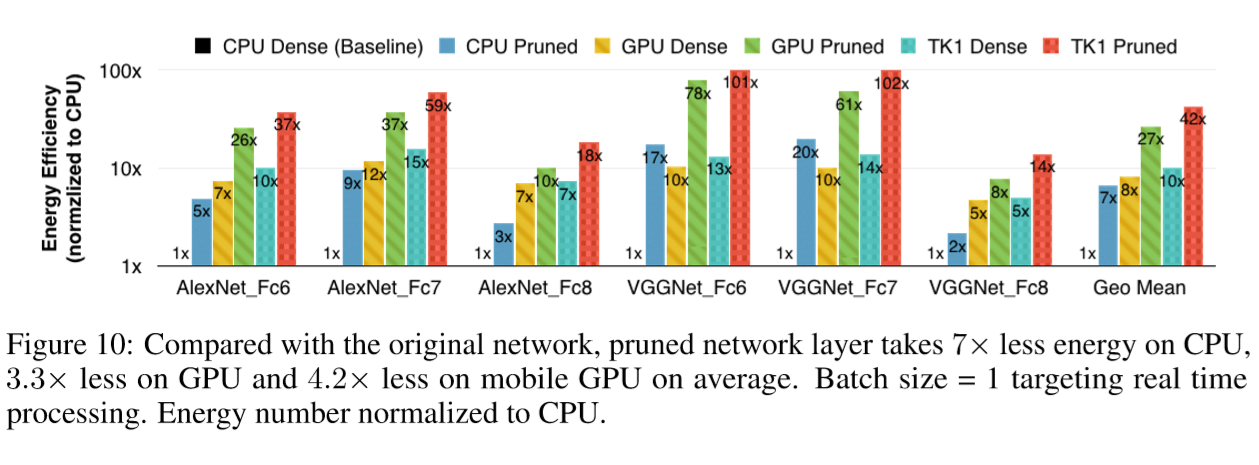
Figure 10 illustrates the energy efficiency of pruning on different hardware. We multiply power consumption with computation time to get energy consumption, then normalized to CPU to get energy efficiency. When batch size = 1, pruned network layer consumes 3× to 7× less energy over the dense network on average. Reported by nvidia-smi, GPU utilization is 99% for both dense and sparse cases.
6.4 Ratio of Weights, Index and Codebook
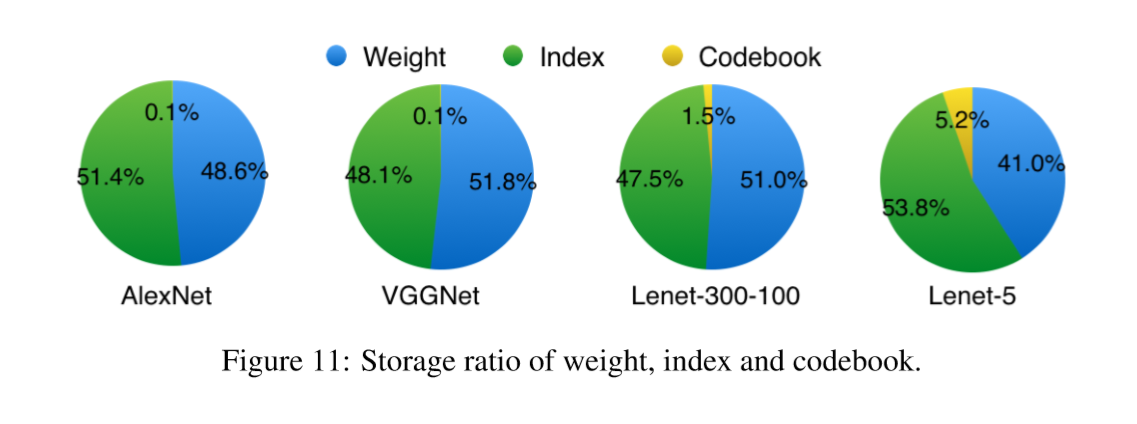
Pruning makes the weight matrix sparse, so extra space is needed to store the indexes of non-zero elements.
Figure 11 shows the breakdown of three different components when quantizing four networks.
Since on average both the weights and the sparse indexes are encoded with 5 bits, their storage is roughly half and half. The overhead of codebook is very small and often negligible.
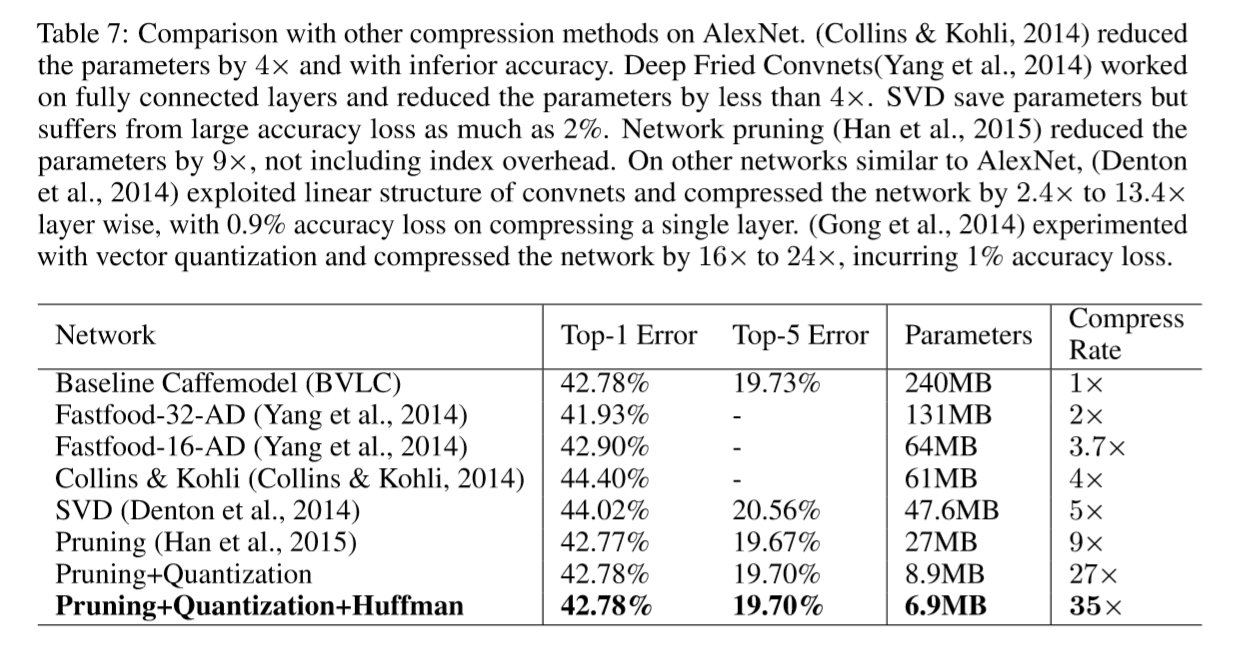
7 Related Work
Neural networks are typically over-parametrized,and there is significant redundancy for deeplearning models(Denil et al., 2013). This results in a waste of both computation and memory usage.
Various proposals to remove the redundancy:
Vanhoucke et al. (2011) explored a fixed-point implementation with 8-bit integer (vs 32-bit floating point) activations.
Hwang & Sung (2014) proposed an optimization method for the fixed-point network with ternary weights and 3-bit activations.
Anwar et al. (2015) quantized the neural network using L2 error minimization and achieved better accuracy on MNIST and CIFAR-10 datasets.
Denton et al. (2014) exploited the linear structure of the neural network by finding an appropriate low-rank approximation of the parameters and keeping the accuracy within 1% of the original model.
The empirical success in this paper is consistent with the theoretical study of random-like sparse networks with +1/0/-1 weights (Arora et al., 2014), which have been proved to enjoy nice properties (e.g. reversibility), and to allow a provably polynomial time algorithm for training.
Much work has been focused on binning the network parameters into buckets, and only the values in the buckets need to be stored.
HashedNets(Chen et al., 2015) reduce model sizes by using a hash function to randomly group connection weights, so that all connections within the same hash bucket share a single parameter value.
In their method, the weight binning is pre-determined by the hash function, instead of being learned through training, which doesn’t capture the nature of images.
Gong et al. (2014) compressed deep convnets using vector quantization, which resulted in 1% accuracy loss. Both methods studied only the fully connected layer, ignoring the convolutional layers.
There have been other attempts to reduce the number of parameters of neural networks by replacing the fully connected layer with global average pooling.The Network in Network architecture(Linetal., 2013) and GoogLenet(Szegedyetal.,2014)achieves state-of-the-art results on several benchmarks by adopting this idea. However, transfer learning, i.e. reusing features learned on the ImageNet dataset and applying them to new tasks by only fine-tuning the fully connected layers, is more difficult with this approach. This problem is noted by Szegedy et al. (2014) and motivates them to add a linear layer on the top of their networks to enable transfer learning.
Network pruning has been used both to reduce network complexity and to reduce over-fitting. An early approach to pruning was biased weight decay (Hanson & Pratt, 1989). Optimal Brain Damage (LeCun et al., 1989) and Optimal Brain Surgeon (Hassibi et al., 1993) prune networks to reduce the number of connections based on the Hessian of the loss function and suggest that such pruning is more accurate than magnitude-based pruning such as weight decay. A recent work (Han et al., 2015) successfully pruned several state of the art large scale networks and showed that the number of parameters could be reduce by an order of magnitude(一个数量级). There are also attempts to reduce the number of activations for both compression and acceleration Van Nguyen et al. (2015).
8 Further Work
While the pruned network has been benchmarked on various hardware, the quantized network with weight sharing has not, because off-the-shelf cuSPARSE or MKL SPBLAS library does not support indirect matrix entry lookup, nor is the relative index in CSC or CSR format supported. So the full advantage of Deep Compression that fit the model in cache is not fully unveiled. A software solution is to write customized GPU kernels that support this. A hardware solution is to build custom ASIC architecture specialized to traverse the sparse and quantized network structure, which also supports customized quantization bit width. We expect this architecture to have energy dominated by on-chip SRAM access instead of off-chip DRAM access.
9 Conclusion
We have presented “Deep Compression” that compressed neural networks without affecting accuracy. Our method operates by pruning the unimportant connections, quantizing the network using weight sharing, and then applying Huffman coding. We highlight our experiments on AlexNet which reduced the weight storage by 35×without loss of accuracy. We show similar results for VGG-16 and LeNet networks compressed by 49×and 39×without loss of accuracy. This leads to smaller storage requirement of putting convnets into mobile app. After Deep Compression the size of these networks fit into on-chip SRAM cache (5pJ/access) rather than requiring off-chip DRAM memory (640pJ/access). This potentially makes deep neural networks more energy efficient to run on mobile. Our compression method also facilitates the use of complex neural networks in mobile applications where application size and download bandwidth are constrained.