第一次作业
类图:

解释:
Poly是项,Proceed是处理类。
第一次作业的时候,自己写了两天(debug)。只有两百行代码,耗时20+小时.....主要原因在于罪恶的正则:
-
坑点1:
正则是无法一次处理过长的式子的,一旦输入会爆出exception,然后一串串红红提示语......
- 解决方法:
引入循环,单项匹配
-
坑点2:
一次正则过长导致遗漏小括号以及与或非层次不对
- 解决方法:
将正则字符换命名,形成一个正则表达式的树结构,更易管理,逻辑性一目了然

重大问题:
- 从上图很明显地看出,inputanalysis函数内语句过多,自己把功能过于集中地写在了一个类当中。
第二次作业
——引入sincos
类图:

解释:
Controller是核心处理类;
Factor是因子,按照正负号分割。Term是项,按照乘除号分割。
第三次作业:
(为了想出来一个框架花了整整一个晚上.......)
类图:

结构:
其中,是按照指导书的推荐做法,将所有的项分为了全部的6个类:
| 类名 | 项的属性 | 作用 |
| Num | 基本项 | 简单地描述常数项 |
| Mi | 基本项 | 描述幂指数项 |
| Sincos | 基本项 | 描述三角函数项 |
| Addsub | 组合项 | left 与 right属性分别是一个Derivinterface对象,表示加减组合项 |
| Muldiv | 组合项 | left 与 right属性分别是一个Derivinterface对象,表示乘法组合项 |
| Qiantao | 组合项 | 为一个嵌套函数,由于幂函数不支持表达式,外层函数一定为三角函数,记录外层三角函数的类型与幂次。同时含有right属性是一个Derivinterface对象,表示内函数 |
同时加上一个处理所有输入输出,创建对象的Term类,与Derivinterface接口(抽象类)。
最关键的实属Derivinterface抽象类。上面的6种跟项有关的类,都实现了这个接口。我们把输入的一整个表达式都处理成一个Derivinterface抽象类。
算法:
——完全的编译思想
甚至还写了词法分析与语法分析模块。
词法分析:


1 //词法分析部分 2 public static void split(String raw, Deque<String> deque) { 3 int i = 0; 4 while (i < raw.length()) { 5 if (raw.charAt(i) == '+' || raw.charAt(i) == '-') { 6 i = copyAddminus(raw, i, deque); 7 } else if (raw.charAt(i) == 's' || raw.charAt(i) == 'c') { 8 i = copySincos(raw, i, deque); 9 } else if (raw.charAt(i) == 'x') { 10 i = copyX(raw, i, deque); 11 } else if (raw.charAt(i) >= '0' && raw.charAt(i) <= '9') { 12 i = copyDigit(raw, i, deque); 13 } else if (raw.charAt(i) == '(' || raw.charAt(i) == ')') { 14 deque.addLast(String.valueOf(raw.charAt(i))); 15 i++; 16 } else if (raw.charAt(i) == '*') { 17 deque.addLast(String.valueOf(raw.charAt(i))); 18 i++; 19 } else if (raw.charAt(i) == '^') { 20 i = copyIndex(raw, i, deque); 21 } else { 22 //因为表达式是不可以有幂运算的,所以^字符只可能出现在x,sin cos当中 23 Term.error(); 24 } 25 } 26 }
语法分析:
1 //语法分析部分 2 public static DerivInterface grammar(Deque<String> deque) { 3 Stack<DerivInterface> termStack = new Stack<DerivInterface>(); 4 Stack<String> opStack = new Stack<String>(); 5 String head = null; 6 while (deque.isEmpty() == false) { 7 head = deque.pollFirst(); 8 if (isop(head) == true) { 9 if (termStack.isEmpty() == false) { 10 if (canPush(head) == true) { 11 opStack.push(head); 12 } else if (head.equals("*")) { 13 mul(head, termStack, opStack); 14 } else if (head.equals("+") || head.equals("-")) { 15 add(head, termStack, opStack); 16 } else if (head.equals(")")) { 17 pop(head, termStack, opStack); 18 } 19 } else { 20 opStack.push(head); 21 } 22 } else { 23 termStack.add(newSimpleTerm(head)); 24 } 25 } 26 while (opStack.isEmpty() == false) { 27 opEnd(termStack, opStack); 28 } 29 //最后应该Dequeue和opStack都为空并且termStack只有一个元素 30 if (opStack.isEmpty() == false || termStack.size() != 1) { 31 Term.error(); 32 } 33 return termStack.pop(); 34 }
很像一个计算器,设立了操作数栈与Derivinterface对象栈。每当读到+ - * sin cos ^时,都会将相应的对象栈和操作数栈(比较优先级后)中对象弹出。结合成一个新的Derivinterface对象后入栈。
为什么答案那么长?
一开始本来设计的时候希望整体是一个Derivinterface对象,求导后依然是一个Derivinterface对象,这样便于做后续的优化。但是后面还是求导直接将结果输出了,为了降低错误率,每个加减组合项,嵌套组合项,能用到括号的地方自己还特意多加了括号,导致结果长度异常长。
时间都去哪儿啦?
加各种各样题目要求的细节了。比较磨人的环节是正负号的处理,非常地繁琐,自己每读一遍题目,就会发现自己又需要多考虑一点东西,这种细节非常多的设计,全是因为一开始设计时候,目光过于短浅。自己这一点设计习惯非常不好,总是依赖测试样例来验证自己的程序的正确性。但是测试样例总归是无法覆盖所有的特殊情况的。这个时候就需要逻辑上正确性证明自己程序。然而,由于coding期间,总是会东补补西凑凑,然后就把自己的结构的统一性破环掉了,这种情况在第三次作业的时候体现地尤为明显,自己对于一些特殊情况的处理,会放在一些奇奇怪怪的函数里面处理,“只要塞得下,就往里面塞”。最后,一个Term类里面装下了所有杂七杂八的判断。
三次作业复杂度比较:
第一次:
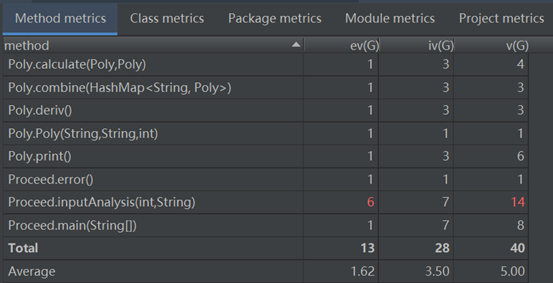
第二次:

第三次:

analysis:
第二次作业的复杂度最小。这一次也是自己coding时间最短的一次作业。因为没有很多地加各种各样的新的需求。说明了什么?
结构越有前瞻性,代码复杂度越小,coding难度越小。
Drawbacks:
- 第三次作业,几乎所有的功能都集中到了term类上面。自己的Term类异常冗长,自己删除了好久的代码才在500行以内。几乎每次作业都会使一个类的结构异常地冗长。类的划分还需要进一步地合理。
- 关于代码正确性测试。“写代码前就需要构造好测试样例”,突然发现老师上课时候讲的这句话非常地有道理。这样不仅仅可以让我们快速地熟悉题目而且不会让我们先入为主地在写完代码后做无用的片面的测试。然而,无论怎样构造测试样例,都是一种事后的挽救行为,在写代码的时候,在思考算法的时候,就应该对于自己的程序进行正确性证明。
最后,感谢那些年跟我一起分享测试代码的小伙伴~~~