今年国庆和中秋赶到一块了,所以在实验室待了7天,事实上第7天晚上就放假了,晚上还约了蔡学长跑了一次十公里,现在还趴着在实验室桌子上怀疑人生没缓过来呢~ 这次的假期目标是做模仿本真堂药业有限公司的网站重写一个,用Dreamweaver CS6和EditPlus和张文配合着把这个网站基本上都实现了,有点简陋谁让只能用原生的HTML,而且可移植也不咋滴,用Dreamweaver CS6写出来的网页在用div标签的时候目前好像只能绝对布局,也就是说如果其他人的显示器的分辨率和我不一样就不行了,现在主流的浏览器默认是不支持JS连接数据库的,只有IE提供了连接数据库的接口,而且还被废弃了~ 也就是说必须要配置一下才能用,而且就算配置了也不一定可以,就比如说我的电脑,直接用IE打开就提示报错,用EditPlus调用IE就可以正常使用,而张文刚好相反,工具的配置问题暂时不想理会,下面是效果:
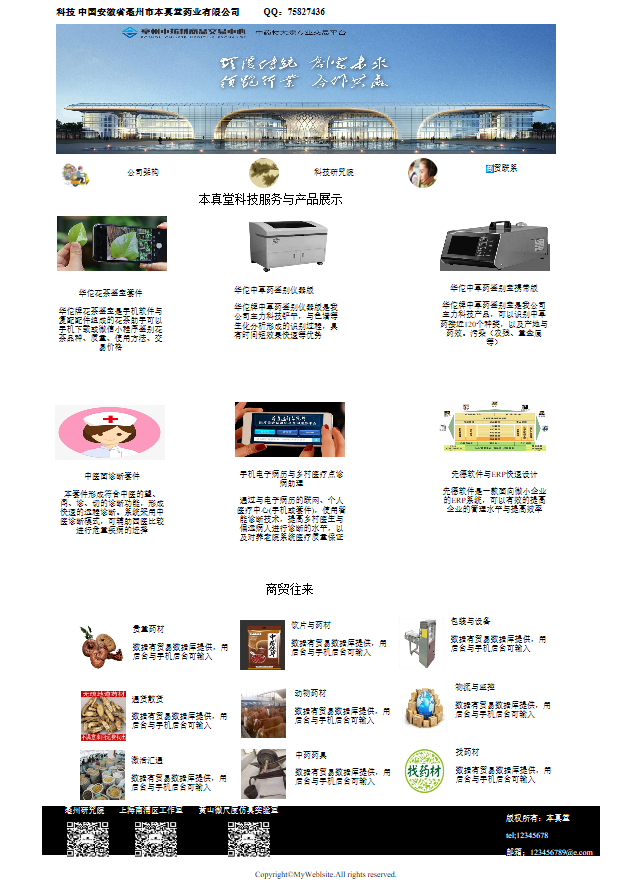




第一个和第二页面是张文做的,因为DW的原因,移植到我电脑上还需要稍作修改一下才能正常显示,第三个和第四个是我做的,第四个页面涉及到连接数据库,所以数据库的结构也贴出来了,总体的结构还算是比较简单的吧,勉强完成了要求,但很明显是经不起推敲的。下面主要分享Web学习的一些想法。这几天我越发觉得学习语言这件事情的本身并没有什么太大的意义,如果对计算机的原理非常的了解,大概看一下那一个语言的语法使用几次也就会了,计算机语言还有偏向,就像我假期的时候弄了个Python爬虫爬了一下网易云的评论生成了词云玩玩一样,Python我感觉更多的是能不能完成这件事情的本身,并不怎么关注细节基本上有很多非常成熟的库你可以调用,比较简单的就可以完成一个小目标,比如说用Python爬取《六月的雨》网易云1442条评论生成的词云:


# encoding=utf-8 import requests import json import csv import time import jieba import numpy from PIL import Image from wordcloud import WordCloud # json数据接口,需要两个恶参数,offset和limit,offset的增量为20,limit的固定为20,刚好抓取网页评论的20条评论 # http://music.163.com/api/v1/resource/comments/R_SO_4_498040739?offset=40&limit=20 # 网页请求 def get_one_comment(offset): headers={ 'Cookie':'_iuqxldmzr_=32; _ntes_nnid=bdaab01e87ee929b3a9a91ea44b5cd45,1534172699282; _ntes_nuid=bdaab01e87ee929b3a9a91ea44b5cd45; __utmc=94650624; WM_TID=M4E4ToHGUg4EetTbOjxEC5J%2BuODh%2B0jj; abt=66; WM_NI=cRw1E4mJtjv9dwKem8xCMaYzUgNNyu8qqM25igmzBYDj%2FJGjHnYTJFFFqen2XIq%2FlCdRUdQxmdIvxSl84%2BvraOwnH1lJboEwOdL6UrZhnx030tzRng9NfOIBNXgIUx7GMUI%3D; WM_NIKE=9ca17ae2e6ffcda170e2e6eeb6b15cf88bb8ade56a8eb48291f97ca5b9e1d2c45bf6ed9cb9e659b1be8e89ca2af0fea7c3b92aa18eb9d2c840af96bc8bf533a8a98586f034bc9d8382dc7297b982affc7ffcafbfaeb13fabb9a39bc15388b6e1abc6628cb297b5c94e869abf86ed3a9c97bfd0ef49a88e9b85d474afbc8797fb59b0e8fcccf57aa391b98fcb3bb096ae90c87d8dbc84d7d87a9ab8a299b339f4acb6b3ed6dfb92aab0cc4a8e88a9aad874f59983b6cc37e2a3; __utma=94650624.827593374.1534172700.1535852507.1535857189.3; __utmz=94650624.1535857189.3.3.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; JSESSIONID-WYYY=kgbbgMKEcRf18SvvxZVqNTmWZD%2Fdn8BpA%2F7aMH7vv4mSpiDaE%5CfkC5xPu5hFv0nk5X7PpvlEJJ97%2BC3WyE5Qv50EW%2FdNPQQPenibqq%2F5IyHkuuMlCTkpkb7TRMl9oBEdFi68ktMI8m%2F5Ilyub4P204bpG0qBv4yx9vvw8CmCJ%2B9vCaSd%3A1535859527007; __utmb=94650624.7.10.1535857189', 'Referer':'https://music.163.com/song?id=4875310', 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36' } # 字符串拼接 url='http://music.163.com/api/v1/resource/comments/R_SO_4_4875310?offset='+str(offset)+'&limit=20' try: response=requests.get(url,headers=headers) if response.status_code == 200: return response.content except Exception as e: print('出错啦!') return None # 解析数据 def parse_json_data(contents): if contents: # 编码格式转换 contents=contents.decode('utf-8') # api接口返回的数据是json格式,把json格式转换为字典结构,获取评论信息 comments=json.loads(contents)['comments'] for comment in comments: content=comment['content'] nickname=comment['user']['nickname'] timeArray=time.localtime(comment['time']/1000) style_time=time.strftime('%Y-%m-%d %H:%M:%S',timeArray) yield{ 'time':style_time, 'nickname':nickname, 'comment':content } # print(nickname+','+content+','+style_time) # csv保存数据 def save_csv_comments(messages,i): # encoding=utf_8_sig只能转换中文乱码和字母乱码,不能支持数字的乱码 with open('comment_csv.csv','a',encoding='utf_8_sig',newline='')as f: csvFile=csv.writer(f) if i == 0: csvFile.writerow(['评论时间','昵称','评论内容']) csvdatas=[] for message in messages: csvdata=[] csvdata.append(message['time']) csvdata.append(message['nickname']) csvdata.append(message['comment'].replace(' ','')) csvdatas.append(csvdata) csvFile.writerows(csvdatas) # 读取csv文件的评论内容的一列 def read_csvFile(fileName): with open(fileName,'r', encoding='UTF-8') as f: # 因为此csv文件并非二进制文件, 只是一个文本文件 readerCSV=csv.reader(f) comment_column=[row[2] for row in readerCSV] return comment_column # 词云生成 def make_word_cloud(text): comment_text=jieba.cut(''.join(text[1:])) print(comment_text) # list类型转换为str类型 comment_text=''.join(comment_text) animal=numpy.array(Image.open('timg_meitu_1.jpg')) wc=WordCloud(font_path='C:/Windows/Fonts/simsun.ttc',background_color="white",width=913,height=900, max_words=2000, mask=animal) # 生成词云 wc.generate(comment_text) #保存到本地 wc.to_file("animal.png") # 程序主入口 def main(offset,i): save_csv_comments(parse_json_data(get_one_comment(offset)),i) if __name__=="__main__": for i in range(100): main(i*20,i) make_word_cloud(read_csvFile('comment_csv.csv'))

用Python爬取《六月的雨》网易云1442条评论生成的词云
越发的觉得语言这件事情并没有那么的重要了,但是为了解决问题你得有一个最称手的兵器吧,我选择的是Java这门语言。对计算机的理解,在和王老师交流的时候,也越发觉得自己知道的还是比较浅薄的,很多东西在和我们说的时候虽然我都有一点印象,但是大多是碎片化的,感性的,老师也确实有点抬举我了,我桌子上的书我可是准备五到十年把他们啃掉的,而现在我也就刚开始而已。但是我觉得大可不必妄自菲薄,我有的是时间,所以我问了一下在哪里可以找到他所说的东西可以学到,我现在是觉得学习这件事情还是更多的要往深层次的地方去挖,上层大概知道了怎么用了以后完全可以深入到底层,上层的设计很多是面向实际的问题而设计的,直接学可能会被不知所云。比如说Java,熟悉了语法以后,完全可以先挖到JDK源码,然后再挖到JVM的原理,再往操作系统的原理挖,体系结构,组成原理,如何用Assembly和C实现这些功能,甚至是数电和模电的原理,还可以跳出这个范围之外从数学的角度从现实的角度分析目前的限制和边界在哪里,我这说的就有一点站的太高了太空了,当然这个是宏观的战略,从小的战术上还是要落实到那些大牛写出的书中逐个理清楚。我自己是自动化专业的,主要的专业课是自动控制原理,虽然学的不是非常的好,不过先把某一课程最核心的思想掌握已经成为了我的一种学习的方式了,所以这门课程最关键的东西我学的还算用心,比如说经典控制理论的数学基础拉氏变换的原理。我9月17号在知乎上发了一条自己对自动化专业的想法:“什么是自动化专业呢必须要澄清和机械没什么关系哦~ 我们主要学习的是如何用计算机控制弱电,然后再通过弱电控制强电,让系统有效的自己动起来,控制的过程有很多复杂的环节,这就是我们学习的内容。”从描述中也可以看出了我们专业更多的是培养系统思维,那些事无巨细的事情交给更专业的人去做就好了,这个专业我觉得还是非常特殊的吧,真的不是一般人可以学好的,学这个专业的人出来要不就很厉害,要不就什么都不咋会。我想还是不要太心急,慢慢来,一辈子那么长,我还很年轻。
我们这次主要用的是HTML5(HyperText Markup Language 5),JavaScript和CSS(Cascading Style Sheets,事实上CSS都没怎么用到,主要深入进去实在是烦,王老师也是这么说的,还有一点我注意到大家似乎都把Cascading翻译成“可折叠的”,词典里的释义是“v. (水)倾泻;大量落下;连续传递(信息、技艺等);(使)(装置、物品)串联(cascade 的现在分词)”,感觉后者的描述更加感性具体)。HTML5是2014年由W3C(World Wide Web Consortium)完成标准制定,运行在浏览器上由浏览器来解析,那下面就简单的分析一下浏览器的工作原理:
1. 导航
导航是加载web页面的第一步。它发生在以下情形:用户通过在地址栏输入一个URL、点击一个链接、提交表单或者是其他的行为
web性能优化的目标之一就是缩短导航完成所花费的时间,在理想情况下,它通常不会花费太多的时间,但是等待时间和带宽会导致它的延时。
1.1 DNS 查找
对于一个web页面来说导航的第一步是要去寻找页面资源的位置。如果导航到https://example.com, HTML页面 被定为到IP地址为 93.184.216.34 的服务器。如果以前没有访问过这个网站,就需要进行DNS查找。
浏览器通过服务器名称请求DNS进行查找,最终返回一个IP地址,第一次初始化请求之后,这个IP地址可能会被缓存一段时间,这样可以通过从缓存里面检索IP地址而不是再通过域名服务器进行查找来加速后续的请求
通过主机名加载一个页面通常仅需要DNS查找一次.。但是, DNS需要对不同的页面指向的主机名进行查找。如果fonts, images, scripts, ads, and metrics 都不同的主机名,DNS会对每一个进行查找。

DNS查找对于性能来说是一个问题,特别是对于移动网络。当一个用户用的是移动网络,每一个DNS查找必须从手机发送到信号塔,然后到达一个认证DNS服务器。手机、信号塔、域名服务器之间的距离可能是一个大的时间等待。
1.2 TCP Handshake
一旦获取到服务器IP地址,浏览器就会通过TCP”三次握手“与服务器建立连接。这个机制的是用来让两端尝试进行通信—浏览器和服务器在发送数据之前,通过上层协议Https可以协商网络TCP套接字连接的一些参数。
TCP的”三次握手“技术经常被称为”SYN-SYN-ACK“—更确切的说是 SYN, SYN-ACK, ACK—因为通过TCP首先发送了三个消息进行协商,开始一个TCP会话在两台电脑之间。 是的,这意味着每台服务器之间还要来回发送三条消息,而请求尚未发出。
1.3 TLS 协商
为了在HTTPS上建立安全连接,另一种握手是必须的。更确切的说是TLS协商 ,它决定了什么密码将会被用来加密通信,验证服务器,在进行真实的数据传输之前建立安全连接。在发送真正的请求内容之前还需要三次往返服务器。

虽然建立安全连接对增加了加载页面的等待时间,对于建立一个安全的连接来说,以增加等待时间为代价是值得的,因为在浏览器和web服务器之间传输的数据不可以被第三方解密。
经过8次往返,浏览器终于可以发出请求。
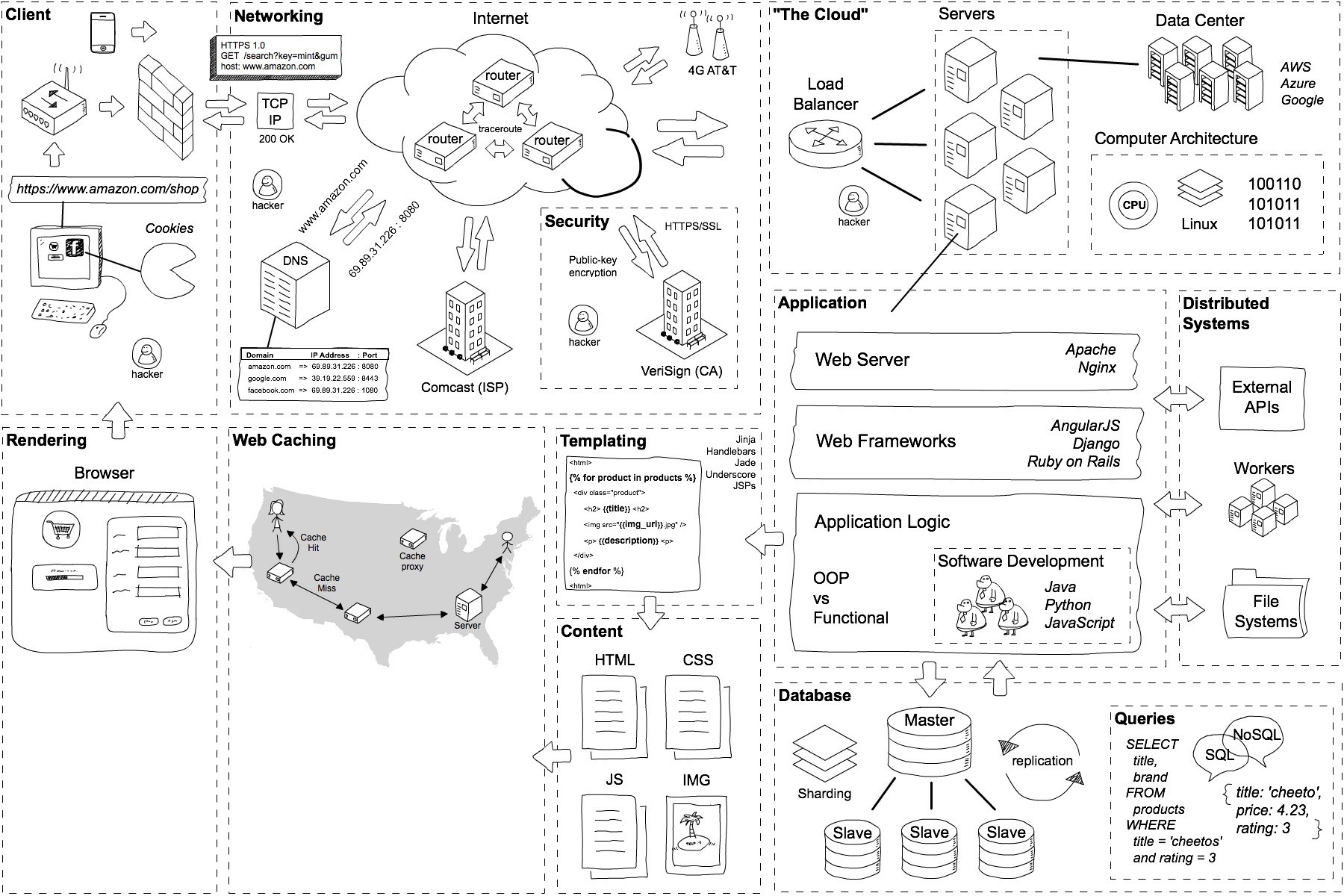
2. 响应
一旦我们建立了到web服务器的连接,浏览器就代表用户发送一个初始的HTTP GET请求,对于网站来说,这个请求通常是一个HTML文件。 一旦服务器收到请求,它将使用相关的响应头和HTML的内容进行回复。
<!doctype HTML> <html> <head> <meta charset="UTF-8"/> <title>My simple page</title> <link rel="stylesheet" src="styles.css"/> <script src="myscript.js"></script> </head> <body> <h1 class="heading">My Page</h1> <p>A paragraph with a <a href="https://example.com/about">link</a></p> <div> <img src="myimage.jpg" alt="image description"/> </div> <script src="anotherscript.js"></script> </body> </html>
初始请求的响应包含所接收数据的第一个字节。”Time to First Byte“ (TTFB)是用户通过点击链接进行请求与收到第一个HTML包之间的时间。第一块内容通常是14kb的数据。
上面的例子中,这个请求肯定是小于14kb的,但是直到浏览器在解析阶段遇到链接时才会去请求链接的资源,下面有进行描述。
2.1 TCP 慢开始 / 14kb 规则
第一个响应包是14kb大小。这是慢开始的一部分,慢开始是一种均衡网络连接速度的算法。慢开始逐渐增加发送数据的数量直到达到网络的最大带宽。
在"TCP slow start"中,在收到初始包之后, 服务器会将下一个包的大小加倍到大约28kb。 后续的包依次是前一个包大小的二倍直到达到预定的阈值,或者遇到拥塞。

如果您听说过初始页面加载的14Kb规则,TCP慢开始就是初始响应为14Kb的原因,也是为什么web性能优化需要将此初始14Kb响应作为优化重点的原因。TCP慢开始逐渐建立适合网络能力的传输速度,以避免拥塞。
2.2 拥塞控制
当服务器用TCP包来发送数据时,客户端通过返回确认帧来确认传输。由于硬件和网络条件,连接的容量是有限的。 如果服务器太快地发送太多的包,它们可能会被丢弃。意味着,将不会有确认帧的返回。服务器把它们当做确认帧丢失。拥塞控制算法使用这个发送包和确认帧流来确定发送速率。
3. 解析
一旦浏览器收到数据的第一块,它就可以开始解析收到的信息。“推测性解析”,“解析”是浏览器将通过网络接收的数据转换为DOM和CSSOM的步骤,通过渲染器把DOM和CSSOM在屏幕上绘制成页面。
DOM是浏览器标记的内部表示。DOM也是被暴露的,可以通过JavaScript中的各种API进行DOM操作。
即使请求页面的HTML大于初始的14KB数据包,浏览器也将开始解析并尝试根据其拥有的数据进行渲染。这就是为什么在前14Kb中包含浏览器开始渲染页面所需的所有内容,或者至少包含页面模板(第一次渲染所需的CSS和HTML)对于web性能优化来说是重要的。但是在渲染到屏幕上面之前,HTML、CSS、JavaScript必须被解析完成。
3.1 构建DOM树
我们描述五个步骤在这篇文章中 critical rendering path.
第一步是处理HTML标记并构造DOM树。HTML解析涉及到 tokenization 和树的构造。HTML标记包括开始和结束标记,以及属性名和值。 如果文档格式良好,则解析它会简单而快速。解析器将标记化的输入解析到文档中,构建文档树。
DOM树描述了文档的内容。<html>元素是第一个标签也是文档树的根节点。树反映了不同标记之间的关系和层次结构。嵌套在其他标记中的标记是子节点。DOM节点的数量越多,构建DOM树所需的时间就越长。

当解析器发现非阻塞资源,例如一张图片,浏览器会请求这些资源并且继续解析。当遇到一个CSS文件时,解析也可以继续进行,但是对于<script>标签(特别是没有 async 或者 defer 属性)会阻塞渲染并停止HTML的解析。尽管浏览器的预加载扫描器加速了这个过程,但过多的脚本仍然是一个重要的瓶颈。
3.2 预加载扫描器
浏览器构建DOM树时,这个过程占用了主线程。当这种情况发生时,预加载扫描仪将解析可用的内容并请求高优先级资源,如CSS、JavaScript和web字体。多亏了预加载扫描器,我们不必等到解析器找到对外部资源的引用来请求它。它将在后台检索资源,以便在主HTML解析器到达请求的资源时,它们可能已经在运行,或者已经被下载。预加载扫描仪提供的优化减少了阻塞。
<link rel="stylesheet" src="styles.css"/> <script src="myscript.js" async></script> <img src="myimage.jpg" alt="image description"/> <script src="anotherscript.js" async></script>
在这个例子中,当主线程在解析HTML和CSS时,预加载扫描器将找到脚本和图像,并开始下载它们。为了确保脚本不会阻塞进程,当JavaScript解析和执行顺序不重要时,可以添加async属性或defer属性。
等待获取CSS不会阻塞HTML的解析或者下载,但是它的确阻塞JavaScript,因为JavaScript经常用于查询元素的CSS属性。
3.3 构建CSSOM树
第二步是处理CSS并构建CSSOM树。CSS对象模型和DOM是相似的。DOM和CSSOM是两棵树. 它们是独立的数据结构。浏览器将CSS规则转换为可以理解和使用的样式映射。浏览器遍历CSS中的每个规则集,根据CSS选择器创建具有父、子和兄弟关系的节点树。
与HTML一样,浏览器需要将接收到的CSS规则转换为可以使用的内容。因此,它重复了HTML到对象的过程,但对于CSS。
CSSOM树包括来自用户代理样式表的样式。浏览器从适用于节点的最通用规则开始,并通过应用更具体的规则递归地优化计算的样式。换句话说,它级联属性值。
构建CSSOM非常非常快,并且在当前的开发工具中没有以独特的颜色显示。相反,开发人员工具中的“重新计算样式”显示解析CSS、构造CSSOM树和递归计算计算样式所需的总时间。在web性能优化方面,它是可轻易实现的,因为创建CSSOM的总时间通常小于一次DNS查找所需的时间。
3.4 其他过程
3.4.1 JavaScript 编译
当CSS被解析并创建CSSOM时,其他资源,包括JavaScript文件正在下载(多亏了preload scanner)。JavaScript被解释、编译、解析和执行。脚本被解析为抽象语法树。一些浏览器引擎使用”Abstract Syntax Tree“并将其传递到解释器中,输出在主线程上执行的字节码。这就是所谓的JavaScript编译。
3.4.2 构建辅助功能树
浏览器还构建辅助设备用于分析和解释内容的辅助功能(accessibility )树。可访问性对象模型(AOM)类似于DOM的语义版本。当DOM更新时,浏览器会更新辅助功能树。辅助技术本身无法修改可访问性树。
在构建AOM之前,屏幕阅读器(screen readers)无法访问内容。
4. 渲染
渲染步骤包括样式、布局、绘制,在某些情况下还包括合成。在解析步骤中创建的CSSOM树和DOM树组合成一个Render树,然后用于计算每个可见元素的布局,然后将其绘制到屏幕上。在某些情况下,可以将内容提升到它们自己的层并进行合成,通过在GPU而不是CPU上绘制屏幕的一部分来提高性能,从而释放主线程。
4.1 Style
第三步是将DOM和CSSOM组合成一个Render树,计算样式树或渲染树从DOM树的根开始构建,遍历每个可见节点。
像<head>和它的子节点以及任何具有display: none样式的结点,例如script { display: none; }(在user agent stylesheets可以看到这个样式)这些标签将不会显示,也就是它们不会出现在Render树上。具有visibility: hidden的节点会出现在Render树上,因为它们会占用空间。由于我们没有给出任何指令来覆盖用户代理默认值,因此上面代码示例中的script节点将不会包含在Render树中。
每个可见节点都应用了其CSSOM规则。Render树保存所有具有内容和计算样式的可见节点——将所有相关样式匹配到DOM树中的每个可见节点,并根据CSS级联确定每个节点的计算样式。
4.2 Layout
第四步是在渲染树上运行布局以计算每个节点的几何体。布局是确定呈现树中所有节点的宽度、高度和位置,以及确定页面上每个对象的大小和位置的过程。回流是对页面的任何部分或整个文档的任何后续大小和位置的确定。
构建渲染树后,开始布局。渲染树标识显示哪些节点(即使不可见)及其计算样式,但不标识每个节点的尺寸或位置。为了确定每个对象的确切大小和位置,浏览器从渲染树的根开始遍历它。
在网页上,大多数东西都是一个盒子。不同的设备和不同的桌面意味着无限数量的不同的视区大小。在此阶段,考虑到视区大小,浏览器将确定屏幕上所有不同框的尺寸。以视区的大小为基础,布局通常从body开始,用每个元素的框模型属性排列所有body的子孙元素的尺寸,为不知道其尺寸的替换元素(例如图像)提供占位符空间。
第一次确定节点的大小和位置称为布局。随后对节点大小和位置的重新计算称为回流。在我们的示例中,假设初始布局发生在返回图像之前。由于我们没有声明图像的大小,因此一旦知道图像大小,就会有回流。
4.3 Paint
最后一步是将各个节点绘制到屏幕上,第一次出现的节点称为first meaningful paint。在绘制或光栅化阶段,浏览器将在布局阶段计算的每个框转换为屏幕上的实际像素。绘画包括将元素的每个可视部分绘制到屏幕上,包括文本、颜色、边框、阴影和替换的元素(如按钮和图像)。浏览器需要非常快地完成这项工作。
为了确保平滑滚动和动画,占据主线程的所有内容,包括计算样式,以及回流和绘制,必须让浏览器在16.67毫秒内完成。在2048x 1536,iPad有超过314.5万像素将被绘制到屏幕上。那是很多像素需要快速绘制。为了确保重绘的速度比初始绘制的速度更快,屏幕上的绘图通常被分解成数层。如果发生这种情况,则需要进行合成。
绘制可以将布局树中的元素分解为多个层。将内容提升到GPU上的层(而不是CPU上的主线程)可以提高绘制和重新绘制性能。有一些特定的属性和元素可以实例化一个层,包括<video>和<canvas>,任何CSS属性为opacity、3D转换、will-change的元素,还有一些其他元素。这些节点将与子节点一起绘制到它们自己的层上,除非子节点由于上述一个(或多个)原因需要自己的层。
层确实可以提高性能,但是它以内存管理为代价,因此不应作为web性能优化策略的一部分过度使用。
4.4 Compositing
当文档的各个部分以不同的层绘制,相互重叠时,必须进行合成,以确保它们以正确的顺序绘制到屏幕上,并正确显示内容。
当页面继续加载资源时,可能会发生回流(回想一下我们迟到的示例图像),回流会触发重新绘制和重新组合。如果我们定义了图像的大小,就不需要重新绘制,只需要重新绘制需要重新绘制的层,并在必要时进行合成。但我们没有包括图像大小!从服务器获取图像后,渲染过程将返回到布局步骤并从那里重新开始。
附:深入浅出浏览器渲染原理
1. 前言
浏览器的内核是指支持浏览器运行的最核心的程序,分为两个部分的,一是渲染引擎,另一个是JS引擎。渲染引擎在不同的浏览器中也不是都相同的。比如在 Firefox 中叫做 Gecko,在 Chrome 和 Safari 中都是基于 WebKit 开发的。本文我们主要介绍关于 WebKit 的这部分渲染引擎内容以及几个相关的问题。
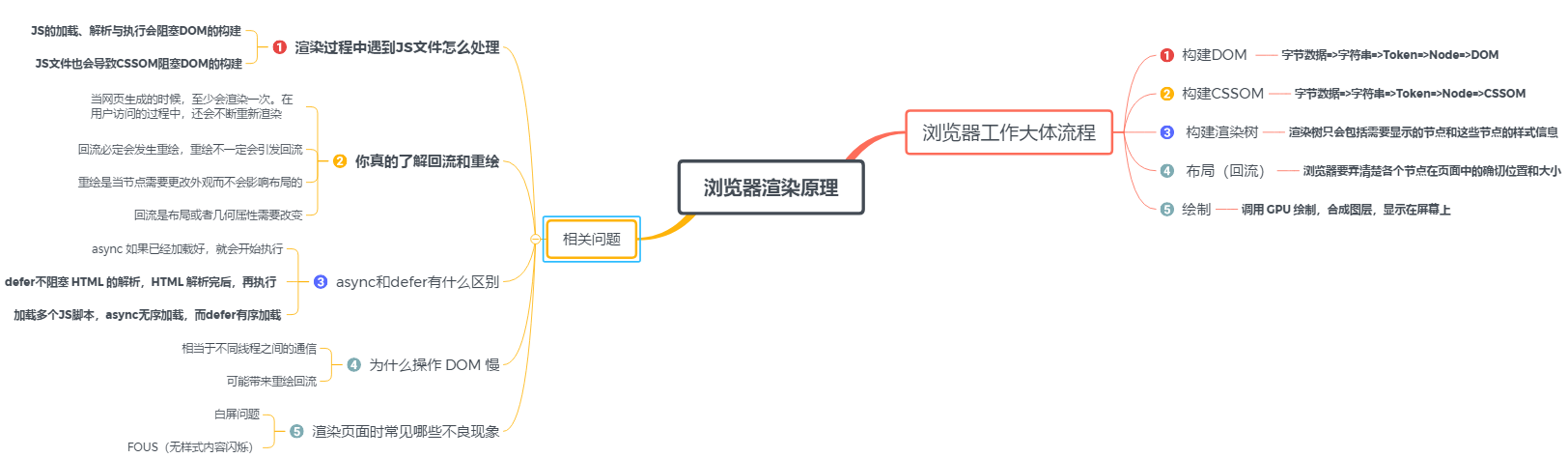
2. 浏览器工作大体流程
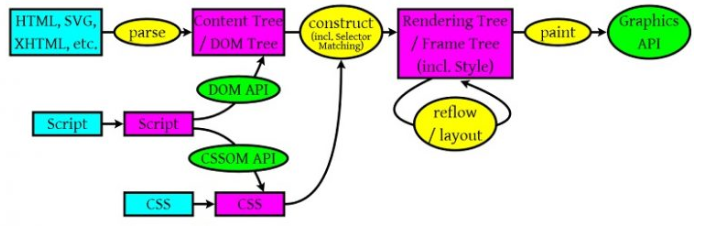
浏览器工作流程大体分为如下三部分:
1)浏览器会解析三个东西:
-
- 一个是HTML/SVG(Scalable Vector Graphics)/XHTML,事实上,Webkit有三个C++的类对应这三类文档。解析这三种文件会产生一个DOM Tree。
- CSS,解析CSS会产生CSS规则树。
- JavaScript,脚本,主要是通过DOM API和CSSOM API来操作DOM Tree和CSS Rule Tree.
2)解析完成后,浏览器引擎会通过DOM Tree 和 CSS Rule Tree 来构造 Rendering Tree。
-
- Rendering Tree 渲染树并不等同于DOM树,因为一些像Header或display:none的东西就没必要放在渲染树中了。
- CSS 的 Rule Tree主要是为了完成匹配并把CSS Rule附加上Rendering Tree上的每个Element。也就是DOM结点。也就是所谓的Frame。
- 然后,计算每个Frame(也就是每个Element)的位置,这又叫layout和reflow过程。
3)最后通过调用操作系统Native GUI的API绘制。
接下来我们针对这其中所经历的重要步骤一一详细阐述。
3. 构建DOM
浏览器会遵守一套步骤将HTML 文件转换为 DOM 树。宏观上,可以分为几个步骤:

-
- 浏览器从磁盘或网络读取HTML的原始字节,并根据文件的指定编码(例如 UTF-8)将它们转换成字符串。
在网络中传输的内容其实都是 0 和 1 这些字节数据。当浏览器接收到这些字节数据以后,它会将这些字节数据转换为字符串,也就是我们写的代码。
-
- 将字符串转换成Token,例如:
<html>、<body>等。Token中会标识出当前Token是“开始标签”或是“结束标签”亦或是“文本”等信息。
- 将字符串转换成Token,例如:
这时候你一定会有疑问,节点与节点之间的关系如何维护?
事实上,这就是Token要标识“起始标签”和“结束标签”等标识的作用。例如“title”Token的起始标签和结束标签之间的节点肯定是属于“head”的子节点。
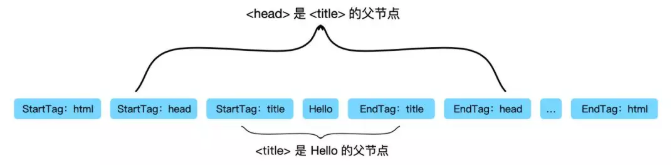
上图给出了节点之间的关系,例如:“Hello”Token位于“title”开始标签与“title”结束标签之间,表明“Hello”Token是“title”Token的子节点。同理“title”Token是“head”Token的子节点。
-
- 生成节点对象并构建DOM
事实上,构建DOM的过程中,不是等所有Token都转换完成后再去生成节点对象,而是一边生成Token一边消耗Token来生成节点对象。换句话说,每个Token被生成后,会立刻消耗这个Token创建出节点对象。注意:带有结束标签标识的Token不会创建节点对象。
接下来我们举个例子,假设有段HTML文本:
<html>
|
上面这段HTML会解析成这样:

4. 构建CSSOM
DOM会捕获页面的内容,但浏览器还需要知道页面如何展示,所以需要构建CSSOM。
构建CSSOM的过程与构建DOM的过程非常相似,当浏览器接收到一段CSS,浏览器首先要做的是识别出Token,然后构建节点并生成CSSOM。

在这一过程中,浏览器会确定下每一个节点的样式到底是什么,并且这一过程其实是很消耗资源的。因为样式你可以自行设置给某个节点,也可以通过继承获得。在这一过程中,浏览器得递归 CSSOM 树,然后确定具体的元素到底是什么样式。
注意:CSS匹配HTML元素是一个相当复杂和有性能问题的事情。所以,DOM树要小,CSS尽量用id和class,千万不要过渡层叠下去。
5. 构建渲染树
当我们生成 DOM 树和 CSSOM 树以后,就需要将这两棵树组合为渲染树。
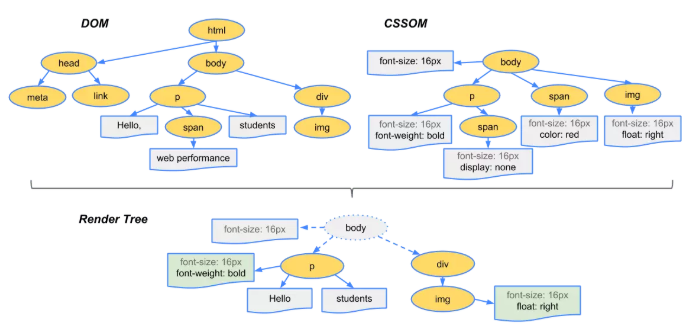
在这一过程中,不是简单的将两者合并就行了。渲染树只会包括需要显示的节点和这些节点的样式信息,如果某个节点是 display: none 的,那么就不会在渲染树中显示。
6. 布局与绘制
当浏览器生成渲染树以后,就会根据渲染树来进行布局(也可以叫做回流)。这一阶段浏览器要做的事情是要弄清楚各个节点在页面中的确切位置和大小。通常这一行为也被称为“自动重排”。
布局流程的输出是一个“盒模型”,它会精确地捕获每个元素在视口内的确切位置和尺寸,所有相对测量值都将转换为屏幕上的绝对像素。
布局完成后,浏览器会立即发出“Paint Setup”和“Paint”事件,将渲染树转换成屏幕上的像素。
以上我们详细介绍了浏览器工作流程中的重要步骤,接下来我们讨论几个相关的问题:
问题一:渲染过程中遇到JS文件怎么处理?
JavaScript的加载、解析与执行会阻塞DOM的构建,也就是说,在构建DOM时,HTML解析器若遇到了JavaScript,那么它会暂停构建DOM,将控制权移交给JavaScript引擎,等JavaScript引擎运行完毕,浏览器再从中断的地方恢复DOM构建。
也就是说,如果你想首屏渲染的越快,就越不应该在首屏就加载 JS 文件,这也是都建议将 script 标签放在 body 标签底部的原因。当然在当下,并不是说 script 标签必须放在底部,因为你可以给 script 标签添加 defer 或者 async 属性(下文会介绍这两者的区别)。
JS文件不只是阻塞DOM的构建,它会导致CSSOM也阻塞DOM的构建。
原本DOM和CSSOM的构建是互不影响,井水不犯河水,但是一旦引入了JavaScript,CSSOM也开始阻塞DOM的构建,只有CSSOM构建完毕后,DOM再恢复DOM构建。
这是什么情况?
这是因为JavaScript不只是可以改DOM,它还可以更改样式,也就是它可以更改CSSOM。前面我们介绍,不完整的CSSOM是无法使用的,但JavaScript中想访问CSSOM并更改它,那么在执行JavaScript时,必须要能拿到完整的CSSOM。所以就导致了一个现象,如果浏览器尚未完成CSSOM的下载和构建,而我们却想在此时运行脚本,那么浏览器将延迟脚本执行和DOM构建,直至其完成CSSOM的下载和构建。也就是说,在这种情况下,浏览器会先下载和构建CSSOM,然后再执行JavaScript,最后在继续构建DOM。
问题二:你真的了解回流和重绘吗
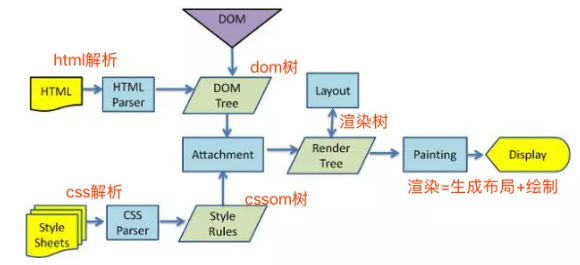
我们知道,当网页生成的时候,至少会渲染一次。在用户访问的过程中,还会不断重新渲染。重新渲染会重复上图中的第四步(回流)+第五步(重绘)或者只有第五个步(重绘)。
-
- 重绘:当render tree中的一些元素需要更新属性,而这些属性只是影响元素的外观、风格,而不会影响布局的,比如background-color。
- 回流:当render tree中的一部分(或全部)因为元素的规模尺寸、布局、隐藏等改变而需要重新构建
回流必定会发生重绘,重绘不一定会引发回流。重绘和回流会在我们设置节点样式时频繁出现,同时也会很大程度上影响性能。回流所需的成本比重绘高的多,改变父节点里的子节点很可能会导致父节点的一系列回流。
1)常见引起回流属性和方法
任何会改变元素几何信息(元素的位置和尺寸大小)的操作,都会触发回流,
-
- 添加或者删除可见的DOM元素;
- 元素尺寸改变——边距、填充、边框、宽度和高度
- 内容变化,比如用户在input框中输入文字
- 浏览器窗口尺寸改变——resize事件发生时
- 计算 offsetWidth 和 offsetHeight 属性
- 设置 style 属性的值

2)常见引起重绘属性和方法
下面例子中,触发了几次回流和重绘?
var s = document.body.style;
|
3)如何减少回流、重绘
-
- 使用 transform 替代 top
- 使用 visibility 替换 display: none ,因为前者只会引起重绘,后者会引发回流(改变了布局)
- 不要把节点的属性值放在一个循环里当成循环里的变量。
for(let i = 0; i < 1000; i++) {
|
-
- 不要使用 table 布局,可能很小的一个小改动会造成整个 table 的重新布局
- 动画实现的速度的选择,动画速度越快,回流次数越多,也可以选择使用 requestAnimationFrame
- CSS 选择符从右往左匹配查找,避免节点层级过多
- 将频繁重绘或者回流的节点设置为图层,图层能够阻止该节点的渲染行为影响别的节点。比如对于 video 标签来说,浏览器会自动将该节点变为图层。
问题三:async和defer的作用是什么?有什么区别?
接下来我们对比下 defer 和 async 属性的区别:

其中蓝色线代表JavaScript加载;红色线代表JavaScript执行;绿色线代表 HTML 解析。
1)情况1<script src="script.js"></script>
没有 defer 或 async,浏览器会立即加载并执行指定的脚本,也就是说不等待后续载入的文档元素,读到就加载并执行。
2)情况2<script async src="script.js"></script> (异步下载)
async 属性表示异步执行引入的 JavaScript,与 defer 的区别在于,如果已经加载好,就会开始执行——无论此刻是 HTML 解析阶段还是 DOMContentLoaded 触发之后。需要注意的是,这种方式加载的 JavaScript 依然会阻塞 load 事件。换句话说,async-script 可能在 DOMContentLoaded 触发之前或之后执行,但一定在 load 触发之前执行。
3)情况3 <script defer src="script.js"></script>(延迟执行)
defer 属性表示延迟执行引入的 JavaScript,即这段 JavaScript 加载时 HTML 并未停止解析,这两个过程是并行的。整个 document 解析完毕且 defer-script 也加载完成之后(这两件事情的顺序无关),会执行所有由 defer-script 加载的 JavaScript 代码,然后触发 DOMContentLoaded 事件。
defer 与相比普通 script,有两点区别:**载入 JavaScript 文件时不阻塞 HTML 的解析,执行阶段被放到 HTML 标签解析完成之后。
在加载多个JS脚本的时候,async是无顺序的加载,而defer是有顺序的加载。**
问题四:为什么操作 DOM 慢
因为 DOM 是属于渲染引擎中的东西,而 JS 又是 JS 引擎中的东西。当我们通过 JS 操作 DOM 的时候,其实这个操作涉及到了两个线程之间的通信,那么势必会带来一些性能上的损耗。操作 DOM 次数一多,也就等同于一直在进行线程之间的通信,并且操作 DOM 可能还会带来重绘回流的情况,所以也就导致了性能上的问题。
问题五:渲染页面时常见哪些不良现象?
由于浏览器的渲染机制不同,在渲染页面时会出现两种常见的不良现象—-白屏问题和FOUS(无样式内容闪烁)
FOUC:由于浏览器渲染机制(比如firefox),再CSS加载之前,先呈现了HTML,就会导致展示出无样式内容,然后样式突然呈现的现象;
白屏:有些浏览器渲染机制(比如chrome)要先构建DOM树和CSSOM树,构建完成后再进行渲染,如果CSS部分放在HTML尾部,由于CSS未加载完成,浏览器迟迟未渲染,从而导致白屏;也可能是把js文件放在头部,脚本会阻塞后面内容的呈现,脚本会阻塞其后组件的下载,出现白屏问题。
总结
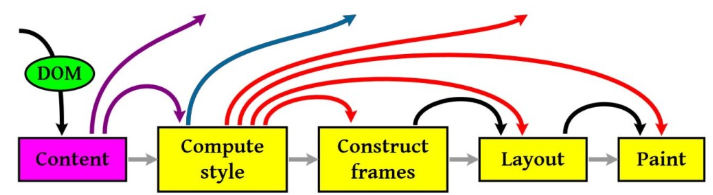
-
-
浏览器工作流程:构建DOM -> 构建CSSOM -> 构建渲染树 -> 布局 -> 绘制。
-
CSSOM会阻塞渲染,只有当CSSOM构建完毕后才会进入下一个阶段构建渲染树。
-
通常情况下DOM和CSSOM是并行构建的,但是当浏览器遇到一个script标签时,DOM构建将暂停,直至脚本完成执行。但由于JavaScript可以修改CSSOM,所以需要等CSSOM构建完毕后再执行JS。
- 如果你想首屏渲染的越快,就越不应该在首屏就加载 JS 文件,建议将 script 标签放在 body 标签底部。
-
附:JavaScript 运行原理解析
说到JavaScript的运行原理,自然绕不开JS引擎,运行上下文,单线程,事件循环,事件驱动,回调函数等概念。本文主要参考文章[1,2]。
为了更好的理解JavaScript如何工作的,首先要理解以下几个概念。
-
- JS Engine(JS引擎)
- Runtime(运行上下文)
- Call Stack (调用栈)
- Event Loop(事件循环)
- Callback (回调)
1.JS Engine
简单来说,JS引擎主要是对JS代码进行词法、语法等分析,通过编译器将代码编译成可执行的机器码让计算机去执行。
目前最流行的JS引擎非V8莫属了,Chrome浏览器和Node.js采用的引擎就是V8引擎。引擎的结构可以简单由下图表示:
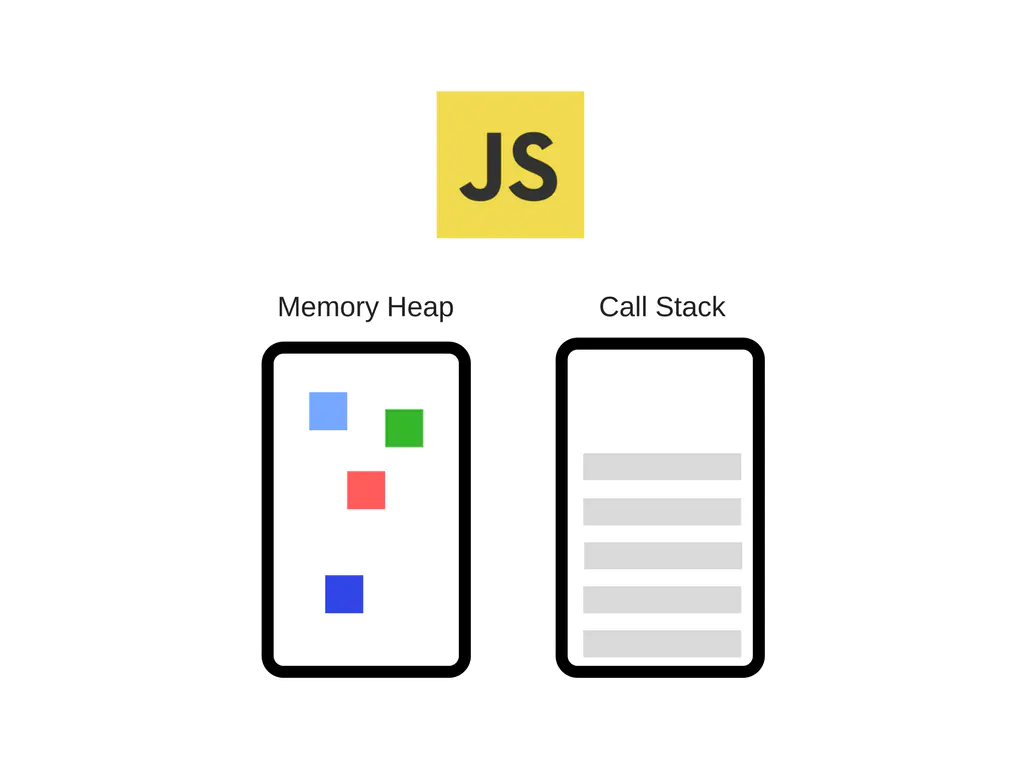
就如JVM虚拟机一样,JS引擎中也有堆(Memory Heap)和栈(Call Stack)的概念。
-
-
栈。用来存储方法调用的地方,以及基础数据类型(如var a = 1)也是存储在栈里面的,会随着方法调用结束而自动销毁掉(入栈-->方法调用后-->出栈)。
-
堆。JS引擎中给对象分配的内存空间是放在堆中的。如var foo = {name: 'foo'} 那么这个foo所指向的对象是存储在堆中的。
-
此外,JS中存在闭包的概念,对于基本类型变量如果存在与闭包当中,那么也将存储在堆中。详细可见此处1,3
关于闭包的情况,就涉及到Captured Variables。我们知道Local Variables是最简单的情形,是直接存储在栈中的。而Captured Variables是对于存在闭包情况和with,try catch情况的变量。
function foo () {
var x; // local variables
var y; // captured variable, bar中引用了y
function bar () {
// bar 中的context会capture变量y
use(y);
}
return bar;
}
如上述情况,变量y存在与bar()的闭包中,因此y是captured variable,是存储在堆中的。
2.RunTime
JS在浏览器中可以调用浏览器提供的API,如window对象,DOM相关API等。这些接口并不是由V8引擎提供的,是存在与浏览器当中的。因此简单来说,对于这些相关的外部接口,可以在运行时供JS调用,以及JS的事件循环(Event Loop)和事件队列(Callback Queue),把这些称为RunTime。有些地方也把JS所用到的core lib核心库也看作RunTime的一部分。

同样,在Node.js中,可以把Node的各种库提供的API称为RunTime。所以可以这么理解,Chrome和Node.js都采用相同的V8引擎,但拥有不同的运行环境(RunTime Environments)[4]。
3.Call Stack
JS被设计为单线程运行的,这是因为JS主要用来实现很多交互相关的操作,如DOM相关操作,如果是多线程会造成复杂的同步问题。因此JS自诞生以来就是单线程的,而且主线程都是用来进行界面相关的渲染操作 (为什么说是主线程,因为HTML5 提供了Web Worker,独立的一个后台JS,用来处理一些耗时数据操作。因为不会修改相关DOM及页面元素,因此不影响页面性能),如果有阻塞产生会导致浏览器卡死。
如果一个递归调用没有终止条件,是一个死循环的话,会导致调用栈内存不够而溢出,如:
function foo() {
foo();
}
foo();
例子中foo函数循环调用其本身,且没有终止条件,浏览器控制台输出调用栈达到最大调用次数。
JS线程如果遇到比较耗时操作,如读取文件,AJAX请求操作怎么办?这里JS用到了Callback回调函数来处理。
对于Call Stack中的每个方法调用,都会形成它自己的一个执行上下文Execution Context,关于执行上下文的详细阐述请看这篇文章
4.Event Loop & Callback
JS通过回调的方式,异步处理耗时的任务。一个简单的例子:
var result = ajax('...');
console.log(result);
此时并不会得到result的值,result是undefined。这是因为ajax的调用是异步的,当前线程并不会等到ajax请求到结果后才执行console.log语句。而是调用ajax后请求的操作交给回调函数,自己是立刻返回。正确的写法应该是:
ajax('...', function(result) {
console.log(result);
})
此时才能正确输出请求返回的结果。
JS引擎其实并不提供异步的支持,异步支持主要依赖于运行环境(浏览器或Node.js)。
So, for example, when your JavaScript program makes an Ajax request to fetch some data from the server, you set up the “response” code in a function (the “callback”), and the JS Engine tells the hosting environment: “Hey, I’m going to suspend execution for now, but whenever you finish with that network request, and you have some data, please call this function back.”
The browser is then set up to listen for the response from the network, and when it has something to return to you, it will schedule the callback function to be executed by inserting it into the event loop.
上面这两段话摘自于How JavaScript works,以通俗的方式解释了JS如何调用回调函数实现异步处理。
所以什么是Event Loop?
Event Loop只做一件事情,负责监听Call Stack和Callback Queue。当Call Stack里面的调用栈运行完变成空了,Event Loop就把Callback Queue里面的第一条事件(其实就是回调函数)放到调用栈中并执行它,后续不断循环执行这个操作。
一个setTimeout的例子以及对应的Event Loop动态图:
console.log('Hi');
setTimeout(function cb1() {
console.log('cb1');
}, 5000);
console.log('Bye');
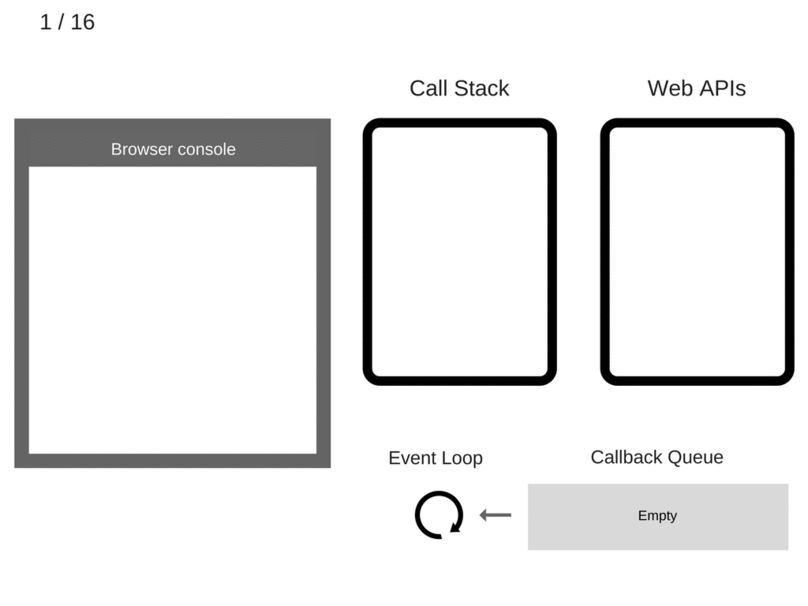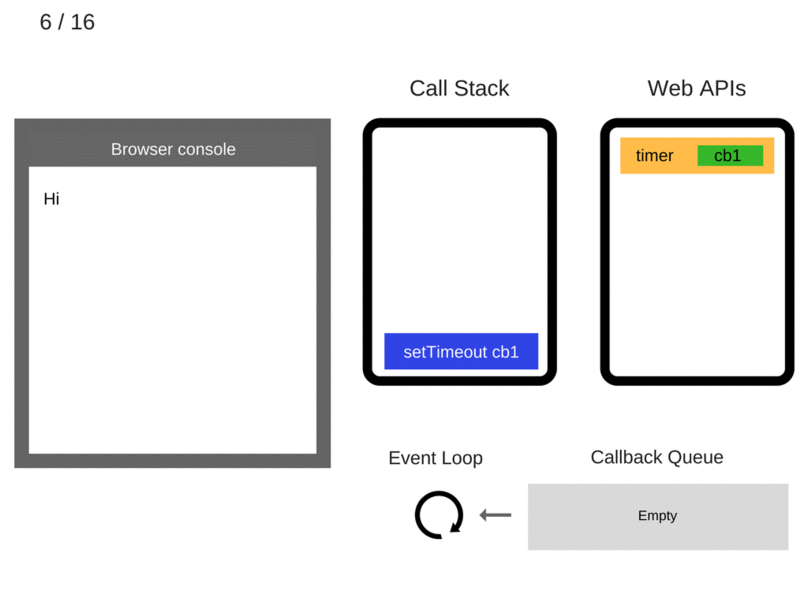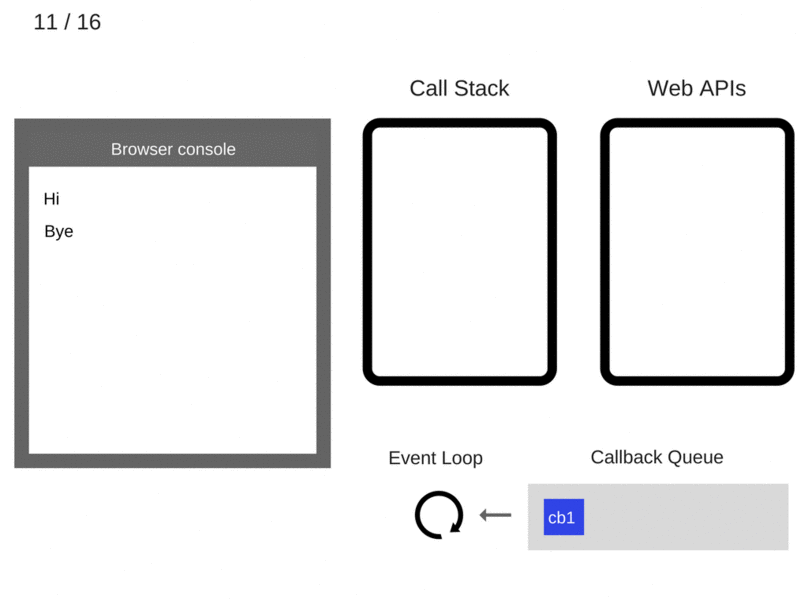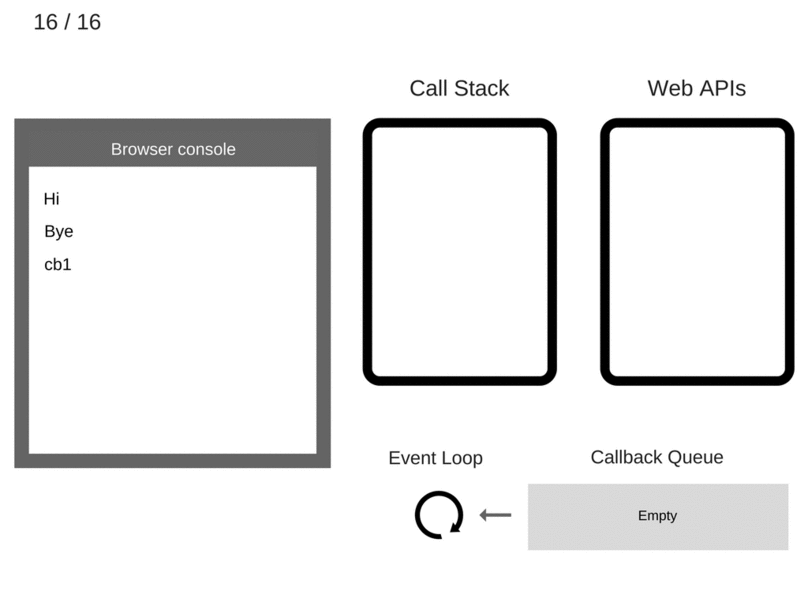
setTimeout有个要注意的地方,如上述例子延迟5s执行,不是严格意义上的5s,正确来说是至少5s以后会执行。因为Web API会设定一个5s的定时器,时间到期后将回调函数加到队列中,此时该回调函数还不一定会马上运行,因为队列中可能还有之前加入的其他回调函数,而且还必须等到Call Stack空了之后才会从队列中取一个回调执行。
所以常见的setTimeout(callback, 0) 的做法就是为了在常规的调用介绍后马上运行回调函数。
console.log('Hi');
setTimeout(function() {
console.log('callback');
}, 0);
console.log('Bye');
// 输出
// Hi
// Bye
// callback
在说一个容易犯错的栗子:
for (var i = 0; i < 5; i++) {
setTimeout(function() {
console.log(i);
}, 1000 * i);
}
// 输出:5 5 5 5 5
上面这个栗子并不是输出0,1,2,3,4,第一反应觉得应该是这样。但梳理了JS的时间循环后,应该很容易明白。
调用栈先执行 for(var i = 0; i < 5; i++) {...}方法,里面的定时器会到时间后会直接把回调函数放到事件队列中,等for循环执行完在依次取出放进调用栈。当for循环执行完时,i的值已经变成5,所以最后输出全都是5。
关于定时器又可以看看这篇有意思的文章
最后关于Event Loop,可以参考下这个视频。到目前为止说的event loop是前端浏览器中的event loop,关于Nodejs的Event Loop的细节阐述,请看我的另一篇文章Node.js design pattern : Reactor (Event Loop)。两者的区别对比可查看这篇文章你不知道的Event Loop,对两种event loop做了相关总结和比较。
总结
最后总结一下,JS的运行原理主要有以下几个方面:
-
-
JS引擎主要负责把JS代码转为机器能执行的机器码,而JS代码中调用的一些WEB API则由其运行环境提供,这里指的是浏览器。
-
JS是单线程运行,每次都从调用栈出取出代码进行调用。如果当前代码非常耗时,则会阻塞当前线程导致浏览器卡顿。
-
回调函数是通过加入到事件队列中,等待Event Loop拿出并放到调用栈中进行调用。只有Event Loop监听到调用栈为空时,才会从事件队列中从队头拿出回调函数放进调用栈里。
-
1.How JavaScript works: an overview of the engine, the runtime, and the call stack
5. 交互
一旦主线程绘制页面完成,你会认为我们已经“准备好了”,但事实并非如此。如果加载包含JavaScript(并且延迟到onload事件激发后执行),则主线程可能很忙,无法用于滚动、触摸和其他交互。
”Time to Interactive“(TTI)是测量从第一个请求导致DNS查找和SSL连接到页面可交互时所用的时间——可交互是”First Contentful Paint“之后的时间点,页面在50ms内响应用户的交互。如果主线程正在解析、编译和执行JavaScript,则它不可用,因此无法及时(小于50ms)响应用户交互。
在我们的示例中,可能图像加载很快,但anotherscript.js文件可能是2 MB,而且用户的网络连接很慢。在这种情况下,用户可以非常快地看到页面,但是在下载、解析和执行脚本之前,就无法滚动。这不是一个好的用户体验。避免占用主线程,如下面的WebPageTest示例所示:

在本例中,DOM内容加载过程花费了1.5秒多的时间,主线程在这段时间内完全被占用,对单击事件或屏幕点击没有响应。
分析完了浏览器的原理之后再落实到代码语法的本身。
HTML:
CSS:


JavaScript:
贴一段上面连接数据库的代码感受一下JavaScript的语法特点,当然绝不止这些,我觉得只要到达能看的懂并能简单的改动代码的功能就可以了,想深入完全可以沉浸进去好好训练一番。
<script> //创建数据库连接对象 var conn = new ActiveXObject("ADODB.Connection"); //创建数据集对象 var rs = new ActiveXObject("ADODB.Recordset"); try { //数据库连接串,具体配置请参考:http://www.connectionstrings.com/ var connectionString = "Driver={MySQL ODBC 5.2 ANSI Driver};Server=127.0.0.1;User=root;Password=237001;Database=sakila;Option=3;Port=3306"; console.log(connectionString); //打开连接 conn.open(connectionString); for (var i = 1; i < 10; i ++) { var id_1 = 10*i + 1; var id_2 = 10*i + 2; var id_3 = 10*i + 3; //查询语句 var sql = "select images, price, description from bzt369 where location = " + i + ";"; //打开数据集(即执行查询语句) //rs.open(sql,conn);//(或者rs=conn.execute(sql)) rs=conn.execute(sql); //alert("数据库查询成功"); var image = rs.Fields("images"); var price = rs.Fields("price"); var description = rs.Fields("description"); document.getElementById(id_1).src = image; //document.getElementById(id_1).setAttribute('src', '../images/鞋1'); document.getElementById(id_2).innerHTML = description; document.getElementById(id_3).innerHTML = price; } //关闭记录集 rs.close(); //关闭数据库连接 conn.close(); } catch(e){ alert("查询失败:" + e.message); //异常报告 console.log(e.message); } finally { //TODO } </script>
附:网页的加载速度优化
网站的打开速度是一个非常重要的用户体验考核标准,当然,影响网站打开速度的原因有很多,比如服务器的问题,比如程序的问题等等,本文和大家主要分析的不是外部因素,主要是大家在网站设计过程当中,把内部因素做到极致,加快网站的打开速度就是这么简单!
一、如何判断一个网页的打开速度
1、网页内容的大小
搜索引擎优化网页打开的最佳速度:2秒! 网页内容所包括的文本、产品的图片、视频、flash文件等。 我们有一个网页访问的时间计算公式:网页打开时间=网页内容大小/最小带宽+解析次数*每次解析时间+服务器处理时间+客户端解析时间。用户最满意的打开 网页时间,是在2秒以下。用户能够忍受的最长等待时间的中位数,在 6-8秒之间。这就是说,8秒是个临界值,如果你的网站打开速度在8秒以上,那么很可能,大部分访问者最终都会离你而去。
2、控制页面的总规模
要想把网页做得精彩,内容必须丰富,但不要把所有的内容都放在一个页面上,应控制页面的总规模。首先统计页面中的每个元素,如文字、图像、activex或java代码 以及html文本的大小,页面容量最好在50k以下。
二、网页设计优化
网页优化是指在设计,使用网页各元素时,能够尽量减少网页元素对下载速度所产生的影响。这些细节我们了解后,是能在日常网页制作中可以进行避免的。
1、让网页符合w3c(World Wide Web Consortium)标准
(1) 在网页制作中使 用结构层同表现层完全分离。也就 是布局使用用css而不用table。这样做不仅能替换掉专业的表现层的垃圾代码如标签。而且也能让你的网站在重构方而能够轻松实现。几年来的多项研宄已 证实,如果对一个网站进行重写,使用div+css布局取代表格布局,那么可以砍掉原xhmtl文档大小的一半。
(2) 让html标记有始有终。不管是我们自己写或是查看他人的html代码时,会发现html代码标签写得不规范。有的标记有头无尾,如 标签li,标签p。它并没有妨碍代码的正确执行。但浏览器却会花费时间来判断和计算段落或者列表项目在哪里结束。所以,我们一定要让标记有始有终,这样做 不仅使html代码格式规范,更可以加速页面的显示速度。
2、优化层叠样式表
(1) 层叠样式表css是html的装扮器,一个漂亮的web页面不可能没有它。一般来说,我们要合并精减css代码,移除无用多余代码;图片尽量不要使用css的滤镜来渲染; css的选择器尽量简单定义。
(2) html页面中有多种引用css的方法,不同的方法导致的效率也不一样。通常,我们可以将定义于<style></style>间的样式控制代码提取出来,保存到单独的.css文件中,然后在HTML页面中以<LINK>标记或者@import标记的方式进行引用:
<style>
@import url("mysheet1.css");
</style>
请注意2点:1、.css文件中无需包括<style>标记;2、@import和LINK标记要定义在HTML页面的HEAD部分。
3、优化图片
图片可以说是影响网页加载速度最大的因素,不管是使用图片优化工具,还是减小图片大小。在质量和文件大小之间必须找到一个合适的均衡点。主要有以下几个需了解的方面。
(1)一般在网页上使用的图片格式有三种,jpg、png、gif。我们只需要知道在什么时候应该使用什么格式,以减少网页的加载时间。
(2)图片的使用显示。需要显示图片时,尽量使用背景图片,而不是直接加载。也需要注意的是尽量不要用一个很小的图片当背景,这样做会加大客户端cpu处理时间。比如说预载入下一页的主要内容时。在用户看到大图之前先把小图展开,让用户不至于在等待的过程中太焦虑。
(3)图片在html代码里要标明大小。这样浏览器就能事先留好空。当你在网页上添加图片或表格时,你应该指定它们的高度和宽度,也就是参数。如果浏览器没有 找到height和width这两个参数, 它需要一边下载图片一边计算大小,如果图片很多,浏览器需要不断地调整页面。这不但影响速度, 也影响浏览体验。
4、优化脚本语言
(1)网页的效果离不开脚本程序的支持,我们经常会在页面中嵌入多种脚本语言,比如常用到的javascript 与vbscript语言。动态脚本代码在使用中也可以进行一定的优化。在网页中使用同一种脚本语言。不知你发觉没有,在一个网页中使用到多种脚本代码时, 这样的混合使用会减慢页面的访问速度。原因在于:要解释并运行多种脚本代码,就必须在内存中装载多种脚本引擎。所以,请尽量在页面中使用同一种脚本语言编 写代码。
(2)能用层叠样式表实现效果时,不使用脚本语言。如必须使用动态脚本代码时,尽量将代码外放。我们知道搜索引擎是不能读取脚本语言的。如 果你觉得往外放太 过麻烦,我们可以将脚本代码与网页分离,单独放到底部来。对于访客来说,网站打开至加载到底部的代码时间很短,有时可以忽略不记,所以不会影响什么。而对 于搜索引擎来说它不认识的代码越少当然越好了。
(3)将多个页面都用到的脚本程序编写成独立存在的脚本文件,然后再在页面中通过JavaScript等脚文语言调用它。将多页面共有部分 提取出来减少web页面下载时间的关键就是设法减小文件大小。当多个页面共用一些成分内容时,就可以考虑将这些公用部分单独分离出来。这样,公用文件只需要下载一次,然后就进入缓冲区。等下 再次调用包含公用文件的html页面时,下载时间明显减少。
(4)有很多站长朋友们总是会自认为网站的一些网页特效多一点(也就是用JS代码实现这些特效),可以增加网站的用户体验度。殊不知,这样会导致网站的页面加载速度过慢,另一方面用户通常不会愿意等待加载超过5秒的网页,因此,就会导致用户的流失了。网站可以适当地加一些JS代码做网页特效,如果JS代码超过3个以上的话就要合并成一个JS文件,这样可以提高网页加载的速度。
5、其它技巧的优化
(1)巧用iframe布局
巧用iframe加快网页打开速度。如果网页上插入一些广告代码,又不想让这些广告网站影响 度的话,那么,使用iframe最合适不过了。例如在某个首页上插入一些广告代码方法:将这些广告代码放到一个独立的页面去,然后在首页用iframe代 码将该页面嵌入即可,这样就不会因为广告页面的延迟而拖了整个首页的显示。又比 如,开发一个文档预览页面,可以在左边放置一系列主题,在右边放置一个iframe,其中包含要预览的文档;当鼠标掠过左边的每一个主题链接时,就在右边 建立一个 预览文档。我们只需使用单一且简化了处理过程。
(2)不要让统计代码影响速度
很多网站都有统计代码,为站长和广告商家提供访问依据,但是,不管功能有多强大的网站统计系统,都会有出问题的时候。都要运行时间,如果直 接把统计代码放到页面内容的前面,或者放在一个table或者div标签里,那么在计数器不能访问的时候,你的页面上那个table或者div就会产生几 十秒钟的延迟,导致页面很长时间才能访问。所以,要提高网站的速度,就要讲究统计代码放置的位置,推荐的做法是:把统计代码放到页面的最下面,并且不要和 页面内容同在一个table或者div标签里。 可以在页面代码的最下方直接放置统计代码,或者在最下方单独做一 个table或者div来放置计数器,这样,在计数器不能访问的时候,你的 iframe,修改它的src属性即可。这样做,不仅代码效率高效,而网站速度也不会受到丝毫影响。
(3)页面静态化设计
有些内容可以静态化就将其静态化,以减少服务器的负担。 如用图片代替flash,这对SEO(Search engine optimization )也 有好处。同理,能用静态html页面实现的,尽量用静态网页。因为数据 更新的原因,asp、php、jsp等程 序实现了网页信息的动态交互,运行起来的确非常方便,因为它们的 数据交互性好,能很方便存取最新 内容、更改数据库的内容,使网站 “动”起来,如:论坛、留言板 等。但是这类程序必须先由服务 执行处理后,生成html页面,然后 再“送”往客户端浏览,这就不得 不耗费一定的服务器资源。如果在 虚拟主机上过多地使用这类程序, 网页显示速度肯定会慢,所以如何 可能,为了网页打开速度加快,请 尽量使用静态的html页面。
对于网页设计者来说。每一个页面都应该是精雕细刻,尽其可能优化每一个细节,加快网页下载打开的速度,以提高用户体验的感受,能够让我们的网站有更好的用户体验,赶快按照上面说的方法,让自己的网站打开速度飞起来吧!
减少web页面下载时间的关键就是设法减小文件大小。当多个页面共用一些成分内容时,就可以考虑将这些公用部分单独分离出来。比如:我们可以将多个HTML页面都用到的脚本程序编写成独立存在的.js文件,然后再在页面中按如下方式调用它:
<script src="myfile.js"></script>
这样,公用文件只需要下载一次,然后就进入缓冲区。等下次再次调用包含公用文件的html页面时,下载时间明显减少。
让样式表内容进入地下工作
北京网站建设公司称CSS是HTML装扮器,一个漂亮的Web页面不可能没有它。HTML页面中有多种引用CSS的方法,不同的方法导致的效率也不一样。通常,我们可以将定义于<style></style>间的样式控制代码提取出来,保存到单独的.css文件中,然后在HTML页面中以<LINK>标记或者@import标记的方式进行引用:
<style>
@import url("mysheet1.css");
</style>
请注意2点:1、.css文件中无需包括<style>标记;2、@import和LINK标记要定义在HTML页面的HEAD部分。
宝贵内存节省两法
尽量减少HTML页面占用的内存空间是加快页面下载速度的一个有效方法。在这方面,有2个需要注意的问题:
1、使用同一种脚本语言
HTML页面离不开脚本程序的支持,我们经常会在页面中嵌入多种脚本语言,比如JavaScript与VBScript。但是,不知你发觉没有:这样的混合使用减慢了页面的访问速度。原因在于:要解释并运行多种脚本代码,就必须在内存中装载多种脚本引擎。所以,请尽量在页面中使用同一种脚本语言编写代码。
2、巧用IFrame
你使用过<IFRAME>标记吗?它可是一个非常美妙的功能。如果要在一个HTML文档中包含第2个页面的内容,通常的方法是使用<FRAMESET>标记。但是有了<IFRAME>,一切变得简单了。比如,开发一个文档预览页面,可以在左边放置一系列主题,在右边放置一个IFRAME,其中包含要预览的文档;当鼠标掠过左边的每一个主题链接时,就在右边建立一个新的IFRAME以预览文档。这样做,代码效率无疑是高效的,但同时导致了繁重的处理过程,最终是缓慢的速度。
只使用单一的IFRAME。当鼠标指向一个新主题时,只需要修改IFRAME元素的SRC属性即可。这样,任何时间内只会有一个预览文档保留在内存。
择优选用动画定位属性
每天上网浏览页面,你一定会看到许多动画效果。比如,一个可爱的小兔子在页面上来回地走动 ... 实现这个效果的核心技术就是CCS定位。通常,我们是使用element.style.left和element.style.top2个属性来达到图形定位的目的。但是,这样做会产生一些问题:left属性返回一个字符串,并且其中包含了度量单位(比如100px)。因此,要设定新的位置坐标,就必须首先对这个字符串返回值进行处理,然后才能赋值,像下面一样:
dim stringLeft, intLeft
stringLeft = element.style.left
intLeft = parseInt(stringLeft)
intLeft = intLeft + 10
element.style.left = intLeft;
你一定会感觉做这么点事情竟要编写这么复杂的代码,是否有更简洁的方法?看这4个属性:posLeft、posTop、posWidth 和 posHeight,它们对应于相应字符串返回值的点数数值。好了,使用这些属性重新编写代码实现上面代码实现的功能:
element.style.posLeft += 10
代码短小、速度却更快!
循环控制多个动画
说到制作动画效果,当然离不开定时器的运用。通常的方法就是使用window.setTimeout来不断地定位页面上的元素。但是,如果页面上有多个动画要显示,是不是就要设定多个定时器呢?答案是No!原因很简单:定时器功能将消耗掉大量宝贵的系统资源。可是我们仍能在页面上控制多个动画,技巧就是使用一个循环。在循环中根据不同的变量值控制相应动画的位置,整个循环中只使用一个window.setTimeout()函数调用。
Visibility快于Display
让图画时隐时现会创造很有趣的效果,有2种方法可以实现这个目的:使用CSS的visibility属性或者display属性。对于绝对位置元素,diaplay和visibility具有同样的效果。两者的区别在于:设置为display:none的元素将不再占用文档流的空间,而设置为visibility:hidden的元素仍然保留原位置。
但是如果要处理绝对位置的元素,使用visibility会更快。
从小处着手
编写DHTML网页的一个重要提示是:从小处着手。初次编写DHTML页面时,一定不要试图在页面中使用你了解到的全部DHTML功能。每次可以只使用一个单一的新特征,并且仔细地观察由此产生的变化。如果发现性能有所下降,就可以快速地找到为什么。
脚本的DEFER化
DEFER是脚本程序强大功能中的一个“无名英雄”。你可能从没有使用过它,但是看完这里的介绍后,相信你就离不开它。它告诉浏览器Script段包含了无需立即执行的代码,并且,与SRC属性联合使用,它还可以使这些脚本在后台被下载,前台的内容则正常显示给用户。
最后请注意两点:
1、不要在defer型的脚本程序段中调用document.write命令,因为document.write将产生直接输出效果。
2、而且,不要在defer型脚本程序段中包括任何立即执行脚本要使用的全局变量或者函数。
保持同一URL的大小写一致性
我们都知道UNIX服务器是大小写敏感的,但是你知道吗:Internet Explorer的缓冲区也是区别对待大小写字符串的。因此,作为web开发者,一定要记住保持相同链接的URL字符串在不同位置的大小写的一致性。否则,就会在浏览器的缓冲区中存放同一位置的不同文件备份,也增加了下载同一位置内容的请求次数。这些都无疑降低了web访问效率。所以请谨记:同一位置的URL,在不同页面中请保持URL字符串的大小写一致性。
让标记有始有终
自己编写或者查看他人的HTML代码时,我们一定都遇到过标记有头无尾的情况。比如:
<P>有头无尾标记举例
<UL>
<LI>第一个
<LI>第二个
<LI>第三个
</UL>
很明显,上面的代码中缺少三个</LI>结束标记。但是这并不妨碍它的正确执行。在HTML中,这样的标记还有一些,例如FRAME、IMG和P。
可是请不要偷懒,请将结束标记写完整,这样做不仅使HTML代码格式规范,更可以加速页面的显示速度。因为Internet Explorer将不会花费时间判断和计算段落或者列表项目在哪里结束。
<P>有头有尾标记举例</P>
<UL>
<LI>第一个</LI>
<LI>第二个</LI>
<LI>第三个</LI>
</UL>
以上列举了有关加速HTML页面的11个处理技巧,描述这些很简单,但是只有真正领会并掌握其中的本质,并且举一反三,才会编写出更快、更好的程序。
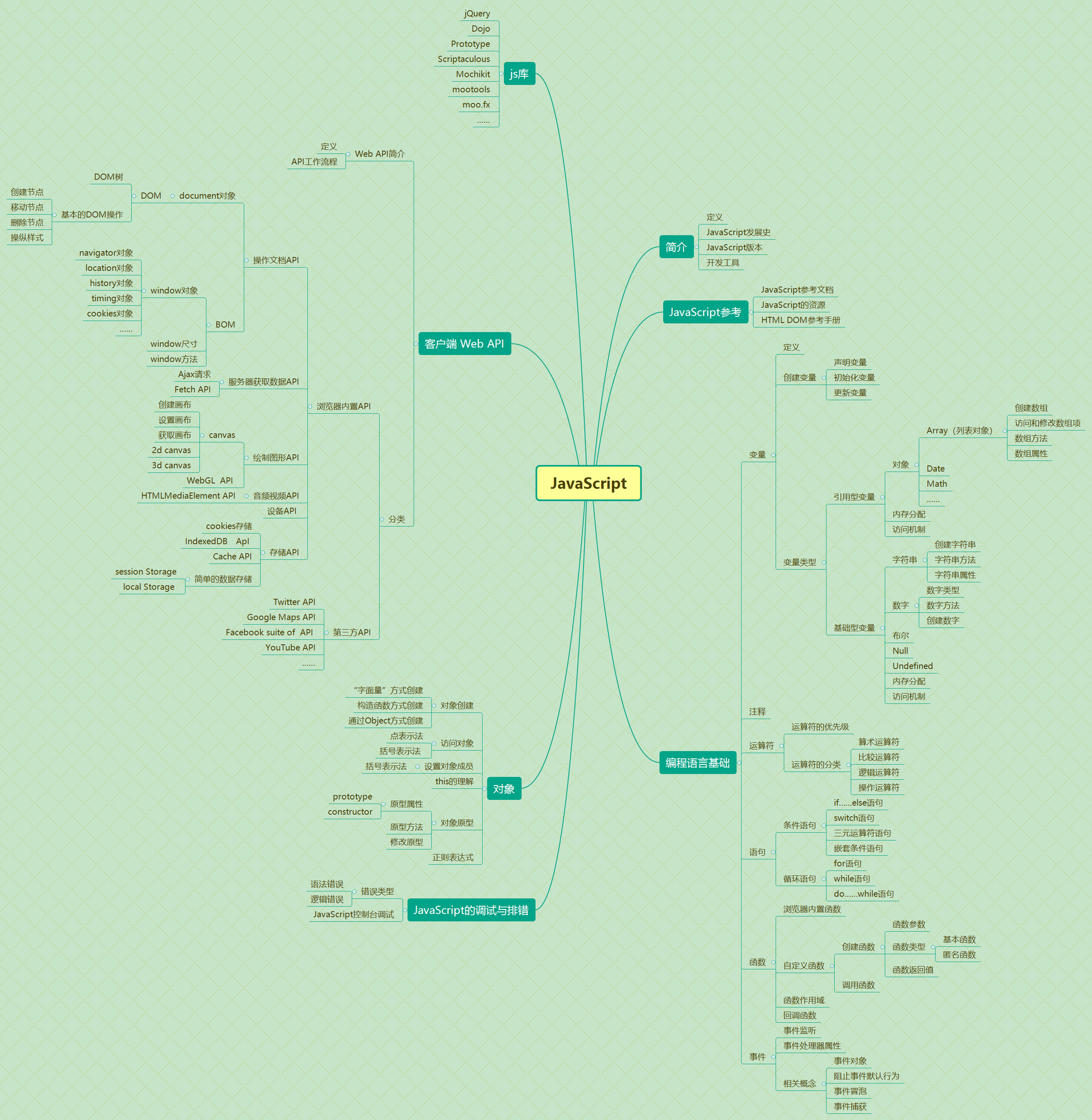
我在学习的时候参考的是www.runoob.com上的在线教程学习的,学习HTML,CSS和JavaScript最佳的方式也就是在浏览器上边学边试边练边复习最好了,但是在学习前端的这些内容的时候,真的很容易陷进庞杂的标签功能中出不来抓不住主线迷失了,所以我采取的策略是先快速的完整的过一遍,能记住多少是多少,然后在实际的使用中遇到哪个再深入进去,基本上也够了。
我在写这篇博客的时候,特意加上了“时光”两个字,这样就不会觉得很没有感情了。这几天在实验室一直戴着耳机,白天一个人6点50起床,独自走到实验室,中午和傍晚的时候,我,张文和蔡学长一起到一食堂走走笑笑去吃饭,讨论着各种稀奇古怪的问题,有的时候王老师会举行会议一起坐在一起讨论着问题,想必这是在大学最好的一种状态了,身边有一起奋斗的好友,前面有NB的老师带路。周围的人都在嚷嚷着考研,考研墙上的院校却袅袅数人,偶尔会看到零星点点的所谓名校的身影。毕竟在鸡场,你不把自己往悬崖推一把又怎么知道自己又是不是一只搏击长空的鹰?每次开会的时候我真的很想珍惜每次能和王老师交流的机会,可是因为水平的限制能提出的问题真的很有限,会提问题也反映了这个人的水平高低,大多数的问题都是可以在Google上找到的,如何找到书上没有网上也找不到的问题,我觉得每次在开会的时候临时想问题还是有些牵强了点,完全可以先每一个星期把遇到的困惑的问题,有可能已经知道了答案但是不确定的拿出来讨论,甚至讨论也可以是知识以外的问题。除此之外,这几天秋高气爽,每次独自走在排球场边的那条路的时候,微风徐来,吹的两边的树林沙沙作响,伴着网易云的音乐,一片片的秋叶在空中飞然后舞徐徐落下,我常常幻觉,你在前面跳着走着,我在后面轻轻的跟着。我放缓脚步,真好。

螃蟹在剥我的壳,笔记本在写我。
漫天的我落在枫叶上雪花上。
而你在想我。
——小雨 《武汉大学第二届“三行诗”大赛第41号作品》
https://www.zhihu.com/question/21983419/answer/65109389
2020.10.11
最后交付的时候不但出了一些意外,而且确实做得不咋滴,没什么技术的难度,被老师怂的没脾气,今天白天又重新一个人把页面重新从头到尾改了一遍,现在的在各种电脑的显示器上显示是正常的了,但是就像我在傍晚和他们讨论的时候说到的,一个是还是最刚开始的问题,JavaScript连接数据库的问题,还有就是数据库的读写分离保证10w访问量的时候如何实现,我目前用事务提交的方式可以保证不会出错,但是不能保证效率。在深入的想我在做的一些事情的更底层的原因的时候,渐渐的也发现自己不知道的或者说概念不清楚的领域还有很多, 比如说JavaScript、HTML和CSS的语法体系我没有建立起来,服务端和客户端再详细一些的区分又是什么?JavaScript的背后的原理又是什么?还有CSS和HTML,浏览器的原理又是什么?当我键入bzt369.com的时候这个过程都发生了什么?数据库如何保证事务安全,各种锁和错误的原因又是什么?如何提高读取和写入的效率并不会出错?都是问题,当然已经解决了部分,却显现出来的都是问题。
参考:
https://developer.mozilla.org/zh-CN/docs/Web/Performance/%E6%B5%8F%E8%A7%88%E5%99%A8%E6%B8%B2%E6%9F%93%E9%A1%B5%E9%9D%A2%E7%9A%84%E5%B7%A5%E4%BD%9C%E5%8E%9F%E7%90%86
https://blog.fundebug.com/2019/01/03/understand-browser-rendering/
https://segmentfault.com/a/1190000014221584