1 项目介绍
基于深度神经网络完成一个极简的物体检测器,实现物体类别和bounding_box的预测。
1.1 数据集

- 数据下载地址/项目地址:https://github.com/rb93dett/CNN_Object_Detection(tiny_vid)
- 每张图像中只有一个物体;大小128*128像素
- 物体类被只有5个:['car', 'bird', 'turtle', 'dog', 'lizard']
- 每个类别包含180张图像
- 标注文件在gt_XX.txt (coordinates are 0-index based): image_index, xmin, ymin, xmax, ymax
1.2 评价指标
定位准确率(IoU>0.5)、分类准确率、分类和定位同时正确率,可视化检测结果
1.3 项目环境
- 硬件配置:MacBook Pro 13’Intel Core i5
- 开发框架:PyCharm + PyTorch
2 项目内容
2.1 实现思路
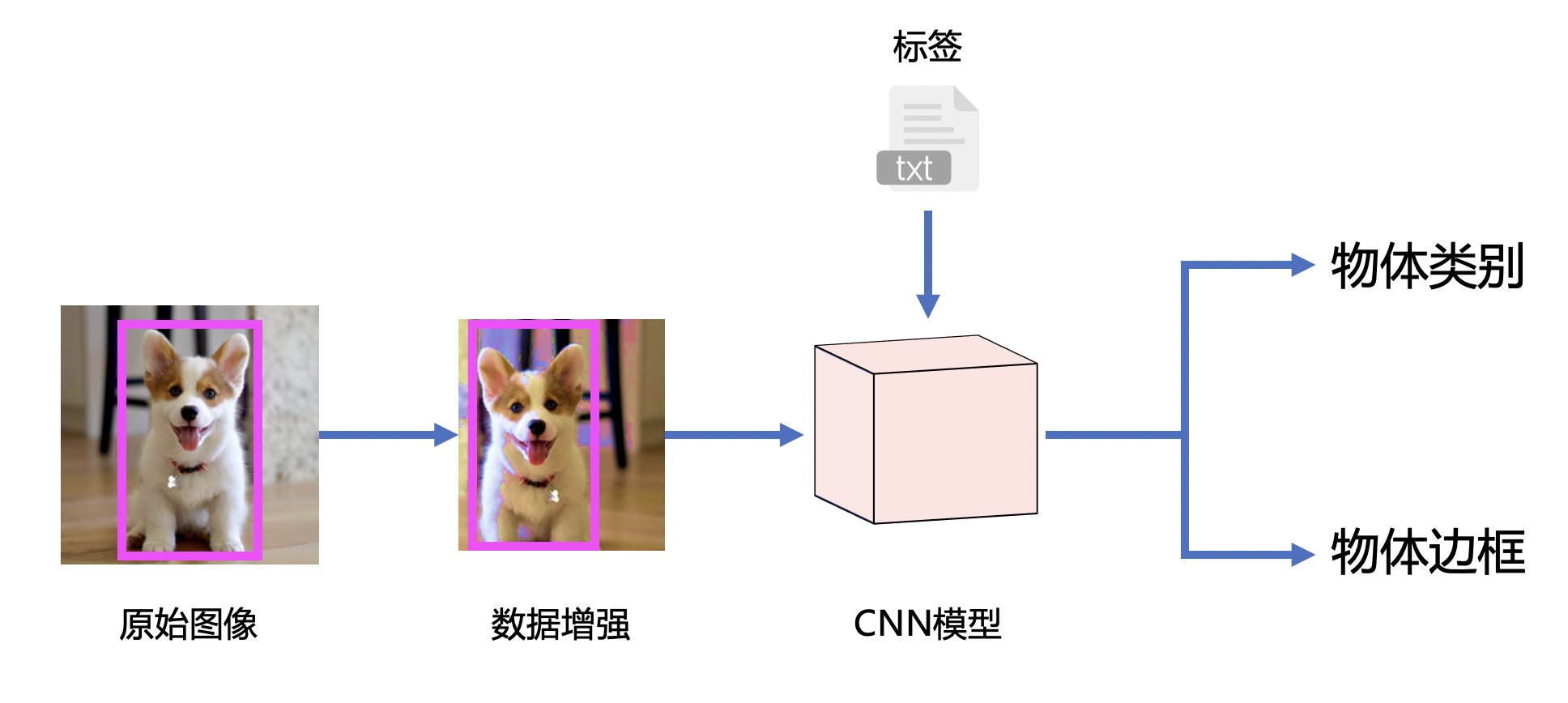
首先是项目的完整思路,其实并不复杂,具体而言,针对原始图像,由于tiny_vid数据集较小,所以为了得到较好的结果,先对数据实现数据增强,从而获得了更多的训练数据,提高模型效果。接下来,通过扩充后的数据集输入搭建的CNN模型,并导入ground truth标签,完成模型的训练,最终就可以向模型输入待分类和定位的图像,输出预测的物体类别和边框。
2.2 数据增强

上图所示是具体的数据增强方法举例,首先针对一张原始图像,可以对它进行随机的distort,改变饱和度,亮度这些颜色参数,然后还以进行图像翻转,同时对bounding box的位置也进行调整,最后是图像裁切,同样根据裁切后的图像设定新的bounding box即可。
2.3 网络架构
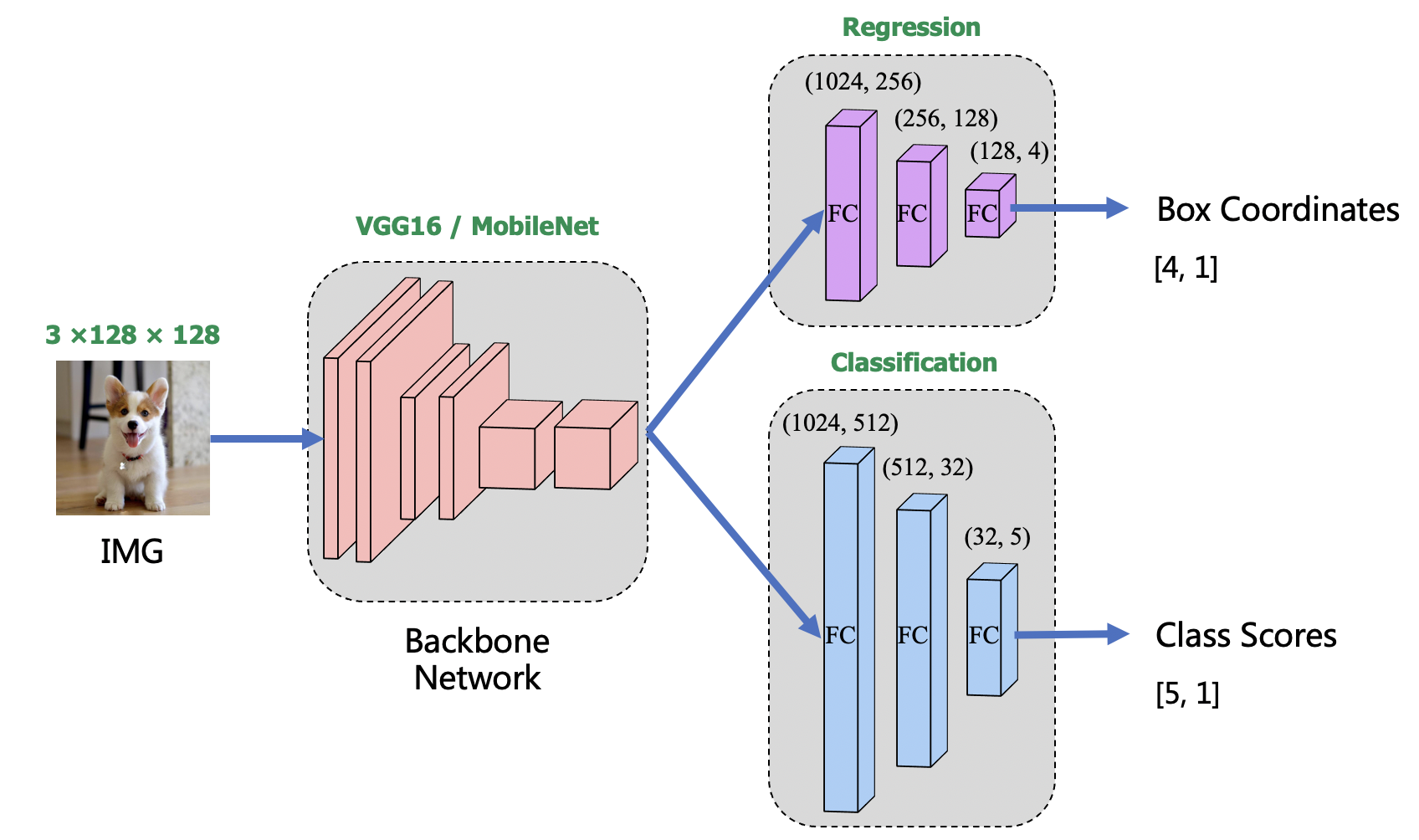
VGG预训练模型下载地址:https://download.pytorch.org/models/vgg16-397923af.pth
接下来是网络的架构,首先将数据输入到backbone网络中完成特征提取,backbone实现了VGG16和MobileNet两个版本,可以在训练之前选择任一一种,然后自己训练网络或者导入预训练的模型参数,然后首先将输出特征送入一个自己定义的回归网络,完成bounding box的预测,另外再使用一个分类模型实现物体识别与分类。具体网络结构如上图。
2.4 项目效果
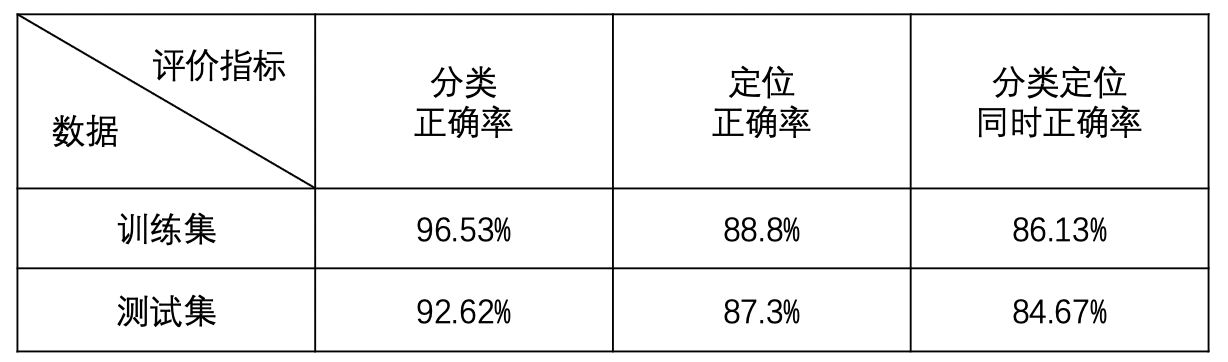
以VGG为backbone,经过多次训练得到的最好效果如下,对于一个简单的物体检测网络而言,在这个数据集上的表现还可以。
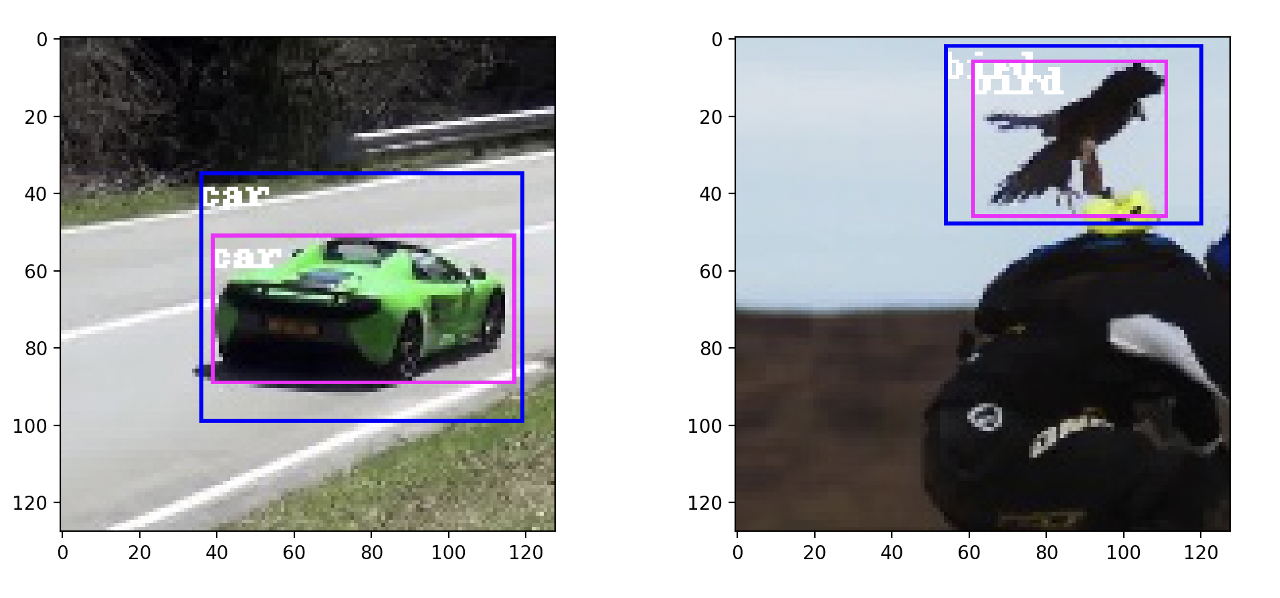
下面是物体识别的可视化结果示例,其中粉色为groud_truth,蓝色为此模型预测的结果。
参考文献:https://github.com/pengzhiliang/object-localization
本项目代码实现参考了上述工作,感谢作者(基本是照搬复现>.<,作者代码思路很清晰),对于基本功是很好的锻炼,通过这篇博文来回顾整个工作,当作复习。希望对大家有所帮助:)