本次集群搭建,使用了三台Linux虚拟机,IP地址分别为 128, 129, 130; Redis版本5.0.4;
Tips: 集群,哨兵 sentinel,分片 cluster
集群作用,配置,主从3种数据同步方式;
哨兵作用,配置,哨兵的leader选举,master的故障发现;
数据分片Cluster作用,配置,hash 槽slot,带来的问题[原子性,数据重定向,新增节点的数据迁移(solt和数据)]
1. Redis集群
集群作用
虽然Redis提供了RDB和AOF两种数据持久化方式, 但当单机硬盘故障时, 仍然会有数据丢失问题,所以在实际生产环境一般会引入集群,避免单点故障。
主从复制
集群的主从复制, master/slave模式。一般情况下主数据库负责读写操作,当有写操作时,会同步给从数据库; 而从数据一般是只读的, 并接受主数据库
同步来的数据。一个主数据库对应多个从数据库。
集群安装配置
-
修改主数据库
redis.conf配置, 找到bind 127.0.0.1改为bind 0.0.0.0, 允许所有ip访问 -
修改从数据库
redis.conf配置, 添加主数据库节点replicaof <masterip> <masterport>e.gslaveof 192.168.1.1 6379 -
分别启动服务
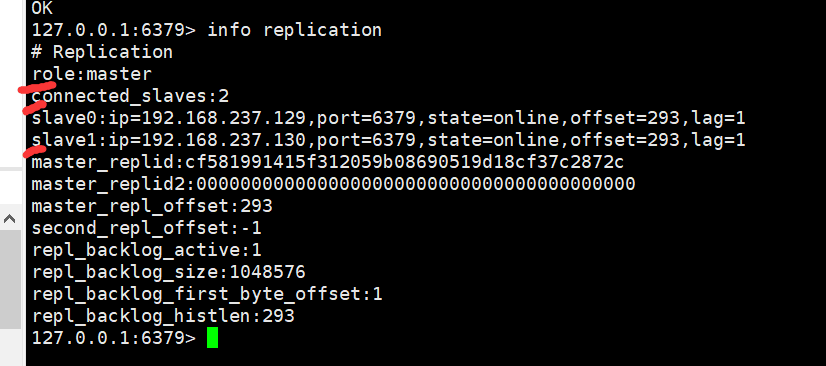
redis-server redis.conf, 客户端redis-cli登入, 执行info replication查看当前redis节点的主从状态;
tip : 可能需要关闭防火墙systemctl stop firewalld
结果如图:
集群数据同步及原理
数据同步直观体现很简单: 当在主数据库执行插入命令, 从数据库也会有这条数据;
同步原理有三种方式: 全量复制, 增量复制, 无磁盘复制;
- 全量复制
一般是在初始化的时候执行, 比如新加入了一个slave节点, 执行流程
a. 从数据库连接主数据库,并发送SYNC
b. 主数据执行BGSAVE, 异步以RDB持久化方式生成当前时点数据快照并记录时间点, 缓存在此期间所执行的命令
c. 从数据库接收到快照并load进行数据恢复
d. 主数据库发送缓存的增量数据, 从数据库接受并执行
在进行单次数据同步时,主数据库接受客户端发出的写指令并执行, 不需要等到所有从数据库数据同步完成才返回给客户端执行成功的信息, 而是先返回
客户端信息,然后将数据同步至从数据库; 两者是异步执行的; 这一特性保证了master的性能不受影响;
slave的数据同步及master返回客户端结果两种操作是异步的, 这一特性保证了master的性能不受影响; 不过当在数据同步期间, master/slave断开了连接,master并不清楚最终消息同步给了多少个slave。不过redis提供了一些配置, 保证当有指定N个salve在M秒内有心跳,master才可以执行写操作,配置如下:
# It is possible for a master to stop accepting writes if there are less than
# N replicas connected, having a lag less or equal than M seconds.
#
# The N replicas need to be in "online" state.
#
# The lag in seconds, that must be <= the specified value, is calculated from
# the last ping received from the replica, that is usually sent every second.
#
# This option does not GUARANTEE that N replicas will accept the write, but
# will limit the window of exposure for lost writes in case not enough replicas
# are available, to the specified number of seconds.
#
# For example to require at least 3 replicas with a lag <= 10 seconds use:
#
# min-replicas-to-write 3
# min-replicas-max-lag 10
本次演示我是三台redis数据库,一master,二slave,所以修改redis.conf配置为
min-replicas-to-write 2
min-replicas-max-lag 10
然后先三台服务都正常启动,master客户端执行hash命令,可以正常执行;之后停掉其中一台slave服务,再执行hash命令,可以看到已经提示不能执行写操作:
127.0.0.1:6379> hset mymap key1 v1
(integer) 1
127.0.0.1:6379> hset mymap key2 v2
(error) NOREPLICAS Not enough good replicas to write.
- 增量复制
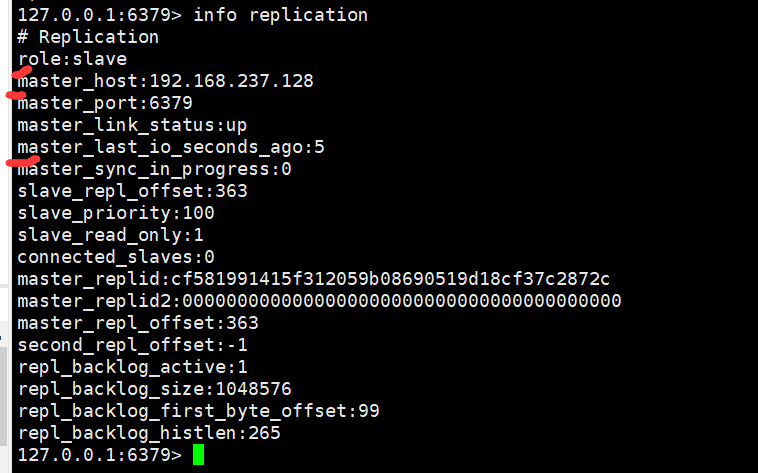
从redis2.8之后,开始支持了主从数据同步的断点续传,如果主从连接断开,下次slave重新连接上之后,会从上次网络断开的地方开始复制,而不需要全量复制;这是因为redis slave会记录当前数据同步的offset位置,这些信息可以在info replication中看到
127.0.0.1:6379> info replication
# Replication
role:slave
master_host:192.168.237.128
master_port:6379
master_link_status:up
master_last_io_seconds_ago:10
master_sync_in_progress:0
slave_repl_offset:976 #offset 记录当前同步的位置
slave_priority:100
slave_read_only:1
connected_slaves:0
master_replid:cb7b2630275333b8cdb6cfaf967fa2a3ee91d7c4
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:976
second_repl_offset:-1
repl_backlog_active:1 #backlog 记录
repl_backlog_size:1048576
repl_backlog_first_byte_offset:151
repl_backlog_histlen:826
master和slave会在内存中创建一个backlog, master和slave都会保存一个replica offset和master id, offset就是保存在backlog中的。如果master和slave的网络断开了,下次连接上之后,slave会让master从上次的replica offset开始进行数据同步。如果没有找到offset,就会执行全量复制。
在slave数据库客户端中执行命令replconf listening-port 6379, sync, 客户端会实时展示master同步来的数据
127.0.0.1:6379> replconf listening-port 6379
OK
127.0.0.1:6379> sync
Entering replica output mode... (press Ctrl-C to quit)
SYNC with master, discarding 236 bytes of bulk transfer...
SYNC done. Logging commands from master.
"PING"
"SELECT","0"
"lpush","lll","1","2","3","4"
"PING"
"PING"
"PING"
- 无磁盘复制
redis2.8之后,提供了无磁盘复制:因为redis的全量复制是基于RDB持久化方式生产快照文件来进行同步,当磁盘读写性能比较低或者压根没有使用RDB方式进行持久化(使用AOF),就会有性能或者使用上的问题。
redis的无磁盘复制配置:
# 1) Disk-backed: The Redis master creates a new process that writes the RDB
# file on disk. Later the file is transferred by the parent
# process to the replicas incrementally.
# 2) Diskless: The Redis master creates a new process that directly writes the
# RDB file to replica sockets, without touching the disk at all.
#
# With disk-backed replication, while the RDB file is generated, more replicas
# can be queued and served with the RDB file as soon as the current child producing# the RDB file finishes its work. With diskless replication instead once
# the transfer starts, new replicas arriving will be queued and a new transfer
# will start when the current one terminates.
#
# When diskless replication is used, the master waits a configurable amount of
# time (in seconds) before starting the transfer in the hope that multiple replicas
# will arrive and the transfer can be parallelized.#
# With slow disks and fast (large bandwidth) networks, diskless replication
# works better.
repl-diskless-sync no
将默认配置改为yes,repl-diskless-sync yes,根据注释可以看出,无磁盘复制是直接创建一个新的进程,在内存中生产RDB快照文件并传输,根本用不到磁盘。
2. Redis哨兵机制
master选举
上面一节提到了redis有master和slave两种节点,当master节点出现单点故障的时候,就需要重新进行leader选举; 这在zk或者别的分布式协调服务也都有体现,redis是通过配置哨兵sentinel来实现的;
哨兵sentinel的作用
哨兵是一个独立的进程,用来监视master和slave的运行情况,当master节点不可用,会发起投票从slave重新选出新的master节点;
但引入sentinel又会出现新的单点故障问题,比如哨兵节点sentinel挂了,当需要选举master时就不可用了,因此哨兵sentinel也需要是集群环境;在一个一主多从的Redis系统中,可以使用多个哨兵来进行监控;此时哨兵集群的作用不仅是监视master和slave的运行情况,还会互相之间监听;哨兵集群需要解决故障发现和master选举的协商问题。
哨兵sentinel之间的相互感知
sentinel之间的相互感知是基于redis频道发布订阅来实现的:
- 首先多个sentinel节点都是监听同一个master的,可以建立联系,然后订阅master的固定频道: sub[channel:sentinel:hello]
- 当有新的sentinel节点加入时,会将自身信息发布到master的固定频道: pub[channel:sentinel:ip+msg]
- 其余sentinel节点订阅了该频道,接收到消息后建立长连接
master的故障发现
sentinel节点会定时向监听的master节点发送心跳来判断master节点是否存活,当master节点没有响应时,当前sentinel节点会认为master节点主观不可用,然后把主观不可用信息发送给其它sentinel节点去确认,当确认的sentinel节点数>quorum,会认为master节点'客观不可用',然后从slave节点中开始进行选举流程;
因为sentinel时集群环境,当多个sentinel节点同时认为master客观不可用,就需要选举出一个sentinel leader来决策那个节点可以当作master,这里用到了Raft算法,和Paxos类似,都是分布式一致性算法,基于投票算法,超过半数的节点通过提议即可;具体可参考: leader选举和分布式一致性问题的动态演示
哨兵sentinel的配置
sentinel的配置说明可查看sentinel.conf文件;
- 首先将
sentinel.conf文件备份,创建新的sentinel.conf配置如下
port 26370 # 哨兵独立进程的端口号
sentinel monitor mymaster 192.168.237.129 6379 1 # 哨兵监听的master节点ip及端口号配置, 当1个sentinel节点主观认为master挂掉了,就变为'客观不可用'
sentinel down-after-milliseconds mymaster 10000 # 和master节点10s内没有心跳响应,就认为master挂了
sentinel failover-timeout mymaster 15000 # 如果15s内master没有活过来,则启动failover,从slave中选举新的leader
- 之后,修改3台redis的
redis.conf参数的配置:
protected-mode no
bind 0.0.0.0
- 最后,确保防火墙是关的,避免不必要麻烦
systemctl stop firewalld - 启动,方式有两种
[root@shen01 redis-5.0.4]# redis-sentinel sentinel.conf
或者
[root@shen01 redis-5.0.4]# redis-server sentinel.conf --sentinel
启动日志
2443:X 18 Apr 2019 21:51:15.191 # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.
2443:X 18 Apr 2019 21:51:15.191 # Sentinel ID is a094ef9a52207bfa060530cab0181bd31a7c190e
2443:X 18 Apr 2019 21:51:15.191 # +monitor master mymaster 192.168.237.129 6379 quorum 1 ## 可以看到启动之后哨兵在监视master 129
## 之后停止129 redis服务,触发哨兵选举
2443:X 18 Apr 2019 21:56:15.203 # +sdown master mymaster 192.168.237.129 6379 # +sdown 哨兵发送心跳,129master无响应,此时哨兵认为主观不可用
2443:X 18 Apr 2019 21:56:15.203 # +odown master mymaster 192.168.237.129 6379 #quorum 1/1 # +odown, 由 '主观不可用' 变为 '客观不可用'
2443:X 18 Apr 2019 21:56:15.203 # +new-epoch 2 # 更换朝代
2443:X 18 Apr 2019 21:56:15.203 # +try-failover master mymaster 192.168.237.129 6379 # +try-failover , 哨兵开始进行故障恢复
2443:X 18 Apr 2019 21:56:15.208 # +vote-for-leader a094ef9a52207bfa060530cab0181bd31a7c190e 2
2443:X 18 Apr 2019 21:56:15.208 # +elected-leader master mymaster 192.168.237.129 6379
2443:X 18 Apr 2019 21:56:15.208 # +failover-state-select-slave master mymaster 192.168.237.129 6379
2443:X 18 Apr 2019 21:56:15.261 # +selected-slave slave 192.168.237.128:6379 192.168.237.128 6379 @ mymaster 192.168.237.129 6379
2443:X 18 Apr 2019 21:56:15.261 * +failover-state-send-slaveof-noone slave 192.168.237.128:6379 192.168.237.128 6379 @ mymaster 192.168.237.129 6379
2443:X 18 Apr 2019 21:56:15.337 * +failover-state-wait-promotion slave 192.168.237.128:6379 192.168.237.128 6379 @ mymaster 192.168.237.129 6379
2443:X 18 Apr 2019 21:56:15.861 # +promoted-slave slave 192.168.237.128:6379 192.168.237.128 6379 @ mymaster 192.168.237.129 6379
2443:X 18 Apr 2019 21:56:15.861 # +failover-state-reconf-slaves master mymaster 192.168.237.129 6379
2443:X 18 Apr 2019 21:56:15.919 * +slave-reconf-sent slave 192.168.237.130:6379 192.168.237.130 6379 @ mymaster 192.168.237.129 6379
2443:X 18 Apr 2019 21:56:16.887 * +slave-reconf-inprog slave 192.168.237.130:6379 192.168.237.130 6379 @ mymaster 192.168.237.129 6379
2443:X 18 Apr 2019 21:56:16.887 * +slave-reconf-done slave 192.168.237.130:6379 192.168.237.130 6379 @ mymaster 192.168.237.129 6379
2443:X 18 Apr 2019 21:56:16.972 # +failover-end master mymaster 192.168.237.129 6379 # +failover-end 哨兵完成故障恢复
2443:X 18 Apr 2019 21:56:16.972 # +switch-master mymaster 192.168.237.129 6379 192.168.237.128 6379 # 切换master由129 变为 128
2443:X 18 Apr 2019 21:56:16.972 * +slave slave 192.168.237.130:6379 192.168.237.130 6379 @ mymaster 192.168.237.128 6379
2443:X 18 Apr 2019 21:56:16.972 * +slave slave 192.168.237.129:6379 192.168.237.129 6379 @ mymaster 192.168.237.128 6379
2443:X 18 Apr 2019 21:56:27.024 # +sdown slave 192.168.237.129:6379 192.168.237.129 6379 @ mymaster 192.168.237.128 6379 # +sdown 虽然129服务已停止,哨兵仍然会将129以slave角色记录为 +sdown, 这样后续129服务重新启用,然可以自动重新连入集群
此时登入128客户端,查看节点信息,也可看出128确实由slave已经变为了master :
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:1
min_slaves_good_slaves:1
slave0:ip=192.168.237.130,port=6379,state=online,offset=49774,lag=0
master_replid:851db0425859c0014156966091a5e56b1021bc02
master_replid2:87cacfc32eb76c082030544063e79001f5fd171e
master_repl_offset:49919
second_repl_offset:22554
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:49919
3. Redis-Cluster
Redis的数据分区
Redis是基于内存的高速缓存数据库,在集群环境中,多个节点的内存可能不一样,但存储的数据大小是一样的,就会形成木桶效应;此时可以基于Redis3.0提供的Cluster,使用 分片 - 哨兵 -集群的方式来优化;
分片Cluster的概念简单可以理解为将全量的数据库数据分块存储,比如现在有6台机器, 1master5slave及哨兵配置来保证高可用,redis数据库中中缓存了大量数据,按之前的1主5从集群配置,每个节点都会存储海量的数据; 现在可以将6台机器分为[1master,1slave][1master,1slave][1master,1slave]设置三个集群分别存储的数据区间为 A:0-5000, B:5001-10000, C:10001-16383; 然后根据一定的算法计算key对应所属区间,分别存储;
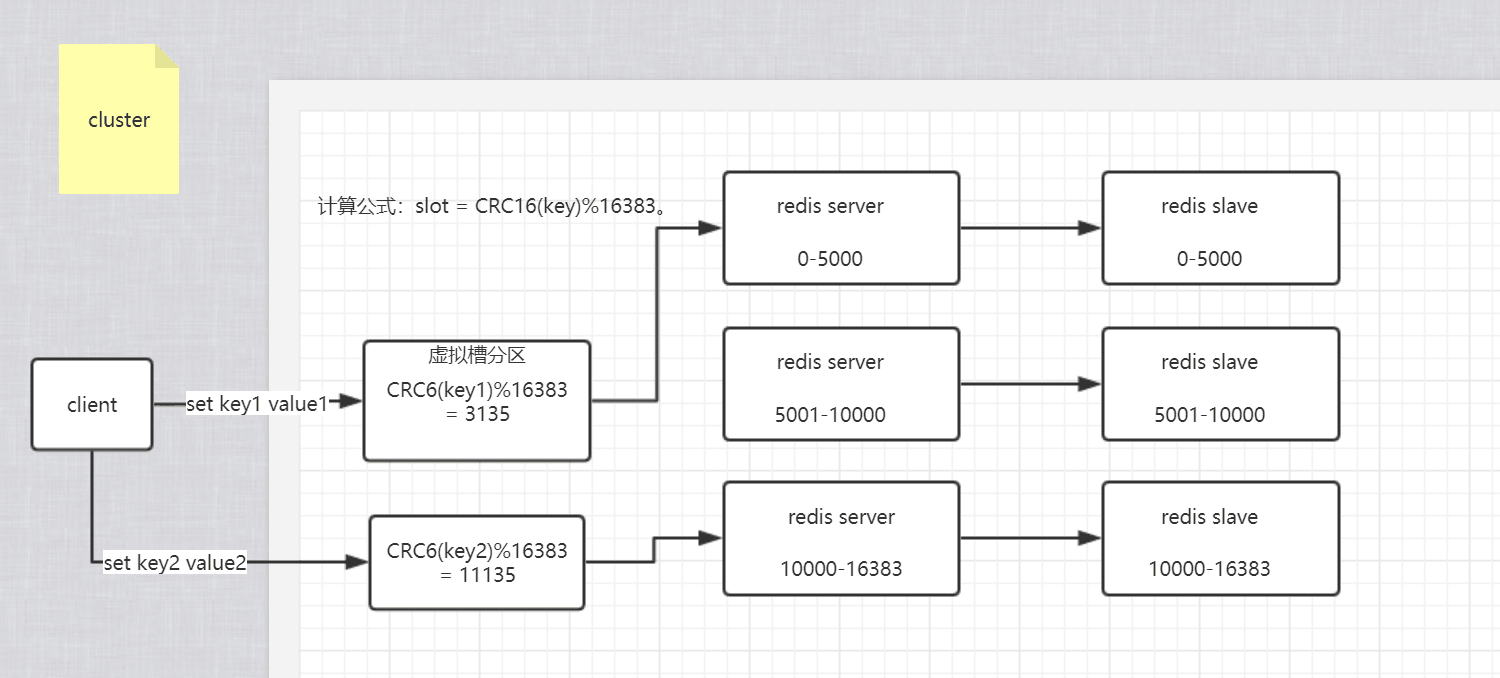
和java中HashMap的底层数据结构[数组+单向链表(红黑树)]很像,key值根据hash算法先得到数组下标,之后存入下标对应链表内部; redis的分片存储算法是: CRC16(key)%16383;虚拟槽分区巧妙地使用了哈希空间,使用分散度良好的哈希函数把所有的数据映射到一个固定范围内的整数集合,整数定义为槽(slot)。比如Redis Cluster槽的范围是0 ~ 16383。槽是集群内数据管理和迁移的基本单位。采用大范围的槽的主要目的是为了方便数据的拆分和集群的扩展,每个节点负责一定数量的槽。
Redis的HashTag
当Redis没有分区前,执行MSET key value [key value …]同时为多个键设值时,可以保证在一个节点上进行;但当启用Redis-Cluster分片时,根据算法得到不同的槽点,并不能保证分布在同一个节点内,也就不能体现原子性操作;在配置了分片要求key尽可能分散在不同机器,又要求某些相似的key存储在同一节点上,此时Redis提供了HashTag的概念:
hashTag在根据key计算所对应的槽点时,会判断key值包不包含{},包含的话不在使用key做hash,而是使用{}内的字符串来做hash计算槽点,要想将相同的一批数据存入同一台机器上,可以将key这样配置,保证计算出的槽点一样,存储在的机器节点自然也就一样了:
e.g127.0.0.1:6379> mset userZhangSanName 张三 userZhangSanAge 16 userZhangSanID 112可以根据具体业务场景修改为127.0.0.1:6379> mset {user}ZhangSanName 张三 {user}ZhangSanAge 16 {user}ZhangSanID 112或者127.0.0.1:6379> mset user{ZhangSan}Name 张三 user{ZhangSan}Age 16 user{ZhangSan}ID 112
Redis的数据节点重定向
在进行分片存储之后,客户端在读数据时,需要的数据可能在当前的节点存储,也可能不在当前节点对应槽点的范围内,此时当前节点会从无中心化的拓扑联系中找出存储相应槽点数据的对应节点,将MOVED重定向请求返回给客户端,客户端重定向到另一节点读取数据:
- A节点组[1masterNslave]负责槽点数据范围 0~5000,B节点组 5001~10000, C节点组 10001~16383;
- 此时客户端向C节点组发起读请求,获取key1的数据,C节点组使用分片存储算法计算key1对应槽位7653,根据Cluster的无中心化节点联系,找出对应7653槽点数据存储在B节点组;然后将B节点组的IP+Port返回给客户端;返回
-MOVED 7653 127.0.0.1:6380 - 客户端收到Moved重定向请求,去对应地址请求数据;
新增节点组的数据迁移
在稳定的Redis Cluster配置中,节点组对应的槽点都是固定的;但是当需要新增节点组进行扩容或者已有节点组宕机的情况,就需要进行数据迁移和16384个槽位的迁移;目前这一过程还处于半自动状态,仍需要人工参与;
**槽位solt迁移 **
新增一个主节点
新增一个节点D,redis cluster的这种做法是从各个节点的前面各拿取一部分slot到D上。大致就会变成这样:
节点A覆盖1365-5460
节点B覆盖6827-10922
节点C覆盖12288-16383
节点D覆盖0-1364,5461-6826,10923-12287
删除一个主节点
先将节点的数据移动到其他节点上,然后才能执行删除
数据迁移
槽的迁移会有三种状态,迁移前,迁移中,迁移后:
以A节点组[0-1364]槽位迁移至D节点组[0-1364]槽位为例:
1. 首先会将A节点组标记为MIGRANTING[表示solt正在迁移],D节点组标记为IMPORTING[表示solt正在迁入]
2. 迁移前: 客户端请求的key还没有迁移出去,仍是正常处理;
3. 迁移后: 原数据槽点在A节点组,迁移后在D节点组,客户端请求发送至A节点组,A判断solt已经迁移至D,回复ASK信息跳转至D节点组请求数据
4. 迁移中: 数据在A节点组,往D节点组迁移了一部分,此时客户端请求发送至D节点组,D节点组判断不是ASK信息跳转,且是Importing状态,则不允许修改,跳转回A节点组执行
后续研究:和Cluster相似的另外一些Redis的分布式解决方案:twemproxy和codis