线程和进程的区别:
进程之间切换非常消耗资源
线程之间切换相对来说节省资源

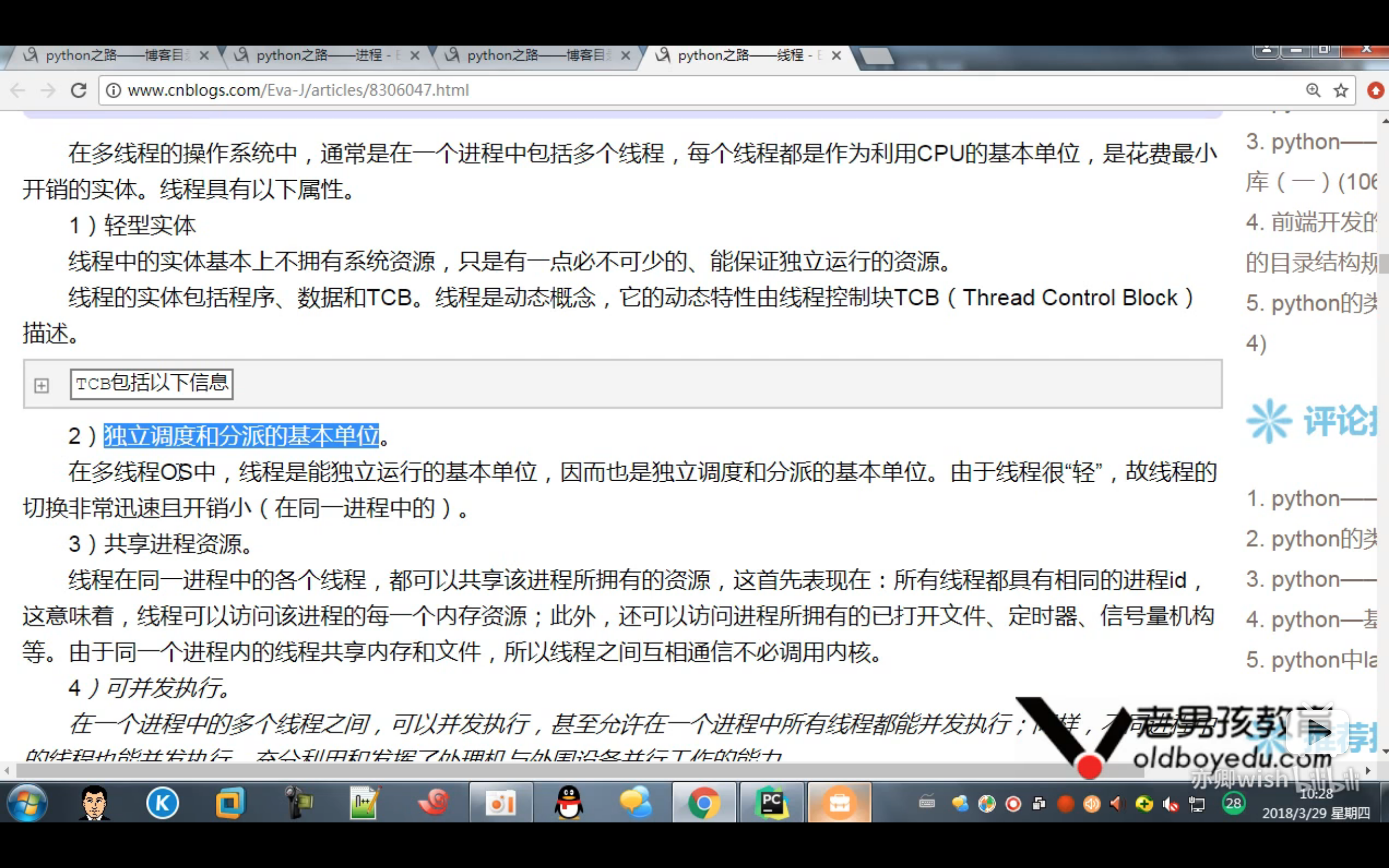
使用线程的场景:
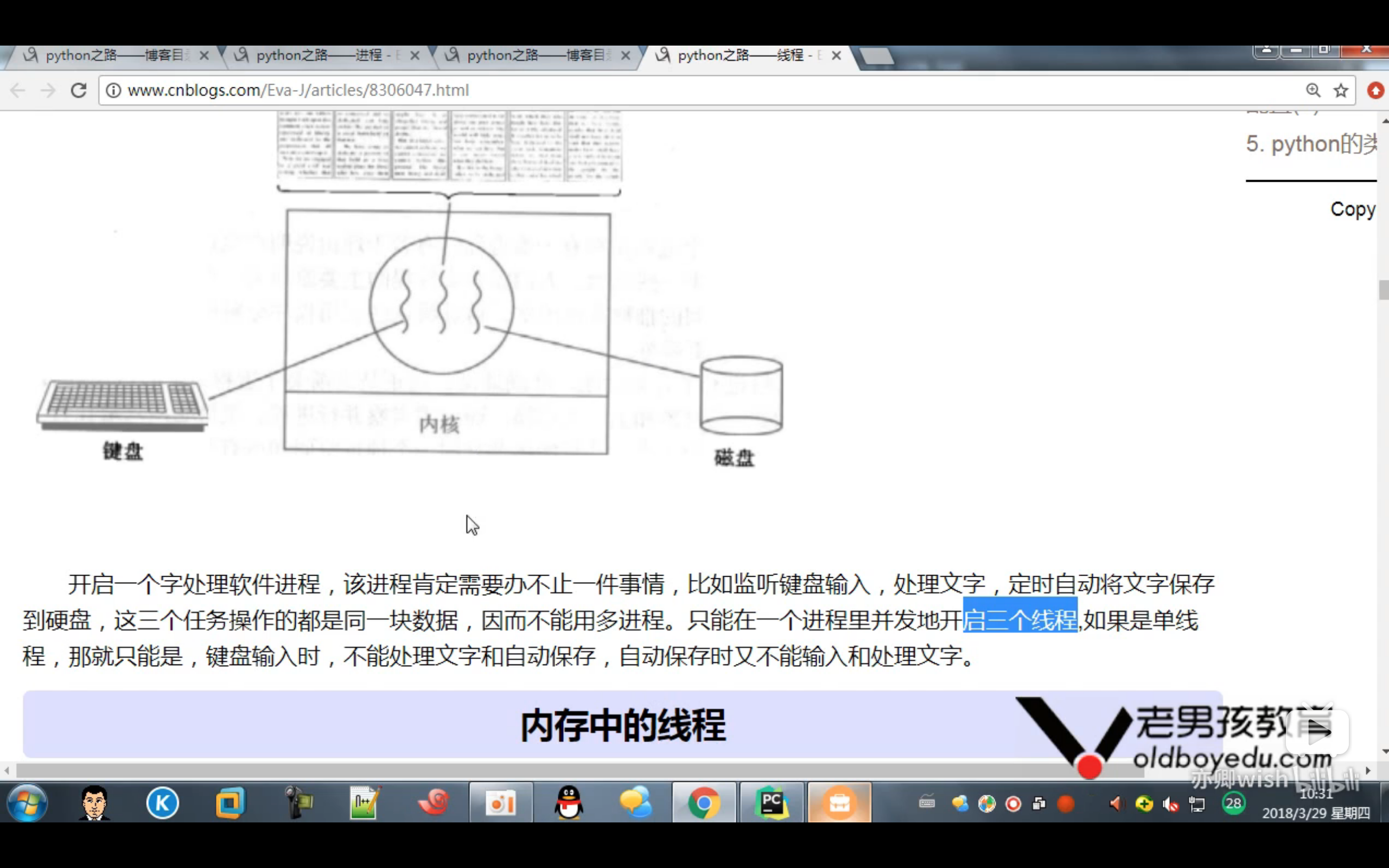
多进程和多线程的数据共享的区别
# 多进程 最后执行打印结果两个100
from multiprocessing import Process
def func1():
global g
g = 0
if __name__ == '__main__':
g = 100
print(g)
p = Process(target=func1)
p.start()
p.join()
print(g)
# 多线程 最后执行打印结果两个第一个100,第二个0
from threading import Thread def func1(): global g g = 0 if __name__ == '__main__': g = 100 print(g) t = Thread(target=func1) t.start() t.join() print(g)



全局解释锁GIL锁住的不是线程共享的数据,而是所有的进程。
虽然有了全局解释锁GIL,但是还不是最安全的,因为比如以下情况:
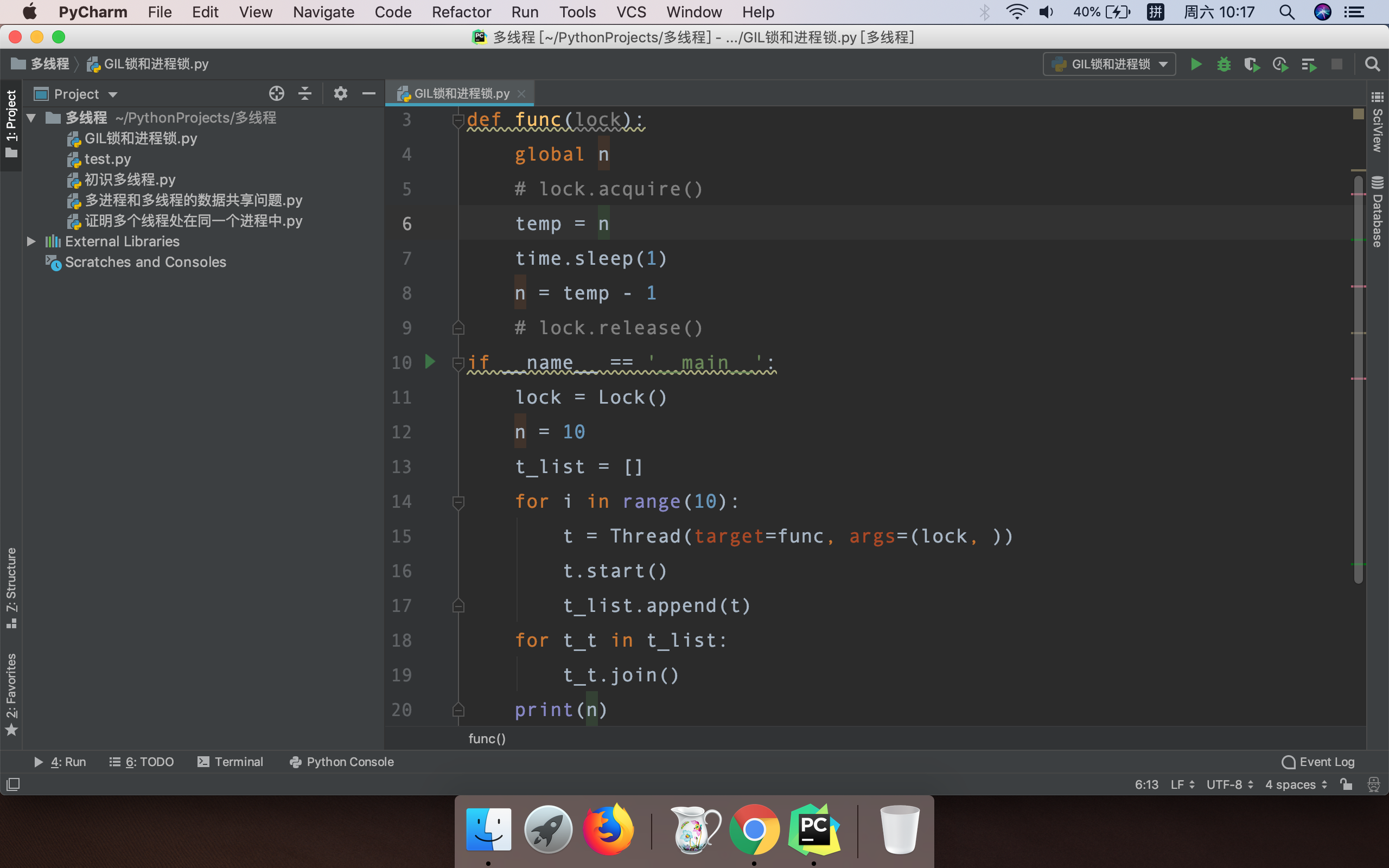
这种情况下我想着线程有了全局解释锁,最后结果应该是0,打印出来结果却是9,因为中间我们人为让程序睡眠了一秒(真实情况下可能由于时间片轮转到了下一个线程),
所以这个时候就需要加锁了。
科学家吃面引出来的死锁问题:
from threading import Thread, Lock
import time
noodle_lock = Lock()
fork_look = Lock()
def eat1(name):
noodle_lock.acquire()
print("{}拿到面了".format(name))
fork_look.acquire()
print("{}拿到叉子了".format(name))
print("{}开始吃面了".format(name))
noodle_lock.release()
fork_look.release()
def eat2(name):
fork_look.acquire()
print("{}拿到叉子了".format(name))
time.sleep(1)
noodle_lock.acquire()
print("{}拿到面了".format(name))
print("{}开始吃面了".format(name))
fork_look.release()
noodle_lock.release()
if __name__ == '__main__':
Thread(target=eat1, args=("alex", )).start()
Thread(target=eat2, args=("egon", )).start()
Thread(target=eat1, args=("nezha", )).start()
Thread(target=eat2, args=("bossjin", )).start()
科学家吃面引出来的递归锁问题:
from threading import Thread, RLock
import time
fork_look = noodle_lock = RLock()
def eat1(name):
noodle_lock.acquire()
print("{}拿到面了".format(name))
fork_look.acquire()
print("{}拿到叉子了".format(name))
print("{}开始吃面了".format(name))
noodle_lock.release()
fork_look.release()
def eat2(name):
fork_look.acquire()
print("{}拿到叉子了".format(name))
time.sleep(1)
noodle_lock.acquire()
print("{}拿到面了".format(name))
print("{}开始吃面了".format(name))
fork_look.release()
noodle_lock.release()
if __name__ == '__main__':
Thread(target=eat1, args=("alex", )).start()
Thread(target=eat2, args=("egon", )).start()
Thread(target=eat1, args=("nezha", )).start()
Thread(target=eat2, args=("bossjin", )).start()
同一个进程或线程中用到两把或两把以上锁的时候,就容易产生死锁现象,这个时候把互斥锁改为递归锁,就能规避这种情况。
RLock内部维护着一个Lock和一个counter变量,counter记录了acquire的次数,从而使得资源可以被多次require。直到一个线程所有的acquire都被release,其他的线程才能获得资源。
进程中的数据本身就不共享,所以很少会用到加锁的情况,而线程则是数据共享的,所以需要加锁
线程中的事件例子:
from threading import Thread, Event
import random
import time
e = Event()
def check_web():
time.sleep(random.randint(3, 6))
e.set()
def conn_db():
count = 1
while count < 4:
e.wait(1)
if e.is_set():
print("连接数据库成功")
break
else:
print("第{}次连接数据库失败".format(count))
count += 1
else:
raise TimeoutError("连接数据库超时")
if __name__ == '__main__':
Thread(target=check_web).start()
Thread(target=conn_db).start()
线程中的定时器
from threading import Thread, Timer
def func():
print("五秒后的线程开启")
if __name__ == '__main__':
Timer(interval=5, function=func).start()
线程池中的队列:
# 多线程中的数据已经是共享的了,为什么还要用队列? # 比如a线程要修改共享的一个列表中的一个元素,刚拿回来数据准备修改,时间片到了b线程, # 这个时候b又去修改这个元素,就会造成数据的不安全,这个时候可以想到应该加锁, # 而队列中就是加好锁了,供我们使用。 import queue q = queue.Queue() #队列,先进先出 q.put(1) q.put(2) print(q.get()) q = queue.LifoQueue() #栈,先进后出 q.put(1) q.put(2) print(q.get()) q = queue.PriorityQueue() #优先级队列 q.put((10, "a")) q.put((1, "b")) q.put((8, "c")) print(q.get())
线程池
# 线程池里面的线程个数最多不要超过cpu个数乘以五
from concurrent.futures import ThreadPoolExecutor
import time
def func(n):
print(n)
time.sleep(1)
return n * n
if __name__ == '__main__':
pool = ThreadPoolExecutor(max_workers=5)
for i in range(1, 21):
p = pool.submit(func, i)
pool.shutdown() #shutdown起到了close和join两个效果,close不让往线程池中扔任务,join等待线程池中的任务执行完毕
print("主线程")