什么是熵值法
熵值法是一种客观赋权方法,借鉴了信息熵思想,它通过计算指标的信息熵,根据指标的相对变化程度对系统整体的影响来决定指标的权重,
即根据各个指标标志值的差异程度来进行赋权,从而得出各个指标相应的权重,相对变化程度大的指标具有较大的权重
熵越大说明系统越混乱,携带的信息越少,权重越小;熵越小说明系统越有序,携带的信息越多,权重越大
步骤:
数据经过无量纲处理之后,计算第 j 个指标中,第 i 个样本指标值的比重:
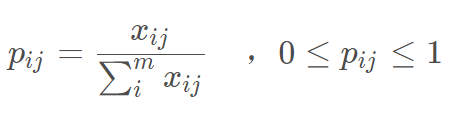
得到数据的比重矩阵:
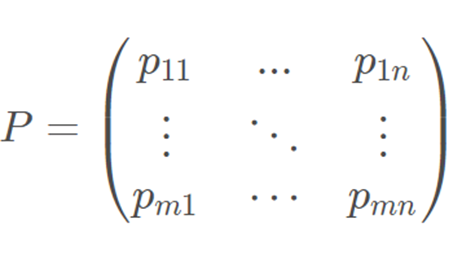
定义第 j 个指标的熵值:


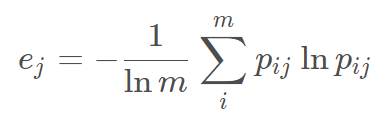
定义第 j 个指标的的差异程度: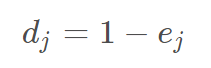
得到权重: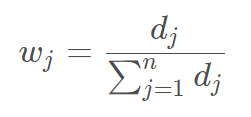
评价结果为: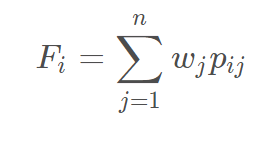
优点
1) 无量纲化方法得当。由于熵权法采用的是归一法,这种方法具有鲁棒性强、单调性好、数据信息恒定和缩放无关性等优点;
2) 熵权法根据客观真实的数据,运用差异驱动原理尝试求得最佳权重,力求全面真实地反映指标数据所包含的信息;
3) 赋权过程具有很高的信度和效度。
缺点
要求指标值一定全部是大于零的。一些极端值在实际运用中不可避免地会出现某些指标的数值为零,某些指标的数据出现异常值等数据大于零是利用熵值法赋权的基本要求,遇到极端值时熵权法可能不再适用。为了保持数据的信息含量、效度和完整性,对于极端值是不能作直接删去处理的,需要对指标数据进行合理有效的变换,如果既要保留原始数据的信息,又使得熵值赋权法适用,那么就必须设法对熵值赋权法进行改进
改进
有公式5

经过简单数学变换,达到了平移的效果,离散程度变小,因此,对熵值赋权法按上式进行修正,修正后数据所含的信息有所损失
为了保持数据原有信息的完整性,尝试给出数据所含信息变化的一个可以接受的合理范围,也就是离散程度变化的范围,并利用这个信息损失容忍度来确定熵值赋权法修正的范围。为了进一步探讨这一问题称 α(0 < α < 1) 为信息损失容忍度,若 α 满足下式,则 u 是关于 n、s、α 的函数

易知,信息损失量容忍度 α、数据之和 s、数据的个数 n 决定着 u 的值。显然,数据 b 1 ,b 2 ,…,b n 之和 s、数据样本的个数 n 是确定的值。
易知,α 和 u两者 为函数关系并容易得到表达式u(n,s,α):

有 s、n 不变,α 越大,u 的取值范围越大
针对熵权法缺陷,通过式(5) 的改进,使得在遇到特殊数据时熵权法继续适用,扩大了熵权法的适用范围。式(5) 的处理过程是将矩阵 C m×n 每行的数据离散程度变小,从而达到了克服熵权法缺陷的目的。为了保持原始数据的完整性,要求原始数据的信息损失尽量较少。又 知,u 是关于 n、s、α 的函数,根据连续函数的可逆性,知 α 是关于 n、s、u 的函数。在实际数据中,n、s 是确定的常量,通过控制 u 的大小,可以使信息损失量在一个合理的范围之内。显然,只要控制α在合理的范围内,将求得的u代入式(5),就可以实现既可以控制数据的信息损失在合理范围之内,又可以克服熵权法缺陷
