#1生成器
def func():
lst = []
for i in range(10000):
lst.append("衣服%s" % i)
return lst
lst = func()
print(lst)
def func():
for i in range(1, 10000):
yield "衣服%s" % i
gen = func()
for i in range(50):
yf = gen.__next__()
for i in range(50):
yf = gen.__next__()
for i in range(50):
yf = gen.__next__()
def func():
lst = []
for i in range(1, 10000):
lst.append("衣服%s" % i)
if i % 50 == 0:
yield lst
lst = [] # 新的装衣服的地方
gen = func()
yf1 = gen.__next__()
print(yf1)
yf2 = gen.__next__()
print(yf2)
yf3 = gen.__next__()
print(yf3)
yf4 = gen.__next__()
yf5 = gen.__next__()
print(yf1)
print(yf2)
print(yf3)
print(yf4)
print(yf5)
# 生成器:本质是迭代器, 写法和迭代器不一样. 用法和迭代器一样
# 生成器函数: 函数中带有yield, 执行生成器函数的时候返回生成器。而不是执行这个函数
def func():
print("你好啊, 我叫赛利亚,")
yield "西岚的武士刀" # return 和yield都可以返回数据
ret = func() # generator ret是一个生成器
print(ret)
s = ret.__next__() # 当执行到__next__()的时候, 函数才真正的开始执行
print("接受到的是", s)
def func():
print("打开手机")
print("打开陌陌")
yield "手机"
print("约妹子")
print("出来喝喝茶")
yield "电脑"
print("我加了一句话")
gen = func() # 生成器
ret1 = gen.__next__()
print(ret1)
ret2 = gen.__next__()
print(ret2)
ret3 = gen.__next__() # 找不到最后一个yield 会报错
print(ret3)
# 特点:
# 1. 节省内存, 几乎不占用内存
# 2. 惰性机制
# 3。只能往前走
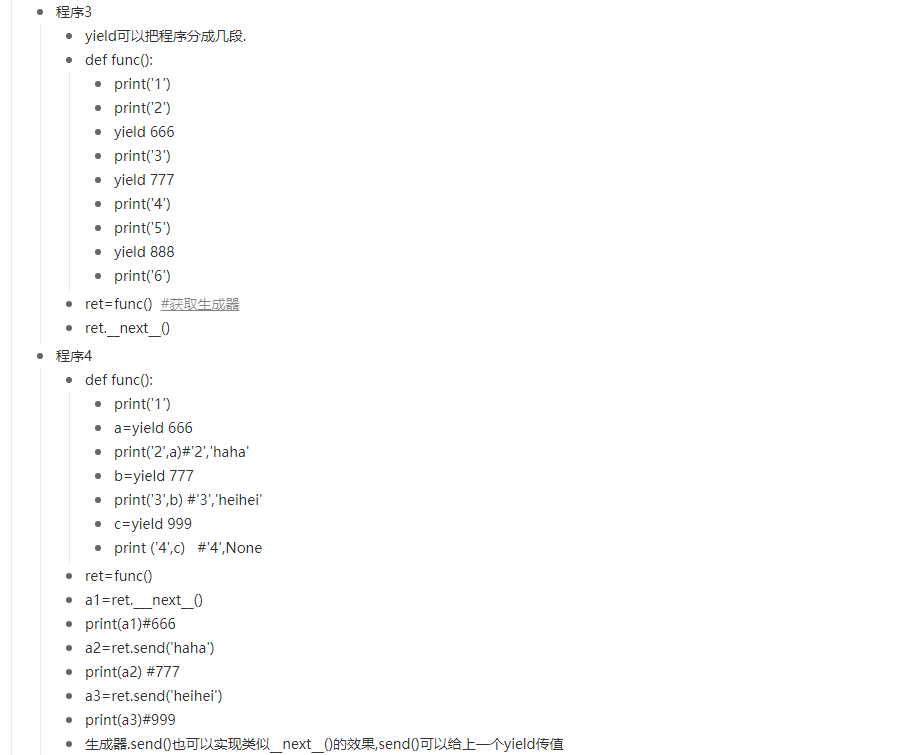
# send() 也可以实现类似__next__()的效果, send()可以给上一个yield传值
def func():
print("韭菜盒子")
a = yield "哇哈哈"
print("肉包子", a)
b = yield "脉动"
print("锅包肉", b)
yield "冰红茶"
gen = func()
ret = gen.send("胡辣汤")
print(ret)
ret = gen.send("刘伟") # 给上一个yield传值
print(ret)
ret = gen.send("刘德华") # 给上一个yield传值
print(ret)
# send()和__next__()的区别
# send不可以用在开头
# send可以给上一个yield传值, 不能给最后一个yield传值
def func():
yield "麻花藤"
yield "李彦宏"
yield "马云"
yield "刘强东"
gen = func()
print(gen.__next__()) # 麻花藤
print(gen.__next__()) # 麻花藤
print(gen.__next__()) # 麻花藤
print(gen.__next__()) # 麻花藤
# 生成器的本质是迭代器.
print("__iter__" in dir(gen))
# 生成器可以直接使用for循环
for el in gen:
print(el)
lst = list(gen) # 把生成器中的每一个数据拿出来组合成一个列表
print(lst)
#2 推导式
# 列表推导式 : [结果 for循环 if筛选]
lst = ["python%s" % i for i in range(1, 17)]
print(lst)
# 创建列表: [1,3,5,7,9..99]
lst = [i for i in range(1, 100, 2)]
print(lst)
lst = [i for i in range(1,100) if i % 2 == 1]
print(lst)
# 获取1-100内能被3整除的数
lst = [i for i in range(1, 101) if i % 3 == 0]
# # 100以内能被3整除的数的平⽅
lst = [i*i for i in range(1, 101) if i % 3 == 0]
# 寻找名字中带有两个e的⼈的名字
names = [['Tom', 'Billy', 'Jefferson', 'Andrew', 'Wesley', 'Steven','Joe'],
['Alice', 'Jill', 'Ana', 'Wendy', 'Jennifer', 'Sherry', 'Eva']]
lst = [name for first in names for name in first if name.count("e") >= 2 ]
print(lst)
# 字典推导式, {key: value for循环 if 筛选}
dic = {"张无忌":"九阳神功", "乔峰":"降龙十八掌", "楚留香":"帅"}
d = {dic[k]: k for k in dic}
print(d)
#3 生成器表达式
# 元组没有推导式
# [结果 for if]
# {key for if}
# {key:value for if}
# (结果 for if) # 生成器表达式, 拿到的是生成器
# 可以使用生成器表达式直接创建生成器
gen = (i for i in range(10)) # generator
print(gen.__next__())
print(gen.__next__())
print(gen.__next__())
print(gen.__next__())
print(gen.__next__())
print(gen.__next__())
print(gen.__next__())
print(gen.__next__())
print(gen.__next__())
print(gen.__next__())
print(gen.__next__())
# 生成器表达式: 记录一下代码。 然后每次需要的时候去生成器中执行一次这个代码
# 列表推导式: 一次性把所有的数据创建出来, 容易产生内存浪费
# 特性:
# 1. 节省内存
# 2. 惰性机制
# 3.只能向前。
# 生成器函数
def func():
print(111)
yield 222
g = func() # 生成器
g1 = (i for i in g) # 生成器
g2 = (i for i in g1) # 生成器
print(list(g1)) # 222
print(list(g2))
print(list(g)) # 才会开始真正的取数据
# 计算两个数的和
def add(a, b):
return a + b
# 生成器函数, 0-3
def test():
for r_i in range(4):
yield r_i
# 获取到生成器
g = test() # 惰性机制
for n in [2, 10]:
g = (add(n, i) for i in g) # 循环的内部也是一个生成器
# __next__()
# list()
print(list(g)) # 刚开始拿数据
# 生成器记录的是代码
lst1 = ["东北", "陕西", "山西", "开封", "杭州", "广东", "济南"]
lst2 = ['大拉皮', "油泼面", "老陈醋", "灌汤包", "西湖鲤鱼", "早茶", "胶东一锅鲜"]
dic = {lst1[i]:lst2[i] for i in range(len(lst1))}
print(dic)
# 集合推导式 无序不重复 可哈希
# {key for if}
lst = ["周杰伦","周伯通","周润发","周伯通","周笔畅","周伯通","周星驰","周伯通"]
s = {el for el in lst}
print(s)