引言:之前就提到过常见的反爬虫机制就有IP封禁,就是当你访问频率超过一个阀值服务器就会拒绝服务。这时网页就会提示“您的IP访问频率太高”,或者跳出一个验证码让我们输入,之后才能解封,但是一会后又会出现这种情况。这时我们就可以通过代理IP来进行请求就可以完美解决这个问题。但是通常各大网站上提供的代理IP可用率都不高,我们就需要搭建自己的IP池来反复筛选剔除不可用的IP。除了这种搭建IP池的方式也还有付费代理或者ADSL混淆拨号。但是成本太高这里就介绍第一种方式。
首先先介绍一下代理设置的方法:
测试网站是:http://httpbin.org/get,我们可以根据他返回的origin字段判断代理是否设置成功。在此之前你需要在代理IP网站上找一个可用的代理IP用来测试。
import requests proxy = ‘198.50.163.192' proxies = { 'http':'http://'+ip, 'https':'https://'+ip } url = 'http://www.httpbin.org/get' try: response = requests.get(url=url,proxies=proxies) print(response.text) except requests.exceptions.ConnectionError as e: print('Error',e.args)
结果如下:
{ "args": {}, "headers": { "Accept": "*/*", "Accept-Encoding": "gzip, deflate", "Cache-Control": "max-age=259200", "Host": "www.httpbin.org", "User-Agent": "python-requests/2.25.1", "X-Amzn-Trace-Id": "Root=1-607afb83-4447c22c3cf70d892063860f" }, "origin": "198.50.163.192", "url": "http://www.httpbin.org/get" }
可见origin字端对应的值就是刚刚我们设置的IP,但是这样手动设置明显是不好的,如果我们能动态获取IP就完美了。
这里我动态实现了一个IP池用来获取各大代理IP网站上的免费代理IP并对其自动进行测试筛选。
准备工作:确保成功安装Redis数据库并启动服务,另外还需要安装aiohttp,redis-py,pyquery,Flask库
这里提供一个超好用的开源IP代理池ProxyPool
ProxyPool下载地址:
https://github.com/Python3WebSpider/ProxyPool.git
1.ProxyPool的使用:
首先使用 git clone 将源代码拉到你本地,
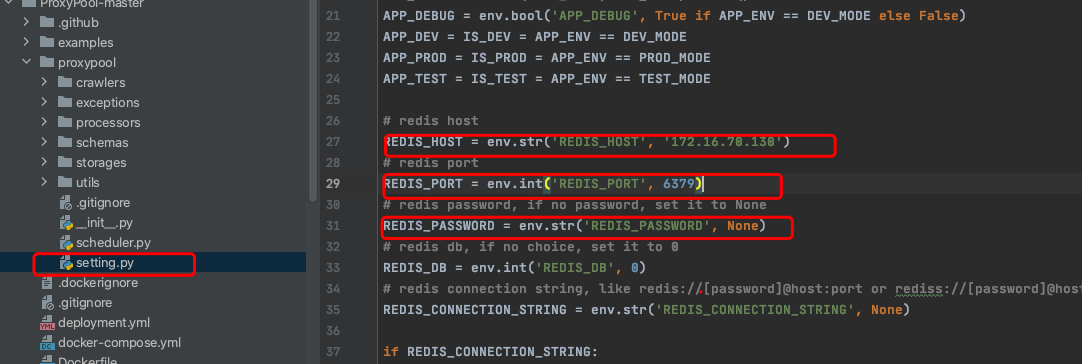
2.进入proxypool目录,修改settings.py文件,PASSWORD为Redis密码,如果为空,则设置为None。(新装的redis一般没有密码。),如果不是运行在LInux系统上就需要设置REDIS_HOST也就是你的主机IP地址。端口好默认为6379。
3.开启redis服务,并关闭防火墙(如果直接运行到本地可以无视)
4.直接运行run.py 不能退出,一直让它运行!!!
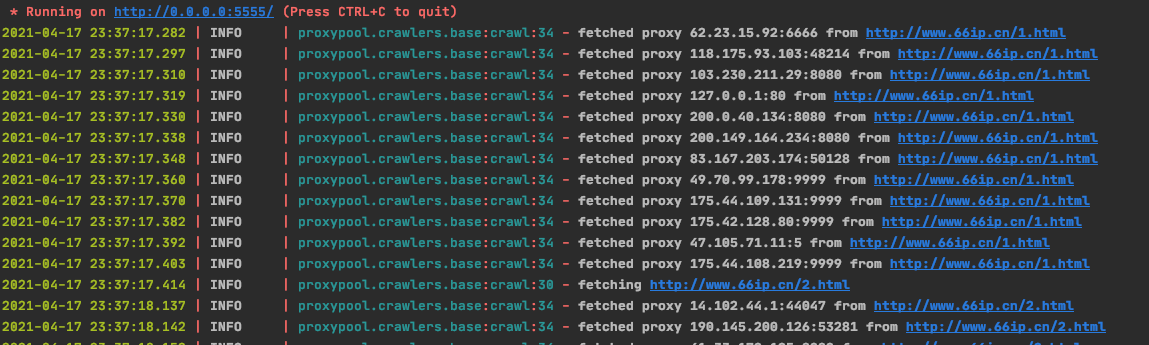
5.浏览器输入http://0.0.0.0:5555/random即可随机获取一个可用的代理IP 或者(http://localhost:5555/random)

下面我们用代理IP池进行测试:
import requests PRO_POOL_URL = 'http://localhost:5555/random' url = 'http://httpbin.org/get' def get_proxy(): #定义一个获取代理IP的函数 try: response = requests.get(url=PRO_POOL_URL) if response.status_code == 200: return response.text except ConnectionError: return None proxy = get_proxy() print(proxy) #输出一下所获得的代理IP proxies_http = { 'http':'http://'+proxy, } proxies_https={ 'https':'https://'+proxy, } if url.split(':')[0] == 'http': response = requests.get(url=url,proxies=proxies_http).text print(response) else: response = requests.get(url=url,proxies=proxies_https).text print(response)
结果如下:
144.217.101.245:3129 { "args": {}, "headers": { "Accept": "*/*", "Accept-Encoding": "gzip, deflate", "Cache-Control": "max-age=259200", "Host": "httpbin.org", "User-Agent": "python-requests/2.25.1", "X-Amzn-Trace-Id": "Root=1-607b0182-5da37f946cf8ee9021f389ee" }, "origin": "144.217.101.245", ### "url": "http://httpbin.org/get" }
origin字端返回的是从http://localhost:5555/random随机获取的IP证明伪装IP成功了,这时再对网站进行高频爬取就不会被封IP了。IP封禁就解决了。但是如果需要更高效的爬取还是用付费代理或者ADSL拨号吧,花钱的毕竟更稳定更快。