一.昨天内容回顾
- 索引设计依据
与数据表有关系的sql语句都统计出来
where order by or等等条件的字段适当做索引
原则:
频率高的sql语句
执行时间长的sql语句
业务逻辑重要的sql语句
什么样子字段不适合做索引?
内容比较单调的字段不适合做索引
- 前缀索引
一个字段只取前边的几位内容做索引
好处:索引空间比较少、运行速度快
前n位做索引,前n位要具备唯一标识当前记录的特点
- 全文索引
Mysql5.5 只MYisam存储引擎可以实现
Mysql5.6 Myisam和Innodb存储引擎都可以实现
fulltext index 索引名称 (字段,字段)
select * from 表名 where 字段 like '%内容%' or 字段 like '%内容%';
select * from 表名 match(字段,字段) against("内容1,内容2");
match(字段,字段) against("内容1,内容2")
- 索引结构
Mysql的索引结构是B+Tree结构
索引就是数据结构(自然有算法),算法可以保证数据非常快速被找到
非聚集(Myisam)
叶子节点的关键字(索引字段内容) 与 记录的物理地址对应
聚集(Innodb)
主(键)索引:叶子节点的关键字 与 整条记录对应
非主(唯一/普通/全文)索引:叶子节点的关键字 与 主键关键字对应
- 查询缓存
开启缓存,开辟缓存空间(64MB)
缓存失效:表 或 数据 内容改变
不使用缓存:sql语句有变化的信息,例如当前时间、随机数
同一个业务逻辑的多个sql语句,有不同结构(空格变化、大小写变哈)的变化,每个样子的sql语句会分别设置缓存
- 分区、分表设计
分区表算法(Mysql):key hash range list
(php代码不会发生变化)
分区增加或减少:
减少:hash/range/list类型算法会丢失对应的数据
- 垂直分表
把一个数据表的多个字段进行拆分,分别分配到不同的数据表中
涉及的算法是php层面的
- 架构设计
主从模式(读写分离、一主多从)
主服务器负责"写"数据,从服务器负责"读"数据
"主" 会 自动 给"从" 同步数据(mysql本身技术)
通过"负载均衡"可以平均地从 从服务器 获得数据
- 慢查询日志设置
show variables like 'slow_query_log%';
开启慢查询日志开关
设置时间阀值
二.Mysql优化
1. 大量写入记录信息
保证数据非常快地写入到数据库中
insert into 表名 values (),(),(),();
以上一个insert语句可以同时写入多条记录信息,但是不要写入太多
避免意外情况发生。
可以一次少写一些,例如每次写入1000条,这样100万的记录信息,执行1000次insert语句就可以了。
分批分时间把数据写入到数据库中。
以上设计写入大量数据的方法损耗的时间:
写入数据(1000条)----->为1000条数据维护索引
写入数据(1000条)----->为第2个1000条数据维护索引
......
写入数据(1000条)----->为第1000个1000条数据维护索引
以上设计写入100万条记录信息,时间主要都被"维护索引"给占据了
如果做优化:就可以减少索引的维护,达到整体运行时间变少。
(索引维护不需要做1000次,就想做一次)
解决:
先把索引给停掉,专门把数据先写入到数据库中,最后在一次性维护索引
1.1 Myisam数据表
- 数据表中已经存在数据(索引已经存在一部分)
alter table 表名 disable keys;
大量写入数据
alter table 表名 enable keys; //最后统一维护索引
- 数据表中没有数据(索引内部没有东西)
alter table 表名 drop primary key ,drop index 索引名称(唯一/普通/全文);
大量写入数据
alter table 表名 add primary key(id),(唯一/全文)index 索引名 (字段);
1.2 Innodb数据表
该存储引擎支持"事务"
该特性使得我们可以一次性写入大量sql语句
具体操作:
start transaction;
大量数据写入(100万条记录信息 insert被执行1000次)
事务内部执行的insert的时候,数据还没有写入到数据库
只有数据真实写入到数据库才会执行"索引"维护
commit;
commit执行完毕后最后会自动维护一次"索引";
2. 单表、多表查询
数据库操作有的时候设计到 连表查询、子查询操作。
复合查询一般要涉及到多个数据表,
多个数据表一起做查询好处:sql语句逻辑清晰、简单
其中不妥当的地方是:消耗资源比较多、时间长
不利于数据表的并发处理,因为需要长时间锁住多个表
例如:
查询每个品牌下商品的总数量(Goods/Brand)
Goods:id name bd_id
Brand: bd_id name
select b.bd_id,b.name,count(g.*) from Brand b join Goods g on b.bd_id=g.bd_id group by b.bd_id;
以上sql语句总运行时间是5s
但是业务要求是数据库的并发性要高,就需要把"多个查询" 变为 "单表查询"
步骤:
① select bd_id,count(*) from Goods group by bd_id; //查询每个品牌的商品数量 //3s
② select bd_id,name from Brand; //3s
③ 在php通过逻辑代码整合① 和 ② //1s
3. limit使用
数据分页使用limit;
limit 偏移量,长度(每页条数);
偏移量:(当前页码-1)*每页条数
分页实现:
每页获得10条信息:
limit 0,10;
limit 10,10;
limit 20,10;
limit 30,10;
limit 990,10; //第100页
limit 9990,10; //第1000页
limit 99990,10; //第10000页
limit 999990,10; //第100000页
limit 1499990,10; //第150000页
limit 1500000,10; //第150001页
select * from emp limit 1500000,10; //慢 1秒多时间
select * from emp where empno>1600001 limit 10; //快 0.00秒级

数据表目前有empno主键索引:
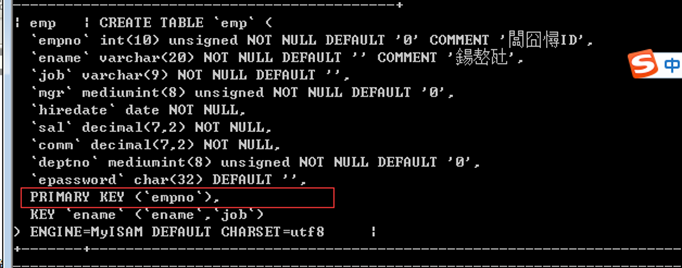
limit 偏移量,长度;运行时间较长:

单纯运行limit 运行时间比较长,内部没有使用索引,翻页效果 之前页码的信息给获得出来,但是"越"过去,因此比较浪费时间
现在对获得相同页码信息的sql语句进行优化
由单纯limit变为 where 和 limit的组合:
执行速度明显加快,因为其有使用where条件字段的索引

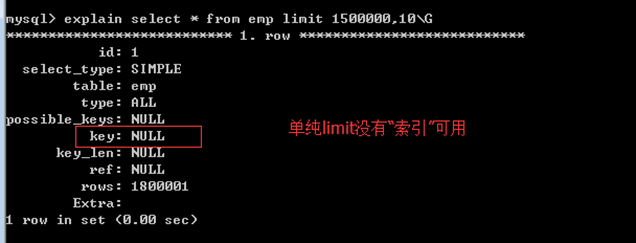

4. order by null
强制不排序
有的sql语句在执行的时候,本身默认会有排序效果
但是有的时候我们的业务不需要排序效果,就可以进行强制限制,进而"节省默认排序"带来的资源消耗。
group by 字段;
获得的结果在默认情况下会根据"分组字段"进行排序:

order by null强制不排序,节省对应资源: