1.使用struct和class定义类以及类外的继承有什么区别?
1)使用struct定义结构体它的默认数据成员类型是public,而class关键字定义类时默认成员时private.
2) 在使用继承的时候,struct定义类时它的派生类的默认具有public继承,而class的派生类默认是private继承。
2.派生类和虚函数概述?
1)基类中定义虚函数的目的是想在派生类中重新定义函数的新功能,如果派生类中没有重新对虚函数定义,那么使用派生类对象调用这个虚函数的时候,默认使用基类的虚函数。
2)派生类中定义的函数必须和基类中的函数定义完全相同。
3)基类中定义了虚函数,那么在派生类中同样也是。
3.虚函数和纯虚函数的区别?
1)虚函数和纯虚函数都使用关键字virtual。如果在基类中定义一个纯虚函数,那么这个基类是一个抽象基类,也称为虚基类,不能定义对象,只能被继承。当被继承时,必须在派生类中重新定义纯虚函数。
class Animal { public: virtual void getColol() = 0; // 纯虚函数 }; class Animal { public: virtual void getColor(); // 虚函数 };
4.深拷贝和浅拷贝的区别
举个栗子~:
浅拷贝:
char p[] = "hello"; char *p1; p1 = p;
深拷贝:
char p[] = "hello"; char *p1 = new char[]; p1 = p;
解释:
浅拷贝就是拷贝之后两个指针指向同一个地址,只是对指针的拷贝。
深拷贝是经过拷贝后,两个指针指向两个地址,且拷贝其内容。
2)浅拷贝可能出现的问题
a. 因为两个指针指向同一个地址,所以在一个指针改变其内容后,另一个也可能会发生改变。
b.浅拷贝只是拷贝了指针而已,使得两个指针指向同一个地址,所以当对象结束其生命期调用析构函数时,可能会对同一个资源释放两次,造成程序奔溃。
4.STL中vector实现原理,是1.5倍还是两倍?各有什么优缺点?
vector是顺序容器,他是一个动态数组。
1.5倍优势:可以重用之前分配但已经释放的内存。
2倍优势: 每次申请的内存都不可以重用
5.STL中map,set的实现原理。
map是一个关联容器,它是以键值对的形式存储的。它的底层是用红黑树实现。平均查找复杂度是O(logn)
set也是一个关联容器,它也是以键值对的形式存储,但键值对都相同。底层也是以红黑树实现。平均查找复杂度O(logn)。
6. C++特点是什么,多态实现机制?多态作用?两个必须条件?
C++中多态机制主要体现在两个方面,一个是函数的重载,一个是接口的重写。接口多态指的是“一个接口的多种形态”。每一个对象内部都有一个虚表指针,该虚表指针被初始化为本类的虚表。所以在程序中,不管对象类型如何转换,但该对象内部的虚表指针始终不变,才能实现动态的对象函数调用,这是c++多态的实现原理。
多态的基础是继承,需要虚函数的支持。子类继承父类的大部分资源,不能继承的有构造函数,析构函数,拷贝构造函数,operator = ,友元函数等。
作用:
1.隐藏实现细节,代码能够模块化。 2.实现接口重用:为了类在继承和派生过程中正确调用。
两个必要条件:
1.虚函数 2.一个基类的指针或者引用指向子类对象。
7.多重继承有什么问题?怎样消除多重继承中的二义性?
1)增加程序的复杂性,使程序的编写和维护都比较困难,容易出错;
2)继承类和基类的同名函数产生了二义性,同名函数不知道调用基类还是继承类,c++ 中用虚函数解决这个问题。
3)继承过程中可能会继承一些不必要的数据,可能会产生数据很长。
可以使用成员限定符和虚函数解决多重继承中的函数的二义性问题。
8.什么叫动态关联,什么叫静态关联?
多态中,程序在编译时确定程序的执行动作叫做静态关联,在运行时才能确定叫做动态关联。
9.那些库函数属于高危函数?为什么?
strcpy赋值到目标区间可能会造成缓冲区溢出!
10.求两个数的乘积和商数,用宏定义来实现
#define Chen(a,b) ((a) * (b)) #define Divide(a,b) ((a) / (b))
11.枚举和#define宏的区别
1)用#define定义的宏在预编译的时候进行简单替换。枚举在编译的时候确定其值。
2)可以调试枚举常量,但不可以调试宏常量。
3)枚举可以一次定义大量的常量,而宏只能定义一个。
12.介绍下函数的重载:
重载是对不同类型的函数进行调用而使用相同的函数名。重载至少要在参数类型,参数个数,参数顺序中有一个不同。
13.派生新类要经过三个步骤
1)继承基类成员 2)改造基类成员 3)添加新成员
14.面向对象的三个基本性质?并简单描述
1)封装 : 将客观事物抽象成类,每个类对自身的数据和方法进行封装。
2)继承
3)多态 允许一个基类的指针或引用指向一个派生类的对象。
15.多态性体现都有那些?动态绑定怎么实现?
多态性是一个接口,多种实现,是面向对象的核心。
动态绑定是指在编译器在编译阶段不知道调用那个方法。
编译时多态性:通过重载函数实现。
运行时多态性:通过虚函数实现,结合动态绑定。
16.动态联编和静态联编
静态联编是指程序在编译链接时就知道程序的执行顺序
动态联编是指在程序运行时才知道程序调用函数的顺序。
17.为什么析构函数要定义成虚函数?
如果不将析构函数定义成虚函数,那么在释放内存的时候,编译器会使用静态联编,认为p就是一个基类指针,调用基类析构函数,这样子类对象的内存没有释放,造成内存泄露。定义成虚函数后,使用动态联编,先调用子类析构函数,再调用基类析构函数。
18.那些函数不能被定义成虚函数?
1)构造函数不能被定义成虚函数,因为构造函数需要知道所有信息才能构造对象,而虚函数只允许知道部分信息。
2)内联函数在编译时被展开,而虚函数在运行时才能动态绑定。
3)友元函数 因为不可以被继承。
4)静态成员函数 只有一个实体,不能被继承,父子都有。
19.类型转换有那些?各适用什么环境?dynamic_cast转换失败时,会出现什么情况?(对指针,返回NULL,对引用抛出bad_cast异常)
1) static_cast静态类型转换,适用于基本类型之间和具有继承关系的类型。
i.e. 将double类型转换为int 类型。将子类对象转换为基类对象。
2)常量类型转换 const_cast, 适用于去除指针变量的常量属性。无法将非指针的常量转换为普通常量。
3)动态类型转换 dynamic_cast。运行时进行转换分析的,并非是在编译时。dynamic_cast转换符只能用于含有虚函数的类。
dynamic_cast用于类层次间的向上转换和向下转换,还可以用于类间的交叉转换。在类层次间进行向上转换,即子类转换为父类,此时完成的功能和static_cast相同,因为编译器默认向上转换总是安全的。向下转换时,因为dynamic_cast具有类型检查的功能,所以更加安全。类间的交叉转换指的是子类的多个父类之间指针或引用的转换。
20.为什么要用static_cast而不用c语言中的类型转换?
static_cast转换,它会检查看类型能否转换,有类型安全检查。
21.如何判断一段程序是由c编译的还是由c++编译的?
#ifdef _cplusplus cout << "c++" << endl; #else cout << "c" << endl; #endif
22.操作符重载,具体如何定义?
除了类属关系运算符 "." ,成员指针运算符 "*",作用域运算符 “'::”,sizeof运算符和三目运算符"?:"以外,C++中所有运算符都可以重载。
<返回类型说明符>operator<运算符符号>(<参数表>){}
重载为类的成员函数或类的非成员函数时,参数个数会不同,应为this指针。
23.内联函数和宏定义的区别
内联函数是用来消除函数调用时的时间开销的。频繁被调用的短小函数非常受益。
A.宏定义不检查函数参数,返回值之类的,只是展开,相对来说,内联函数会检查参数类型,所以更安全。
B.宏是由预处理器替换实现的,内联函数是通过编译器控制来实现的。
24.动态分配内存和静态分配内存的区别?
动态分配内存是使用运算符new来分配的,在堆上分配内存。
静态分配就是像A a;这样的由编辑器来创建一个对象,在栈上分配内存。
25.explicit 是干什么用的?
构造器,阻止不应该允许的由转换构造函数进行的隐式类型转换。explicit是用来阻止外部非正规的拷贝构造。
26.既然new/delete的功能完全覆盖了malloc()和free()那么为什么还要保留malloc/free呢?
因为C++程序要经常调用C程序,而C程序只能使用malloc/free来进行动态内存管理。
27.头文件中#idfef/define/endif干什么用?
预处理,防止头文件被重复使用,包括program once都这样。
28.预处理器标识#error的作用是什么?
抛出错误提示,标识预处理宏是否被定义。
29.怎样用C编写死循环?
while(1) { } for(;;) { }
30.用变量a给出如下定义:
一个有10个指针的数组,该指针指向一个函数,该函数有一个整型参数并返回一个整型数 int (*a[10])(int);
31.volatile是干啥用的?(必须将cpu的寄存器缓存机制回答的很透彻)使用实例有哪些?(重点)
1)访问寄存器比访问内存要快,编译器会优化减少内存的读取,可能会读脏数据。声明变量为volatile,编译器不在对访问该变量的代码进行优化,仍然从内存读取,使访问稳定。
总结:volatile声明的变量会影响编译器编译的结果,用volatile声明的变量表示这个变量随时都可能发生改变,与该变量有关的运算,不在编译优化,以免出错。
2)使用实例:(区分c程序员和嵌入式系统程序员的基本问题)
并行设备的硬件寄存器 (如:状态寄存器)
一个中断服务子程序会访问到的非自动变量
多线程应用中被几个任务共享的变量
3)一个参数既可以是volatile又可以是const吗?
可以。比如状态寄存器,声明为volatile表示它的值可能随时改变,声明为const 表示它的值不应该被程序试图修改。
4) 一个指针可以被声明为volatile吗?解释为什么?
可以。尽管这并不是很常见。一个例子是当中断服务子程序修改一个指向一个buffer的指针时。
下面的函数有什么错误:
int square(volatile int *ptr) { return *ptr * *ptr; }
下面是答案:
这段代码有点变态。这段代码的目的是用来返指针*ptr指向值的平方,但是,由于*ptr指向一个volatile型参数,编译器将产生类似下面的代码:
int square(volatile int *ptr){ int a,b; a = *ptr; b = *ptr; return a * b; }
由于*ptr的值可能被意想不到地该变,因此a和b可能是不同的。结果,这段代码可能返不是你所期望的平方值!正确的代码如下
int square(volatile int *ptr){ int a; a = *ptr; return a * a; }
32.引用和指针的区别
1)引用是直接访问,指针是间接访问
2)引用是变量的别名,本身不单独分陪自己的内存空间。而指针有自己的内存空间。
3)引用绑定内存空间必须赋初值。是一个变量别名,不能更改绑定,可以改变对象的值
33.关于动态内存分配和静态内存分配的区别:
1)静态内存分配是在编译时完成的,不占cpu资源;动态内存分配是在运行时完成的,分配和释放占用cpu资源。
2)静态内存分配是在栈上分配的,动态内存分配是在堆上分配的。
3)动态内存分配需要指针或引用数据类型的支持,而静态内存分配不需要。
4)静态内存分配是按计划分配,在编译前确定内存块的大小,而动态内存分配是按需分配
5)静态内存分配是把控制权交给编译器,而动态内存分配是把控制权交给程序员
6)静态内存分配运行效率要比动态的高,因为动态内存分配在分配和释放时都需要cpu资源
34.分别设置和清除一个整数的第三位?
#define BIT3 (0x1 << 3) static int a; void set_3() { a |= BIT3; } void clear_3() { a &= ~BIT3; }
35.memcpy函数的实现
void* my_memcpy(void *dest , const void * src, size_t size) { if(dest == NULL && src == NULL) { return NULL; } char* dest1 = dest; char* src1 = src; while(size-- >0) { *dest1 = *src1; dest1++; src1++; } return dest; }
36.strcpy函数的实现
char* my_strcpy(char* dest, const char* src) { assert(dest != NULL && src != NULL); char* dest1 = dest; while((*dest++ = *src++) != '�'); return dest1; }
37.strcat函数的实现
char* strcat(char* dest, const char* src) { assert(dest != NULL && src != NULL); char* dest1 = dest; while(*dest != '�' ) dest++; while((*dest++ = *src++) != '�'); return dest1; }
38.strncat函数的实现
char* my_strncat(char* dest, const char * src, int n) { assert(dest != NULL && src != NULL); char* dest1 = dest; while(*dest != '�') dest++; while(n--) { *dest = *src; dest++; src++; } dest++; *dest = '�'; return dest1; }
39.strcmp函数的实现
int my_strcmp(const char* str1,const char* str2) { int ret = 0; while(!(ret =*(unsigned char*) str1 -*(unsigned char*) str2) && *str1) { str1++; str2++; } if(ret < 0) return -1; else if(ret >0) return 1; else return ret; }
40.strncmp函数的实现
int my_strncmp(const char* str1, const char* str2,int n) { assert(str1!= NULL && str2 != NULL); while(*str1 && *str2 && (*str1 == *str2) && n--) { str1++; str2++; } int ret = *str1 - *str2; if(ret >0) return 1; else if(ret < 0) return -1; else return ret; }
41.strlen函数的实现
int my_strlen(const char *str) { assert(str != NULL); int len = 0; while(*str++ != '�') { len++; } return len; }
42.strstr函数的实现
char* my_strstr(const char* str1, const char* str2) { int len2; if(!(len2 = strlen(str2))) return (char *)str1; for(;*str1; str1++) { if(*str1 == *str2 && strncmp(str1,str2,len)) return (char *) str1; } return NULL; }
43.String类的实现
class String { public: String(const char *str = NULL); String(const String &other); ~String(); String & operator = (const String &other); String & operator + (const String &other); bool operator == (const String &other); int getlength(); private: char *m_data; }; String ::String(const char* str) { if(str == NULL) { m_data = new char[1]; m_data = '�'; } else { m_data = new char[strlen(str)+1]; strcpy(m_data,str); } } String :: String(const String &other) { if(!other.m_data) { m_data = 0; } else { m_data = new char[strlen(other.m_data)+1]; strcpy(m_data,other.m_data); } } String :: ~String() { if(m_data) { delete[] m_data; m_data = 0; } } String & String :: operator = (const String & other) { if(this != &other) { delete[] m_data; if(!other.m_data) { m_data = 0; } else { m_data = new char[strlen(other.m_data)+ 1]; strcpy(m_data, other.m_data); } } return *this; } String & String :: operator + (const String & other) { String newString; if(!other) { newString = *this; } else if(!m_data) { newString = other; } else { m_data = new char[strlen(m_data) + strlen(other.m_data) + 1]; strcpy(newString.m_data,m_data); strcat(newString.m_data,other.m_data); } return newString; } bool String::operator == (const String &other) { if(strlen(m_data) != strlen(other.m_data)) { return false; } else { return strcmp(m_data,other.m_data) ? false : true; } } int String :: getlengrh() { return strlen(m_data); }
44.sizeof()的大小
http://www.myexception.cn/program/1666528.html
45.do{}while(0);的用法有那些?
1)可以将语句作为一个独立的域 2)对于多语句可以正常访问 3)可以有效的消除goto语句,达到跳转语句的效果。
46.请用c/c++实现字符串反转(不调用库函数)“abc”类型的
char* reverse_str(char * str) { if(str == NULL) { return NULL; } char* begin; char* end; begin = end = str; while(*end != '�') { end++; } --end; while(begin < end) { char tmp = *begin; *begin = *end; *end = tmp; begin++; end--; } return str; }
二.服务器编程
1.多线程和多进程的区别(重点必须从cpu调度,上下文切换,数据共享,多核cpu利用率,资源占用等方面来回答。有一个问题必会问到,哪些东西是线程私有的,答案中必须包含寄存器!!)
1)进程数据是分开的:共享复杂,需要用IPC,同步简单; 多线程共享进程数据:共享简单,同步复杂。
2)进程创建销毁,切换复杂。速度慢;线程创建销毁,切换简单,速度快。
3)进程占用内存多,cpu利用率低;线程占用内存少,cpu利用率高;
4)进程编程简单,调试简单;线程编程复杂,调试复杂;
5)进程间不会相互影响,但当一个线程挂掉将导致整个进程死掉
6)进程适用于多核,多机分布;线程适用于多核
线程所私有的: 线程id,寄存器的值,线程的优先级和调度策略,栈,线程的私有数据,error变量,信号屏蔽字。
2.多线程锁的种类有那些?
1)互斥锁(mutex) 2)递归锁 3)自旋锁 4)读写锁
自旋锁(spinlock):是指当一个线程在获取锁的时候,如果锁已经被其它线程获取,那么该线程将循环等待,然后不断的判断锁是否能够被成功获取,直到获取到锁才会退出循环。
3.自旋锁和互斥锁的区别?
自旋锁:当锁被其他线程占用时,其它线程并不是睡眠状态,而是不停地消耗cpu,获取锁;互斥锁则不然,保持睡眠,直到互斥锁被释放唤醒。
自旋锁递归调用容易造成死锁,对长时间才能获得锁的情况,容易造成cpu利用率低,只有内核可抢占式或SMP情况下才真正需要自旋锁。
4.进程间通信:
1)管道 2)命名管道 3)消息队列 4)共享内存 5)信号量 6)套接字
5.多线程程序架构,线程数量应该如何设置?
应尽量和cpu核数相等,或者为cpu核数+1的个数。
6.网络编程设计模式,reactor/proactor/半同步半异步模式?
reactor模式:同步阻塞I/O模式,注册对应读写事件处理器,等待事件发生,进而调用事件处理器处理事件。
proactor模式:异步I/O模式。
reactor模式和proactor模式的主要区别是读取和写入是由谁来完成的。reactor模式需要应用程序自己读取或者写入数据,proactor模式中,应用程序不需要实际读写的过程。
半同步半异步模式:
上层的任务(如数据库查询,文件传输)通过同步I/O模型,简化了编写并行程序的难度。
底层的任务(如网络控制器的中断处理)通过异步I/O模型,提供了更好的效率。
7.有一个计数器,多个线程都需要更新,会遇到什么问题,原因是什么应该如何做,怎样优化?
有可能一个线程更新的数据已经被另一个线程更新了,读脏数据/丢失修改,更新的数据出现异常。可以通过加锁来解决,保证数据更新只会被一个线程更新。
8.如果select返回可读,结果只读到0字节,什么情况?
某个套接字集合中没有准备好,可能会select内存用FD_CLR清为0。
9.CONNECT可能会长时间阻塞,怎么解决?
1)使用定时器,最常用也是最有效的一种方法。
2)使用非阻塞;设置非阻塞,返回之后使用select检测状态。
10.keepalive是什么东西?如何使用?
keepalive,是在tcp中可以检测死连接的机制。
1)如果主机可达,对方就会响应ACK应答,就认为连接是存活的。
2)如果可达,但应用程序退出,对方就发RST应答,发送TCP撤销连接。
3)如果可达,但应用程序崩溃,对方就发FIN应答。
4)如果对方主机不响应ACK,RST,那么继续发送直到超时,就撤销连接。默认2小时。
11.udp调用connect有什么作用?
1)因为udp可以是一对一,一对多,多对一,多对多的通信,所以每次调用sendto/recvfrom都需要指定目标ip地址和端口号。通过调用connect函数建立一个端到端连接,就可以和tcp一样使用send()/recv()传递数据,而不需要每次都指定目标IP地址和端口号。但是它和TCP不同的是他不需要三次握手的过程。
2)可以通过在已经建立UDP连接的基础上,调用connect()来指定新的目标IP地址和端口号以及断开连接。
12.socket编程,如果client断电了,服务器如何快速知道?
1)使用定时器(适合有数据流动的情况)
2)使用socket选项SO_KEEPALIVE(适合没有数据流动的情况)
a. 自己编写心跳包程序,简单说就是给自己的程序加入一个线程,定时向对端发送数据包,查看是否有ACK,根据ACK的返回情况来管理连接。这个方法比较通用,但改变了现有的协议;
b.使用TCP的KEEPALIVE机制,UNIX网络编程不推荐使用SO_KEEPALIVE来做心跳测试。
keepalive原理:TCP内嵌心跳包,以服务端为例,当server检测到超过一定时间(2小时)没有数据传输,就会向client传送一个keepalive pocket
三.LINUX操作系统
1.熟练netstat,tcpdump,ipcs,ipcrm
netstat:检查网络状态 tcpdump : 截取数据包 ipcs:检查共享内存 ipcrm:解除共享内存
2.共享内存段被映射进进程空间之后,存在于进程空间的什么位置?共享内存段最大限制是多少?
将一块内存空间映射到两个或者多个进程地址空间。通过指针访问该共享内存区。一般通过mmap将文件映射到进程地址共享区。
存在于进程数据段,最大限制是0x2000000Byte。
3.写一个C程序判断是大端还是小端字节序
union { short value; char a[sizeof(short)]; }test; int main() { test.value = 0x0102; if(test.a[0] == 1 && test.a[1] == 2)
cout << "big" << endl; else cout << "little" << endl; return 0; }
4.i++操作是否是原子操作?并解释为什么?
肯定不是,i++主要看三个步骤:
首先把数据从内存放到寄存器,在寄存器上进行自增,然后返回到内存中,这三个操作中都可以被断开。
5.标准库函数和系统调用?
系统调用:是操作系统为用户态运行的进程和硬件设备(如cpu,磁盘,打印机等)进行交互提供的一组接口,即就是设置在应用程序和硬件设备之间的一个接口层。Linux内核是单内核,结构紧凑,执行速度快,各个模块之间是直接调用的关系。Linux系统上到下依次是用户进程->linux内核->硬件。其中系统调用接口是位于Linux内核中的,整个linux系统从上到下可以是:用户进程->系统调用接口->linux内核子系统->硬件,也就是说Linux内核包括了系统调用接口和内核子系统两部分;或者从下到上可以是:物理硬件->OS内核->OS服务->应用程序,操作系统起到“承上启下”作用,向下管理物理硬件,向上为操作系服务和应用程序提供接口,这里的接口就是系统调用了。
库函数:把函数放到库里。把一些经常使用的函数编完放到一个一个lib文件里,供别人用。别人用的时候把它所在的文件名用#include<>加到里面就可以了。一类是c语言标准规定的库函数,一类是编译器特定的库函数。
系统调用是为了方便使用操作系统的接口。库函数是为了人们方便编程而使用。
6.fork()一个子进程后,父进程的全局变量能否被子进程使用?
fork()一个子进程后,子进程将会拥有父进程的几乎一切资源,但是他们各自拥有各自的全局变量,不能通用,不像线程。对于线程,各个线程共享全局变量。
7.线程同步几种方式?
互斥锁,信号量,临界区。
8.为什么要字节对其?
1)有些特殊的cpu只能处理4倍开始的内存地址。
2)如果不是整倍数读取会导致读取多次。
3)数据总线为读取数据做了基础。
9.对一个数组而言,delete a和delete[] a有什么区别?
对于基础数据类型没有什么区别,但是对于对象而言,delete a只调用一次析构函数,delete[] a才会析构所有。
10.什么是协程?
用户态的轻量级线程,有自己的寄存器和栈。
11.线程安全的几种方式?
1)原子操作 2)同步与锁 3)可重入 4)阻止过度优化的volatile。
12.int (*f(int,void(*)()))(int,int)是什么意思?
一个名为f的参数为int 和指向void的指针函数的指针函数,返回值为int,参数是int和int
(一个函数,参数为int和指向返回值为void的无参数的函数指针,返回值为一个指向返回值为int,参数为int和int的函数指针)
13.什么是幂等性?举个栗子?
其任意多次执行所产生的影响与一次执行的影响相同。
14.当接收方的接收窗口为0时还能接收数据吗?为什么?还能接收什么数据?那怎么处理这些数据呢?
可以接收。
数据:零窗口探测报文,确认报文段;携带紧急数据的报文段。
可能会被抛弃。
15.当接收方返回的接收窗口为0时?发送方怎么做?
开启计时器,发送零窗口探测报文。
16.下面两个函数早执行时有什么区别?
int f(string &str); f("abc"); //报错
int f(const string &str); f("abc"); // 正常
17.char *const* (*next)()是什么?
next是一个指针,指向一个函数,这个函数返回一个指针,这个指针指向char类型的常量指针
18.如何判断一个数是2的次方?
思想: 直接用这个数和这个数减一的数进行按位与操作就可以。如果等于0则TRUE,否则false。
19. 布隆过滤器 (Bloom Filter)
Q:一个网站有 100 亿 url 存在一个黑名单中,每条 url 平均 64 字节。这个黑名单要怎么存?若此时随便输入一个 url,你如何快速判断该 url 是否在这个黑名单中?
布隆过滤器:
它实际上是一个很长的二进制矢量和一系列随机映射函数。
它可以用来判断一个元素是否在一个集合中。它的优势是只需要占用很小的内存空间以及有着高效的查询效率。
对于布隆过滤器而言,它的本质是一个位数组:位数组就是数组的每个元素都只占用 1 bit ,并且每个元素只能是 0 或者 1。
一开始,布隆过滤器的位数组所有位都初始化为 0。比如,数组长度为 m ,那么将长度为 m 个位数组的所有的位都初始化为 0。
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 1 | 。 | 。 | 。 | 。 | 。 | m-2 | m-1 |
在数组中的每一位都是二进制位。
布隆过滤器除了一个位数组,还有 K 个哈希函数。当一个元素加入布隆过滤器中的时候,会进行如下操作:
•使用 K 个哈希函数对元素值进行 K 次计算,得到 K 个哈希值。•根据得到的哈希值,在位数组中把对应下标的值置为 1。
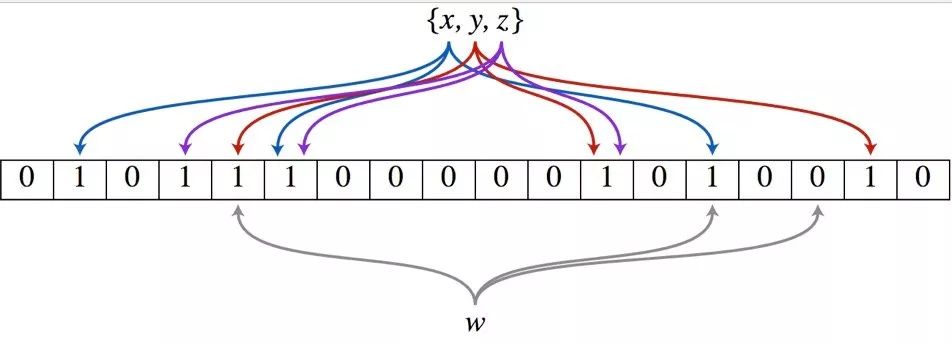
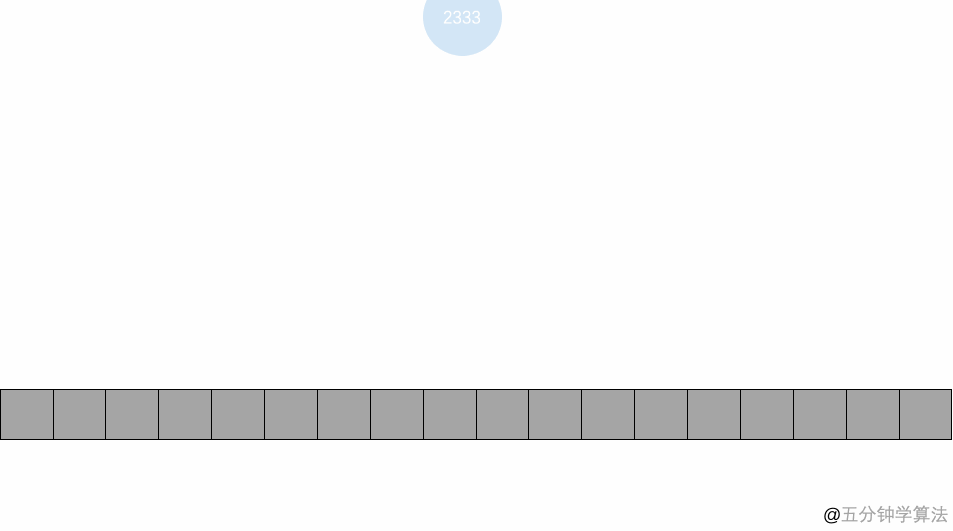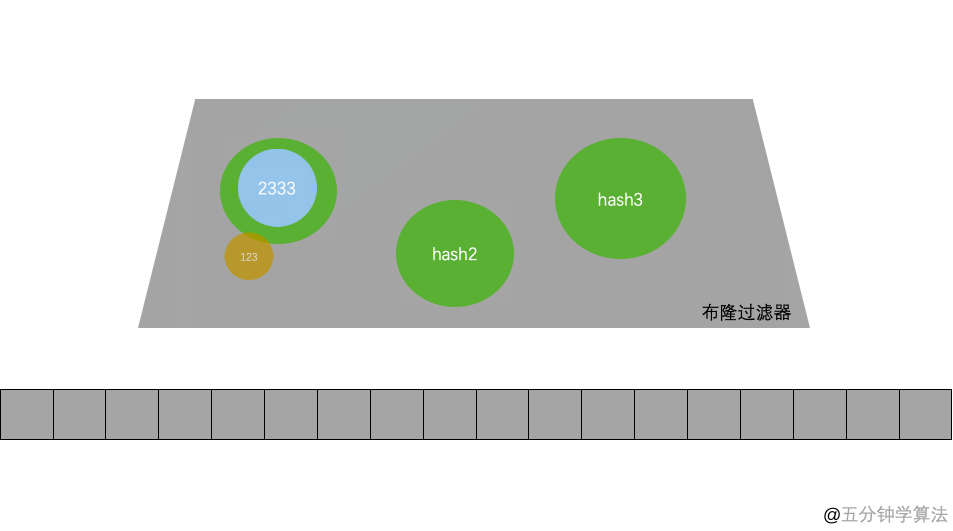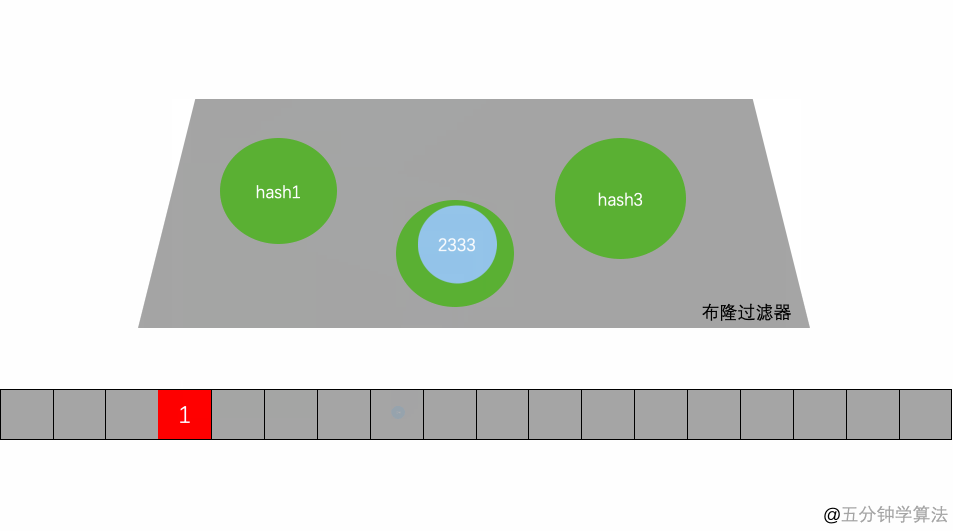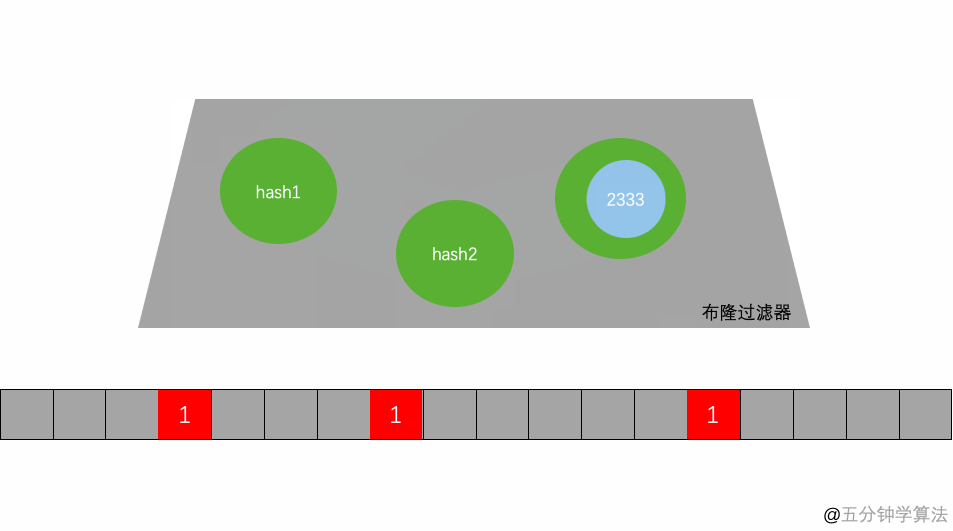
举个例子,假设布隆过滤器有 3 个哈希函数:f1, f2, f3 和一个位数组 arr。现在要把 2333 插入布隆过滤器中:
•对值进行三次哈希计算,得到三个值 n1, n2, n3。•把位数组中三个元素 arr[n1], arr[n2], arr[3] 都置为 1。
当要判断一个值是否在布隆过滤器中,对元素进行三次哈希计算,得到值之后判断位数组中的每个元素是否都为 1,如果值都为 1,那么说明这个值在布隆过滤器中,如果存在一个值不为 1,说明该元素不在布隆过滤器中。
很明显,数组的容量即使再大,也是有限的。那么随着元素的增加,插入的元素就会越多,位数组中被置为 1 的位置因此也越多,这就会造成一种情况:当一个不在布隆过滤器中的元素,经过同样规则的哈希计算之后,得到的值在位数组中查询,有可能这些位置因为之前其它元素的操作先被置为 1 了。
如图 1 所示,假设某个元素通过映射对应下标为4,5,6这3个点。虽然这 3 个点都为 1 ,但是很明显这 3 个点是不同元素经过哈希得到的位置,因此这种情况说明这个元素虽然不在集合中,也可能对应的都是 1,这是误判率存在的原因。
所以,有可能一个不存在布隆过滤器中的会被误判成在布隆过滤器中。
这就是布隆过滤器的一个缺陷:存在误判。
但是,如果布隆过滤器判断某个元素不在布隆过滤器中,那么这个值就一定不在布隆过滤器中。总结就是:
•布隆过滤器说某个元素在,可能会被误判•布隆过滤器说某个元素不在,那么一定不在
用英文说就是:False is always false. True is maybe true。
误判率:
布隆过滤器可以插入元素,但不可以删除已有元素。其中的元素越多,false positive rate(误报率)越大,但是false negative (漏报)是不可能的。
假设布隆过滤器有m比特,里面有n个元素,每个元素对应k个指纹的Hash函数
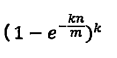
补救方法
布隆过滤器存在一定的误识别率。常见的补救办法是在建立白名单,存储那些可能被误判的元素。
使用场景
布隆过滤器的最大的用处就是,能够迅速判断一个元素是否在一个集合中。因此它有如下三个使用场景:
•网页爬虫对 URL 的去重,避免爬取相同的 URL 地址•进行垃圾邮件过滤:反垃圾邮件,从数十亿个垃圾邮件列表中判断某邮箱是否垃圾邮箱(同理,垃圾短信)•有的黑客为了让服务宕机,他们会构建大量不存在于缓存中的 key 向服务器发起请求,在数据量足够大的情况下,频繁的数据库查询可能导致 DB 挂掉。布隆过滤器很好的解决了缓存击穿的问题。
以上来自公众号:5分钟学算法。
20. 排序算法
1)冒泡 平均O(n^2),最好O(n)。稳定的排序算法。
void m_sort(vector<int> &a) { int len = a.size(); bool flag = true; for(int i = 0; i <len; i++) { for(int j = i+1; j < len - i - 1; j++) { if(a[j-1] > a[j]) { swap(a[j-1],a[j]); flag = false; } } if(flag) break; } }
2)选择排序 最好O(n^2) 平均O(n^2)
void select_sort(vector<int> &a) { int len = a.size(); for(int i = 0; i <len; i++) { int min = i; for(int j = i +1; j < len; j++) { if(a[j] < a[min]) { min = j; } } if(i != min) { swap(a[i],a[min]); } } }
3)插入排序 平均O(n^2) , 最好O(n)
void insert_sort(vector<int>& a) { int len = a.size(); for(int i = 1; i < len; i++) { int tmp = a[i]; int j = i; while(j > 0 && tmp < a[j-1]) { a[j] = a[j-1]; j--; } if(j != i) { a[j] = tmp; } } }
4)希尔排序 平均O(nlogn) 最坏O(nlong^2 n)
void shell_select(vector<int>& a) { int len = a.size(); int gap = 1; while(gap < len) { gap = gap * 3 +1; } while(gap > 0) { for(int i = gap; i< len; i++) { int tmp = a[i]; int j = i - gap; while(j >= 0 && tmp < a[j]) { a[j+gap] = a[j]; j -= gap; } a[j + gap] = tmp; } gap = floor(gap/3); } }
5) 归并排序 平均O(nlogn) 最坏O(nlogn)
vector<int> merge_sort(vector<int> &a,int left,int right) { if(left < right) { int mid = (left + right) / 2; a = merge_sort(a,left,mid); a = merge_sort(a,mid+1,right); merge(a,left,mid,right); } return arr; } void merge(int[] &arr,int left,int mid,int right) { int[] a = new int[right - left +1]; int i = left; int j = mid+1; int k = 0; while(i <= mid && j <= right) { if(arr[i] < arr[j]) { a[k++] = arr[i++]; } else { a[k++] = arr[j++]; } } while(i <= mid) a[k++] = arr[i++]; while(j <= mid) a[k++] = arr[j++]; for(i = 0; i < k; i++) { arr[left++] = a[i]; } }
6)快速排序 平均O(nlogn) 最坏O(n^2)
void quick_sort(vector<int> &a,int left,int right) { if(left < right) { int pre = site(a, 0,right); quick_sort(a,left,pre-1); quick_sort(a,pre+1,right); } } void my_swap(vector<int>& a,int i,int j) { int tmp = a[i]; a[i] = a[j]; a[j] = tmp; } int site(vector<int>& a,int left,int right) { int pivot = left; int index = pivot + 1; for(int i = index; i<= right; i++) { if(a[i] < a[pivot]) { my_swap(a, i,index); index++; } } my_swap(a, pivot, index-1); return index-1; }
7) 堆排序 平均O(nlogn) 最好O(nlogn)
int heap[maxn],sz = 0; void push(int x) { int i = sz++; while(i > 0) { int p = (i-1)/2; while(heap[p] <= x) break; heap[i] = heap[p]; i = p; } heap[i] = x; } int pop() { int ret = heap[0]; int x = heap[--sz]; int i = 0; while(i * 2 +1 < sz) { int a = i * 2+1, b = i * 2+ 2; if(b < sz && heap[b] < heap[a]) a = b; if(heap[a] >= x) break; heap[i] = heap[a]; i = a; } heap[i] = x; return ret; }