在介绍正则表达式和re模块之前,先简要介绍一下
正则表达式与re模块的关系
1.正则表达式是一门独立的技术,任何语言均可使用
2.python中要想使用正则表达式需要通过re模块
正则表达式
元字符
##############################################


分组
##############################################

量词
##############################################
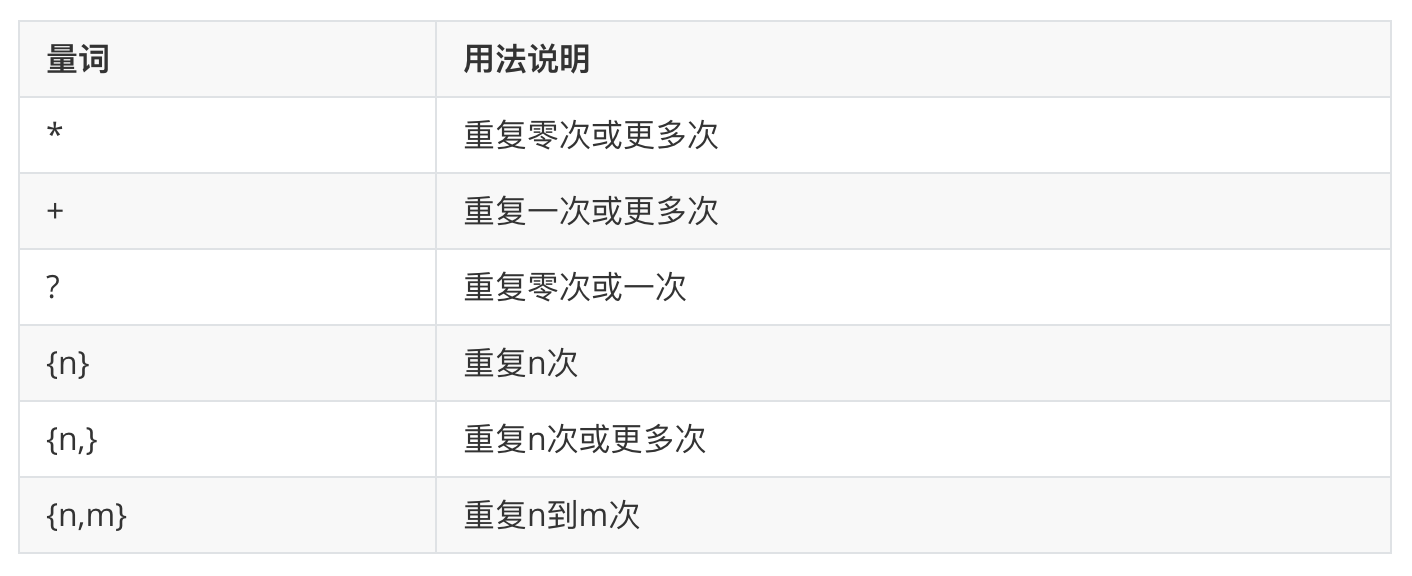
- {n}代表大括号前字符n个
- {n,m}代表大括号前字符n-m个
- {n,}代表大括号前字符n-多个
- {+,}代表大括号前字符1-多个
- {0,}代表大括号前字符0-多个
量词只能限制紧挨着他的那一个正则符号
注意:量词需要写在匹配符号的后面,并且只约束紧挨着它的那个正则表达式
转义符
在正则表达式中,有很多有特殊意义的是元字符,比如 和s等,如果要在正则中匹配正常的" "而不是"换行符"就需要对""进行转义,变成'\'。
在python中,无论是正则表达式,还是待匹配的内容,都是以字符串的形式出现的,在字符串中也有特殊的含义,本身还需要转义。所以如果匹配一次" ",字符串中要写成'\n',那么正则里就要写成"\\n",这样就太麻烦了。这个时候我们就用到了r' '这个概念,此时的正则是r'\n'就可以了。

对照表
|
语法 |
意义 |
说明 |
|
"." |
任意字符 |
|
|
"^" |
字符串开始 |
'^hello'匹配'helloworld'而不匹配'aaaahellobbb' |
|
"$" |
字符串结尾 |
与上同理 |
|
"*" |
0 个或多个字符(贪婪匹配) |
<*>匹配< itle>chinaunix</title> |
|
"+" |
1 个或多个字符(贪婪匹配) |
与上同理 |
|
"?" |
0 个或多个字符(贪婪匹配) |
与上同理 |
|
*?,+?,?? |
以上三个取第一个匹配结果(非贪婪匹配) |
<*>匹配< itle> |
|
{m,n} |
对于前一个字符重复m到n次,{m}亦可 |
a{6}匹配6个a、a{2,4}匹配2到4个a |
|
{m,n}? |
对于前一个字符重复m到n次,并取尽可能少 |
‘aaaaaa’中a{2,4}只会匹配2个 |
|
"" |
特殊字符转义或者特殊序列 |
|
|
[] |
表示一个字符集 |
[0-9]、[a-z]、[A-Z]、[^0] |
|
"|" |
或 |
A|B,或运算 |
|
(...) |
匹配括号中任意表达式 |
|
|
(?#...) |
注释,可忽略 |
|
|
(?=...) |
Matches if ... matches next, but doesn't consume the string. |
'(?=test)' 在hellotest中匹配hello |
|
(?!...) |
Matches if ... doesn't match next. |
'(?!=test)' 若hello后面不为test,匹配hello |
|
(?<=...) |
Matches if preceded by ... (must be fixed length). |
'(?<=hello)test' 在hellotest中匹配test |
|
(?<!...) |
Matches if not preceded by ... (must be fixed length). |
'(?<!hello)test' 在hellotest中不匹配test |
贪婪匹配
正则匹配的时候默认都是贪婪匹配(尽量匹配多的)
<.*>:先拿着里面的.*去匹配所有的内容,然后再根据>往回退着找,遇到即停止
<.*?>:先拿着?后面的>去匹配符合条件的最少的内容,然后把匹配的结果返回
你可以通过在量词后面加一个?就可以将贪婪匹配变成惰性匹配
.*?x
就是取前面任意长度的字符,直到一个x出现
Re模块
三个必须掌握的方法
re.findall
# 第一个参数是正则表达式,第二个参数是待匹配的文本内容 ret = re.findall('a', 'eva egon yuan') # 返回所有满足匹配条件的结果,放在列表里 print(ret)
re.search
ret = re.search('a', 'eva egon yuan') print(ret.group()) # 结果:'a' # 函数会在字符串内查找模式匹配,直到找到第一个匹配然后返回一个包含匹配信息的对象,
该对象可以通过调用group()方法得到匹配的字符串,如果字符串没有匹配,则返回None,
并且需要注意的是如果ret是None,再调用.group()会直接报错。
这一易错点可以通过if判断来进行筛选 if ret: print(ret.group())
re.match
ret = re.match('a', 'abc').group() # 同search,不过仅在字符串开始处进行匹配 print(ret) # ‘a' # match是从头开始匹配,如果正则规则从头开始可以匹配上,
就返回一个对象,需要用group才能显示,如果没匹配上就返回None,调用group()就会报错
res = re.match('a','eva egon jason') print(res) print(res.group()) """ 注意: 1.match只会匹配字符串的开头部分 2.当字符串的开头不符合匹配规则的情况下 返回的也是None 调用group也会报错 """
search 和match区别要弄清楚!!!!!!!!!!
match 和 search的区别,mathch从开头开始匹配找一个,search搜索所有找第一个
其他方法
re.split
ret = re.split('[ab]', 'abcd') # 先按'a'分割得到''和'bcd',在对''和'bcd'分别按'b'分割 print(ret) # ['', '', 'cd'] 返回的还是列表
re.sub
ret = re.sub('d', 'H', 'eva3bitten4yuan4',1) # 将数字替换成'H',参数1表示只替换1个 # sub('正则表达式','新的内容','待替换的字符串',n) """ 先按照正则表达式查找所有符合该表达式的内容 统一替换成'新的内容' 还可以通过n来控制替换的个数 """ print(ret) # eva3bitten4yuan4
re.subn
ret = re.subn('d', 'H', 'eva3bitten4yuan4') # 将数字替换成'H',返回元组(替换的结果,替换了多少次) ret1 = re.subn('d', 'H', 'eva3bitten4yuan4',1) # 将数字替换成'H',返回元组(替换的结果,替换了多少次) print(ret) # 返回的是一个元组 元组的第二个元素代表的是替换的个数
re.compile
obj = re.compile('d{3}') #将正则表达式编译成为一个 正则表达式对象,规则要匹配的是3个数字 ret = obj.search('abc123eeee') #正则表达式对象调用search,参数为待匹配的字符串 res1 = obj.findall('347982734729349827384') print(ret.group()) #结果 : 123 print(res1) #结果 : ['347', '982', '734', '729', '349', '827', '384']
re.finditer
import re ret = re.finditer('d', 'ds3sy4784a') #finditer返回一个存放匹配结果的迭代器 print(ret) # <callable_iterator object at 0x10195f940> print(next(ret).group()) #查看第一个结果 print(next(ret).group()) #查看第二个结果 print([i.group() for i in ret]) #查看剩余的左右结果
分组优先机制
对于search方法
import re res = re.search('^[1-9]d{14}(d{2}[0-9x])?$',110105199812067023) print(res.group()) print(res.group(1)) # 获取正则表达式括号阔起来分组的内容 print(res.group(2)) # search与match均支持获取分组内容的操作 跟正则无关是python机制
对于findall方法
ret = re.findall('www.(baidu|google).com', 'www.google.com') print(ret) # ['google'] 这是因为findall会优先把匹配结果组里内容返回,如果想要匹配结果,取消权限即可 ret = re.findall('www.(?:baidu|google).com', 'www.google.com') # ?:取消分组优先 print(ret) # ['www.google.com']
补充:
import re ret = re.search("<(?P<tag_name>w+)>w+</(?P=tag_name)>","<h1>hello</h1>") #还可以在分组中利用?<name>的形式给分组起名字 #获取的匹配结果可以直接用group('名字')拿到对应的值 print(ret.group('tag_name')) #结果 :h1 print(ret.group()) #结果 :<h1>hello</h1> """ 注意?P=tag_name相当于引用之前正则表达式,并且匹配到的值必须和前面的正则表达式一模一样 """
匹配整数:
ret=re.findall(r"d+","1-2*(60+(-40.35/5)-(-4*3))") print(ret) #['1', '2', '60', '40', '35', '5', '4', '3'] ret=re.findall(r"d+.d*|(d+)","1-2*(60+(-40.35/5)-(-4*3))") print(ret) #['1', '2', '60', '', '5', '4', '3'] ret.remove("") print(ret) #['1', '2', '60', '5', '4', '3']