| 项目 | 内容 |
|---|---|
| 这个作业属于哪个课程 | 2021春季计算机学院软件工程(罗杰 任健) |
| 这个作业的要求在哪里 | 结对作业-总结 |
| 我在这个课程的目标是 | 提升工程能力和团队意识,熟悉软件开发的流程 |
| 这个作业在哪个具体方面帮助我实现目标 | 总结结对编程 |
项目概要
| 内容 | |
|---|---|
| 项目地址 | 结对项目 gitlab 地址 |
| 学号后四位 | 3019 3293 |
实践反思
Q1 复盘
针对前面两个阶段中出现的问题,分析问题的特征、产生的根源和对质量的影响程度;
本次结对主要出现以下几个问题:
第一是对于结对编程“驾驶员和领航员互换”的实践偏差。
第一次作业最开始时,在 my 做完需求分析、写完设计文档后,已达一个小时,为了“实践结对编程”,我们驾驶员领航员互换,让 lkl 同学主笔,但 lkl 同学没有完全理解需求设计文档的内容,而且也不习惯编码的时候被别人看,写起来的效率很低。后来换 my 同学执笔,并全程驾驶。
驾驶员和领航员不断轮换角色,不要连续工作超过一小时,每工作 一小时休息15分钟。领航员要控制时间。
——《构建之法》4.5.4 如何结对编程
由于初次实践结对编程,对于条条框框执行得比较严格,导致两人初期效率很低。设计完需求和设计文档后,脑中有清晰的编码网络,这时驾驶员仍没有进入低效率时间,应当马上按照自己的思路进行编码,同时领航员也可以逐步理解需求和设计。
由于 my 同学打 ACM 训练较多,可以连续 5-10 小时较高效率进行编码工作,而 lkl 同学作为领航员可能在更少的时间内就进入了稍低效率的工作时段。my 热情过于高涨,领航员也没能及时制止,导致没能及时结束当日的工作时间,虽然两次作业都在一天之内结束了战斗,但实际发现每次的后半段出现的 bug 会更多一些,这或许是由于两人的效率逐渐下降导致的。
尽管如此,因为驾驶员和领航员的互相 push (经常提出问题,沟通交流想法,验证思路等),两人的效率仍然保持在一个较高的水平。同时,由于完成大部分编码开发后两人高强度专注设置测试,对于指导书覆盖情况较好,因此,对于最终代码质量的影响程度很小。
仔细思考,这是由于对于稍微大型工程的理解实现没能从普通的规模小的程序转化,过于追求速度,而导致“一天把所有事都做完”的思想控制了整个开发进程。如果工作量再大一点(一天写不完的那种),可能还会出现其他的问题。
第二是开始时对于问题划分没有做彻底。
交给 lkl 同学驾驶员的角色后,my 错误地认为初期不需要太多的审核,就去学习 maven cobertura 往课程组 CI 上部署的步骤了。我们虽然在之前已经定下来了代码规范(通过 OO checkstyle),但由于 lkl 同学近期 python 写的比较多,变量命名是下划线分隔的小写字母串,以及部分变量名称也命名不全面规范(如 fa_dir),在 my 部署好 CI 后,回来才发现这个问题,花了一定时间更改。这虽然没有影响最终的代码质量,但在最初规定下来合适的代码命名规范是非常有必要的,当时只考虑到了 checkstyle 而没有考虑到变量命名。
第三是对于一些需求,一些存疑的决策没有被记录下来。
在第一次作业开始时,对于不清晰的 . .. 三种将路径字符串使用 / 分割开后特殊情况的处理,最开始指导书对于这个方面的描述是有问题的,课程组也在讨论考虑是否采纳 my 同学关于将 . .. 作为特殊目录的建议,因此此时需求是不确定的。lkl 同学在此时是驾驶员,使用的方法是先将路径预处理,将多个 / 化为一个 / ,并在 findDirectory 函数中特殊判断。领航员 my 认为不妥,提出将此法换作 . .. 三种特殊目录。
在提出此法后,驾驶员和领航员互换, my 同学延续自己的思路进行编码,而此时领航员应当对这个决定进行审核,两人也应当对于这一个新的实现方式进行分析测试,考虑是否会影响到指导书中其他部分的实现。但实际是两人直接使用了这个方法,也没有对此进行记录,这在第一次作业中的情况符合了指导书的定义,但在第二次作业对于 srcname 和 / 结尾路径需要进行的特殊处理情况就会变多。第二次作业没有及时发现这个问题,导致小部分重构。如果对此决策进行一定的记录,将会在第二次作业开始时就着重关注此问题,从而优化时间分配。
lkl:特征:问题多发于第二阶段,大多与需求不清有关,进一步细化,软硬链接的相关操作是问题重灾区。根源:由于第一次作业中对于 mkdir -p 原子性的考虑与课程组相悖,导致第二阶段需要修改,因此我们在第二阶段需求分析时,只要遇到理解有偏差的点就提 issue ,并且大多情况下需要等到 issue 被解决才开始实际编码,这样导致后期程序堆积了许多需要调整和补充的地方,且由于对应的 issue 被解决的时间不等,有部分问题直接被我们遗忘了,等到这些被遗忘的问题在测试阶段暴露出来时,我们才反应过来 bug 发生位置不是之前商量好需要修改的地方嘛!影响:程序大体没有很多 bug ,问题在于我们对于细节之处有所疏忽,但所幸得益于整体设计质量较高,需要修改的地方比较小。
Q2 需求分析
总结结对项目中的需求分析实践体会,并分析哪些 bug 是因为需求分析不足而带来的;
需求分析这块我们有话要说。
软件工程,唯一不变的是变化。所以干脆别幻想客户的需求会在第一 时刻很明确,然后保持不会变。
——《构建之法》7.2.6 保持敏捷,预期和适应变化
由于我们组起步较早(第一天发布就完成了任务,后续进行需求改变的迭代开发),大量需求是不明确且含有争议的。在这种有争议的情况下,我们仍能较高质量的完成作业并在每次迭代时修改极少量代码(不进行重构),主要原因就是对于需求的合理分析,当然合理的架构也是其中一方面。
第一次作业中,对于需求分析的要求较低(指导书相对较为明确,改的一些地方也是我们所提出建议即我们的架构),故着重谈论第二次的需求分析。
对于变动化的、存在争议的需求,应当如何实现呢?从实现者的角度,对于模糊的情况要做出适当的有记录的假设,并且尽量避免调用非必要实体。简单来说,比如我认为 / 结尾这件事很麻烦,如果每个方法都处理一次字符串,不仅代码很冗杂,实现不优雅,容易出现边界问题,而且也大大增加了测试和复审的工作量。这时,通过一个对需求的分析,发现这个结尾的 / 其实是可以作为 feature 的一个小问题,那么我可以放心大胆的调用 findFile 之类的方法,无非将空文件名视作一个特殊目录,而无需追求更加严谨的细节。
什么样的假设才是适当的、合理的假设?
首先,对于整体进行分析,我们最终要实现一个什么目标。在本次作业中,我们要实现的是一个文件管理系统(用户事太少了,略掉)。其次,对于内容进行分析,我们要支持什么样的命令。我们需要支持一个操作符后面加一两条路径的命令,所以我得有个东西处理这个路径,而且要统一处理,增强代码复用性。再次,对于如何支持这个内容进行分析,我们需要什么样的实体。我们要支持文件、目录、软硬链接四个实体。每个实体有其对应的功能。这就分析完毕了。
有了这样的分析,我们就可以对于指导书的一些细节进行假设:
注意,默认情况下程序需将所有出现的软链接视为它指向的路径下的文件或目录,但在以下情况时程序要特殊处理:
- 当软链接指向一个文件时,指令 rm, info, mv, cp 中的软链接路径不做重定向。
- 当软链接指向一个目录时,指令 rm, rm -r, info, mv, cp 中完全匹配软链接路径的参数不做重定向,但软链接路径作为参数的上层目录时需重定向。
分析一下软链接的性质,就是一个记录绝对路径的快捷方式。因此,软链接可以当做一个文件用,也可以当做他指向的抽象文件用。这里的规范就是在区分这两种用途:删除、移动、拷贝、输出信息时,当做一个快捷方式用,否则当做其指向的抽象文件。那么当软链接作为 mv cp 的 dst 时,解释为快捷方式也可,解释为指向的目录也没问题,因此对此暂作出不予考虑,当做快捷方式用处理的假设,并作出记录,需要支持当做指向目录用的需求改变。这种问题是指导书未考虑到的,因此在后续开发中可以进行 Ubuntu 实验,观察其真实动作。但由于这步操作的优先级较低,故仅作记录,后续再做实验。
同样,对于链接到软链接的软链接,指导书中规定其指向的路径为所指向软链接指向的路径,这可以合理假设为一个防止软链接链的补丁,但这样的规范并不能真正避免软链接链,是无必要的实体,所以大可认为需求不合理,发表 issue 并记录实现方式。包括规范目录后判断可不可以添加 / 时,这其实就是在补第一次指导书中的补丁,而第一次指导书出现此问题正是由于对于路径这个实体定义不充分造成的,对于这种模糊的需求,我只需做出假设,记录,并预留需求改动的接口。
我们假设的记录方式有二:一是在代码中作出记录,如注释、 TODO 代码块;二是通过自己项目的 issue 区,在记录自己的实现后,等待需求发生变化(issue 收到回应),然后本地进行修改提交。将假设进行记录,极大地方便了代码复审和对应需求改变进行的迭代开发。
Q3 架构设计
总结结对中的架构设计实践体会,描述通过改进设计来提高程序的性能改进的思路和方法,并分析哪些 bug 是因为架构设计不足(特别的,需求变化)而触发的 bug;
有了合理的需求假设,架构设计就水到渠成了。注意,好的架构应当在任何合理的需求变化下作出尽量少的改动。比如,对于某些需求变化,如果我们只需要改两三行,而某些团队可能需要进行小范围甚至大规模重构,那么我们在架构上面的磨刀就省下了不少需求改变的砍柴时间,能够做到更加敏捷。
架构分析
整体架构
第一阶段中,使用了 File Directory 两个互无关系的类,由于指导书就把文件管理系统分为了文件和目录,所以写起来没什么不妥,非常顺畅。其中,由于要将路径转化为目录或文件,因此设置了一个**处理路径的函数 findDirectory **,以及调用该函数得到路径的文件/目录名和父目录的函数 getFatherDirectoryAndName,实现了对于路径的统一处理。后面会发现,这两个函数贯穿始终,成为了复用性最高的两个函数。

第二阶段中,事情发生了变化,来了两个 File 的小老弟——SoftLink HardLink ,并且要求 info 命令查询的可能为目录或文件。第一次作业中,这里是通过 if else 语句实现的,而第二次作业时发现可以使用抽象文件的方法更加优雅地实现,果断进行小重构。File 类和两个链接类根据指导书也进行了一些方法的定义重写,最终 getInfo 在抽象类 AbstractFile 里被优雅的实现。
异常
规定每一种异常都起一个好听的名字。于是我们最后有了这么多异常:
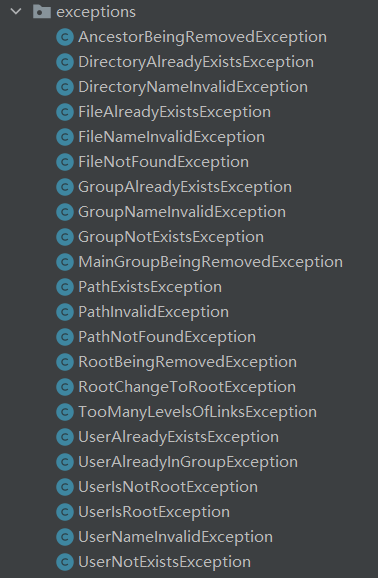
异常的丰富性极大方便了后续测试覆盖的完整性,也在方便修改异常内容的同时,方便了对于异常抛出顺序的测试。
另外,我们规定,在 AbstractFile 及其子类的基本方法中,不许抛异常。所有异常情况由 MyFileSystem 判断并解决,这样规定下来保证了抽象文件子类的封闭性。
辅助函数
辅助函数包括对文件名、目录名、用户名、用户组名合法性检测;对文件内容大小的计算;对 tree -a 指令支持的辅助函数;以及将路径处理成一段段文件目录名的路径处理函数。对于这些不涉及文件/目录类的函数,封装到 utils 包中处理,简化主类代码量。
断言
将异常包裹成断言的形式,在各个断言中抛出异常,提高了代码复用性和主函数的可读性。
总结
代码复用性是架构设计中极为重要的一环,需要尽量避免任何形式的复制粘贴,但凡需要复制粘贴,就要将其抽象为函数进行复用。乍一看抽象出额外的函数似乎比较浪费时间,但这在提高了代码可读性的基础上,使得修改代码也变得更加容易了。
优化
改进设计的优化主要是考虑输入条数较少(500)进行的三个简单优化,将存储绝对路径,实时直接查询改为存储名字,查询时循环累加;将递归计算目录大小改为实时更新大小;将递归修改 modify_time 改为懒标记下放修改。另外,第一次作业中还有将 StringBuilder 的 insert改成 append(具体分析见第一次博客)。
没有进行 copy on use 优化(具体内容见第二次博客)的主要原因就是对架构的影响过大。需要支持记录沿途更新的历史记录,并通过历史记录反推出原数据所处位置、所包含内容等。如果该数据是通过 mv cp 得到的,则需要记录大量的更新日志对应关系;且在主体函数 findDirectory 中要实时更新更新日志,在每个方法后都需要向根节点遍历更新一路的日志,对架构的影响过大。因此,没有进行此种优化。
触发的 bug
架构设计不足触发的 bug 较少,需求的改动也通过及时的 issue 处理从而处理掉了。主要还是对指导书细节处理不到位导致严格按照指导书测试的时候修了不少 bug,比如异常抛出的顺序、抛出的内容是 src 还是 dst (最初硬链接抛反了)。
印象比较深的一个 bug 出现在 copy 文件覆盖另一个文件的情况,在我们的架构中,软硬链接也是一种文件,我们单独为软硬链接新建了一个继承自文件类的类,我们在 copy 软硬链接覆盖别的文件时,统一调用文件类的 write 方法,导致 copy 软硬链接覆盖另一个软硬链接或者 copy 普通文件覆盖软硬链接时,被覆盖的链接文件指向的文件或路径并没有被修改,最后是文件类设置一个 cover 方法,软硬链接类重写这个方法,使得各种情况下的行为都与指导书或 issue 区的规定相匹配。
有一个架构设计不足导致需求变化时处理麻烦的问题,就是 mkdir -p 的原子性保证,最后添加了一个类似 findDirectory 的模拟路径检测器解决。
还有一个架构设计不足导致的 feature,就是结尾为 / 的路径在不同指令中的表现不同,没有抽象出合理的函数对结尾为 / 的路径进行处理。
Q4 进度管理
总结结对过程中的进度、质量和沟通管理实践体会,并分析哪些哪些 bug 是因为两个人的理解不一致而导致;
进度管理通过两方面进行:第一是 issue 记录,TODO 事项的处理;第二是对于 commit,进行版本更新,通过 git rebase 避免过多冗余的 commit 出现,保证问题可回溯的同时,方便队友检验(部分因需求小改变导致的更改没有进行线下结对,而是由驾驶员进行修改并交递领航员进行代码复审)。

质量(性能)管理主要是在编码时加入 TODO 块,对可能存在的优化空间进行事先标注,并且先对于主体需求进行实现,对于优化放置在优先级较低的位置处理(从 commit 记录也可以看出来,优化发生在主体需求都已经实现的基础后)。
两人因为同在 OO 系统组修过锅,沟通没有障碍,故没有萌芽阶段,直接进入磨合。中间出现问题时,我们在分析问题成因后,立刻讨论决定是立即修复或将问题记录下来之后进行修复。如果有领航员或驾驶员不确定的问题,此时必有一人来假设并拍板,通过逻辑说服对方,并且对这种假设进行记录。
因为需求主要都是驾驶员进行分析并且与领航员进行讨论,两人达成一致理解后(或分析出指导书具体的需求,或进行有记录的假设)才进行编码,所以理解不一致导致的 bug 可以说不存在。
Q5 未来建议
提出建议:根据三个阶段的结对项目的实践经验,对如何更好的实施和管理结对项目提出自己的建议。
- 结对编程不一定要拘泥于课本上的实现方式,根据两个人的实际情况进行编程。尤其是在进行完需求和设计后,不一定要严格按照一个小时将驾驶员和领航员换一次,尽量由进行设计的同学进行编码,避免对方因为不理解导致的效率低下。
- 完备的规范。尤其是命名规范,因为代码规范通过 OO 的 checkstyle 即可规范,但命名规范应当能够清晰反映该属性/方法的功能特性,这样能够大大方便后续开发时对于代码的使用(如,IDEA 有代码补全功能,在想用某个功能时可以试探性输入已得到对应方法名称)。
- 一定要进行充足的交流。无论是需求分析、设计还是实现,在遇到对指导书的需求理解不充分时,充分的讨论能让双方都理解自己在完成什么事情,从而大大提高结对的效率。
- 决策要果断且合理,并且有记录。对于需求分析、设计和架构各个方面,要果断地提出假设和决策,敏捷开发切忌优柔寡断。另外,如果不是和指导书严密契合的,就要进行完备的记录。
CI 体验感想
通过这次结对编程,你对 CI 的使用体验如何?你对这一工具有何认识?
第二次作业中对于 CI 使用 maven cobertura 进行计算覆盖率的工作大有用途,结对开始时也进行了评测平台的试错(根据不同报错信息推断远程评测细节,如不能修改 git 仓库目录下的文件等),因此结对过程中对于 CI 的使用体验很好,本地修改完 push 即可获得评测结果。由此,我们也在 issue 区对此试错的结果进行了方法分享。
CI 持续集成对于 JUnit 单元测试和 cobertura 计算覆盖率可以自动进行,在版本更新时自动进行构建和测试,非常方便。尤其是考虑到之后团队合作阶段,可能有多个分支都要合并到主干中,一旦对代码进行更改就要进行多方面高层次宽领域的自动化测试(单元测试、集成测试),以验证这个更改对于整个应用不进行破坏。同时,对于单元测试,可以设置每次代码合并都要触发扫描,扫描结果不达标则 job 失败,合并检查失败,无法合并,最终效果就是扫描结果不达标则无法合并。这样也可以保证测试的覆盖率达到要求。
结对编程感想
Q1 结对方法
描述你们结对的方法、结对过程中遇到的困难与收获,结合自己的结对经历,说明结对编程的优点和缺点,分享可以推广的结对妙招。
结对方法
我们组结对的方式主要是线下结对,约好时间地点后进行结对编程;同时,对于部分需求的更改,进行线上结对编程,即两人进行讨论——驾驶员提出解决方案并修改——领航员进行代码审核并提出修改意见。困难和收获都在上文中有所提及,故不再赘述了。
优缺点分析
其实在前两次博客作业中写的够全面了,仅在这里总结一下。
优点:
-
结对确实可以让自己全身心投入思考和编码测试,很难想象自己一个人半天的时间能够将本次作业写完。效率的提升是很高的,避免了大量的摸鱼无效时间,还规范了作息(因为队友 lkl 作息太规律了),两人商量时间也更加具有默契。有时候编码走神写 bug,也会被队友及时发现并指出。另外,还一个好处就是在本地 ubuntu 上跑不出来软链接的一些命令(如 cd 等)队友可以使用自己的电脑进行实验。在一些指导书描述不是很清晰的地方,两人相互讨论理解也极大促进了编码实现的过程,避免了编码者当局者迷的情况。
-
队友敏捷的思维促使我思考,良好的编码习惯(面对过长的方法会积极思考代码抽取;对于作出复杂处理,例如多分支的方法,会先进行单元测试,尽量避免低级逻辑错误;对于需求不清晰的地方、有特殊功用的方法等地方会附带注释,利于代码复审)使我豁然开朗,收获颇多。
缺点:效率低于两个人并行作业。
结对妙招
结对编程之前一定要读《构建之法》!一定要读《构建之法》!一定要读《构建之法》!
这本书里关于各种方面的内容都被我们结对编程所吸收利用,无论是结对编程的细节、目的和方式,还是测试的构造、分类和要求,再是对于需求分析、架构设计,以及对于决策的各个方面,都极大地增强了本次结对编程实践的实现效率和质量。
还有就是,需求分析、架构设计和测试一定要充分。良好的架构决定优秀的代码,而全面的测试更能保证代码的小强无处可逃。
另外,如果你没有足够的 ACM 等长时间组队的比赛经验,不要工作过长时间。正如《构建之法》中所说,在长时间高强度工作之后的效率是会有一定下降的。但如果有,那就随它去吧,在一个问题没解决完之前,你的精力是无限的。
还想提的一点是关于单元测试。引一段《个人阅读作业2》中,轮子哥对于 TDD 的指导:
针对单元测试指出一点。TDD不是形式上的先写测试再写代码。TDD的一个重要作用是帮助你设计组件。你站在组件的调用者的角度,用测试用例写出组件到底该怎样被调用,算是第一步。至于如何安排足够的输入,有一部分当然是要借助代码来完成的,写完后继续补充完整的测试用例也不是不行。单元测试不是完全黑盒也不是完全白盒。以后发现了bug,还可以继续往里面增加一个测试来重现。以后重构了,还能保证犯过的错误永远不会再出现。随着开发进度的推进,测试用例不断的变多也是正常的。
我们虽然没有真正使用测试驱动开发,但是这种“TDD测试的重要作用是帮助你设计组件”的思想贯穿我们测试始终。我们先考虑顶层组件,由上到下地进行测试。对于单个小类 File Directory 并不会进行充分地测试,而是在 MyFileSystem 的调用中去尽量找到调用到这些函数的更多的边界情况,这一点能够充分发挥覆盖率测试的优越性,进行全面的测试。
另外,关于测试,我们永远也达不到测试需求的完全全面,需要在需求的改动和开发测试的改动中寻求一个平衡。有一个段子,分享一下:
一个测试工程师走进一家酒吧,要了一杯啤酒
一个测试工程师走进一家酒吧,要了一杯咖啡
一个测试工程师走进一家酒吧,要了0.7杯啤酒
一个测试工程师走进一家酒吧,要了-1杯啤酒
一个测试工程师走进一家酒吧,要了2^32杯啤酒
一个测试工程师走进一家酒吧,要了一杯洗脚水
一个测试工程师走进一家酒吧,要了一杯蜥蜴
一个测试工程师走进一家酒吧,要了一份asdfQwer@24dg!&*(@
一个测试工程师走进一家酒吧,什么也没要
一个测试工程师走进一家酒吧,又走出去又从窗户进来又从后门出去从下水道钻进来
一个测试工程师走进一家酒吧,又走出去又进来又出去又进来又出去,最后在外面把老板打了一顿
一个测试工程师走进一
一个测试工程师走进一家酒吧,要了一杯烫烫烫的锟斤拷
一个测试工程师走进一家酒吧,要了NaN杯Null
1T测试工程师冲进一家酒吧,要了500T啤酒咖啡洗脚水野猫狼牙棒奶茶
1T测试工程师把酒吧拆了
一个测试工程师化装成老板走进一家酒吧,要了500杯啤酒并且不付钱
一万个测试工程师在酒吧门外呼啸而过
一个测试工程师走进一家酒吧,要了一杯啤酒';DROP TABLE 酒吧
测试工程师们满意地离开了酒吧。
然后一名顾客点了一份炒饭,酒吧炸了
Q2 评价队友
评价你的队友,使用汉堡点评法评价你的结对伙伴,务必给 TA 提改进意见。
lkl:my 同学的思路清晰、严谨;有建设性想法且大部分都能落实于行动;码力很强,完成速度很快且质量较高;对待结对项目非常上心,每周在其上投入较多时间。但是,在我个人看来,my 同学的作息感觉可以适当调整一下(实在没什么改进意见可以提出了),有时候在凌晨一两点发来关于结对项目的进展或问题,而我经常第二天才回。适度娱乐适度学习才是可持续发展之道,为祖国健康工作五十年要从现在开始做准备。
my:lkl 同学对于我们的合作项目很上心,第一天指导书发布约合作时间时,冯如杯答辩完成就马上来一起开始结对工作了;对于细节很细心,很多我因为粗心写的 bug 都会被及时指出;另外作息也很规律,迫使我规律作息,方能够第二天一起约好时间进行结对编程。但是,对于自己实现代码还是有一定心理上的抗拒(不习惯在别人面前写代码),这一点其实可以在后续的编程活动中逐渐放开自我,和队友更加愉悦的合作。我们一起的合作很愉快,在细心的领航员 lkl 同学的领航下,我们结对作业顺利驶向了彼岸。
Q3 软件工具
描述在本次结对编程的过程中,你们使用了哪些软件工具,是如何应用于实践的。
编程语言课程组选择了我们 OO 惯用的 java,不过使用了 maven 进行项目构建,使用 JUnit 进行单元测试,并通过 cobertura 计算覆盖率。
软件也是使用的一直使用的 IDEA,其中使用的插件有检查代码风格的 checkstyle,生成单元测试的 JUnitGenerator,计算圈复杂度并分析改进代码的 MetricsReloaded,以及压力测试使用的 JProfiler。
通过 MetricsReloaded 分析出的圈复杂度较高的方法(如 copy,move),进行详尽的、严格按照指导书描述的测试,以最大限度减少 bug 可能。同时,将一个方法的测试分成多个子测试,便于分析和 debug。

 |
 |
第一次作业中的压力测试,也是通过 JProfiler 对调用树的分析找到“大头”方法(存储绝对路径、递归计算目录大小),并进行优化。具体内容在 前 两 次的博客中压力测试部分有,在此就不在赘述了。
Q4 作业吐槽
描述通过本次结对编程的感悟和体会,对本次作业的有哪些想吐槽的,觉得本次结对作业内容可以在哪些方面做出改进?
lkl:选题的复杂程度其实超乎想象,课程组的本意并不是让我们纠结于细节,但文件系统这样的东西作为操作系统的一部分,谁也说不准用户会干什么,本就需要考虑一堆奇奇怪怪的情况防止操作系统崩溃,所以建议选择能控制的题目或者继续回归迭代指导书。
my:先吐槽一波指导书。从需求方的角度,对于指导书,我们可以从信息量巨大的一个个方法的解释中看到助教们辛苦地对于每一个方法都进行了全面的打磨;但同时我们也会思考,这样复杂的逻辑结构,应该如何设计?可不可以化简?这还要从“如无必要勿增实体”一句切入。
指导书中具有的实体有的是非必要的,如对于链接到软链接的软链接,指向的路径为所指向软链接指向的路径,这是一个防止软链接链的补丁,但这样的规范并不能真正避免软链接链,是无必要的实体。
规范目录后判断可不可以添加 / 时,这其实就是在补第一次指导书中的补丁,而第一次指导书出现此问题正是由于对于路径这个实体定义不充分造成的。
因此,每次添加补丁的时候,都似乎应当回去看一看,是否能够通过明确地定义原来的实体而避免新补丁的出现?当然,这种新产生的定义也要经过回归测试。在添加新功能、修改新问题之后,需要对所有相关实体展开分析和测试,在时间有限的情况下,或对“ bug 易发路段”进行单独挖掘,或进行多人审核(前提是审核者不摸鱼),这才能构成一个完整的回归测试。
不过话说回来,指导书虽然确实很捞,不过也很妙(烂活,就是有点好)。不够清晰或者表述有问题的部分,正体现了需求的不确定性,要求我们更加注重架构,而对于一些细枝末节的东西有自己的实现,有自己的想法,正体现了工程中并不是什么东西都是有标准答案的。对于没必要的细节,当做 feature 处理即可,我们实现如此,代码说什么就是什么,无需多加追究。