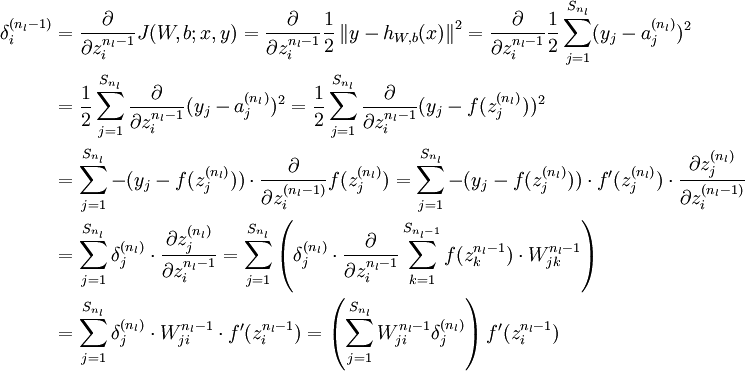反向传播算法(Back Propagation):
引言:
在逻辑回归中,我们使用梯度下降法求参数方程的最优解。
这种方法在神经网络中并不能直接使用,
因为神经网络有多层参数(最少两层),(?为何不能)
这就要求对梯度下降法做少许改进。
实现过程:
一、正向传播
首先,同逻辑回归,我们求出神经网络输出与实际值的“误差”——COST:
这里先使用欧式距离而不是索夫曼函数作为输出的cost:
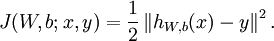
展开之后:
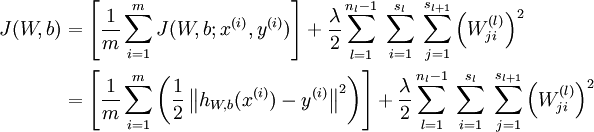
(注意右边的权重衰减项,既规则化)
二、反向传播
对于第 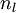 层(输出层)的每个输出单元
层(输出层)的每个输出单元  ,我们根据以下公式计算残差:
,我们根据以下公式计算残差:
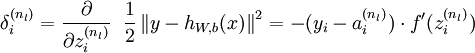
对 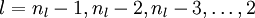 的各个层,第
的各个层,第 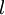 层的第 个节点的残差计算方法如下
层的第 个节点的残差计算方法如下
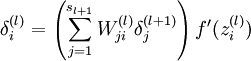
这里:
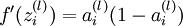
这里相当于把本层节点的残差按照权重“投影”到上一层残差的节点上(“反向传播”就是这个意思)
在计算出各节点的残差之后,参数的偏导如下计算:
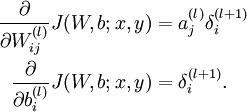
然后就可以梯度下降去了!
梯度下降过程:
1、进行前馈计算,求的所有节点的输出,求得cost;
2、进行反向传播计算,求的所有节点残差(第nl ~ 第2层)
3、利用公式求得cost对参数的偏导
4、更新偏导。
5、重复1~4知道cost差距小于预设值或重复次数大于预设值
(这里以上只讲实现方法,省略所有证明。相关证明贴于最后。)
随机初始化( Random Initialization):
在进行第一次前馈算法之前,神经网络参数的值是多少呢?
全零初始化?这是不可以的!
如果选择相同的参数进行初始化,
隐藏节点的出入必定相同(自己推推,更不用说输出了)。
为了使得对称失效,我们对神经网络的参数进行随机初始化,
既采用接近零的初始值进行初始化。
这个过程可以用matlab产生随机矩阵的功能来实现。
初始化之后,让我们一起下降吧!
用到的证明(残差的计算):
1、
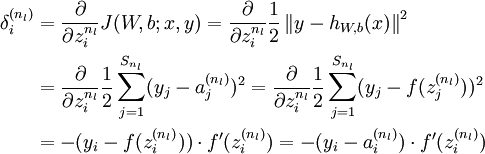
2、