ss


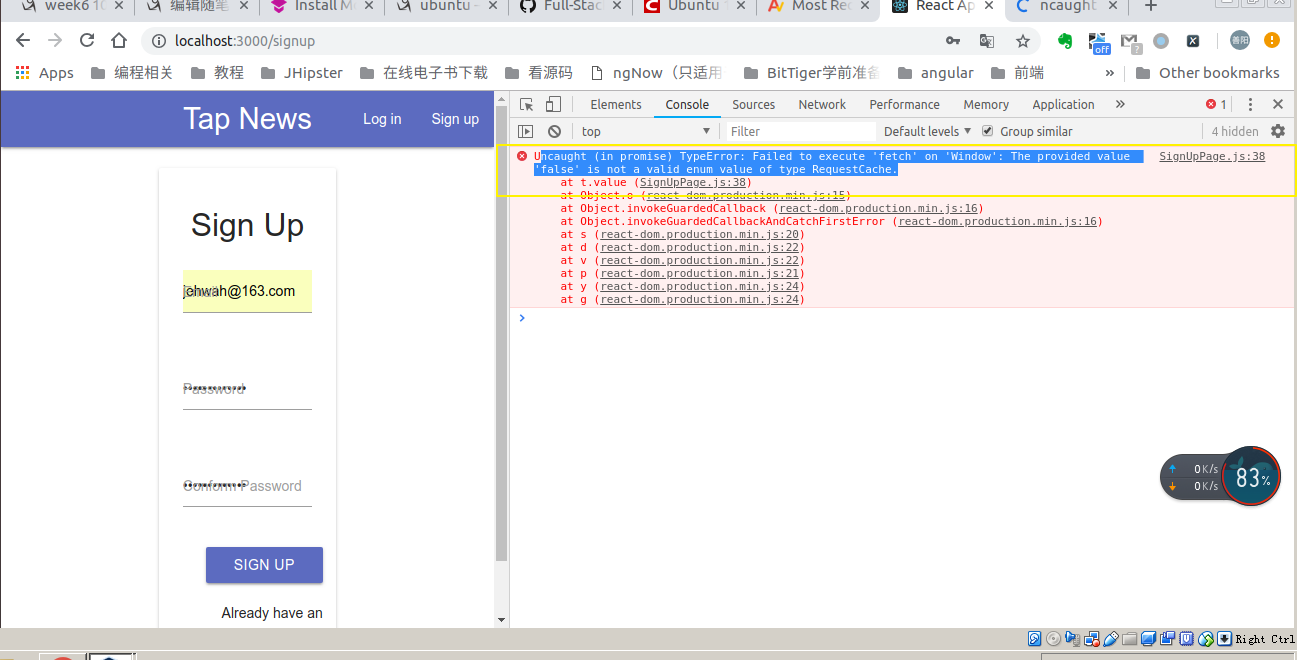
我们要改一下backendserver的service
因为要写几个api还要做很多操作
我们单独写出来 然后由service来调用



import json import os import pickle import random import redis import sys from bson.json_util import dumps from datetime import datetime # import common package in parent directory sys.path.append(os.path.join(os.path.dirname(__file__), '..', 'common')) import mongodb_client REDIS_HOST = "localhost" REDIS_PORT = 6379 # NEWS_TABLE_NAME = "news" NEWS_TABLE_NAME = "news-test" CLICK_LOGS_TABLE_NAME = 'click_logs' NEWS_LIMIT = 100 NEWS_LIST_BATCH_SIZE = 10 USER_NEWS_TIME_OUT_IN_SECONDS = 600 redis_client = redis.StrictRedis(REDIS_HOST, REDIS_PORT, db=0) def getNewsSummariesForUser(user_id, page_num): page_num = int(page_num) begin_index = (page_num - 1) * NEWS_LIST_BATCH_SIZE end_index = page_num * NEWS_LIST_BATCH_SIZE # The final list of news to be returned. sliced_news = [] if redis_client.get(user_id) is not None: news_digests = pickle.loads(redis_client.get(user_id)) # If begin_index is out of range, this will return empty list; # If end_index is out of range (begin_index is within the range), this # will return all remaining news ids. sliced_news_digests = news_digests[begin_index:end_index] print sliced_news_digests db = mongodb_client.get_db() sliced_news = list(db[NEWS_TABLE_NAME].find({'digest':{'$in':sliced_news_digests}})) else: db = mongodb_client.get_db() total_news = list(db[NEWS_TABLE_NAME].find().sort([('publishedAt', -1)]).limit(NEWS_LIMIT)) total_news_digests = map(lambda x:x['digest'], total_news) redis_client.set(user_id, pickle.dumps(total_news_digests)) redis_client.expire(user_id, USER_NEWS_TIME_OUT_IN_SECONDS) sliced_news = total_news[begin_index:end_index] for news in sliced_news: # Remove text field to save bandwidth. del news['text'] if news['publishedAt'].date() == datetime.today().date(): news['time'] = 'today' return json.loads(dumps(sliced_news))
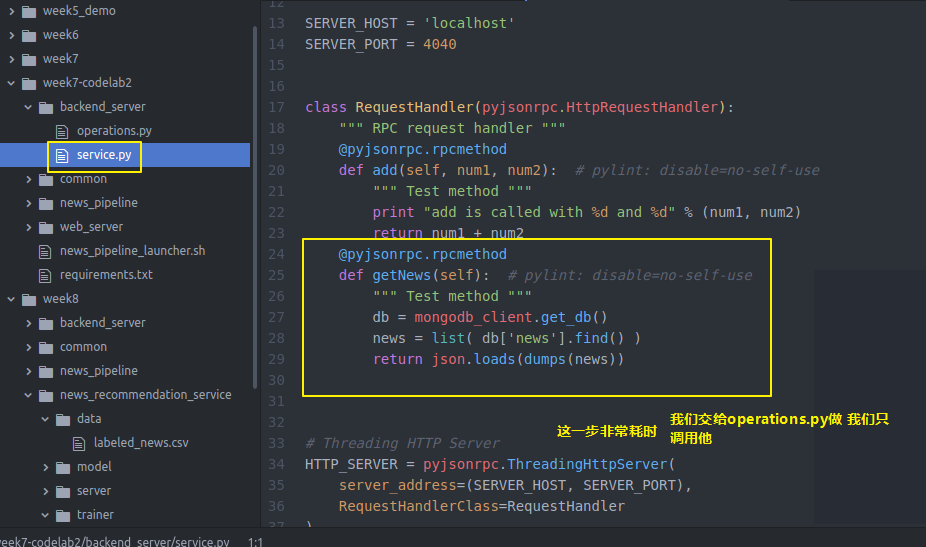

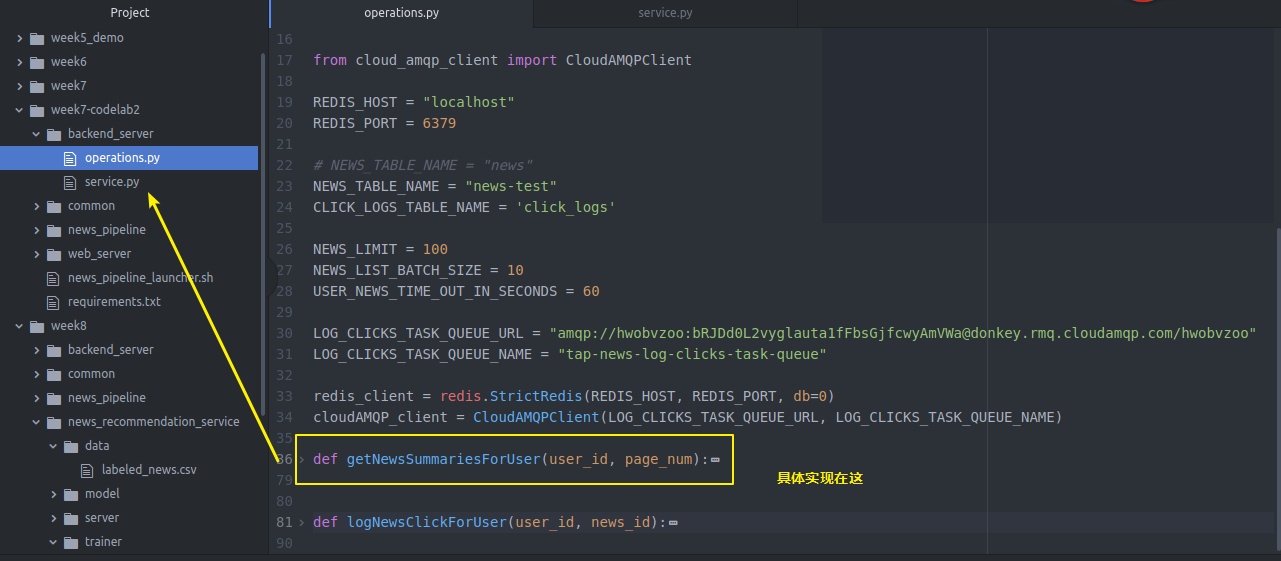
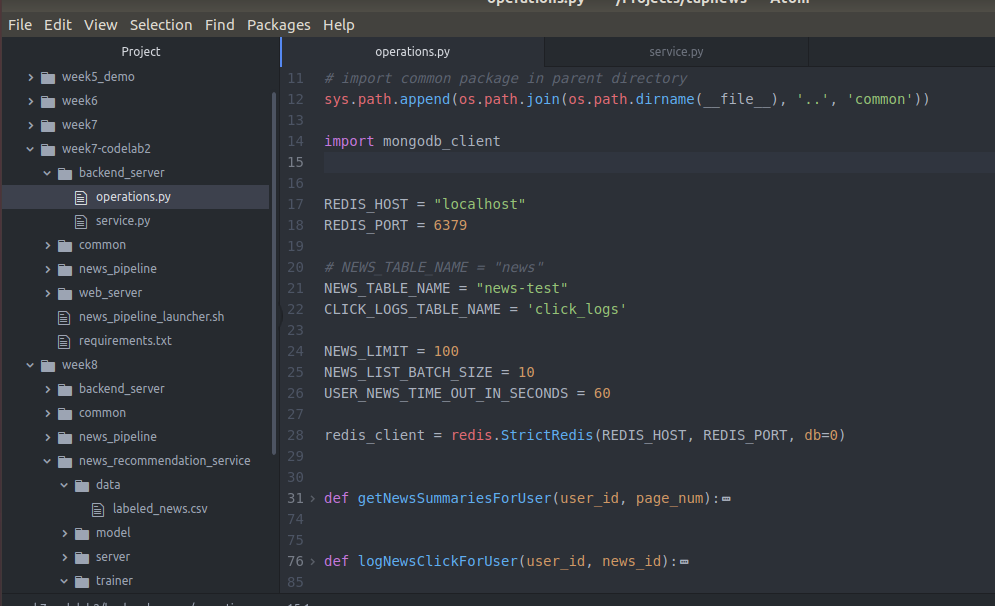
具体实现
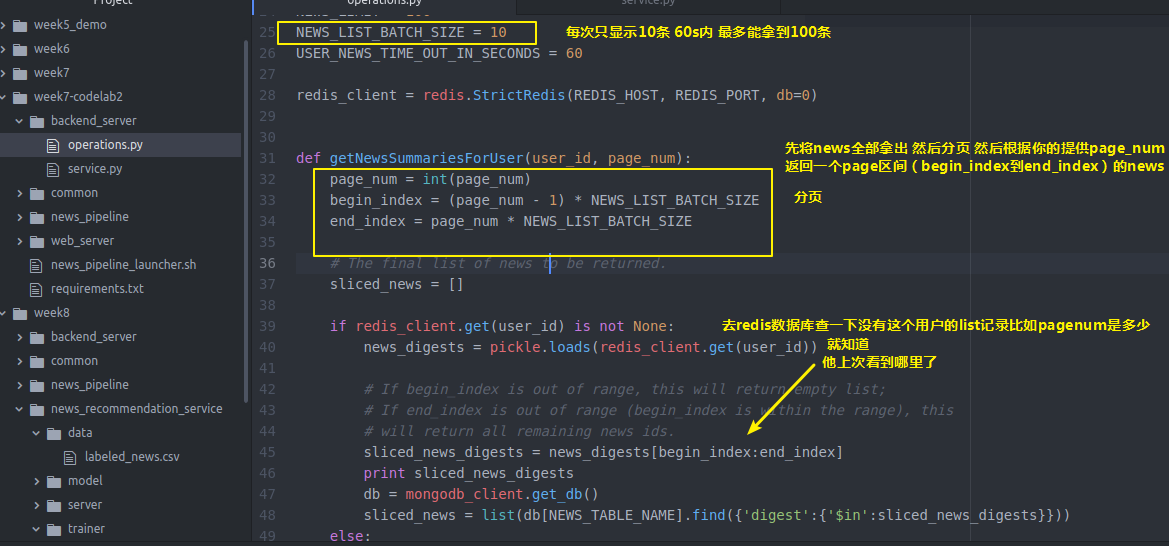
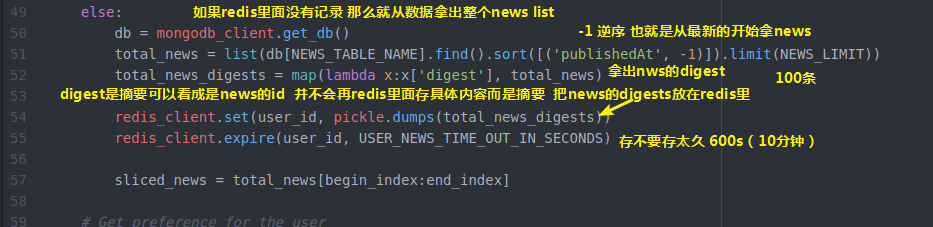
可以自己设置这个过期时间

我们都是下拉获得新闻 你也可以设计一个向上拉强制刷新的功能 比如向上拉触发一个函数cleanRedis来强制清空redis(类似新浪知乎)这样 即使100条获取完了没得获取了
也能强制刷新列表(之后写吧)
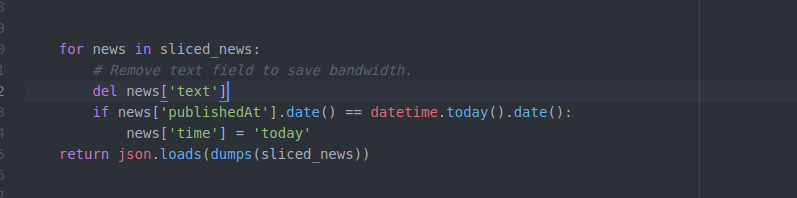
import json import os import pickle import random import redis import sys from bson.json_util import dumps from datetime import datetime # import common package in parent directory sys.path.append(os.path.join(os.path.dirname(__file__), '..', 'common')) import mongodb_client REDIS_HOST = "localhost" REDIS_PORT = 6379 # NEWS_TABLE_NAME = "news" NEWS_TABLE_NAME = "news-test" CLICK_LOGS_TABLE_NAME = 'click_logs' NEWS_LIMIT = 100 NEWS_LIST_BATCH_SIZE = 10 USER_NEWS_TIME_OUT_IN_SECONDS = 600 redis_client = redis.StrictRedis(REDIS_HOST, REDIS_PORT, db=0) def getNewsSummariesForUser(user_id, page_num): page_num = int(page_num) begin_index = (page_num - 1) * NEWS_LIST_BATCH_SIZE end_index = page_num * NEWS_LIST_BATCH_SIZE # The final list of news to be returned. sliced_news = [] if redis_client.get(user_id) is not None: news_digests = pickle.loads(redis_client.get(user_id)) # If begin_index is out of range, this will return empty list; # If end_index is out of range (begin_index is within the range), this # will return all remaining news ids. sliced_news_digests = news_digests[begin_index:end_index] print sliced_news_digests db = mongodb_client.get_db() sliced_news = list(db[NEWS_TABLE_NAME].find({'digest':{'$in':sliced_news_digests}})) else: db = mongodb_client.get_db() total_news = list(db[NEWS_TABLE_NAME].find().sort([('publishedAt', -1)]).limit(NEWS_LIMIT)) total_news_digests = map(lambda x:x['digest'], total_news) redis_client.set(user_id, pickle.dumps(total_news_digests)) redis_client.expire(user_id, USER_NEWS_TIME_OUT_IN_SECONDS) sliced_news = total_news[begin_index:end_index] for news in sliced_news: # Remove text field to save bandwidth. del news['text'] if news['publishedAt'].date() == datetime.today().date(): news['time'] = 'today' return json.loads(dumps(sliced_news))
上面代码提到的比如 lamda表达式配合map摘取新闻中的digest字段

还有pickle对字符串序列化和反序列化
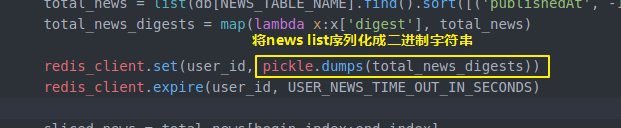

配合使用
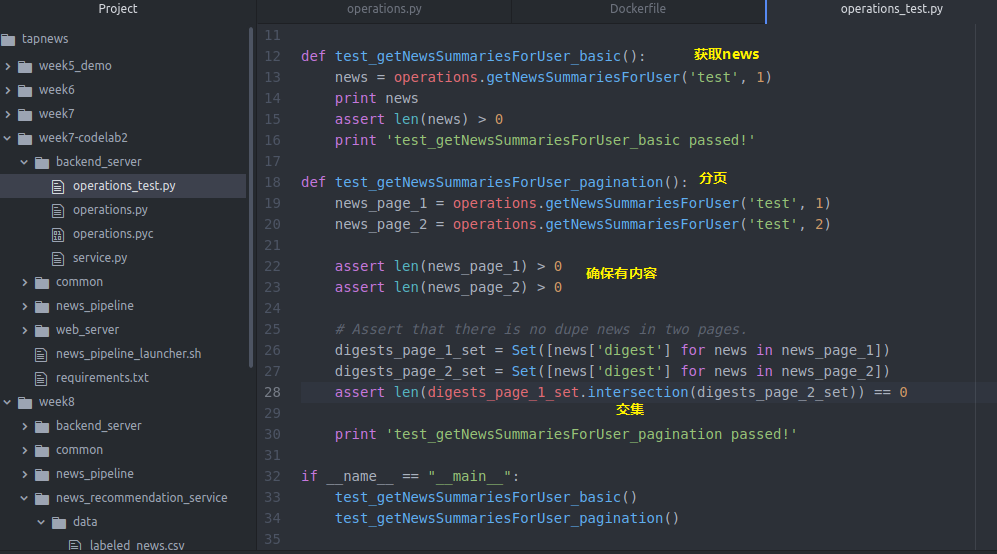
我们写个test

import operations import os import sys from sets import Set # import common package in parent directory sys.path.append(os.path.join(os.path.dirname(__file__), '..', 'common')) # Start Redis and MongoDB before running following tests. def test_getNewsSummariesForUser_basic(): news = operations.getNewsSummariesForUser('test', 1) print news assert len(news) > 0 print 'test_getNewsSummariesForUser_basic passed!' def test_getNewsSummariesForUser_pagination(): news_page_1 = operations.getNewsSummariesForUser('test', 1) news_page_2 = operations.getNewsSummariesForUser('test', 2) assert len(news_page_1) > 0 assert len(news_page_2) > 0 # Assert that there is no dupe news in two pages. digests_page_1_set = Set([news['digest'] for news in news_page_1]) digests_page_2_set = Set([news['digest'] for news in news_page_2]) assert len(digests_page_1_set.intersection(digests_page_2_set)) == 0 print 'test_getNewsSummariesForUser_pagination passed!' if __name__ == "__main__": test_getNewsSummariesForUser_basic() test_getNewsSummariesForUser_pagination()
下面我们来运行一下



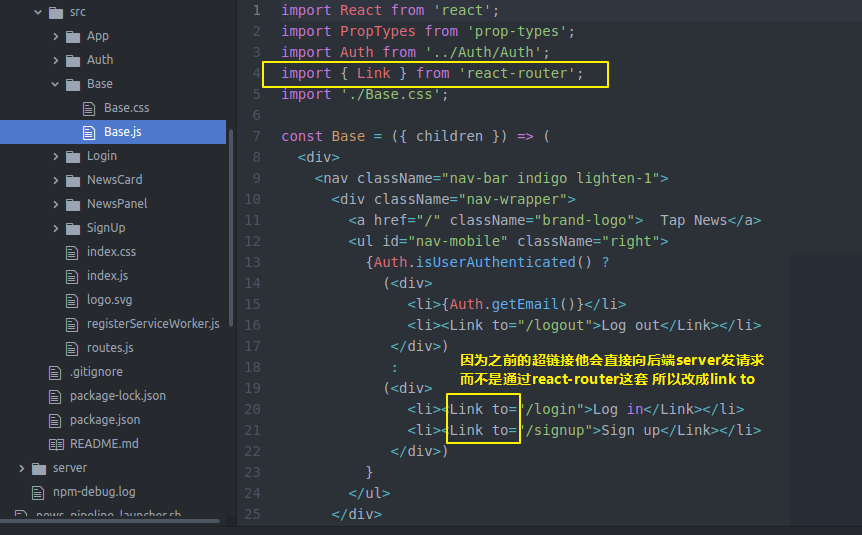
后端api完成让那个了
没回到前端webserver的client的Base
将原来的超链接换成router的link to
同理 loginForm也要修改

signup也是.

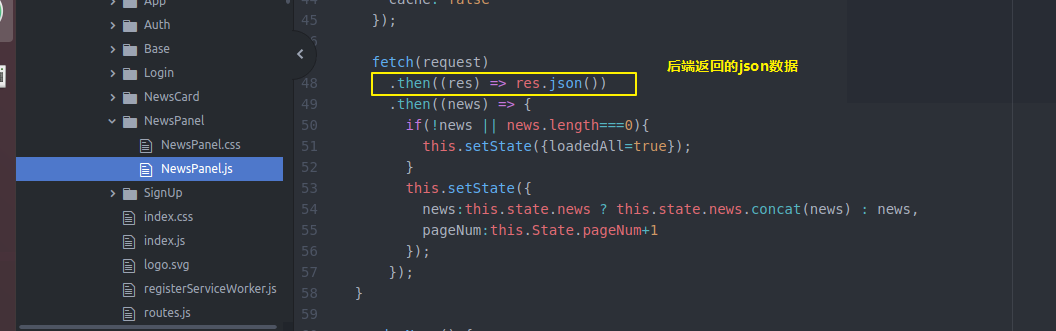
然后还要在NewsPannel做一些工作 之前比较简单 只是state保存一些信息 通过loadmorenews获得更多news
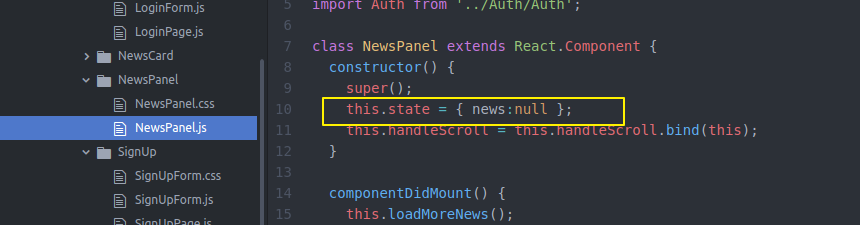
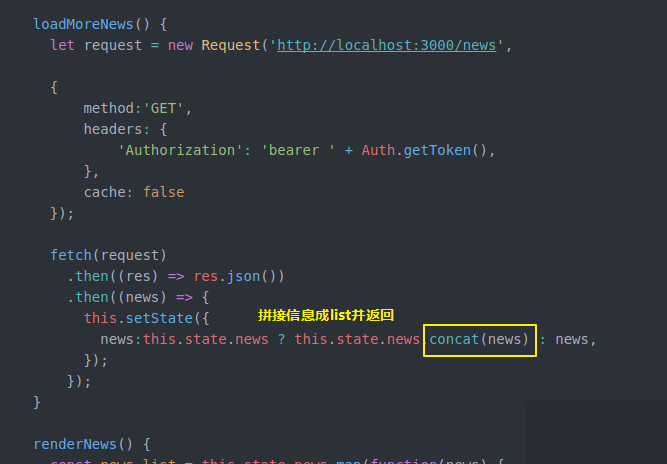
现在我们state除了这些 还要记录分页 总页数 加载完没有
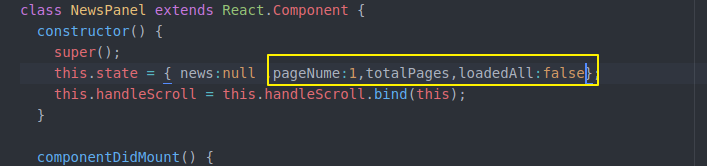
然后loadmorenews

然后做个判断

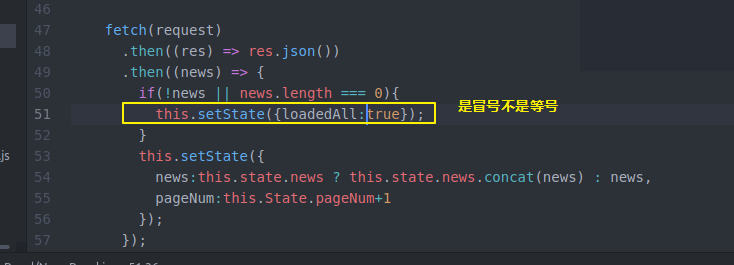
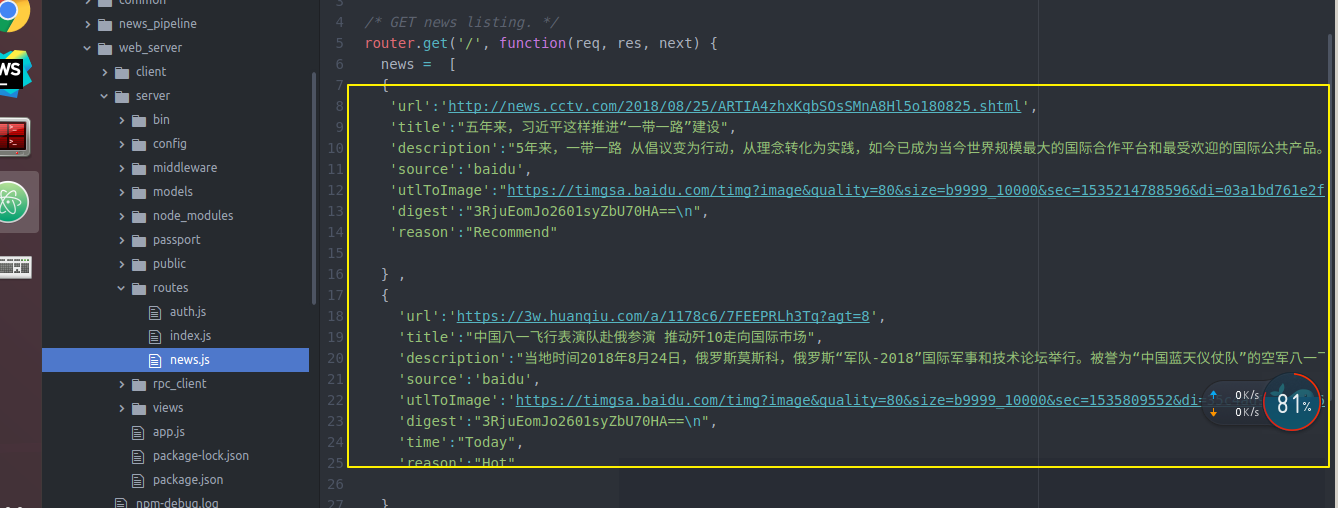
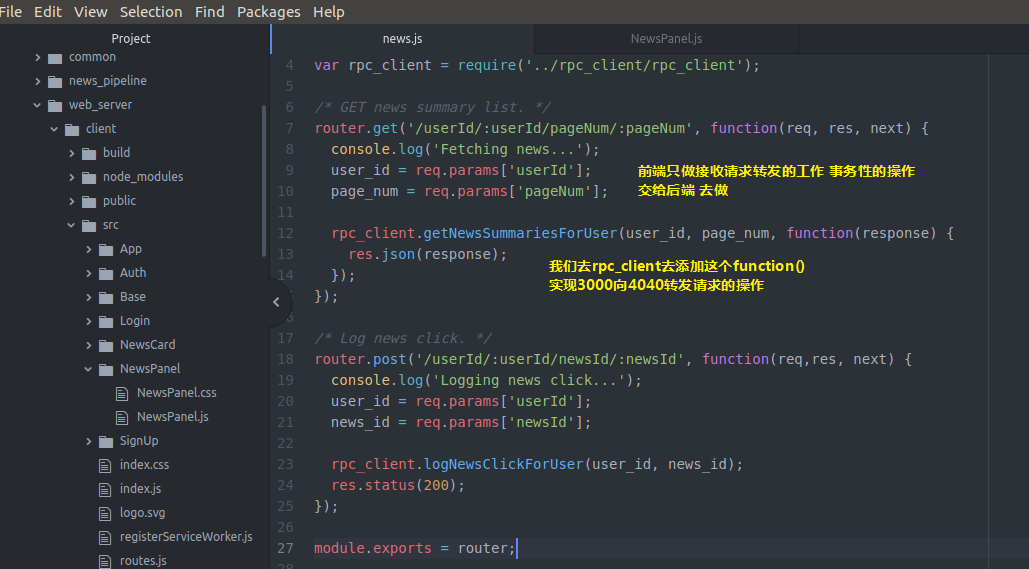
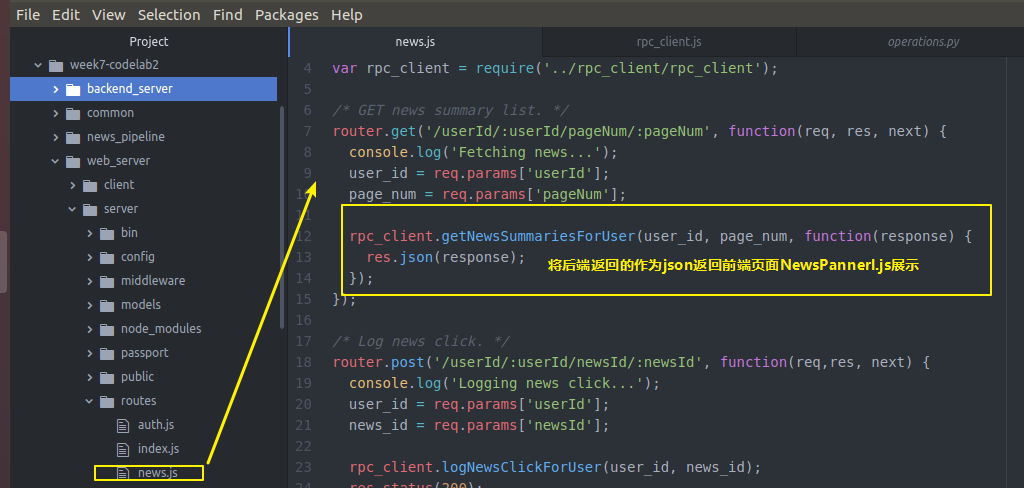
然后 还记得我们的获取新闻的api对象的webserver的server端的news.js是临时数据
news.js吗 我们去修改一下 让他从真正的后端backendserver从数据库拿数据
var express = require('express'); var router = express.Router(); var rpc_client = require('../rpc_client/rpc_client'); /* GET news summary list. */ router.get('/userId/:userId/pageNum/:pageNum', function(req, res, next) { console.log('Fetching news...'); user_id = req.params['userId']; page_num = req.params['pageNum']; rpc_client.getNewsSummariesForUser(user_id, page_num, function(response) { res.json(response); }); }); /* Log news click. */ router.post('/userId/:userId/newsId/:newsId', function(req,res, next) { console.log('Logging news click...'); user_id = req.params['userId']; news_id = req.params['newsId']; rpc_client.logNewsClickForUser(user_id, news_id); res.status(200); }); module.exports = router;

所以我们回去带上这两个参数
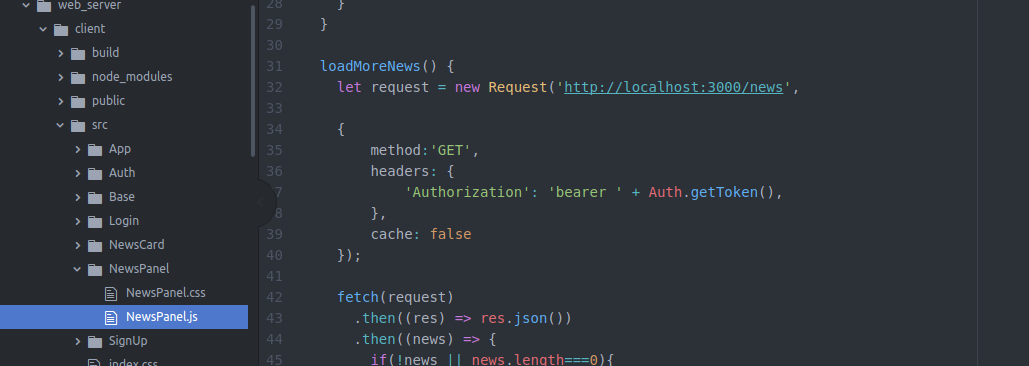
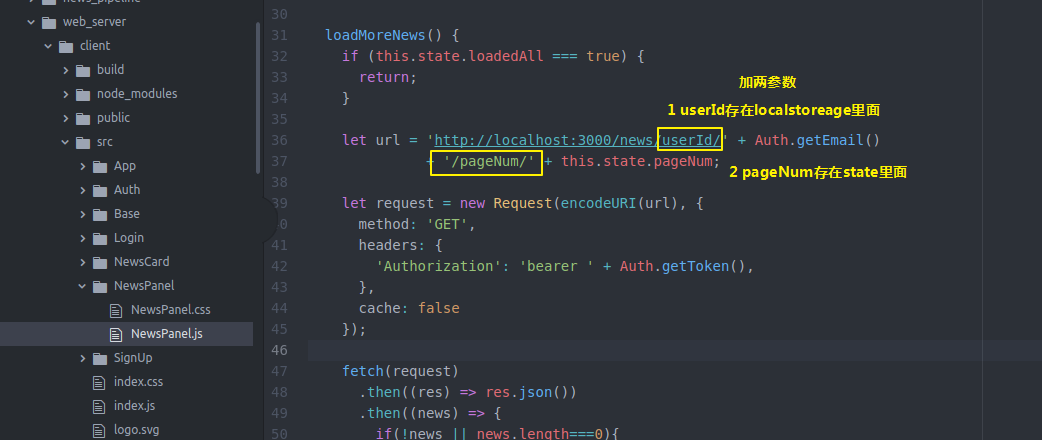
ok
再回到webserver server去
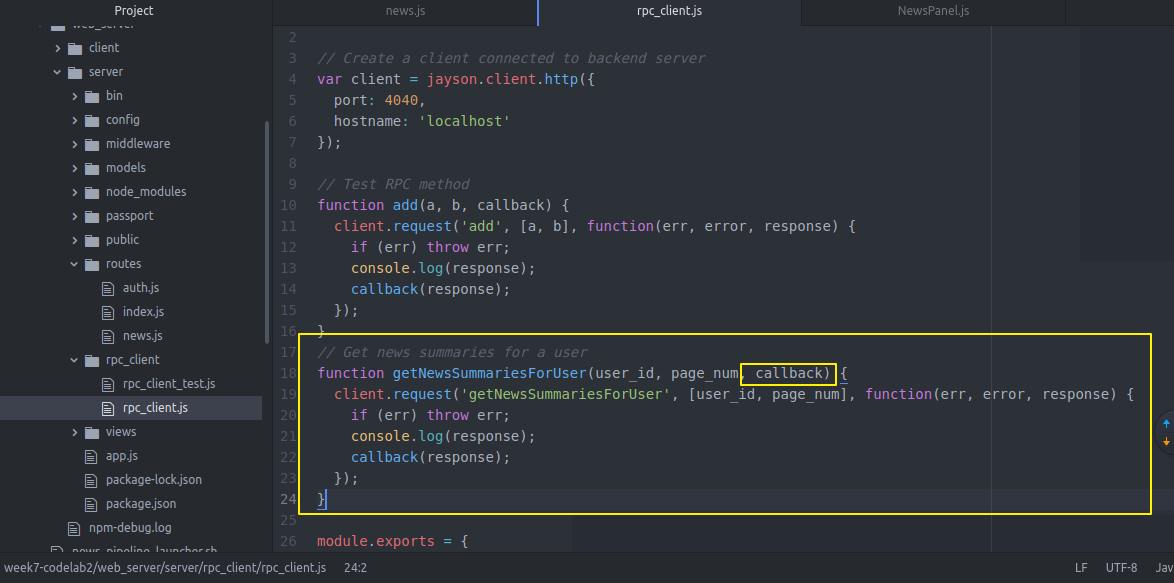
然后我们的真正的后端backend server
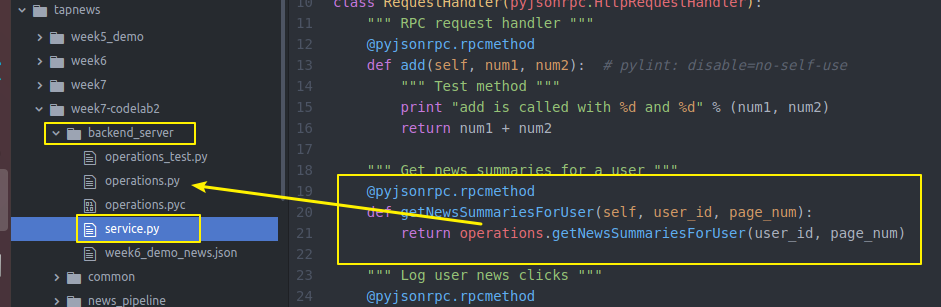
具体实现
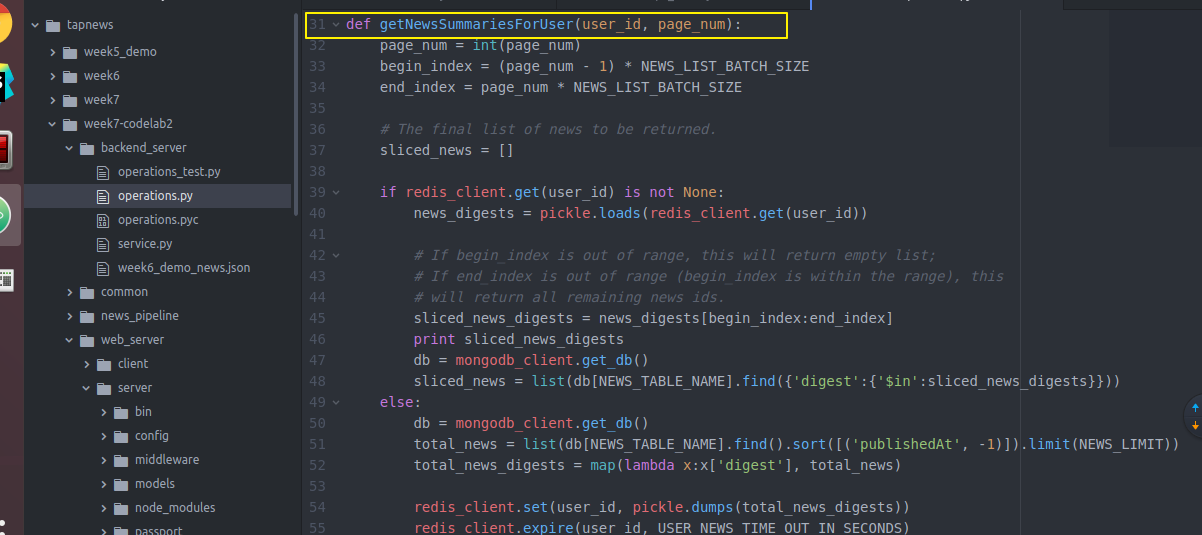
等这些操作完成后又回到web server的server去了
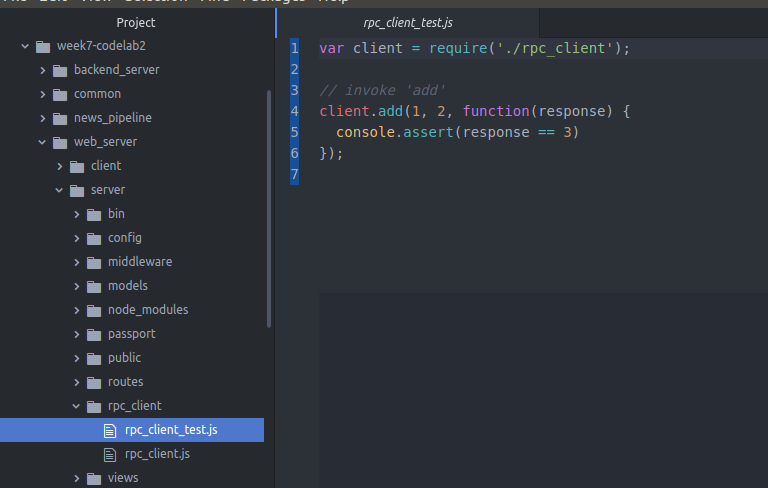
我们洗个test验证一下
我们先将后端骑起来
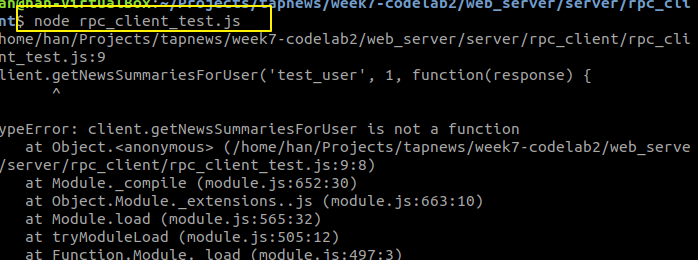
他说找不到这个方法
我们去看看
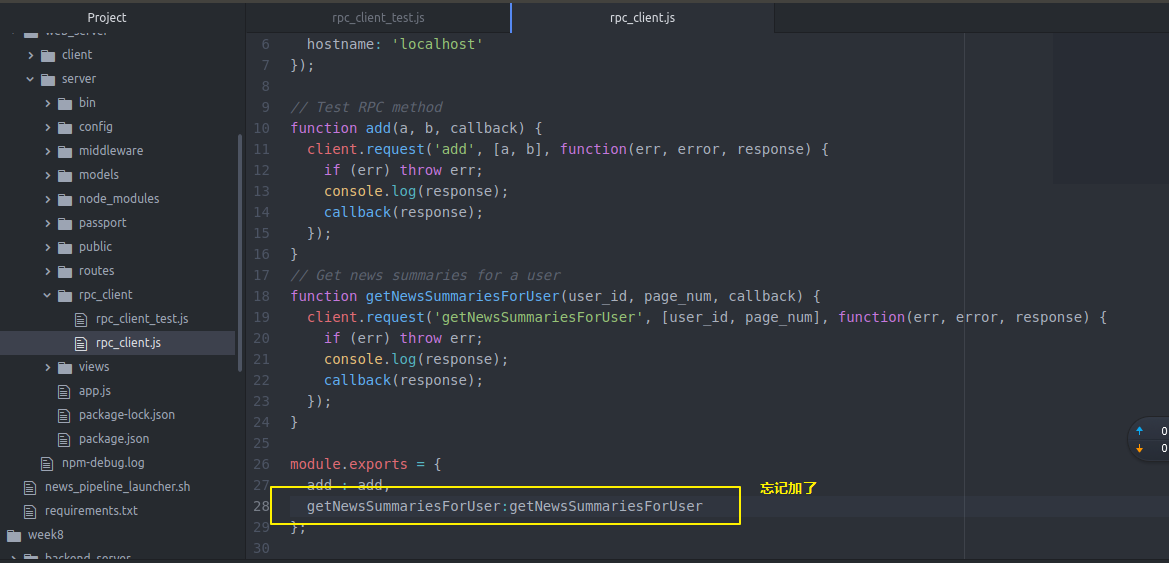
在运行
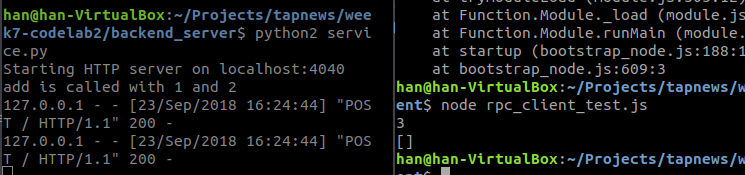
返回空 因为没有这个userid
下面前端和后端调通(从网页上看到效果)
首先在web server的client先build一下(将前端页面文件传到build文件中)
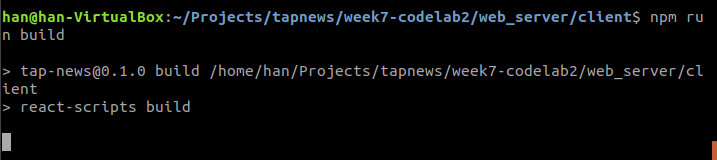
然后去server 起一个端口 npm start 就可以只开一个端口来调试了