今天写第二个递归算法——快速排序。
快排介绍:
今天介绍快速排序,这也是在实际中最常用的一种排序算法,速度快,效率高。就像名字一样,快速排序是最优秀的一种排序算法。
思想
快速排序采用的思想是分治思想。
快速排序是找出一个元素(理论上可以随便找一个)作为基准(pivot),然后对数组进行分区操作,使基准左边元素的值都不大于基准值,基准右边的元素值 都不小于基准值,如此作为基准的元素调整到排序后的正确位置。递归快速排序,将其他n-1个元素也调整到排序后的正确位置。最后每个元素都是在排序后的正 确位置,排序完成。所以快速排序算法的核心算法是分区操作,即如何调整基准的位置以及调整返回基准的最终位置以便分治递归。




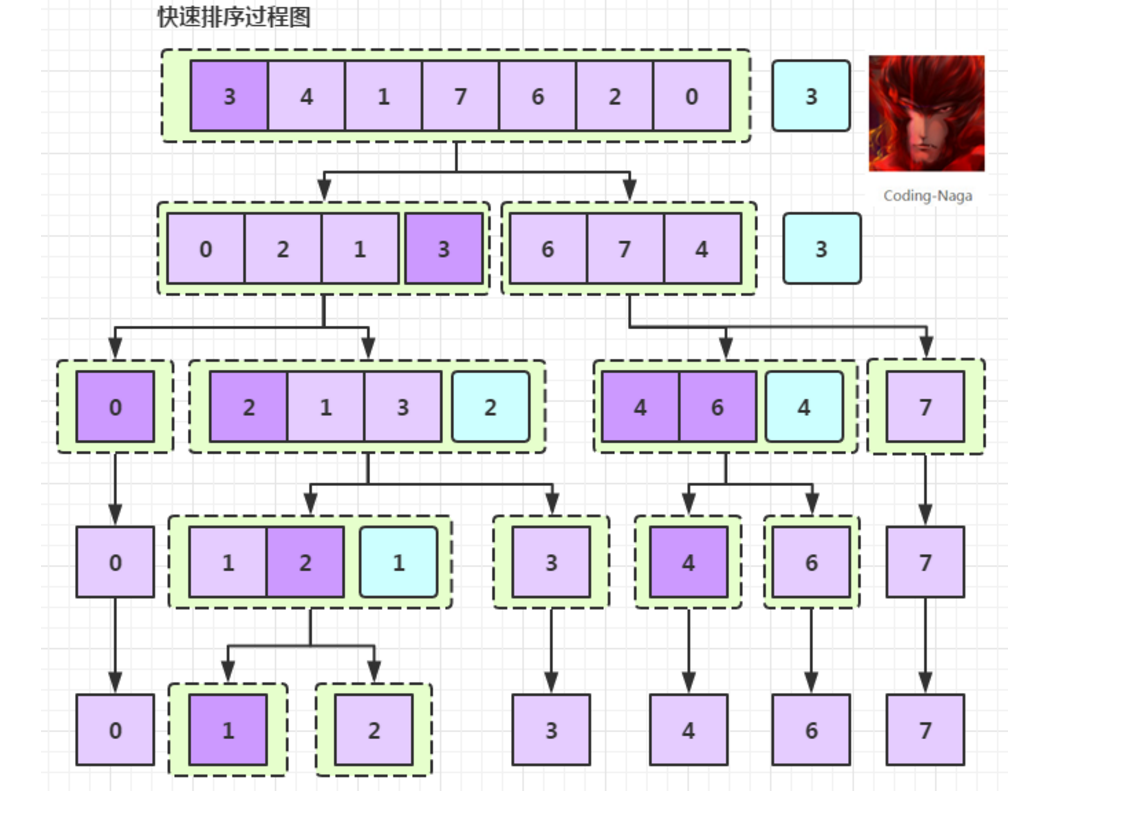
简单来说————快排就是取一串数字的第一个数的数值为基数(用key=arr[left],记录下来),然后取low与high两个变量分别指向开始和结尾。之后high--,找到比第一个数key小的数字,然后与赋值到arr[low]这个位置(因为high这个位置的这个数<key,而我们的目标是将数组以key的值为中点把各个数分成大于key和小于key的两部分,所以把第一个数覆盖掉)--不过应该会有同学纳闷,如果我覆盖了这里的这个数字,那么我不就少了一个数字吗?其实这里不用担心,在我们程序的最后会把最后一个属于key的那个位置赋值为key。同理,low这个位置应该++,找比key大的数,若有的话把arr[high]=arr[low]。
文字解释有点复杂,下面我们支教上代码:
int quick(int v[],int left,int right){ if(left<right){//这个条件不能少,相当于一个跳出条件,如果当left>right时,程序是不向下进行的。 int key=v[left]; int low = left; int high= right;//key就是我们上面所说的那个支点,有了这个支点后我们根据这个支点的数的大小分组了(都是选择当前数列第一个数为支点) while(low<high){//这个判断条件不能丢,因为你是要把当前数组中所有的数都要跑一遍。 while(low<high&&v[high]>key){ high--; }//向后移位去找“放错位置”的数 if(low<high) { v[low]=v[high];low++; }//low这里赋值,相当于此时high这里的数是多余的。然后low这里就不用在判读了,直接++. while(low<high&&v[low]<=key){ low++; } if(low<high) { v[high]=v[low];high--; } }//low这里与high情况相同。 v[low]=key;//这一句话就是用来解释不断赋值后肯定有一个数没有放进来,这个数就是开始的那个arr[left],此时这个是数就要放到属于它应该在的位置low处了(因为最后是low处的值放到了high处) quick(v,left,low-1); quick(v,low+1,right);//递归---以当前问题的支点为分界线,将问题分为两个小问题。 } }
快排时间复杂度: 在这里我们知道快排的时间复杂度不固定,当问题恰巧第一个数是最大的时候,那意味着每一次我都要移动n-1个数。此时时间复杂度为 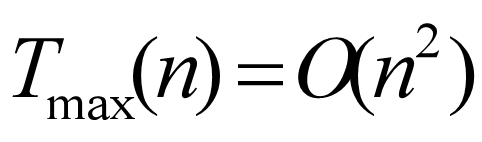
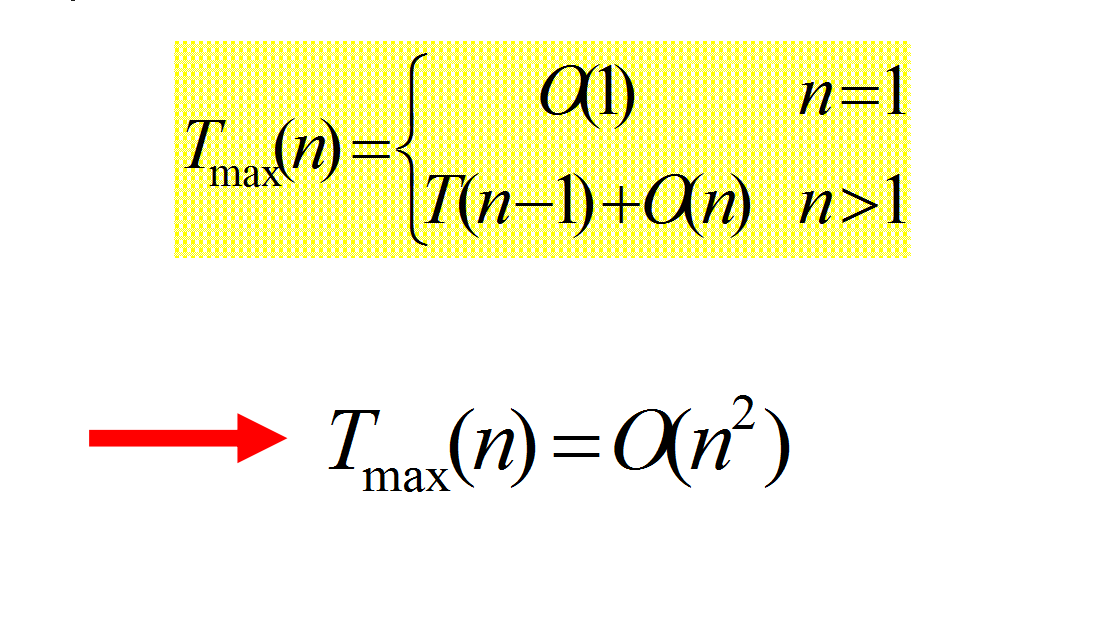
而一般来说,快排的平均时间复杂度和合并排序一样,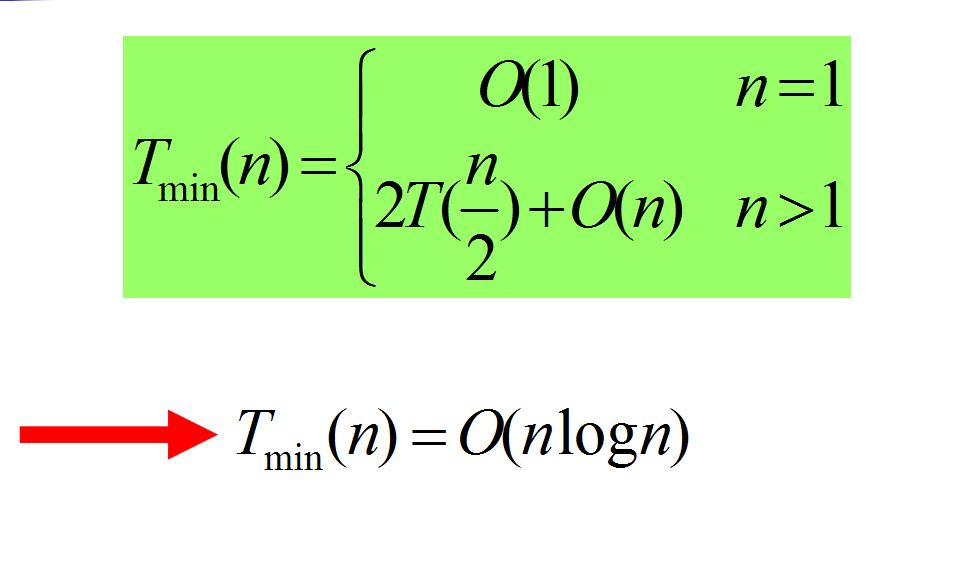
但是经过实验,快排的效率的确要大于合并排序。具体的原因大家可以查一查资料,研究一下。。。
快排就到这里,,有什么不妥的地方希望指出。我改正。
————————————————————————————————————————————————Made By Pinging