原想法:通过遍历找出每个位点可能出现的单词的列表,然后通过dfs遍历找出所有的组合,有点类似于之前刷pat时用的dijstra+dfs,代码如下
class Solution {
List<String>[]startWordList;
List<String>words=new ArrayList<>();
List<String>result=new ArrayList<>();
public void dfs(int cursor,int length){
if(cursor>length){
return;
}else if(cursor==length){//这种情况即找到了结果
String res="";
for(int i=0;i<words.size();i++){
if(i==0){
res=res+words.get(i);
}else {
res=res+" "+words.get(i);
}
}
result.add(res);
return;
}
for(String word:startWordList[cursor]){
words.add(word);
dfs(cursor+word.length(),length);
words.remove(words.size()-1);
}
}
public List<String> wordBreak(String s, List<String> wordDict) {
startWordList=new List[s.length()];
for(int i=0;i<startWordList.length;i++){
startWordList[i]=new ArrayList<>();
}
//先通过循环搜索出所有开始点可能出现的单词
for(int i=0;i<s.length();i++){
for(int j=i;j<=s.length();j++){
String sub=s.substring(i,j);
for(String word:wordDict){
if(word.equals(sub)){
startWordList[i].add(word);
}
}
}
}
dfs(0,s.length());
return result;
}
}
全是a的那个点运行超时了。
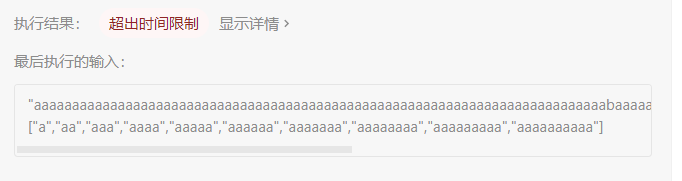
优化:记忆化搜索
标注不能达到终点的点,当每一次搜索结束后返回true or false,发现某个点不可达后将其哈希表中对应项标注,此后回溯后再次经过此点时则直接跳过。代码如下:
```class Solution {
List<String>[]startWordList;
List<String>words=new ArrayList<>();
List<String>result=new ArrayList<>();
boolean[]cantAchieve;//记录某个点是否能达到终点
public boolean dfs(int cursor,int length){
if(cursor>length){
return false;
}else if(cursor==length){//这种情况即找到了结果
String res="";
for(int i=0;i<words.size();i++){
if(i==0){
res=res+words.get(i);
}else {
res=res+" "+words.get(i);
}
}
result.add(res);
return true;
}
if (cantAchieve[cursor]==false) {
boolean find=false;
for(String word:startWordList[cursor]){
words.add(word);
boolean ok=dfs(cursor+word.length(),length);
words.remove(words.size()-1);
if(ok==true){
find=ok;
}
}
if(find==false){
cantAchieve[cursor]=true;
}
return find;
}else{
return false;
}
}
public List<String> wordBreak(String s, List<String> wordDict) {
startWordList=new List[s.length()];
cantAchieve=new boolean[s.length()];
for(int i=0;i<startWordList.length;i++){
startWordList[i]=new ArrayList<>();
}
//先通过循环搜索出所有开始点可能出现的单词
for(int i=0;i<s.length();i++){
for(int j=i;j<=s.length();j++){
String sub=s.substring(i,j);
for(String word:wordDict){
if(word.equals(sub)){
startWordList[i].add(word);
}
}
}
}
dfs(0,s.length());
return result;
}
}