1.功能概述
1.1 图像分类功能概述
在遥感技术的应用中,对资源分布、自然灾害、区域环境等的监测和分析依附于遥感图像分类。而遥感图像分类是进行图像信息提取的有效手段。随着遥感技术的的不断改进,各领域对遥感图像分类方法的要求越来越高,主要表现在以下几个方面:
- 分类结果的精确性:各领域对分类结果的精度要求越来越高。
- 分类速度的时效性:随着近年来遥感数据的快速增长,项目中往往需要进行海量遥感数据的快速处理。遥感图像分类属于大规模机器学习,数据量大导致运算量很大。另外,人们在追求高精度的同时,计算复杂度也随之增加,这对遥感应用的时效性提出了很高的要求。
- 分类方法使用的便捷性:解译人员对分类算法的分类行为难以理解,无法准确了解参数设置与分类结果之间的关联性,需要将分类器的行为转化为易于理解的符号规则,把遥感影像的内在特征和规律显示出来。
1.2 监督分类功能特点
遥感图像分类实现的主要方法包括监督分类和非监督分类。其中监督分类作为一种先学习后分类的机器学习策略,利用像元光谱特征的相似性进行分类,具有较高的分类精度,是对遥感图像进行信息提取的主要手段。
监督分类功能特点包括:
- 充分利用分类地区的先验知识,有目的的选择分类类别;
- 通过对样本的反复检验和训练,提高分类成果的可靠性,出现严重错误的几率较低;
- 分类速度相对较快,分类精度较高;
- 人为主观性比较强,获取合格的样本比较费时费力。
分类方法 | 优点 | 缺点 | 适用范围 |
监督分类 | 精确度高,准确性好,与实际类别吻合较好 | 工作量大 | 有先验知识时使用该方法 |
非监督分类 | 工作量小易于实现 | 分类结果与实际类别相差较大,准确性差 | 在没有类别先验知识时使用该方法 |
在实际应用中监督分类精度要高于非监督分类,更适用于遥感图像的精细化分类,非监督分类可应用于分类精细化程度不高的快速分类的场景中。
1.3 监督分类应用
在目前的遥感图像分类的应用中,传统模式识别的监督分类方法,诸如最小距离、最大似然法等,能够满足应用人员对大区域遥感影像的快速分类处理需求。可以为行业用户提供一种信息提取的解决方案,已广泛在农业、林业、水资源、地质环境调查、环境保护、土地利用、城市规划等领域。
但是监督分类由于单一地依靠地物的光谱特征进行分类,由于受到遥感影像本身的空间分辨率及"同物异谱""异物同谱"现象存在,导致分类精度不高,因此对某些地区,某些地物需要对分类器加以改进或者与其他分类方法结合使用来提高分类精度。
2.基本概念
2.1 训练样本
定义:
- 训练样本用来确定图像中已知类别像素的特征。建立训练样本之前首先要根据工作要求,收集研究区域的相关资料,包括DEM、土地利用覆盖图、植被覆盖图、行政区划图等。根据这些资料,确定分类对象和分类系统。
训练样本的选取:
- 根据系统分类要求,在遥感图像上用人机交互的方式勾绘各种典型地物的分布范围,即训练样本。
训练区的选取注意事项:
- 训练样本必须具有典型性和代表性。同一类别的训练样本的光谱特征必须是均一的,不能包含其他类别或者混合像元。
- 应分散的选取训练样本,不要太集中。目的是使每一类别的训练样本都具有一定的代表性。
- 训练样本的数量。作为一个普遍的规则,如果图像有N波段,则每一类别至少应该有10N个训练样本。
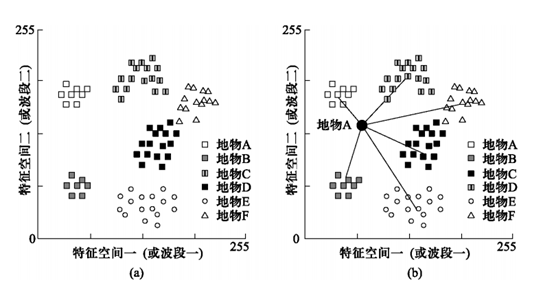
2.2 监督分类方法-最小距离法
定义:
- 利用训练样本中各类别在各波段上的均值,根据各像元与训练样本平均值距离的大小来决定其类别。哪类别集群中心离它"最近",该像素就属于哪个类别。
2.3 监督分类方法-马氏距离法
定义:
- 马氏距离是一种加权的欧式距离,它以协方差的倒数作为权重,协方差越大表示距离越短,因此马氏距离表示数据的协方差距离。
马氏距离的优点:
- 它不受量纲的影响,两点之间的马氏距离与原始数据的测量单位无关,马氏距离还可以排除变量之间的相关性的干扰。
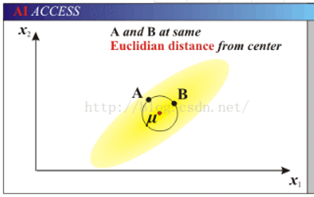
欧式距离
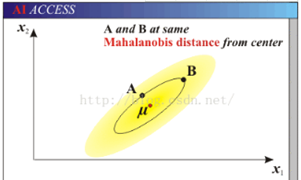
马氏距离
2.4 监督分类方法-最大似然法
示例:
- 现在我们有两个盒子:甲和乙,每个里面都装了100个球,其中甲中装了95个红球,5个蓝球,乙中装了20个红球,80个蓝球,现在有人从盒子里面取出了一个球,发现是红球,然后让你猜:"他是从哪个盒子里面取出来的?",想必你会猜"甲"吧。

定义:
- 首先定义一个从属于某种类别的概率分布集群,然后把待分类像元落入各类别的条件概率作为判别函数, 将像元落入某类别的条件概率最大的类定义为该像元的类别。

最大似然法确定概率密度函数
最大似然法假设遥感图像的每个波段数据都为标准正态分布,条件概率的计算转化为求取正态分布的概率密度函数 f(x)的值。
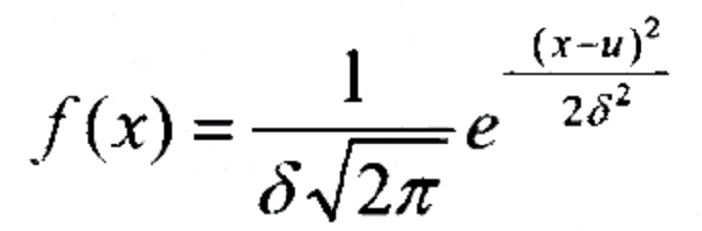
μ:均值
δ:方差
2.5 混淆矩阵
混淆矩阵(confusion matrix):是一个用于表示分为某一类别的像元个数与地面检验为该类别数的比较阵列。
图像类别 | 参考类 | ||||
X | Y | Z | 行和 | 用户精度 | |
X | A | E | F | G | A/G |
Y | B | I | Z | M | I/M |
Z | C | Y | J | O | J/O |
列和 | D | P | Q | N | |
生产者精度 | A/D | I/P | J/Q | ||
用户精度:是指正确分到X类的像元总数(对角线值)与分类器将整个影像的像元分为X类的像元总数(混淆矩阵中X类行的总和)比率。用户精度 = A / G。用来表示分类结果中,各类别的可信度,整张分类成果的可靠性。
生产者精度:指分类器将整个影像的像元正确分为A类的像元数(对角线值)与A类真实参考总数(混淆矩阵中A类列的总和)的比率。生产者精度= A / D。用于比较分类方法的好坏。
总体分类精度:指被正确分类的类别像元数与总的类别个数的比值。总体分类精度= A + I + J / N。
2.6 Kappa系数
kappa系数是一种衡量分类精度的指标。它是通过把所有地表真实分类中的像元总数(N)乘以混淆矩阵对角线(Xii)的和,再减去某一类地表真实像元总数与该类中被分类像元总数之积对所有类别求和的结果,再除以总像元数的平方减去某一类地表真实像元总数与该类中被分类像元总数之积对所有类别求和的结果所得到的。

N:地表真实分类中的像元总数.
xii:正确分类的数量(对角线上的数值)
Xi+:i类分类像元总数(行)
X+i:i类真实像元总数(列)
图像类别 | 参考类 | |||
X | Y | Z | 行和 | |
X | A | E | F | G |
Y | B | I | Z | M |
Z | C | Y | J | O |
列和 | D | P | Q | N |
Kappa系数= [ N*(A+I+J)-(D*G+P*M+Q*O) ] / [ N2 -(D*G+P*M+Q*O) ]
Kappa系数 | 分类质量 |
<0 | 很差 |
0-0.2 | 差 |
0.2-0.4 | 一般 |
0.4-0.6 | 好 |
0.6-0.8 | 很好 |
0.8-1.0 | 极好 |
Kappa系数与分类精度关系
3.操作演示
使用数据:
高分2号多光谱数据,监督分类.img
操作流程:
监督分类总体上可以分为4个过程:
定义训练样本→执行监督分类→评价分类结果→分类后处理
其中评价分类结果和分类后处理的顺序可以根据实际情况进行调整。
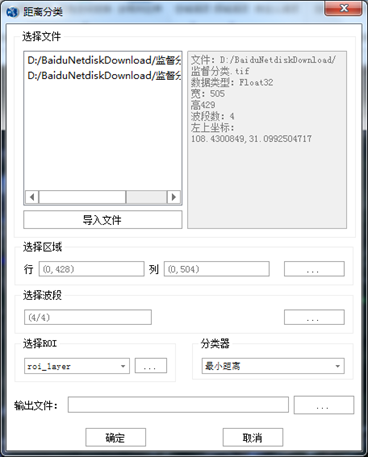
3.1 距离分类
打开PIE-Basic软件,在"图像处理"标签下的"图像分类"组,单击【监督分类】按钮下的下拉箭头,选择【距离分类】,打开【距离分类】对话框:
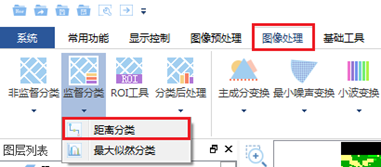

- 参数设置:
- 【选择文件】选择需要分类的数据;
- 【导入文件】如果待分类影像不在文件列表中,可以通过单击【导入文件】,添加待处理影像到文件列表中;
- 【选择区域】中设置待分类处理的区域,这里默认对裁剪出来的数据进行全图分类;
- 【选择波段】中选择需要分类的波段,默认是全部波段参与分类;
- 【选择ROI】中选择ROI文件,这里会自动读取制作的ROI样本文件;
- 【分类器】中设置监督分类规则(最小距离或马氏距离)。
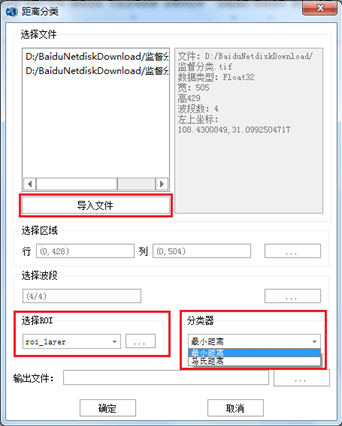
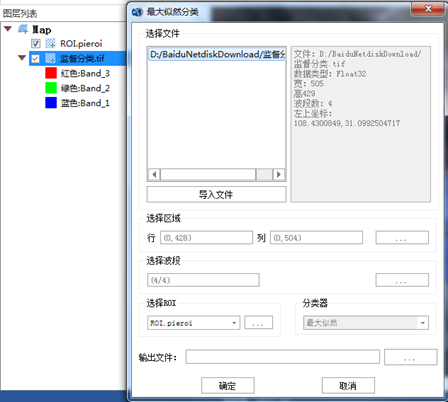
3.2 最大似然分类
打开PIE-Basic软件,在"图像处理"标签下的"图像分类"组,单击【监督分类】按钮下的下拉箭头,选择【最大似然分类】,打开【最大似然分类】对话框:
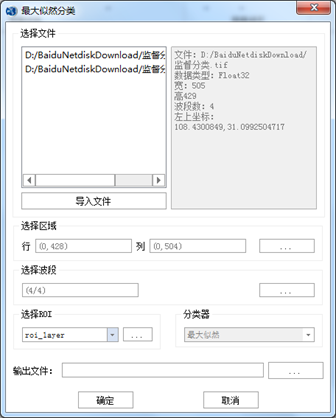
- 参数设置:
- 【选择文件】选择需要分类的数据;
- 【导入文件】如果待分类影像不在文件列表中,可以通过单击【导入文件】,添加待处理影像到文件列表中;
- 【选择区域】中设置待分类处理的区域,这里默认对裁剪出来的数据进行全图分类;
- 【选择波段】中选择需要分类的波段,默认是全部波段参与分类;
- 【选择ROI】中选择ROI文件,这里会自动读取制作的ROI样本文件;
- 【分类器】中设置监督分类规则-最大似然分类算法;
- 【输出文件】设置输出影像的保存路径和名称。

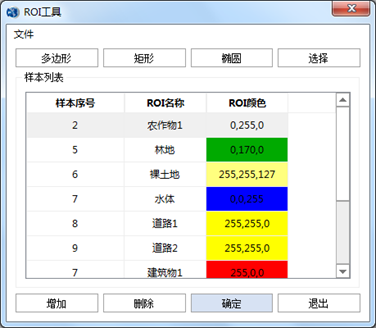
3.3 ROI工具
打开PIE-Basic软件,在"图像处理"标签下的"图像分类"组,单击【ROI工具】,打开【 ROI工具】对话框:
3.4分类后处理
监督分类和非监督分类等分类方法得到的一般是初步结果,难于达到最终的应用目的。因此,需要对初步的分类结果进行一些处理,才能得到满足需求的分类结果,这些处理过程就通常称为分类后处理。常用分类后处理通常内容包括:分类合并、分类统计、过滤、聚类、主/次要分析、精度评价。

打开PIE-Basic软件,在"图像处理"标签下的"图像分类"组,单击【分类后处理】按钮下的下拉箭头,显示分类后处理算法。
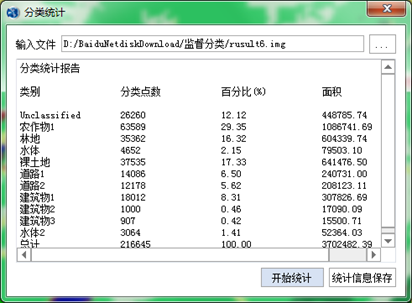
- 分类后统计:分类统计主要基于分类结果计算相关输入文件的统计信息。统计内容包括各类别的分类点数(像元个数)、百分比以及面积。
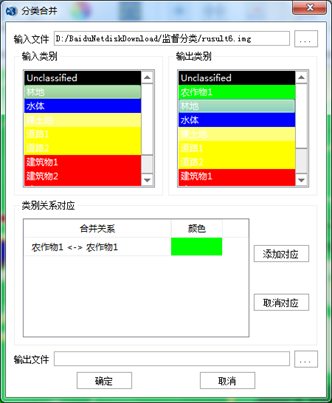
- 分类合并:是将分类成果中多个同物异谱的类别进行合并。
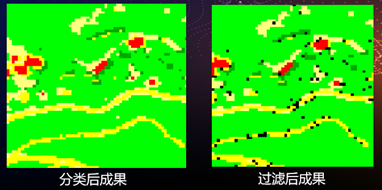
- 过滤:用以解决分类图像中出现的孤岛问题,使用斑点分组方法来消除分类文件中被隔离的像元 。像元被过滤后,被归类为Unclassified。

- 过滤阈值:若一类中被分组的像元少于设定的阈值,这些像元会被归类到Unclassified 层中;
- 聚类领域:观察周围的4个或8个像元,判定一个像元是否与周围的像元同组。
- 聚类:聚类处理是运用形态学算子(腐蚀和膨胀)将邻近的类似分类区域聚类并合并。首先将被选的分类用一个膨胀操作合并到一起,然后用指定了大小的变换核对分类图像进行侵蚀操作。


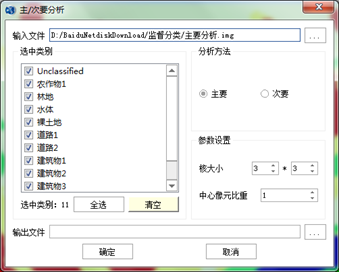
- 主/次要分析:图像分类往往会产生一些面积很小的图斑,主/次要分析采用类似于卷积滤波的方法将较大类别数中虚假像元归到该类中。主要分析功能是采用类似卷积滤波的方法将较大类别中的虚假像元归到该类中,首先定义一个变换核尺寸,然后用变换核中占主要地位(像元最多)类别数代替中心像元的类别数,次要分析相反,用变换核中占次要地位的像元的类别数代替中心像元的类别数。

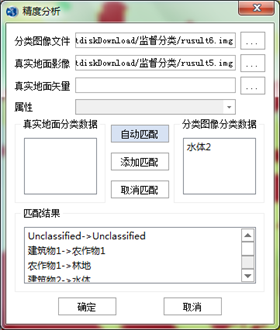
- 精度分析:是对分类结果的总体分类精度和各类地物的精度进行评价。评价方法包括混淆矩阵、Kappa系数。 真实感兴趣区参考源可以使用两种方式:一是标准的分类图(矢量);二是选择的感兴趣区(验证样本区栅格数据),真实感兴趣区参考源的选择通常是历史的分类栅格文件。
3.5实操流程
第一步:类别定义/类别判别
根据分类目的、影像数据自身的特征和分类区收集的信息确定分类系统。对影像进行特征判断,评价图像质量,决定是否需要进行影像增强等预处理。从遥感影像上仔细观察地物覆盖情况,大体判断主要地物的类别数量。经过判别本次演示数据的目标类别包括:建筑物、水体、道路、耕地、林地、其他类别等。

第二步:样本选择
使用PIE-Basic软件【ROI工具】进行样本选择。打开【ROI工具】对话框。点击【增加】添加样本类别,设置样本的名称和颜色双击需要修改的ROI名称列,名称进行高亮显示,开 始进行名称修改。双击ROI颜色列,打开选择颜色面板,选择样本的色彩。
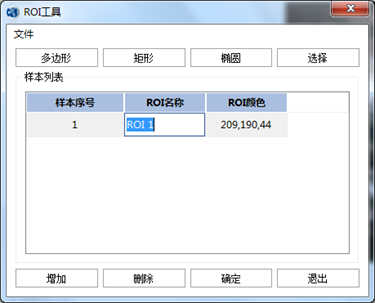
样本类别创建完成后,开始在影像上选取样本。选中样本类别,使用矩形工具在影像上
选择纯净像元区域进行勾绘。同样方法,在图像别的区域绘制其他样本,样本要满足一定数量,并且尽量均匀分布在整个图像上。最后,可以用【文件】下的保存ROI工具把ROI文件保存到本地。

第三步:分类器选择
根据分类的复杂度、精度需求等指标确定选择哪一种分类器。PIE-Basic软件提供了两种分类方法,距离分类和最大似然分类方法。
- 距离分类的分类法原理简单,分类精度不高,但计算速度快,可以在快速浏览分类概况中使用。
- 最大似然法是监督分类常用的方法之一,分类精度较高,本次案例选用最大似然法进行监督分类。

第四步:影像分类
在"图像处理"标签下的"图像分类"组,单击【监督分类】按钮下的下拉箭头,打开【最大似然分类】对话框;【选择文件】栏中会自动加载图层列表中的栅格影像,选中待分类的遥感影像。【选择ROI】中选择本次要使用的ROI文件,如果图层列表中只有一个ROI,则不要选择。【分类器】中已自动加载最大似然算法,不需要设置。

第五步:分类后处理
内容包括:分类合并、主/次要分析、分类统计、精度评价。
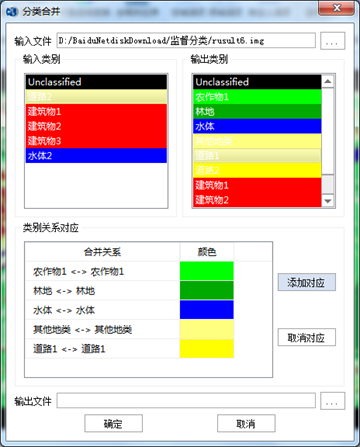
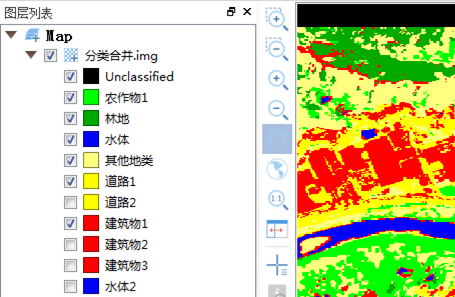
(1)分类合并:将分类成果中同一类别的不同图层合并到一起。选择"图像处理"标签下的"图像分类"组,单击【分类后处理】按钮下的下拉箭头,选择【分类合并】,打开【分类合并】对话框,进行图层合并。
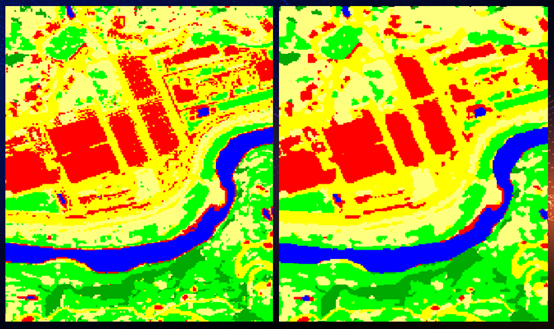
(2)主次/要分析:监督分类或者非监督分类,分类结果中不可避免地会产生一些面积很小的图斑。无论从专题制图的角度,还是从实际应用的角度,都有必要对这些小图斑进行剔除或重新分类,目前常用的方法有主次/要分析、聚类处理和过滤处理。但效果最好的是主次/要分析。
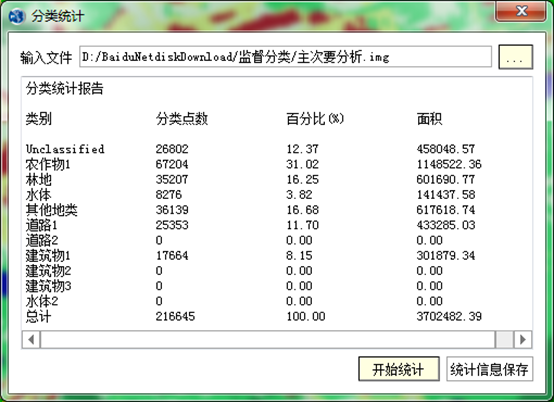
(3)分类统计:将分类合并后的成果进行统计,合并后的图层有统计信息,被合并的图层属性是0。最后,可以对统计结果进行保存。
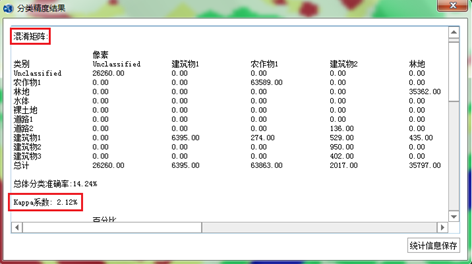
(4)精度评价:使用历史分类成果作为真实地理影像进行混淆矩阵和Kappa系数。
总体分类精度:84.78%
Kappa系数:81.46%

