对文章做摘要学习。
1. 传统目标检测方法:

(1)区域选择:这一步是为了对目标的位置进行定位。由于目标可能出现在图像的任何位置,而且目标的大小、长宽比例也不确定,所以最初采用滑动窗口的策略对整幅图像进行遍历,而且需要设置不同的尺度,不同的长宽比。这种穷举的策略虽然包含了目标所有可能出现的位置,但是缺点也是显而易见的:时间复杂度太高,产生冗余窗口太多,这也严重影响后续特征提取和分类的速度和性能。
(2)特征提取:由于目标的形态多样性,光照变化多样性,背景多样性等因素使得设计一个鲁棒的特征并不是那么容易。然而提取特征的好坏直接影响到分类的准确性。(这个阶段常用的特征有SIFT、HOG等)
(3)分类器:主要有SVM, Adaboost等。
总结:传统目标检测存在的两个主要问题:一个是基于滑动窗口的区域选择策略没有针对性,时间复杂度高,窗口冗余;二是手工设计的特征对于多样性的变化并没有很好的鲁棒性。
2.基于区域提议(region proposal)的深度学习算法:
对于滑动窗口存在的问题,region proposal提供了很好的解决方案。region proposal(候选区域)是预先找出图中目标可能出现的位置。但由于region proposal利用了图像中的纹理、边缘、颜色等信息,可以保证在选取较少窗口(几千个甚至几百个)的情
况下保持较高的召回率。比较常用的region proposal算法有selective Search和edge Boxes,如果想具体了解region proposal可以看一下PAMI2015的“What makes for effective detection proposals?”
有了候选区域,剩下的工作实际就是对候选区域进行图像分类的工作(特征提取+分类)。自2012年以后,卷积神经网络占据了图像分类任务的绝对统治地位,微软最新的ResNet和谷歌的Inception V4模型的top-5 error降到了4%以内多,这已经超越人在这个特定任务上的能力。所以目标检测得到候选区域后使用CNN对其进行图像分类是一个不错的选择。
2.1 R-CNN
2014年,RBG(Ross B. Girshick)大神使用region proposal+CNN代替传统目标检测使用的滑动窗口+手工设计特征,设计了R-CNN框架,使得目标检测取得巨大突破,并开启了基于深度学习目标检测的热潮。
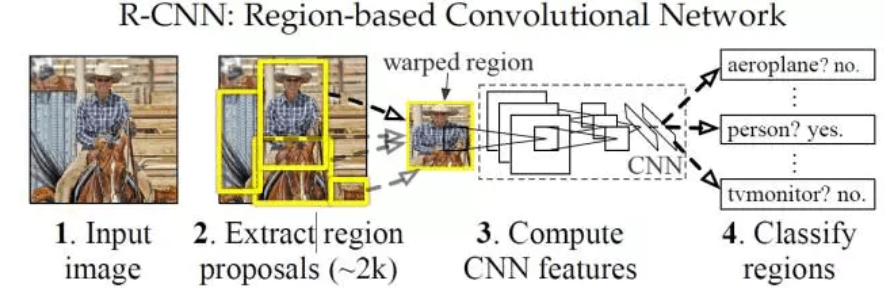
上面的框架图清晰的给出了R-CNN的目标检测流程:
(1)输入测试图像
(2)利用selective search算法在图像中提取2000个左右的region proposal。
(3)将每个region proposal缩放(warp)成227x227的大小并输入到CNN,将CNN的fc7层的输出作为特征。
(4) 将每个region proposal提取到的CNN特征输入到SVM进行分类。
* 上面的框架图是测试的流程图,要进行测试我们首先要训练好提取特征的CNN模型,以及用于分类的SVM:使用在ImageNet上预训练的模型(AlexNet/VGG16)进行微调得到用于特征提取的CNN模型,然后利用CNN模型对训练集提特征训练SVM。
* 对每个region proposal缩放到同一尺度是因为CNN全连接层输入需要保证维度固定。
* 上图少画了一个过程——对于SVM分好类的region proposal做边框回归(bounding-box regression),边框回归是对region proposal进行纠正的线性回归算法,为了让region proposal提取到的窗口跟目标真实窗口更吻合。因为region proposal提取到的窗口不可能跟人手工标记那么准,如果region proposal跟目标位置偏移较大,即便是分类正确了,但是由于IoU(region proposal与Ground Truth的窗口的交集比并集的比值)低于0.5,那么相当于目标还是没有检测到。
但是R-CNN框架也存在着很多问题:
(1) 训练分为多个阶段,步骤繁琐: 微调网络+训练SVM+训练边框回归器
(2) 训练耗时,占用磁盘空间大:5000张图像产生几百G的特征文件
(3) 速度慢: 使用GPU, VGG16模型处理一张图像需要47s。
针对速度慢的这个问题,SPP-NET给出了很好的解决方案
2.2 SPP-NET(Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition)
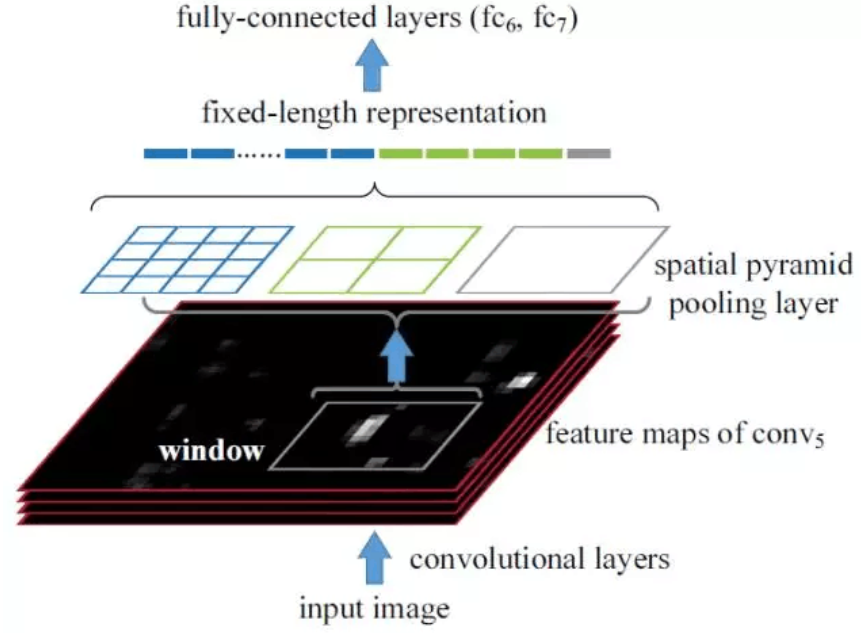
上图对应的就是SPP-NET的网络结构图,任意给一张图像输入到CNN,经过卷积操作我们可以得到卷积特征(比如VGG16最后的卷积层为conv5_3,共产生512张特征图)。图中的window是就是原图一个region proposal对应到特征图的区域,只需要将这些不同大小window的特征映射到同样的维度,将其作为全连接的输入,就能保证只对图像提取一次卷积层特征。SPP-NET使用了空间金字塔采样(spatial pyramid pooling):将每个window划分为4*4, 2*2, 1*1的块,然后每个块使用max-pooling下采样,这样对于每个window经过SPP层之后都得到了一个长度为(4*4+2*2+1)*512维度的特征向量,将这个作为全连接层的输入进行后续操作。
小结:使用SPP-NET相比于R-CNN可以大大加快目标检测的速度,但是依然存在着很多问题:
(1) 训练分为多个阶段,步骤繁琐: 微调网络+训练SVM+训练训练边框回归器
(2) SPP-NET在微调网络的时候固定了卷积层,只对全连接层进行微调,而对于一个新的任务,有必要对卷积层也进行微调。(分类的模型提取的特征更注重高层语义,而目标检测任务除了语义信息还需要目标的位置信息)
针对这两个问题,RBG又提出Fast R-CNN, 一个精简而快速的目标检测框架。
2.3 Fast R-CNN:
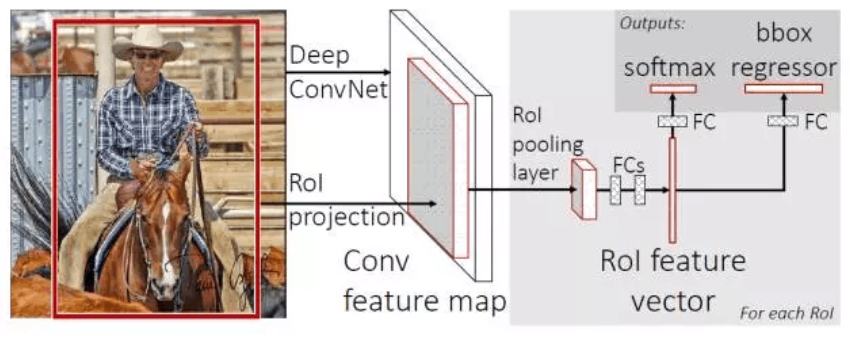
与R-CNN框架图对比,可以发现主要有两处不同:一是最后一个卷积层后加了一个ROI pooling layer,二是损失函数使用了多任务损失函数(multi-task loss),将边框回归直接加入到CNN网络中训练。
(1) ROI pooling layer实际上是SPP-NET的一个精简版,SPP-NET对每个proposal使用了不同大小的金字塔映射,而ROI pooling layer只需要下采样到一个7x7的特征图。对于VGG16网络conv5_3有512个特征图,这样所有region proposal对应了一个7*7*512维度的特征向量作为全连接层的输入。
(2) R-CNN训练过程分为了三个阶段,而Fast R-CNN直接使用softmax替代SVM分类,同时利用多任务损失函数边框回归也加入到了网络中,这样整个的训练过程是端到端的(除去region proposal提取阶段)。
小结:Fast R-CNN融合了R-CNN和SPP-NET的精髓,并且引入多任务损失函数,使整个网络的训练和测试变得十分方便。
缺点:region proposal的提取使用selective search,目标检测时间大多消耗在这上面(提region proposal 2~3s,而提特征分类只需0.32s),无法满足实时应用,而且并没有实现真正意义上的端到端训练测试(region proposal使用selective search先提取处来)。
那么有没有可能直接使用CNN直接产生region proposal并对其分类?Faster R-CNN框架就是符合这样需要的目标检测框架。
2.4 Faster R-CNN(Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks)
如果找到一种方法只提取几百个或者更少的高质量的预选窗口,而且召回率很高,这不但能加快目标检测速度,还能提高目标检测的性能(假阳例少)。RPN(Region Proposal Networks)网络应运而生。RPN的核心思想是使用卷积神经网络直接产生region proposal,使用的方法本质上就是滑动窗口。RPN的设计比较巧妙,RPN只需在最后的卷积层上滑动一遍,因为anchor机制和边框回归可以得到多尺度多长宽比的region proposal。
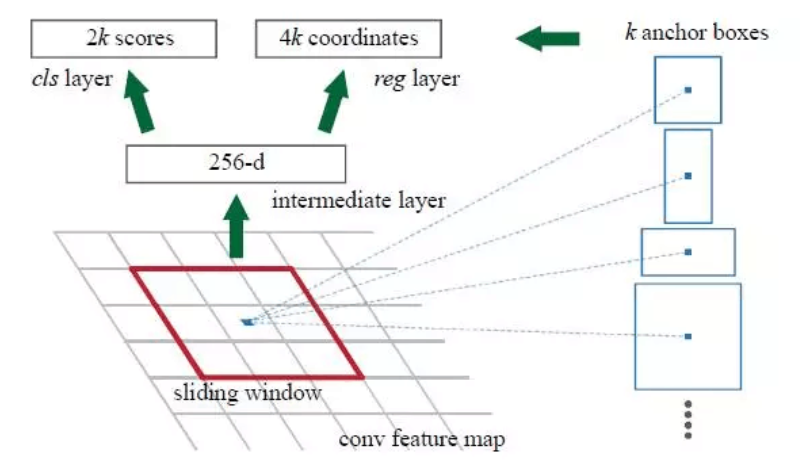
小结:Faster R-CNN将一直以来分离的region proposal和CNN分类融合到了一起,使用端到端的网络进行目标检测,无论在速度上还是精度上都得到了不错的提高。然而FasterR-CNN还是达不到实时的目标检测,预先获取region proposal,然后在对每个proposal分类计算量还是比较大。比较幸运的是YOLO这类目标检测方法的出现让实时性也变的成为可能。
3 基于回归方法的深度学习目标检测算法:
3.1 YOLO:(You Only Look Once: Unified, Real-Time Object Detection)
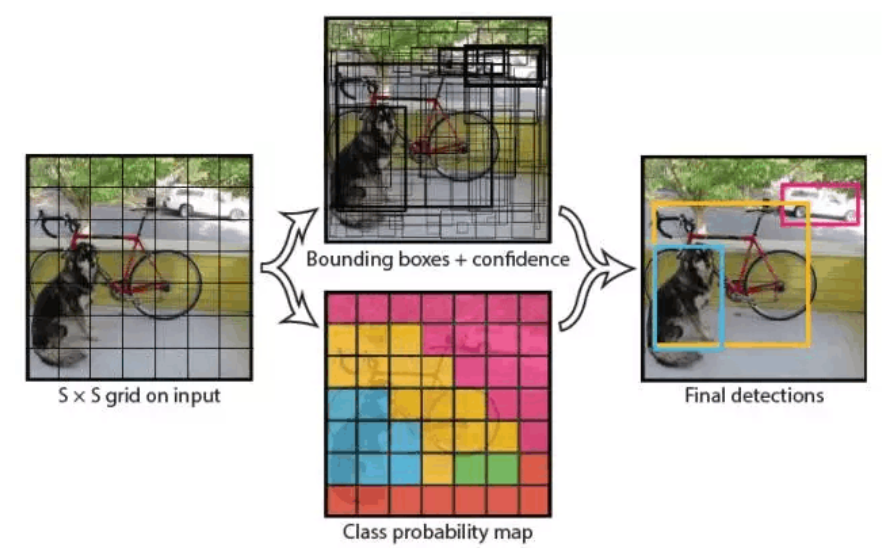
我们直接看上面YOLO的目标检测的流程图:
(1) 给个一个输入图像,首先将图像划分成7*7的网格
(2) 对于每个网格,我们都预测2个边框(包括每个边框是目标的置信度以及每个边框区域在多个类别上的概率)
(3) 根据上一步可以预测出7*7*2个目标窗口,然后根据阈值去除可能性比较低的目标窗口,最后NMS去除冗余窗口即可。
可以看到整个过程非常简单,不需要中间的region proposal在找目标,直接回归便完成了位置和类别的判定。
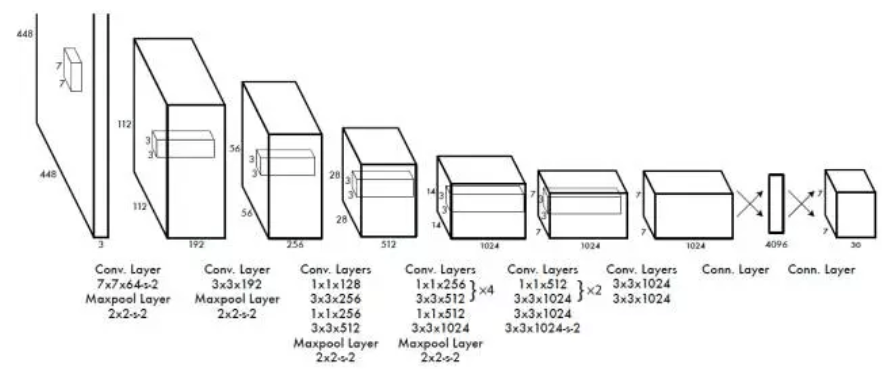
那么如何才能做到直接在不同位置的网格上回归出目标的位置和类别信息呢?上面是YOLO的网络结构图,前边的网络结构跟GoogLeNet的模型比较类似,主要的是最后两层的结构,卷积层之后接了一个4096维的全连接层,然后后边又全连接到一个7*7*30维的张量上。实际上这7*7就是划分的网格数,现在要在每个网格上预测目标两个可能的位置以及这个位置的目标置信度和类别,也就是每个网格预测两个目标,每个目标的信息有4维坐标信息(中心点坐标+长宽),1个是目标的置信度,还有类别数20(VOC上20个类别),总共就是(4+1)*2+20 = 30维的向量。这样可以利用前边4096维的全图特征直接在每个网格上回归出目标检测需要的信息(边框信息加类别)。
小结:YOLO将目标检测任务转换成一个回归问题,大大加快了检测的速度,使得YOLO可以每秒处理45张图像。而且由于每个网络预测目标窗口时使用的是全图信息,使得false positive比例大幅降低(充分的上下文信息)。但是YOLO也存在问题:没有了region proposal机制,只使用7*7的网格回归会使得目标不能非常精准的定位,这也导致了YOLO的检测精度并不是很高。
3.2 SSD(SSD: Single Shot MultiBox Detector)
上面分析了YOLO存在的问题,使用整图特征在7*7的粗糙网格内回归对目标的定位并不是很精准。那是不是可以结合region proposal的思想实现精准一些的定位?SSD结合YOLO的回归思想以及Faster R-CNN的anchor机制做到了这点。
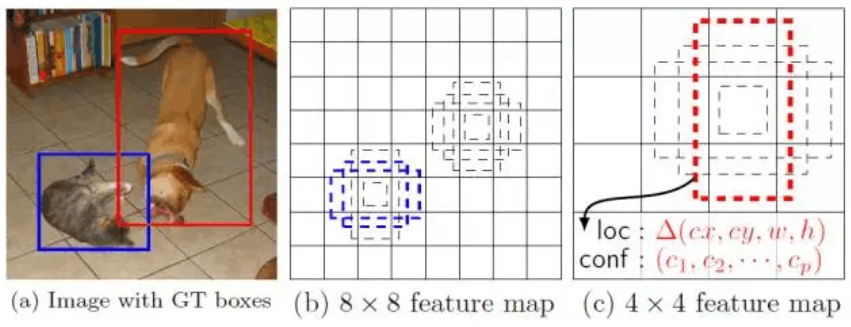
首先SSD获取目标位置和类别的方法跟YOLO一样,都是使用回归,但是YOLO预测某个位置使用的是全图的特征,SSD预测某个位置使用的是这个位置周围的特征(感觉更合理一些)。使用Faster R-CNN的anchor机制,如SSD的框架图所示,假如某一层特征图(图b)大小是8*8,那么就使用3*3的滑窗提取每个位置的特征,然后这个特征回归得到目标的坐标信息和类别信息(图c)。
不同于Faster R-CNN,这个anchor是在多个feature map上,这样可以利用多层的特征并且自然的达到多尺度(不同层的feature map 3*3滑窗感受野不同)。
小结:SSD结合了YOLO中的回归思想和Faster R-CNN中的anchor机制,使用全图各个位置的多尺度区域特征进行回归,既保持了YOLO速度快的特性,也保证了窗口预测的跟Faster R-CNN一样比较精准。
4 提高目标检测的方法:
(1)难分样本挖掘(hard negative mining)
(2)多层特征融合
(3)使用上下文信息