本文使用的是正则表达式爬取古诗文网,爬取的信息有:标题、朝代、作者、内容等信息
1.网站分析
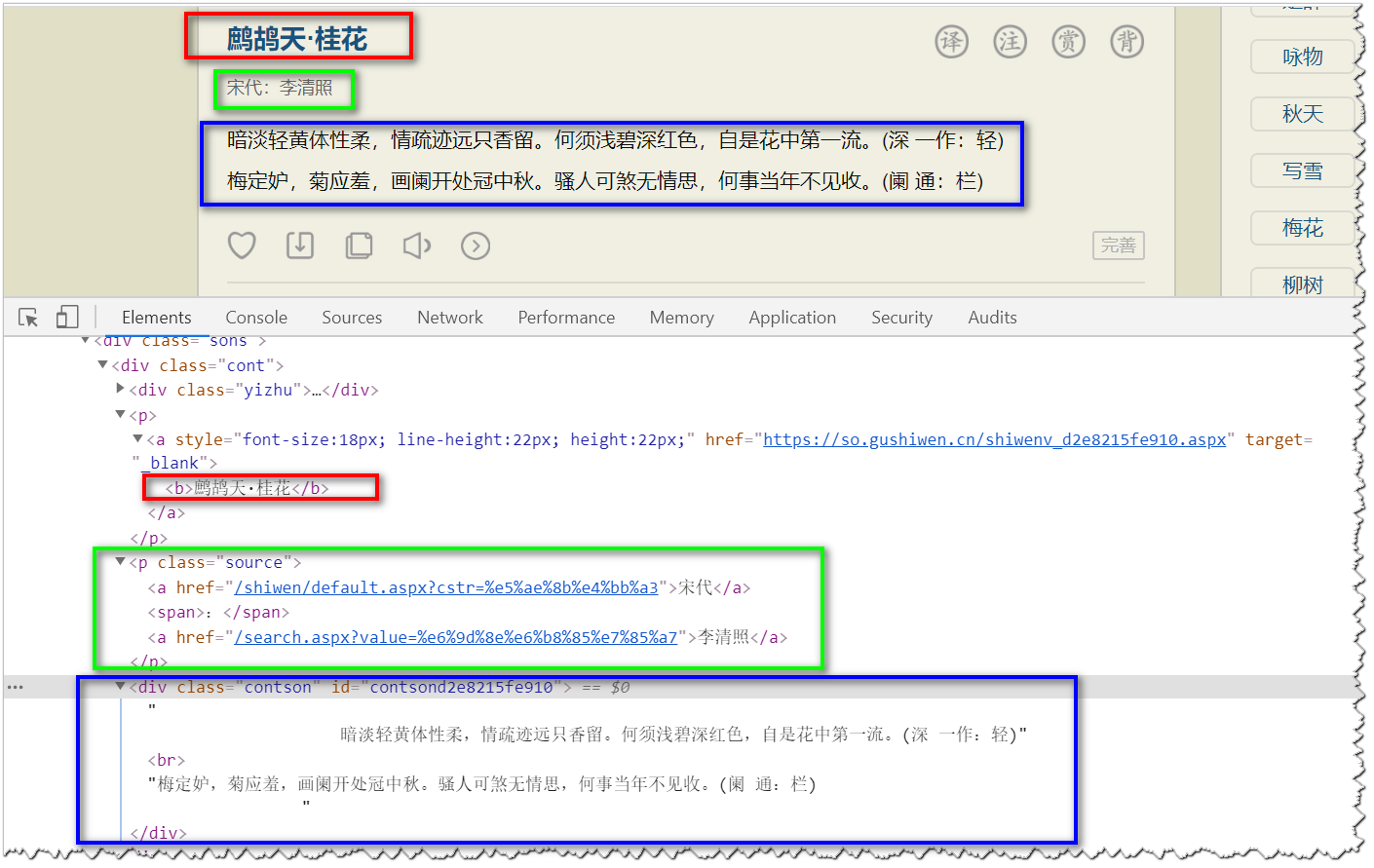
通过上图,我已将需要爬取的信息与标签的对应位置根据不同的颜色标记出来,标题位于class="cont"的div标签下的b标签中,朝代与作者都位于class="source"的p标签下的a标签中,内容信息位于class="contson"的div标签中,知道这些后,我们便可以使用正则表达式来匹配得出我们需要的信息了
2.抓取代码
# Author:Logan
import requests
import re
HEADERS = {
'User_Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
}
def parse_url(url):
response = requests.get(url, headers=HEADERS)
text = response.text
titles = re.findall(r'<divsclass="cont">.*?<b>(.*?)</b>',text,re.DOTALL)
dynasties = re.findall(r'<psclass="source">.*?<a.*?>(.*?)</a>', text, re.DOTALL)
authors = re.findall(r'<span>:</span>.*?<a.*?>(.*?)</a>', text, re.DOTALL)
contents = re.findall(r'<divsclass="contson".*?>(.*?)</div>', text, re.DOTALL)
peoms = []
for content in contents:
x = re.sub('<.*?>',"",content).strip()
peoms.append(x)
result = []
for value in zip(titles,dynasties,authors,peoms):
title, dynasty, author, peom = value
ret = {
"title":title,
"dynatie":dynasty,
"author": author,
"peom":peom
}
result.append(ret)
for gsw in result:
print(gsw)
print("=" * 30)
def main():
base_url = 'https://so.gushiwen.org/shiwen/default_2A9cb3b7c0e4a0A{}.aspx'
for i in range(1,12):
url = base_url.format(i)
print(url)
parse_url(url)
if __name__ == '__main__':
main()
抓取截图:
