问题描述:
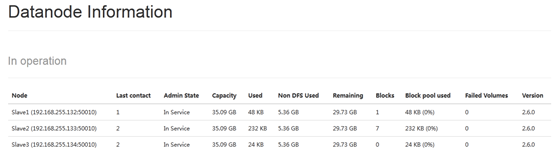
集群原始组成部分为:Master、Slave1、Slave2后来有添加一台Slave3,配置完相应的文件后,启动hadoop、spark发现只启动了Slave1、Slave3两个datanode,后来停止掉hadoop服务后,再次启动,这次只启动了Slave1、Slave2,jps查看Slave3的进程也没有datanode,但是对于yarn、spark此机器确实有启动对应服务
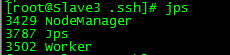
查看/app/hadoop/logs/hadoop-root-namenode-Master.log
解决办法:
回想下,可能是由于我添加的节点直接拷贝的Slave2机器的内容(包括hadoop、spark软件,及软件日志,datanode ID信息等等),因为他们的storageID是一样的,datanode启动时会向Master发送BPID,可以在log中查看到这些信息
2015-05-26 10:23:47,485 INFO org.apache.hadoop.hdfs.server.datanode.BlockPoolSliceScanner: Periodic Block Verification Scanner initialized with interval 504 hours for block pool BP-1121039461-192.168.255.131-1431764031745
2015-05-26 10:23:47,491 INFO org.apache.hadoop.hdfs.server.datanode.DataBlockScanner: Added bpid=BP-1121039461-192.168.255.131-1431764031745 to blockPoolScannerMap, new size=1
先关闭hadoop服务,然后
删除Slave3的如下目录文件
/app/hadoop/logs/*
/app/hadoop/hdfs/data/*
删除完后,再次启动,问题解决