The French author Georges Perec (1936–1982) once wrote a book, La disparition, without the letter 'e'. He was a member of the Oulipo group. A quote from the book:
Tout avait Pair normal, mais tout s’affirmait faux. Tout avait Fair normal, d’abord, puis surgissait l’inhumain, l’affolant. Il aurait voulu savoir où s’articulait l’association qui l’unissait au roman : stir son tapis, assaillant à tout instant son imagination, l’intuition d’un tabou, la vision d’un mal obscur, d’un quoi vacant, d’un non-dit : la vision, l’avision d’un oubli commandant tout, où s’abolissait la raison : tout avait l’air normal mais…
Perec would probably have scored high (or rather, low) in the following contest. People are asked to write a perhaps even meaningful text on some subject with as few occurrences of a given “word” as possible. Our task is to provide the jury with a program that counts these occurrences, in order to obtain a ranking of the competitors. These competitors often write very long texts with nonsense meaning; a sequence of 500,000 consecutive 'T's is not unusual. And they never use spaces.
So we want to quickly find out how often a word, i.e., a given string, occurs in a text. More formally: given the alphabet {'A', 'B', 'C', …, 'Z'} and two finite strings over that alphabet, a word W and a text T, count the number of occurrences of W in T. All the consecutive characters of W must exactly match consecutive characters of T. Occurrences may overlap.
Tout avait Pair normal, mais tout s’affirmait faux. Tout avait Fair normal, d’abord, puis surgissait l’inhumain, l’affolant. Il aurait voulu savoir où s’articulait l’association qui l’unissait au roman : stir son tapis, assaillant à tout instant son imagination, l’intuition d’un tabou, la vision d’un mal obscur, d’un quoi vacant, d’un non-dit : la vision, l’avision d’un oubli commandant tout, où s’abolissait la raison : tout avait l’air normal mais…
Perec would probably have scored high (or rather, low) in the following contest. People are asked to write a perhaps even meaningful text on some subject with as few occurrences of a given “word” as possible. Our task is to provide the jury with a program that counts these occurrences, in order to obtain a ranking of the competitors. These competitors often write very long texts with nonsense meaning; a sequence of 500,000 consecutive 'T's is not unusual. And they never use spaces.
So we want to quickly find out how often a word, i.e., a given string, occurs in a text. More formally: given the alphabet {'A', 'B', 'C', …, 'Z'} and two finite strings over that alphabet, a word W and a text T, count the number of occurrences of W in T. All the consecutive characters of W must exactly match consecutive characters of T. Occurrences may overlap.
InputThe first line of the input file contains a single number: the number of test cases to follow. Each test case has the following format:
One line with the word W, a string over {'A', 'B', 'C', …, 'Z'}, with 1 ≤ |W| ≤ 10,000 (here |W| denotes the length of the string W).
One line with the text T, a string over {'A', 'B', 'C', …, 'Z'}, with |W| ≤ |T| ≤ 1,000,000.
OutputFor every test case in the input file, the output should contain a single number, on a single line: the number of occurrences of the word W in the text T.
Sample Input
3
BAPC
BAPC
AZA
AZAZAZA
VERDI
AVERDXIVYERDIAN
Sample Output
1 3 0
题意:计算模式串在原串中出现的次数
对于next数组的理解是理解kmp的关键。
next[i]:记录的是前后缀最长公共长度。
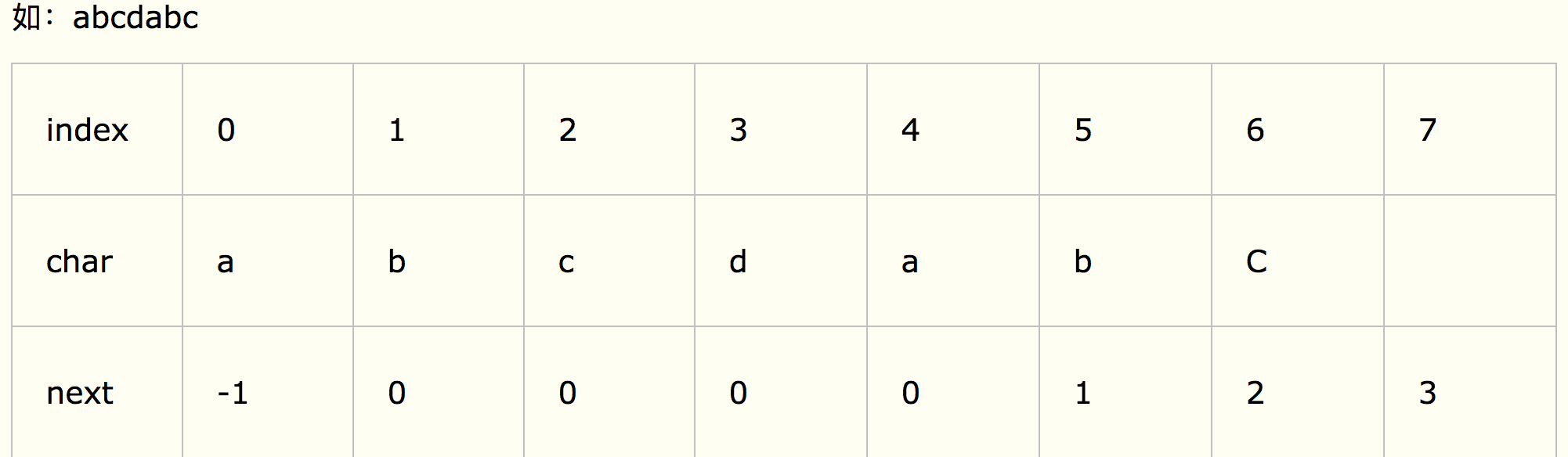
KMP:
1 #include<stdio.h> 2 #include<iostream> 3 #include<string.h> 4 using namespace std; 5 6 const int N=1000020; 7 const int M=10020; 8 9 char s[N];//原串 10 char t[M];//模式串 11 int nextt[M]; 12 13 void getnext(int len)//求的是模式串的next数组 14 { 15 int i=0,j=-1; 16 nextt[0]=-1; 17 while(i<len) 18 { 19 if(j<0||t[i]==t[j]) 20 nextt[++i]=++j; 21 else 22 j=nextt[j]; 23 } 24 } 25 26 int kmp(int m,int n)//m模式串长度、n原串长度 27 { 28 int i=0,j=0,ans=0; 29 while(i<n) 30 { 31 if(j==-1||t[j]==s[i]) 32 { 33 i++; 34 j++; 35 } 36 else 37 j=nextt[j]; 38 if(j==m) 39 { 40 ans++; 41 j=nextt[j]; 42 } 43 } 44 return ans; 45 } 46 47 int main() 48 { 49 int tt; 50 scanf("%d",&tt); 51 while(tt--) 52 { 53 memset(s,'\0',sizeof(s)); 54 memset(t,'\0',sizeof(t)); 55 memset(nextt,0,sizeof(nextt)); 56 scanf("%s%s",t,s);//模式串、原串 57 int len1=strlen(t);//模式串 58 int len2=strlen(s);//原串 59 getnext(len1); 60 printf("%d\n",kmp(len1,len2)); 61 } 62 return 0; 63 }
哈希:
1 #include<stdio.h> 2 #include<iostream> 3 #include<cmath> 4 #include<algorithm> 5 #include<string.h> 6 #include<queue> 7 #include<map> 8 using namespace std; 9 typedef unsigned long long ull; 10 const int N=1e6+20; 11 12 char a[N],b[N]; 13 ull p[N],sum[N],x=131; 14 //求a(子串)在b(母串)中出现多少次 15 16 void w() 17 { 18 p[0]=1; 19 for(int i=1; i<1000000; i++) 20 p[i]=p[i-1]*x;//预处理出x^n 21 } 22 23 int main() 24 { 25 w(); 26 int t; 27 scanf("%d",&t); 28 while(t--) 29 { 30 scanf("%s %s",a+1,b+1);//使得下标从1开始 31 int la=strlen(a+1);//短 32 int lb=strlen(b+1);//长 33 sum[0]=0; 34 for(int i=1; i<=lb; i++) 35 sum[i]=sum[i-1]*x+(ull)(b[i]-'A'+1); 36 ull s=0; 37 for(int i=1; i<=la; i++) 38 s=s*x+(ull)(a[i]-'A'+1);//*x是为了化成x进制数 39 int ans=0; 40 for(int i=0; i<=lb-la; i++) 41 { 42 if(s==sum[i+la]-sum[i]*p[la]) 43 ans++; 44 } 45 printf("%d\n",ans); 46 } 47 return 0; 48 }
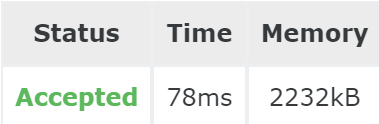
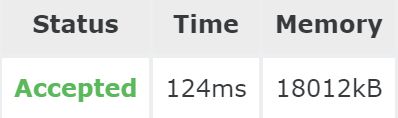
不明白为什么哈希的时间比kmp慢而且占用的内存都快是kmp的10倍了???