CS架构:client server(客户端-服务端)
安装一个客户端应用程序EXE,就可以与服务端进行网络交互
BS架构:browser server (浏览器-服务端)
所有的bs都需要一个浏览器才能访问,
浏览器是一个软件,是特殊的客户端,
所有的bs架构也都是cs架构
基础知识:
网卡:计算机硬件,出厂的时候被分配的一个mac地址
MAC地址:唯一标识了一台机器(8C-I3-O3-DD-9D)
交换机: 用于局域网内多台机器间通信,只认识mac地址,可用arp协议通过ip找到mac地址
局域网:一个区域内多台电脑组成的一个内部网络(区域内电脑ip前缀相同)
IP地址:iP地址是指互联网协议地址(英语:Internet Protocol Address,又译为网际协议地址),是IP Address的缩写。IP地址是IP协议提供的一种统一的地址格式,它为互联网上的每一个网络和每一台主机分配一个逻辑地址,以此来屏蔽物理地址的差异。
规定网络地址的协议叫ip协议,它定义的地址称之为ip地址
IP协议:在传输过程中规定位数.顺序等传输规则内容(IP地址规范)
ipv4:四位的点分十进制(32位二进制)
ipv6:六位的冒分十六进制
子网掩码:就是表示子网络特征的一个参数(局域网共同的网段)。它在形式上等同于IP地址,也是一个32位二进制数字,它的网络部分全部为1,主机部分全部为0。
IP协议的作用主要有两个,一个是为每一台计算机分配IP地址,另一个是确定哪些地址在同一个子网络。
端口:帮助我们在机器上的对应服务使用端口, 0-65535,使用8000以后
地址解析协议是根据IP地址获取物理地址的一个TCP/IP协议。收到返回消息后将该IP地址和物理地址存入本机ARP缓存中并保留一定时间,下次请求时直接查询ARP缓存以节约资源。
路由器:能够在局域网与局域网间通信,是连接因特网中各局域网、广域网的设备,
网关ip:在一台机器对局域网外的地址进行访问时使用的出口ip,路由器具有判断网络地址和选择IP路径的功能,用于连接多个逻辑上分开(不同网段192.168._._)的网络,
ip地址在网络上可以定位一台机器,端口port能够在网络上定位一台机器上的一个服务
本地回环地址:127.0.0.1
全网段地址:0.0.0.0
保留字段:192.168.0.0 - 192.168.255.255
172.16.0.0 - 172.32.255.255
10.0.0.1 - 10.255.255.255
TCP协议
-
建立连接:3次握手, 断开连接:4次挥手
-
在建立起连接之后 发送的每一条信息都有回执 为了保证数据的完整性,还有重传机制
-
长连接 :会一直占用双方的端口
-
特点:
可靠 在连接的基础上数据传输,不会丢失,不被重复接收 慢 每一次发送的数据还要等待结果(三次握手)(四次挥手) 对传递数据的长短没有要求
-
常用于发邮件,传文件时候
UDP协议
-
机器之间传递信息不需确认建立连接,直接发送
-
即时传递,不占用端口
-
速度快,可能丢失,
-
不能传输过长的数据(1500字节)
-
常用于即时通信消息传输
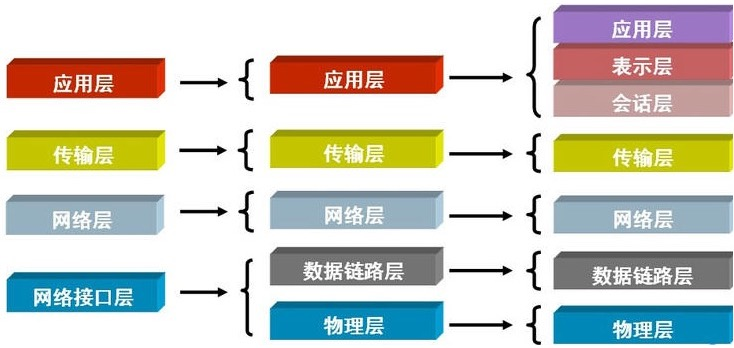
OSI七层协议
通信: 数据传输经过一层层协议包装,直到物理层传输,接收信息通过反向的一层层协议解析来识别数据


Socket是应用层与TCP/IP协议族通信的中间软件抽象层,它是一组接口。帮助我们完成了所有协议信息的组织和拼接.在设计模式中,Socket其实就是一个门面模式,
它把复杂的TCP/IP协议族隐藏在Socket接口后面,对用户来说,一组简单的接口就是全部,让Socket去组织数据,以符合指定的协议。
基于TCP协议的socket
tcp是基于链接的,必须先启动服务端,然后再启动客户端去链接服务端
1 -------------------------client客户端------------------------------------ 2 import socket #导入套接口模块 3 sk=socket.socket() #创建一个套接口(对象) 4 sk.connect(('127.0.0.1',9999)) #要访问的服务器地址,共同端口 5 sk.send('好不好'.encode('utf-8')) #给服务器传送消息 6 msg=sk.recv(1024).decode('utf-8') #接收服务器消息 7 print(msg) 8 sk.close() #关闭套接口(与服务器连接对象) 9 -------------------------------------------------------------------------
1 #=======================serever服务器端================================== 2 import socket #导入套接口模块 3 sk = socket.socket() #创建一个套接口(对象) 4 sk.bind(('127.0.0.1',9999)) #定自己的服务器地址,共同端口 5 #(空�.0.0.0自己电脑ip) 6 sk.listen() #侦听服务器请求消息 7 conn,addr=sk.accept() #阻塞接口#接受连接,储存地址端口 8 msg =conn.recv(1024).decode('utf-8') #阻塞#接受连接地址传入字节 9 print(msg,addr) #打印消息 10 conn.send('你好'.encode('utf-8')) #给连接到(我)服务器的地址发消息 11 conn.close() #关闭地址端口 12 sk.close() #关闭套接口(对象接入) 13 #=========================================================================
socket对象,实际上是存储了所有的操作系统提供给我们的网络资源
基于UDP协议的socket
udp是无链接的,启动服务之后可以直接接受消息,不需要提前建立链接
1 #-----------------------------基于udp协议的客户端------------------------------------ 2 import socket 3 sk=socket.socket(type=socket.SOCK_DGRAM) #使用udp协议需指定socket参数type 4 server_addr = ('127.0.0.1',9999) #指定服务器地址端口 5 content = input('>>>') 6 sk.sendto(content.encode('utf-8'),server_addr) #直接给服务器地址传输数据 7 msg=sk.recv(1024).decode('utf-8') #接收来自服务器的数据 8 print(msg) 9 sk.close() 10 #----------------------------------------------------------------------------------
1 #=======================基于udp协议的服务器端================================= 2 import socket 3 sk=socket.socket(type=socket.SOCK_DGRAM) #使用udp协议需指定socket参数type 4 sk.bind(('127.0.0.1',9999)) #固定自己地址,给客户端链接用 5 msg,client_addr=sk.recvfrom(1024) #直接接受连接服务器的客户端数据 6 print(msg.decode('utf-8'),client_addr) 7 content = input('>>>') 8 sk.sendto(content.encode('utf-8'),client_addr)#给客户端发消息 9 sk.close() 10 # 打印的地址是一个元祖 11 #========================================================================
两种协议都有使用场景,且可以循环传输,在连接建立后在输入与接收时建立while循环,同时可设置退出条件.
tcp黏包
黏包:tcp传输时数据通信是无消息保护边界的。
tcp协议中,应用程序所看到的数据是一个整体,或说是一个流(stream),一条消息有多少字节对应用程序是不可见的,因此TCP协议是面向流的协议,这也是容易出现粘包问题的原因。
TCP协议发送时,由于TCP是数据流协议,#数据并不一定会一次性发送出去,如果这段数据比较长,会被分段发送,如果比较短,可能会等待和下一次数据一起发送。
-
1.小数据封包:
-
发送端为了将多个发往接收端的包,更有效的发到对方,使用了优化方法(Nagle算法),将多次间隔较小且数据量小的数据,合并成一个大的数据块,然后进行封包。一次发送出去,这样接收方就收到了粘包数据。
-
-
2.大数据拆包:
-
当发送端缓冲区的长度大于网卡的MTU时,tcp会将这次发送的数据拆成几个数据包发送出去。发送时文件内容是按照一段一段的字节流发送的,在接收方看了,根本不知道该文件的字节流从何处开始,在何处结束
-
-
3.接收方的缓存机制
-
接收方不及时接收缓冲区的包,造成多个包接收(客户端发送了一段数据,服务端只收了一小部分,服务端下次再收的时候还是从缓冲区拿上次遗留的数据,产生粘包)
总结
-
黏包现象只发生在tcp协议中:
1.从表面上看,黏包问题主要是因为发送方和接收方的缓存机制、tcp协议面向流通信的特点。
2.'实际上,主要还是因为接收方不知道消息之间的界限,不知道一次性提取多少字节的数据所造成的
-
解决方法
-
为了避免黏包,我们先制作一个包含传输信息的字典,
-
dumps为str字典,encode转码字节,len获取字节长度,
-
用struck模块把字节长度转为4字节
-
-
发送4字节包头长度信息---->对应接收4字节,struck解包长度
-
再发送报头字典序列化.转码后信息--->接收解包长度报头内容,decode,loads
-
最后发送内容--->提取报头字典内容组织接收信息长度
-
我们还可以把报头做成字典,字典里包含将要发送的真实数据的详细信息,然后json序列化,然后用struck将序列化后的数据长度打包成4个字节(4个自己足够用了)
发送时 接收时 制作信息报头字典,dumps为str字典, encode转码字节,len获取字节长度, struck模块把字节长度转为4字节 先发4字节报头长度 先收4字节报头长度,用struct取出长度值 再发送字典dumps.encode转码报头 再接收字节decode,loads报头字典,提取信息 最后发真实内容 安排报头内容信息执行提取真实的数据
import json,struct #假设通过客户端上传1MB:的文件a.txt #1.为避免粘包,必须自定制报头 header={'file_size':1048576,'file_name':'/a/b/c/d/e/a.txt','md5':'8f6fbf8347faa4924a76856701edb0f3'} #数据大小(字节),文件路径和md5值 #2.为了该报头能传送,需要序列化并且转为bytes head_bytes=bytes(json.dumps(header),encoding='utf-8') #序列化并转成bytes,用于传输 #3.用struck将报头长度这个数字转成固定长度:4个字节 head_len_bytes=struct.pack('i',len(head_bytes)) #这4个字节里指代一个数字,该数字是报头的长度,为了让客户端知道报头的长度, #4.客户端开始发送 conn.send(head_len_bytes) #先发报头的长度,4个bytes conn.send(head_bytes) #再发报头的字节格式 conn.sendall(文件内容) #然后发真实内容的字节格式 #服务端开始接收 #1.先收报头4个bytes,得到报头长度的字节格式 head_len_bytes=s.recv(4) x=struct.unpack('i',head_len_bytes)[0] #提取报头的长度(_,) #2.按照报头长度x,收取报头的bytes格式 head_bytes=s.recv(x) header=json.loads(header_bytes.decode('utf-8')) #提取报头 #3.最后根据报头细心提取真实的数据 real_data_len=s.recv(header['file_size']) s.recv(real_data_len)