1、表现:一“.xml”为扩展名的文件
2、存储:树形结构
3、xml解析应用:
不同应用程序之间的通信-->订票软件和支付软件
不同的平台间通信-->操作系统
不同平台间数据的共享-->网站和手机
4、DOM解析原理
将整个xml文件先加载完毕,才进行解析
在Java程序中读取xml文件的过程也称为解析xml文件
解析的目的:获取节点名、节点值、属性名、属性值
解析的方式:DOM、SAX、DOM4J、JDOM
5、解析前准备工作:
package com.imooc_xml.dom.test; import java.io.IOException; import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.DocumentBuilderFactory; import javax.xml.parsers.ParserConfigurationException; import org.w3c.dom.Document; import org.w3c.dom.NamedNodeMap; import org.w3c.dom.Node; import org.w3c.dom.NodeList; import org.xml.sax.SAXException; public class DOMTest { public static void main(String[] args) { //1、创建一个DocumentBuilderFactory的对象 DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance(); //2、创建DocumentBuilder对象 try { DocumentBuilder db = dbf.newDocumentBuilder(); //通过DocumentBuilder对象的parser方法加载xml文件到当前项目下 Document document = db.parse("xml/books.xml"); } } catch (ParserConfigurationException e) { e.printStackTrace(); } catch (SAXException e){ e.printStackTrace(); } catch (IOException e){ e.printStackTrace(); } } }
6、解析xml文件的属性名和属性值:
NodeList bookList = document.getElementsByTagName("book");
//遍历每一个book节点
System.out.println("一共有"+bookList.getLength()+"书");
for(int i=0;i<bookList.getLength();i++){
Node book = bookList.item(i);
//遍历book的属性
NamedNodeMap attrs = book.getAttributes();
System.out.println("第"+(i+1)+"本书共有"+attrs.getLength()+"个属性");
for(int j=0;j<attrs.getLength();j++){
Node attr = attrs.item(j);
System.out.println("属性名:"+attr.getNodeName());
System.out.println("属性值:"+attr.getNodeValue());
}
/**
* 前提是,已经知道book节点有且只能有一个ID属性
* Element book = bookList.item(i);
* String attrValue = book.getAttribute("id");
*/
7、解析xml文件的节点名和节点值:
NodeList childNodes = book.getChildNodes(); System.out.println("第"+(i+1)+"本书共有"+ childNodes.getLength()+"个子节点"); for (int k = 0;k<childNodes.getLength();k++){ //区分出text类型的node(有换行和空格)以及element类型的node if(childNodes.item(k).getNodeType() == Node.ELEMENT_NODE){ System.out.println(childNodes.item(k).getNodeName()); //获取element类型element类型节点的节点值 //getFirstChild().getNodeValue():认为值是子节点的子节点 //System.out.println(childNodes.item(k).getFirstChild().getNodeValue()); //区别:<name><a>aa</a>JAVA编程思想</name>一个是null,一个是aaJAVA编程思想 System.out.println(childNodes.item(k).getTextContent()); } }
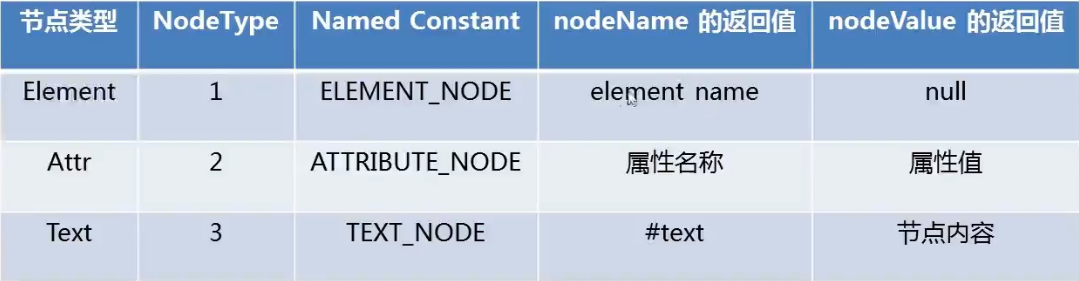
8、 常用节点类型: