Hadoop之Mapred
1.1 Mapred的大致流程

1.2Mapred的详细流程

文件File:文件要存储在HDFS中,每个文件切分成多个一定大小(默认64M)的Block(默认3个备份)存储在多个节点(DataNode)上。文件数据内容:We are studying at school. We are studying at school. …
- 输入和拆分:不属于map和reduce的主要过程,但属于整个计算框架消耗时间的一部分,该部分会为正式的map过程准备数据。
(split)操作:MapReduce框架使用InputFormat基础类做map前的预处理,比如验证输入的格式是否符合输入定义;然后,将输入文件切分为逻辑上的多个input split,input split是MapReduce对文件进行处理和运算的输入单位,只是一个逻辑概念。在进行map计算之前,mapreduce会根据输入文件计算输入分片(input split),每个输入分片(input split)针对一个map任务,输入分片(input split)存储的并非数据本身,而是一个分片长度和一个记录数据的位置的数组。split操作知识将源文件的内容分片形成一系列的input split,每个input split中存储着该分片的数据信息(例如,文件块信息、起始位置、数据长度、所在节点列表…),并不是对文件实际分割成多个小文件,每个input split都由一个map任务进行后续处理。
输入分片(input split)往往和hdfs的block(块)关系很密切,假如我们设定hdfs的块的大小是64mb,如果我们输入有三个文件,大小分别是3mb、65mb和127mb,那么mapreduce会把3mb文件分为一个输入分片(input split),65mb则是两个输入分片(input split)而127mb也是两个输入分片(input split),换句话说我们如果在map计算前做输入分片调整,例如合并小文件,那么就会有5个map任务将执行,而且每个map执行的数据大小不均,这个也是mapreduce优化计算的一个关键点。
实际上每个input split包含后一个Block中开头部分的数据(解决记录跨Block问题)。比如记录“we are studying at school. ”跨越存储在两个Block中,那么这条记录属于前一个Block对应的input split。这里以“ ”分割每条记录,以空格区分一个目标单词。
数据格式化(Format)操作:将划分好的input split格式化成键值对形式的数据。其中key为偏移量,value为每一行的内容。值得注意的是,在map任务执行过程中,会不停地执行数据格式化操作,每生成一个键值对就会将其传入map进行处理。所以map和数据格式化操作并不存在前后时间差,而是同时进行的。这里具体涉及到RecordReader类,其作用是从分片中每读取一条记录,就调用一次map函数。因为input split是逻辑切分而非物理切分,所以还需通过RecordReader根据input split中的信息来处理input split中的具体记录,加载数据并转换为适合map任务读取的键值对,输入给map任务。例如记录“we are studying at school.”作为参数v,调用map(v),然后继续这个过程,读取下一条记录直到input split尾部。
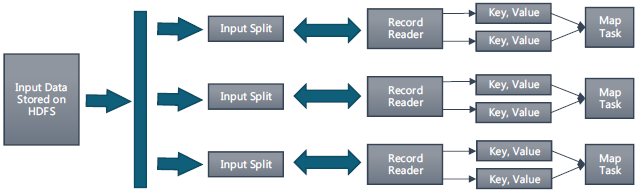
- map阶段: 就是程序员编写好的map函数了,因此map函数效率相对好控制,而且一般map操作都是本地化操作也就是在数据存储节点上进行。在HDFS 中,文件数据是被复制多份的,所以计算将会选择拥有此数据的最空闲的节点。比如记录“we are studying at school”,调用执行一次map(“we are studying at school”),在内存中增加数据:{“we”:1},{“are”:1},{“studying”:1},{“at”:1},{“school”:1}。
- shuffle阶段:Shuffle 过程是指map产生的直接输出结果,经过一系列的处理,成为最终的reduce直接输入的数据为止的整个过程。这是mapreduce 的核心过程。该过程可以分为两个阶段:
3.1 map端的shuffle:由map处理后的结果并不会直接写入到磁盘中,而是会在内存里开启一个环形内存缓冲区,先将map的处理结果写入缓冲区中,这个缓冲区默认大小是100mb,并且在配置文件里为这个缓冲区设定了一个阀值,默认是0.80(这个大小和阀值都是可以在配置文件里进行配置的),同时map还会为输出操作启动一个守护线程,如果缓冲区的内存达到了阀值的80%时候,这个守护线程就会把内容写到磁盘上,这个过程叫spill,另外的20%内存可以继续写入要写进磁盘的数据,写入磁盘和写入内存操作是互不干扰的,如果缓存区被撑满了,那么map就会阻塞写入内存的操作,让写入磁盘操作完成后再继续执行写入内存操作。每次spill操作也就是写入磁盘操作时候就会写一个溢出文件,也就是说在做map输出有几次spill就会产生多少个溢出文件,随着数据不断读入内存缓冲区,会溢出产生多个小文件,等map输出全部做完后,map会合并这些输出文件成一个大文件(这个合并用到归并排序)。同时,在数据溢出转储到磁盘这一过程是复杂的,并不是直接写入磁盘,而是在写入磁盘前map会对数据执行分区partition,排序sort,合并combiner等操作。
3.1.1 分区partition:在数据写入内存时,决定数据由哪个reduce处理,从而分区。比如采用Hash法,有n个reducer,那么数据{“are”,1}的key"are"对n进行取模,返回m,从而生成{partition,key,value}。其实Partitioner操作和map阶段的输入分片(Input split)很像,一个Partitioner对应一个reduce作业,如果我们mapreduce操作只有一个reduce操作,那么Partitioner就只有一个,如果我们有多个reduce操作,那么Partitioner对应的就会有多个,Partitioner因此就是reduce的输入分片。注意,每个map的处理结果和partition处理的key value键值对结果都保存在缓存MemoryBuffer中。缓冲区中的数据:partition key value三元组数据:{“1”,“are”:1},{“2”,“at”:1},{“1”,“we”:1}。
3.1.2 排序sort: 在溢出的数据写入磁盘前会对数据按照key进行排序操作,默认算法为快速排序,第一关键字为分区号,第二关键字为key。这个是在写入磁盘操作时候进行,不是在写入内存时候进行的。例如缓冲区数据{“1”,“are”:1},{“2”,“at”:1}…{“1”,“are”:1},{“1”,“we”:1}排序后为{“1”,“are”:1}{“1”,“are”:1}{“1”,“we”:1}…{“2”,“at”:1}。

3.1.3 合并combiner:combiner阶段是程序员可以选择的。数据合并,在reduce计算前,对相同的key的数据,value值合并,减少输出传输量,Combiner函数事实上是本地化的reducer函数。但是combiner操作是有风险的,使用它的原则是combiner的输入不会影响到reduce计算的最终输入,例如:如果计算只是求总数,最大值,最小值可以使用combiner,但是做平均值或求中值计算使用combiner的话,最终的reduce计算结果就会出错。 例如:
Mapper端使用combiner
3 5 7 ->(3+5+7)/3=5
2 6 ->(2+6)/2=4
Reducer
(5+4)/2=9/2 不等于(3+5+7+2+6)/5=23/5

3.1.4 归并merge:每次溢写会生成一个溢写文件,这些溢写文件最终需要被归并成一个大文件。归并的意思:生成key和对应的value-list。 在Map任务全部结束之前进行归并,归并得到一个大的文件,放在本地磁盘。
合并(Combine)和归并(Merge)的区别:
两个键值对<“a”,1>和<“a”,1>,如果合并,会得到<“a”,2>,如果归并,会得到<“a”,<1,1>>。

3.2 reduce端的shuffle:由于map和reduce往往不在同一个节点上运行,所以reduce需要从多个节点上下载map的结果数据,多个节点的map里相同分区内的数据被复制到同一个reduce上,并对这些数据进行处理,然后才能作为reduce的输入数据被reduce处理。


3.2.1 Copy阶段:reduce端可能从n个map的结果中获取数据,而这些map的执行速度不尽相同,当其中一个map运行结束时,reduce就会从JobTracker中获取该信息。map运行结束后TaskTracker会得到消息,进而将消息汇报给 JobTracker,reduce定时从JobTracker获取该信息,reduce端默认有5个数据复制线程从map端复制数据。Reduce任务通过RPC向JobTracker询问Map任务是否已经完成,若完成,则复制数据。
3.2.2 Sort阶段:
Reduce复制数据先放入缓存,来自不同Map机器,与map一样,内存缓冲区满时,也通过sort和combiner,将数据溢写到磁盘文件中。如果形成了多个磁盘文件还会进行merge归并,最后一次归并的结果作为reduce的输入而不是写入到磁盘中。文件中的键值对是排序的。
当数据很少时,不需要溢写到磁盘,直接在缓存中归并,然后输出给Reduce。注意:当Reducer的输入文件确定后,整个Shuffle操作才最终结束。之后就是Reducer的执行了,最后Reducer会把结果存到HDFS上。
3.3 reduce阶段:和map函数一样也是程序员编写的,最终结果是存储在hdfs上的。每个reduce进程会对应一个输出文件,名称以 part-开头。
1.3 总结MapReduece的工作原理

下面再从map端和reduce端具体分析:
Map端流程:
1.每个输入分片会让一个map任务来处理,map输出的结果会暂时放在一个环形内存缓冲区中(该缓冲区的大小默认为100M),当该缓冲区快要溢出时(默认为缓冲区大小的80%),会在本地文件系统中创建一个溢出文件,将该缓冲区中的数据写入这个文件。
2.在写入磁盘之前,线程首先根据reduce任务的数目将数据划分为相同数目的分区,也就是一个reduce任务对应一个分区的数据。这样做事为了避免有些reduce任务分配到大量数据,而有些reduce任务却分到很少数据,甚至没有分到数据的尴尬局面。其实分区就是对数据进行hash的过程。然后对每个分区中的数据进行排序(默认快速排序),如果此时设置了combiner,将排序后的结果进行combiner操作,这样做的目的是让尽可能少的数据写入到磁盘。
3.当map任务输出最后一个记录时,可能会有很多的溢出文件,这时需要将这些文件归并。归并的过程中会不断地进行排序(归并排序)和combiner操作,目的有两个:一是尽量减少每次写入磁盘的数据量;二是尽量减少reduce复制阶段网络传输的数据量。最后归并成了一个已分区且已排序的文件。为了减少网络传输的数据量,这里可将数据压缩,只要将mapred.compress.map.out设置为true就可以了。
4.将分区中的数据拷贝给相对应的reduce任务。分区中的数据怎么知道它对应的reduce是哪个呢?其实map任务一直和其父TaskTracker保持联系,而TaskTracker又一直和JobTracker保持心跳。所以JobTracker中保存了整个集群的宏观信息。只要reduce任务向JobTracker获取对应的map输出位置就可以了。 Reduce端流程:
1.Reduce会接收到不同map任务传来的数据,并且每个map传来的数据都是有序的。如果reduce端接受的数据量相当小,则直接存储在内存中(缓冲区大小由mapred.job.shuffle.input.buffer.percent属性控制,表示用作此用途的堆空间的百分比),如果数据量超过了该缓冲区大小的一定比例(由mapred.job.shuffle.merge.percent决定),则对数据合并后溢写到磁盘中。
2.随着溢写文件的增多,后台线程会将它们合并成一个更大的有序的文件,这样做事为了给后面的合并节省时间。其实不管在map端还是reduce端,MapReduce都是反复地执行排序,合并操作,所以排序是hadoop的灵魂。
3.合并的过程中会产生许多的中间文件(写入磁盘了),但MapReduce会让写入磁盘的数据尽可能地少,并且最后一次合并的结果并没有写入磁盘,而是直接输入到reduce函数。
在map处理数据后,到reduce得到数据之前,这个流程在MapReduce中可以看做是一个shuffle过程。在经过map的运行后,我们得知map的输出是这样一个key/value对。到底当前的key应该交由哪个reduce去做呢,是需要现在决定的。MapReduce提供Partitioner接口,它的作用就是根据key或value及reduce的数量来决定当前的这对输出数据最终应该交由哪个reduce task处理。默认对key做hash后再对reduce task数量取模。默认的取模方式只是为了平均reduce的处理能力,如果用户自己对Partitioner由需求,可以定制并设置到job上。
1.4 MapReduece数据本地化
首先,HDFS和MapReduce是Hadoop的核心设计。对于HDFS,是存储基础,在数据层面上提供了海量数据存储的支持。而MapReduce,是在数据的上一层,通过编写MapReduce程序对海量数据进行计算处理。
在HDFS中,NameNode是文件系统的名字节点进程,DataNode是文件系统的数据节点进程。MapReduce计算框架中负责计算任务调度的JobTracker对应HDFS的NameNode角色,只不过一个负责计算任务调度,一个负责存储任务调度。MapReduce中负责真正计算任务的TaskTracker对应到HDFS的DataNode角色,一个负责计算,一个负责管理存储数据。
考虑到“本地化原则”,一般地,将NameNode和JobTracker部署到同一台机器上,各个DataNode和TaskTracker也同样部署到同一台机器上。

这样做的目的是将map任务分配给含有该map处理的数据块的TaskTracker上,也就是在input split所对应的数据块所在的存储节点上,由该节点的tasktracker执行map任务,同时将程序JAR包复制到该