最近在学习SLAM,顺便将C++类的知识复习一下。(其中部分官方定义和程序设计方法来源于西北工业大学魏英老师)
1.类的定义:
2.类成员的访问控制:
对类的成员进行访问,有两个访问源:类成员和类用户。class Test { public: void Sum(int a=0,int b=0); }; void Test::Sum(int a=0,int b=0) { cout<<a+b; }
class Test { public: void Sum(int a=0,int b=0); }; void Test::Sum(int a,int b) { cout<<a+b; }
3.对象的定义和使用:
说了这么多,怎么样才能实现在外部实现对类成员的访问呢?这就是我们要讨论的对象。Test test1 , test2; class Test test1 , test2;
Test *p; p = new Test;
delete p;
Test test; test.Sum(); Test *p; p = new Test; p->Sum(); Test test, &r = test; r.Sum();
4.构造函数与析构函数:
建立一个对象的时候,通常最需要做的工作就是初始化对象,如对数据成员赋初值,而构造函数就是用来在创建对象时初始化对象,为对象数据成员赋初值。为什么非得这么做呢?因为在类里面,数据成员不能够进行初始化。即:class Test { int x = 0; ... };
#include <iostream> using namespace std; class Test { public: Test (); Test (int x,int y); void Sum(); private: int a,b; }; Test::Test() { } Test::Test(int x,int y) { a=x; b=y; } void Test::Sum() { cout<<a+b; } int main() { Test test(3,4); test.Sum(); return 0; }
第一个为无参构造函数或默认构造函数,写这个函数的好处是当你在创建对象的时候并不想立即对它初始化,而是在后续的工作中再进行赋初值,即:
Test test;Test test;第二个构造函数就完成了我们的初始化工作,它有两个形参,分别给数据成员a,b进行初始化,定义对象的时候传入了 3和4,则 a和b 被初始化为 3 和 4 。因此程序运行的结果是 打印出了 7。
#include <iostream> using namespace std; class Test { public: Test (); Test (int x,int y); void Sum(); private: int a,b; }; Test::Test() { } Test::Test(int x,int y):a(x),b(y) { } void Test::Sum() { cout<<a+b; } int main() { Test test(3,4); test.Sum(); return 0; }
#include <iostream> using namespace std; class Test { public: Test () {} Test (int x,int y):a(x),b(y) {} void Sum(); private: int a,b; }; void Test::Sum() { cout<<a+b; } int main() { Test test(3,4); test.Sum(); return 0; }
#include <iostream> using namespace std; class Test { public: Test () {} Test (int x,int y):a(x),b(y) {} void Sum(); private: int a,b; }; void Test::Sum() { cout<<a+b; } class AnotherTest { public: AnotherTest(int i,int j):test(i,j) {test.Sum();} private: Test test; }; int main() { AnotherTest test(3,4); return 0; }
下面是一个带默认参数的构造:
#include <iostream> using namespace std; class Test { public: Test () {} Test (int x = 0,int y = 0):a(x),b(y) {} void Sum(); private: int a,b; }; void Test::Sum() { cout<<a+b; } int main() { Test test(3); test.Sum(); return 0; }
Test (int x = 0,int y):a(x),b(y) {}
复制构造函数
Test test1(3,4); Test test2 = test1;
#include <iostream> using namespace std; class Test { public: Test () {} Test (int x ,int y):a(x),b(y) {} Test (const Test& t):a(t.a),b(t.b) {} void Sum(); private: int a,b; }; void Test::Sum() { cout<<a+b; } int main() { Test test1(3,4); Test test2 = test1; test2.Sum(); return 0; }
Test test2(test1);
#include <iostream> #include <cstring> using namespace std; class Test { public: Test (int x,char *ptr) { a = x; p = new char [x]; strcpy(p,ptr); } Test (const Test& C) { a = C.a; p = new char [a]; p = C.p; } void Print(); private: int a; char *p; }; void Test::Print() { int i = 0; while(p[i] != '�') { cout<<p[i]; i++; } } int main() { char p[5] = "test"; Test a(10,p); Test b(a); b.Print(); return 0; }
Test (const Test& C) { a = C.a; p = new char [a]; if(p != 0) strcpy(p,C.p); }
#include <iostream> #include <cstring> using namespace std; class Test { public: Test (int x,char *ptr) { a = x; p = new char [x]; strcpy(p,ptr); } Test (const Test& C) { a = C.a; p = new char [a]; if(p != 0) strcpy(p,C.p); } ~Test() { delete (p); cout<<"p has been destroyed"<<endl; } void Print(); private: int a; char *p; }; void Test::Print() { int i = 0; while(p[i] != '�') { cout<<p[i]; i++; } cout<<endl; } int main() { char p[5] = "test"; Test a(10,p); Test b(a); b.Print(); return 0; }

5.友元机制:
C++提供了友元机制,允许一个类将其非公有成员的访问权限授予指定的函数或类。友元的声明只能在类定义的内部,因此,访问类非公有成员除了自身成员,还有友元。#include <iostream> #include <cstring> using namespace std; class Test { public: Test (int a) { x = a; } ~Test() //析构函数 { } friend void Print(Test& a,Test& b); private: int x; }; void Print(Test& a,Test& b) { cout<<a.x*b.x; } int main() { Test a(10); Test b(3); Print(a,b); return 0; }
#include <iostream> #include <cstring> using namespace std; class B; //类的前向声明 class A { public: A(){} ~A() //析构函数 { } void Print(B& a); }; class B { public: B (int a) { x = a; } private: int x; friend void A::Print(B& a); }; void A::Print(B& a) { cout<<a.x; } int main() { B test1(3); A test2; test2.Print(test1); return 0; }
友元类的关系是单向的,即 A 是 B 的友元,B 不是 A 的友元,类 B 不能访问 A 的数据成员。此外,友元的关系不能传递或继承,类 B 是类 A 的友元,C 是 B 的友元,那么 C 不是 A 的友元,除非另外声明一次。
6.继承与派生:
#include <iostream> using namespace std; class Parallelogram { public: Parallelogram(int a,int b):length(a),width(b) {} int getLength(){return length;} int getWidth() {return width;} private: int length,width; }; class Rectangle : public Parallelogram //公有继承 { public: Rectangle(int a,int b):Parallelogram(a,b) {} //先对基类中的数据成员进行初始化 void Area() //计算面积 { cout<<getLength()*getWidth(); } }; int main() { Rectangle r(3,4); r.Area(); return 0; }
C++还支持一个派生类同时继承多个基类。
{
成员列表
}
同样,派生类的构造函数初始化列表在调用基类构造函数也应该按定义时的先后次序。
接下来我们看个例子:
#include <iostream> using namespace std; class BaseOne { public: BaseOne() {cout<<"This is BaseOne"<<endl;} BaseOne(int a):data(a) {cout<<"BaseOne's data is "<<data<<endl;} private: int data; }; class BaseTwo { public: BaseTwo() {cout<<"This is BaseTwo"<<endl;} BaseTwo(int a):data(a) {cout<<"BaseTwo's data is "<<data<<endl;} private: int data; }; class BaseThree { public: BaseThree() {cout<<"This is BaseThree"<<endl;} }; class Derive:public BaseOne,public BaseTwo,public BaseThree { public: Derive () {cout<<"This is Derive"<<endl;} Derive (int a,int b,int c,int d,int e):BaseOne(a),BaseTwo(b),dataOne(c),dataTwo(d),data(e) {cout<<"Derive's data is "<<data<<endl;} private: BaseOne dataOne; BaseTwo dataTwo; int data; }; int main() { Derive r1; cout<<endl; Derive r2(1,2,3,4,5); return 0; }
程序运行结果如下:
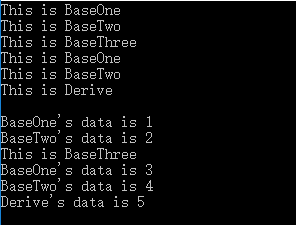
在调用派生类的默认构造函数时,即使没有写出调用基类的默认构造函数,系统也会调用基类的默认构造函数,而在结果的第4 , 5行还调用了一次,原因是派生类里有两个基类的数据成员,因此我们可以观察到,程序先调用了基类的构造函数,然后调用派生类中子对象的构造函数,最后调用派生类的构造函数。
在调用构造函数的时候,先调用基类的构造函数,虽然BaseThree没有参数,但是仍然会调用它的构造函数,然后初始化子对象,调用构造函数,最后调用派生类的构造函数。
二义性问题:
假定我们有如下程序:
#include <iostream> #include <cstring> using namespace std; class A { public: void fun() {cout<<"This is A"<<endl;} }; class B { public: void fun() {cout<<"This is B"<<endl;} }; class C:public A,public B { public: void hun() {fun();} //产生二义性 }; int main() { C c; c.hun(); return 0;
}
相信看到这里大家都知道二义性问题的产生原因了吧,就是两个基类存在名称相同的数据成员,而派生类在调用基类数据成员的时候如果没有显式的指出它属于谁,那么程序就会产生错误,现在我们做如下修改:
void hun() {A::fun(); B::fun();}
这次程序会分别调用 A 和 B 的 fun() 函数。我们要做的只是在它前面写上 基类名加上域运算符 :: ,当然也可以通过 对象名.基类名 :: 和 对象指针名.基类名 :: 这两种方式。
虚基类:
假定我们现在有这样一种继承关系:
#include <iostream> using namespace std; class A { public: void fun() {cout<<"This is A"<<endl;} }; class B:public A { public: void gun() {cout<<"This is B"<<endl;} }; class C:public A { public: void hun() {cout<<"This is C"<<endl;} }; class D:public B,public C { public: void kun() {fun();} //产生二义性 }; int main() { D d; d.kun(); return 0; }
A 是基类,B 是 A 的派生类,C 也是 A 的派生类,而 D 是 B 和 C 的派生类,因此 D 可以访问 A 的数据成员,但现在会产生二义性问题,我们必须显式的指出 fun() 是来自 B 的 还是来自 C 的,但是我们都知道它来自 A , 因此我们希望找到一种方式,使得在继承间接共同基类时只保留一份成员,这就用到了虚基类的机制。
虚基类是在派生类定义时,指定继承方式时声明的。声明的一般形式:
class 派生类名 : virtual 访问标号 虚基类名 , ...
{
成员列表
}
为了保证虚基类在派生类中只继承一次,应当在所有直接派生类中声明为虚基类。依然是上面那个程序,我们只需要:
class B:virtual public A class C:virtual public A
这样我们在类 D 中调用 fun() 函数,就不用指出它究竟属于谁。
接下来我们来看看虚基类构造函数和析构函数的一些特性。
有这样一个程序:
#include <iostream> using namespace std; class A { public: A() {cout<<"This is Grandpa"<<endl;} A(int a):One(a) {cout<<"Grandpa is "<<One<<" years old"<<endl;} ~A() {cout<<"A is over"<<endl;} private: int One; }; class B:virtual public A { public: B() {cout<<"This is father"<<endl;} B(int a,int b):A(a),Two(b) {cout<<"father is "<<Two<<" years old"<<endl;} ~B() {cout<<"B is over"<<endl;} private: int Two; }; class C:virtual public A { public: C() {cout<<"This is mother"<<endl;} C(int a,int b):A(a),Three(b) {cout<<"mother is "<<Three<<" years old"<<endl;} ~C() {cout<<"C is over"<<endl;} private: int Three; }; class D:public B,public C { public: D() {cout<<"This is me"<<endl;} D(int a,int b,int c,int d):A(a),B(a,b),C(a,c),Four(d) {cout<<"I am "<<Four<<" years old"<<endl;} ~D() {cout<<"D is over"<<endl;} private: int Four; }; int main() { D d1; cout<<endl; //D d2(65,40,39,13); return 0; }
首先看默认构造函数(先把d2注释掉),程序运行结果如下:

程序会自动调用构造函数,首先调用虚基类的构造函数,然后再根据派生类继承的次序调用构造函数,如果我们先继承了 C 类,那么先调用 C 类的构造函数。析构函数的调用则正好相反。
接下来看有参的,给 d1 加上注释,去掉 d2 的注释,程序运行结果如下:

调用次序是一样的,因此虚基类的构造函数优先于非虚基类的构造函数进行执行,如果在虚基类中定义了带参数的构造函数,而且没有定义默认构造函数,则在其所有的派生类里(直接和间接)中,都必须通过构造函数的初始化列表对其进行初始化,在最后的派生类中不单单对直接继承的类进行初始化,还要对虚基类进行初始化。
7.多态性和虚函数:
首先介绍一下多态性,多态是指同样的消息被不同类型的对象接收时导致不同的行为,我们举个通俗易懂的例子,假定我们现在有一个模具,这个模具是一个人型模具,根据倒入里面金属液体的不同,它最终会形成不同类型的器件,如果倒入的是液体黄金,那么它会形成一个小金人,如果倒入的是铁水,那就会形成一个小铁人,多态大概就是这样的意思。
多态性可以通过很多方法实现,而我们要说的是 包含多态 实现多态性,C++采用虚函数实现包含多态,至少含有一个虚函数的类成为多态类。
在介绍虚函数之前,我们介绍两种联编。联编就是将模块或者函数合并在一起生成可执行代码的处理过程,同时对每个模块或者函数分配内存地址,并且对外部访问也分配正确的内存地址。
在编译阶段就将函数实现和函数调用绑定起来称为静态联编,程序运行的时候才进行函数实现和函数调用的绑定称为动态联编。
我们举个例子:
#include <iostream> using namespace std; class A { public: void fun() {cout<<"Use A"<<endl;} }; class B : public A { public: void fun() {cout<<"Use B"<<endl;} }; int main() { B b; A *p = &b; p->fun(); return 0; }
我们声明了一个指向类 B 的指针,但是程序的输出结果是:

之所以会这样是因为我们将其定义为 A 类型,程序在编译阶段就已经确定 A 类型的指针调用的 fun() 是 A 类的成员。
接下来我们来看动态联编:
给刚才类 A 的 fun() 函数前面加上 virtual ,
virtual void fun() {cout<<"Use A"<<endl;}将其定义为了虚函数,再次运行:
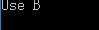
当编译器编译含有虚函数的类时,将为它建立一个虚函数表,相当于一个指针数组,存放每个虚函数的入口地址,编译器为该类增加一个额外的数据成员,这个数据成员是一个指向虚函数表的指针,通常称为vptr。这个例子中,A 类有一个虚函数 fun() , 所以虚函数表里只有一项,如果派生类没有重写这个虚函数,那么虚函数表里的元素所指向的地址就是基类虚函数的地址,重写之后,则 vptr 指向派生类的虚函数地址。
派生类可以继承基类的虚函数表,而且只要和基类同名的成员函数,无论前面加不加 virtual ,都会自动成为虚函数,虚函数的调用规则是,根据当前对象,优先调用对象本身的成员函数。
虚析构函数:
如果将基类的析构函数声明为虚函数,那么其派生类的析构函数也变为虚析构函数,即使名字不同,当基类的析构函数是虚析构函数时,无论指针指的是同一类族中的哪一个类对象,系统总会采用动态联编,调用正确的析构函数,对该对象进行清理。C++中,不支持虚构造函数。
纯虚函数:
许多情况下,不能在基类中为虚函数给出一个有意义的定义,那就将其声明为纯虚函数,具体怎么实现交给派生类去做,纯虚函数的定义形式为:
virtual 返回类型 函数名 (形式参数列表) = 0;
纯虚函数的作用是在基类中为其派生类保留一个函数的名字,以便派生类根据需要对其进行定义,如果一个类里声明了虚函数,而在其派生类中没有对该函数定义,那么该函数在派生类中仍然为纯虚函数。含有纯虚函数的类成为抽象类,抽象类不能定义对象,如果派生类里给出了抽象类中纯虚函数的实现,那么该派生类不再是抽象类,否则仍然是抽象类。抽象类至少含有一个纯虚函数。
接下来我们看一个计算圆形面积和圆柱体体积的程序:
#include <iostream> using namespace std; class Sharp { public: virtual double area() = 0; virtual double volumn() = 0; }; class Circle : public Sharp { public: Circle(double r):R(r) {} virtual double area() {return 3.1415926*R*R;} virtual double volumn() {return 0;} private: double R; }; class Cylinder : public Circle { public: Cylinder(double a,double b):Circle(a),H(b) {} virtual double volumn() {return area()*H;} private: double H; }; int main() { Circle a(20.0); Cylinder b(10.0,2.0); cout<<a.area()<<endl; cout<<b.volumn()<<endl; return 0; }
程序运行结果:
