- 重视Code Review
- 极致——目标是成为优秀的开发者
- Data tells a story!(数据会讲故事)
分析过程对于建模非常的重要,可以帮助我们减少实际上不相关的特征被错误的加入到模型中,尽管在一些模型里,比如线性回归,在建模后期可以通过一定的方法将这些不相关的特征识别出来,但既然能够通过前期的数据观察排除,何不在一开始就做好呢,有句话在建模领域非常有名:garbage in, garbage out
数据的中心:众数、平均数和中位数
- 要点:模型构建&验证比较模型
一、Why?
- 为什么要学习统计的基本概念
一些统计学基本概念,如何用众数,平均数和中位数衡量数据的中心,如何用值域,IQR,方差/标准差来衡量数据的差异。你很有可能已经熟知所有这些统计概念的定义,那么不妨你可以思考一下:
- 为什么我们需要多个指标?
- 这多个指标如何演化而来?
- 他们之间的优劣是什么?
- 针对不同的数据集,我应该如何如何选择最适合的指标?
这样的思考会贯穿在整个机器学习过程中,当你学习了多个模型的衡量指标,当你学了多个机器学习的算法。如何比较他们的优劣,如何选择最合适的算法将会是我们一直在讨论的问题。
What?
- Measures of center(中心测量方法)——描述分布中心的情况(集中程度)
二、众数(Mode)
2.1 定义:
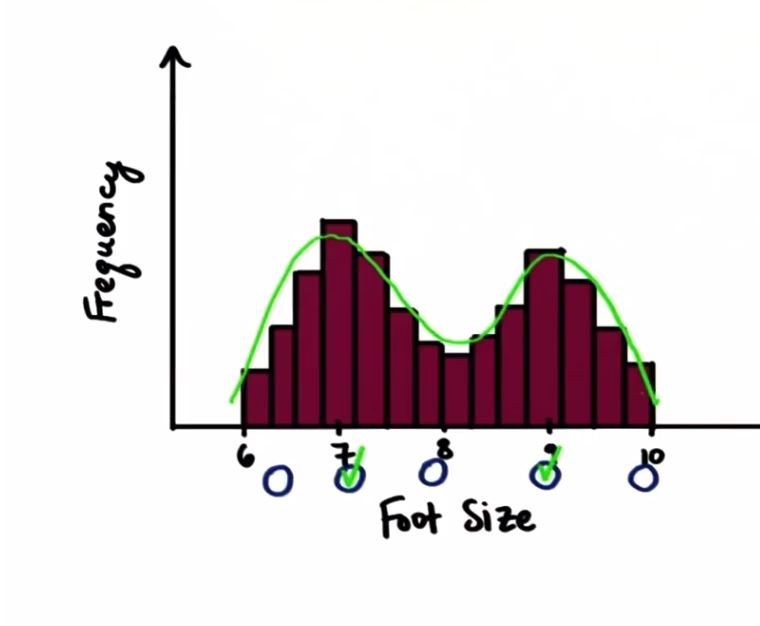
众数是指一组数据中出现频率最高(the highest frequency)的那个数据(从x-axis寻找)。一组数据可以有多个众数,也可以没有众数。
众数是由英国统计学家皮尔生首先提出来的。所谓众数是指社会经济现象中最普遍出现的标志值。从分布角度看,众数是具有明显集中趋势的数值。
- 均匀分布没有众数
- 多峰分布可以有多个众数
三、平均数(Mean)
- sample样本均值 x bar x横
- population总体均值 μ
** Mean和Average区别**
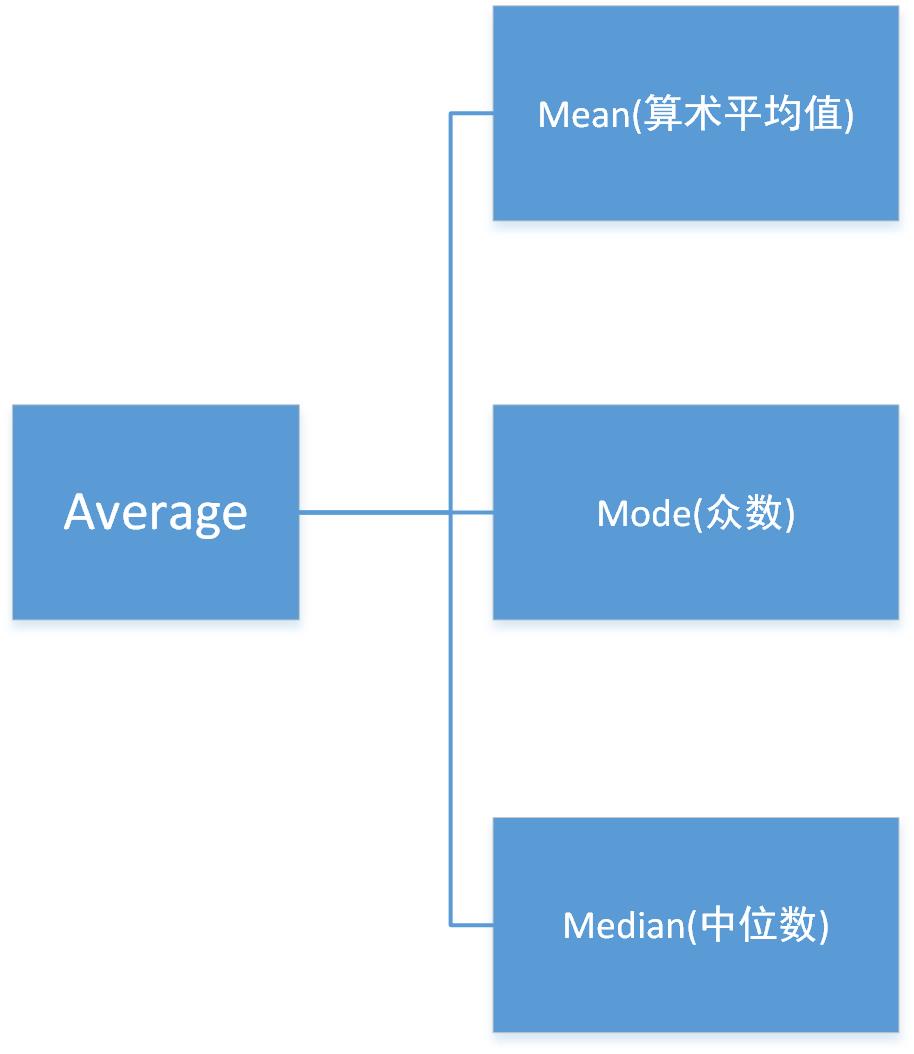
概念对比 Mean&Average
四、中位数
-
众数不受异常值影响,而平均值容易受异常值影响
-
寻找一个两全齐美的方法——中位数Median
-
Robust 稳健性