第一章、认识R语言
参考书:R语言实战
一、数据分析概述:
1.数据分析概念:数据分析是指用适当的统计方法对收集来的大量数据进行分析,提取有用的信息和形成结论来对数据加以详细研究和概括总结的过程。
2.数据分析原则:
(1)为了验证假设,必须提供必要的数据验证。即构建完分析模型后,需要利用测试数据验证模型的正确性。
(2)数据分析是为了发现更多的问题,找到深层次原因。
(3)做数据分析首先要有明确的问题和目标。
3.数据分析步骤

主要阶段为:
探索性数据分析:这一部分是比较重要的,通常需要数据清洗和整合。
模型选定分析:通过定量分析提出一类或几类可能的模型;再进一步分析,确定一类适合的模型。
推断分析使用数理统计的方法。对所确定模型或估计的可靠程度和精度做出推断。
4.“大数据”的分析过程:
数据采集、预处理、统计和分析、数据挖掘(与统计分析不同,数据挖掘一般没有什么预先设定好的主题)
5.数据分析常用的工具
Excel、SPSS、SAS、Matlab、R、Python
二、R语言简介:
1.R语言概述:
R是用于统计分析和绘图的编程语言和软件环境。
R两大重点:处理数据的方法+实现数据可视化
2.R语言特点及其使用:
(1).R是一种区分大小写的解释型语言。
(2).R语句是由函数和赋值构成。R使用<-,而不是传统的=作为赋值符号。注释由符号#开头。
(3).R工作空间workspace,用于管理R工作空间函数,和shell编程类似。
(4).package很重要:包是R函数、数据、预编译代码以一种定义完善的格式组成的集合。计算机上存储包的目录成为库(library)。library()则可以显示库中有哪些包。
执行install.packages(“package name”)即可下载和安装包(注意有引号),提前设置好下载镜像CRAN。
包的载入:要在R会话中使用包,需要用library(package name)命令载入这个包。
三、R的数据结构与数据输入
1.创建数据集
(1).按照个人要求的格式来创建含有研究信息的数据集,是数据分析的第一步。具体步骤为:
①选择一种数据结构来存储数据
②将数据输入或导入这个数据结构中
创建数据集后,往往需要对它进行标注,也就是对变量以及代码添加描述性的标签。
(2).数据集 data set :是一个数据的集合,通常以数据库表格的形式出现
统计学家称 行 为 观测 observation ,称 列 为 变量 variable
数据库分析师称 行 为 记录 record,称 列 为 字段 field
数据挖掘/机器学习学科称 行 为 示例 example,称 列 为 属性 attribute
2.基本的数据结构(向量、矩阵、数组、数据框、因子、列表)
(1).R的数据结构包括向量、数组、数据框和列表。
(2).R可以处理的数据类型(types)[ 也叫作模式(modes) ]包括数值型、字符型、布尔型、复数型和原生型(字节)。
3.数据结构特点及举例
向量、矩阵、数组的本质是数组,数组中的数据必须拥有相同的模式(数据类型)。
数据框的各列模式可以不同。

(1).Vectors 向量
向量是用于存储数值型、字符型或逻辑型数据的一组数组。
①.执行组合功能的函数c()可用来创建变量

标量(单个数值)是只含一个元素的向量。
②.访问向量中的元素
方括号[]用于访问向量中的元素
![]() 访问a中的第二个和第四个元素
访问a中的第二个和第四个元素
![]() 访问a中的第四个元素
访问a中的第四个元素
![]() 返回a中的第二到第四的所有元素
返回a中的第二到第四的所有元素
(2).Matrix 矩阵
矩阵是一个二维数组,每个元素都拥有相同的模式。通过函数matrix创建矩阵
①创建格式:

其中 vector包含了矩阵的元素,nrow和ncol用来指定行和列的维数,dimnames包含了可选的、以字符型向量表示的行名和列名。选项byrow则表明矩阵按行填充(byrow=TRUE)还是按列填充(byrow=FALSE),默认情况下是按列填充。
②创建实例:
#create matrix
cells<-c(1,2,4,6)
rnames<-c("R1","R2")
cnames<-c("C1","C2")
mymatrix<-matrix(cells,nrow = 2,ncol = 2,
byrow = TRUE,dimnames = list(
rnames,cnames))
view(mymatrix)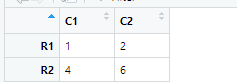
③矩阵下标的使用:
使用数组下标和方括号来按照矩阵中的行、列或单个元素
X[i,]指矩阵X中的第i行,X[,j]指第j列,X[i,j]指第i行第j个元素。选择多行或多列时,下标i和j可为数值型向量。
示例:
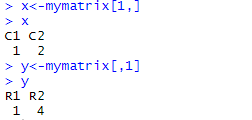 输出了第一行和第一列
输出了第一行和第一列
![]() 输出第一行第一列的元素
输出第一行第一列的元素
![]() 输出第一行第一二列的元素
输出第一行第一二列的元素
(3).Arrays 数组
①创建数组:
数组与矩阵类似,但是维度可以大于2。可通过array函数创建
![]()
其中vector包含了数组中的数据,dimensions是一个数值型向量,给出了各个维度下标的最大值,而dimnames是可选的、各维度名称标签的列表,依次按需命名标签
②数组示例:
#create array
dim1<-c("A1","A2")
dim2<-c("B1","B2","B3")
dim3<-c("C1","c2","c3","c4")
z<-array(1:24,c(2,3,4),dimnames = list(dim1,dim2,dim3))
z
③数组元素查找:
选取元素的方式与矩阵相同,使用方括号[]
(4)Data frames 数据框
①数据框不同的列可以包含不同的模式(数值型、字符型等)的数据,是R中最常处理的数据结构。通过函数data.frame()创建。
![]()
其中列向量col1,col2,col3等可为任意类型(如字符型、数值型、布尔型等)。每一列名称可由函数names指定。
②数据框示例
#Creating a dataframe:糖尿病患者数据
patientID<-c(1,2,3,4)
age<-c(25,34,28,52)
diabetes <- c("Type1", "Type2", "Type1", "Type1")
status <- c("Poor", "Improved", "Excellent", "Poor")
patientdata <- data.frame(patientID, age, diabetes, status)
③选取数据框中的元素
patientdata[1:2]#选取第一二列
patientdata[c("diabetes","status")]#根据列名选择数据
patientdata[2,]#选择第二行
patientdata$age #选择age列
patientdata$age[2]#选择age列的第二个元素
#符号 $ 用来选取数据框中的特定变量,相当于“.”
④数据框常用的一些函数
attach():函数attach()可将数据框添加到R的搜索路径中。R在遇到一个变量名以后,不用再使用$,将检查搜索路径中的数据框,以定位到这个变量。
例:
![]()

![]() 再次运行,显示可以正常运行,画出的图像如下:
再次运行,显示可以正常运行,画出的图像如下:

detach():将数据框从搜索路径中移除。当detach()造成数据对象重名时,原始对象将取得优先权。
所以,函数attach()和detach()最好在分析一个单独的数据框,并且不太可能对多个同名对象时使用。
with():attach()的替代
为了避免频繁attach、detach,可以使用with。
例:
with(patientdata,{
plot(patientID,age)
plot(patientID,status)
})

大括号{}之间的语句都是针对数据框patientdata执行,这样就无需担心名称冲突了,如果只有一条语句,大括号可以省略
(5)Factors 因子
数据类型分为类别(nominal:糖尿病类型)、有序(ordinal:病情的好、中、坏)、连续型(continuous:年龄)
①因子的概念:
在R中,类别变量和有序变量被称为因子。
因子在R中非常重要,它决定了数据的分析方式以及如何进行视觉呈现。
②因子的生成
函数factor()以一个整数向量的形式存储类别值。
例:
diabetes
str(diabetes)
diatype<-factor(diabetes)#函数会自动统计被转化对象的种类数并赋值为相应的整数值。
str(diatype)
对于字符型向量,因子的水平默认依字母顺序创建。可以通过制定levels选项来覆盖默认排序。
![]()
如果用字符向量创建数据框,R会将向量转化为因子。
(6)Lists 列表
列表就是一些对象的有序集合。列表中可能是若干向量、矩阵、数据框,甚至其他列表的组合
(7)对这些数据结构操作要注意的地方:
①R不提供多行注释或块注释功能。
②将一个值赋给某个向量、矩阵、数组、或列表中一个不存在的元素时,R将自动扩展到这个数据结构以容纳新值。
vec<-c(1,1,0,9)
vec[7]<-85
vec
③R中没有标量。标量是以单元素向量的形式出现的。R中的下标不是从0开始,而是从1开始的。
④变量无需提前声明。他们在首次被赋值时生成。
3.数据的输入和导出(支持多种数据源)

(1)使用键盘输入数据
edit()会自动调用一个允许手动输入数据的 文本编辑器。
例: patientdata<-edit(patientdata)

函数edit()事实上是在对象的一个副本上进行操作的。如果不将其赋值到一个目标,所有修改将会全部丢失!
(2)从带分隔符的文本文件导入数据(csv文件)
read.table()从带分隔符的文本文件中导入数据
![]()
header表明首行是否包含了变量名,sep指定分隔符,row.names是一个可选参数,用来指定一个或多个标识符
例:
![]()
默认情况下,字符型变量将转化为因子。
(3)导入Excel数据
读取Excel文件的最好方式就是在Excel中将其导出为csv文件,再使用csv文件的导入方式。
(4)导入XML数据
使用R的XML包,最重要两个函数是xmlTreeParse()和 getNodeSet(),前者负责抓取页面数据并形成树状结构,后者对抓取的数据根据XPath语法来选取特定的节点集合。
(5)导入SPSS数据
SPSS数据集可以通过foreign包中的函数read.spss()导入到R中,也可以使用Hmisc包中的spss.get()函数
(6)导入SAS数据
SAS的版本更新可能会导致R中导入SAS数据集的函数失效。可以采用以下方法:
①以在SAS中使用PROC EXPORT将SAS数据 集保存为一个逗号分隔的文本文件
②再使用处理csv的方法
(7)访问数据库管理系统
R有多种面向关系型数据库管理系统的接口
4.处理数据对象的常用函数

