
一 什么是回归?
回归的目的是预测数值型的目标值,最直接的办法是依据输入,写入一个目标值的计算公式。
假如你想预测小姐姐男友汽车的功率,可能会这么计算:
HorsePower = 0.0015 * annualSalary - 0.99 * hoursListeningToPublicRadio
这就是所谓的回归方程(regression equation),其中的0.0015和-0.99称为回归系数(regression weights),求这些回归系数的过程就是回归。一旦有了这些回归系数,再给定输入,做预测就非常容易了。具体的做法是用回归系数乘以输入值,再将结果全部加在一起,就得到了预测值。
说到回归,一般都是指线性回归(linear regression),所以本文里的回归和线性回归代表同一个意思。线性回归意味着可以将输入项分别乘以一些常量,再将结果加起来得到输出。需要说明的是,存在另一种成为非线性回归的回归模型,该模型不认同上面的做法,比如认为输出可能是输入的乘积。这样,上面的功率计算公式也可以写做:
HorsePower = 0.0015 * annualSalary / hoursListeningToPublicRadio
这就是一个非线性回归的例子,本文对此不做深入讨论。
二 揭开线性回归的神秘面纱
我们想找链家卖一套房子,那么链家的人会问房子有多大,有几个卧室,距离市区有多远,是不是学区房,为什么他们要这些信息呢,是因为他们能根据我们所提供的信息,根据他们的经验,去预测我们这套房子能卖多少钱,我们不妨设房间大小,卧室等因素为 x ,那么我们预测的房价的式子可以用这个方程来表示: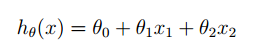
这个方程表示了我们的所预测的房子的价格,但是,这个式子看起来有点不太方便,那么我们就假定一个X0 = 1, 那么这个式子就可以进行转变为下面的矩阵方程:
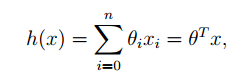
对于我们来说,我们已经知道了预测函数,为了更好的优化这个预测函数,我们需要知道这个算法的损失函数,也就是预测值与真实值的差距,这个差距当然越小越好,根据《统计学习方法》我们可以选择下面的方程作为损失函数:
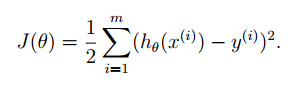
在这个式子中,前面的2为了计算方便所设置的,为什么要使用这个方程,可以看吴恩达视频里面的推导,也可以理解我们做的预测值是符合正态分布的,这个式子与正态分布相契合。上面的这个式子也可以使用矩阵方程进行表述,那么他将变为:
![]()
我们知道,我们需要的求出最合适的预测值,也就是损失函数最小,损失函数最小,也就是他的倒数为0, 那么:
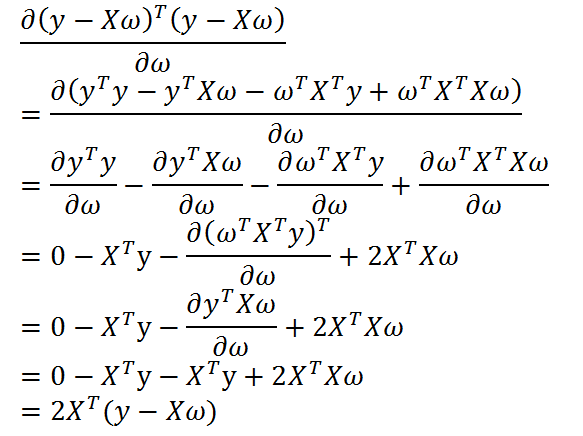
令上述公式等于0,得到:
![]()
w上方的小标记表示,这是当前可以估计出的w的最优解。从现有数据上估计出的w可能并不是数据中的真实w值,所以这里使用了一个"帽"符号来表示它仅是w的一个最佳估计。
值得注意的是,上述公式中包含逆矩阵,也就是说,这个方程只在逆矩阵存在的时候使用,也即是这个矩阵是一个方阵,并且其行列式不为0。
上述的最佳w求解是统计学中的常见问题,除了矩阵方法外还有很多其他方法可以解决。通过调用NumPy库里的矩阵方法,我们可以仅使用几行代码就完成所需功能。该方法也称作OLS, 意思是“普通小二乘法”(ordinary least squares)。
下面我们就开始写出代码,做出一条线性预测的直线
我们先看下数据集,数据下载地址:
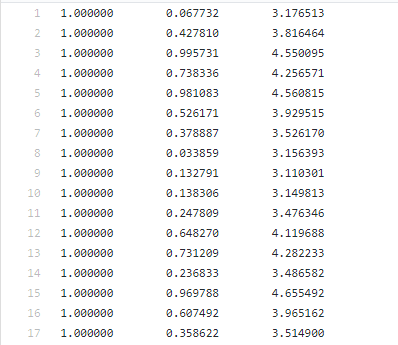
第一列都为1.0(我们无需添加x1这一行了),即x0。第二列为x1,即x轴数据。第三列为x2,即y轴数据。首先绘制下数据,看下数据分布。编写代码如下


1 import numpy as np 2 import matplotlib.pyplot as plt 3 4 def loadDataSet(fileName): 5 """ 6 功能:导入数据 7 输入:file 8 输出:X, y 9 """ 10 data = np.loadtxt(fileName) 11 X = data[:,0:-1] 12 y = data[:,-1] 13 return X, y 14 15 def plotDataSet(data, result): 16 """ 17 功能 画出原始的图像 18 """ 19 m = len(data) 20 xcode = []; ycode = [] 21 22 for i in range(m): 23 xcode.append(data[i][1]) 24 ycode.append(result[i]) 25 26 plt.figure(dpi = 100) 27 plt.subplot(111) 28 plt.scatter(xcode, ycode, c = 'b', s = 10) 29 plt.title('DataSet') 30 plt.xlabel('X') 31 plt.show() 32 33 34 if __name__ == "__main__": 35 X, y = loadDataSet("data.txt") 36 plotDataSet(X, y) 37 weight = standRegres(X, y) 38 print (weight) 39 plotPreData(X, y, weight)
这样我们就可以得到图像:

其次,我们使用上面的公式,得到权重:
import numpy as np
import matplotlib.pyplot as plt
def loadDataSet(fileName):
"""
功能:导入数据
输入:file
输出:X, y
"""
data = np.loadtxt(fileName)
X = data[:,0:-1]
y = data[:,-1]
return X, y
def plotDataSet(data, result):
"""
功能 画出原始的图像
"""
m = len(data)
xcode = []; ycode = []
for i in range(m):
xcode.append(data[i][1])
ycode.append(result[i])
plt.figure(dpi = 100)
plt.subplot(111)
plt.scatter(xcode, ycode, c = 'b', s = 10)
plt.title('DataSet')
plt.xlabel('X')
plt.show()
def standRegres(data, result):
"""
功能:求出权重值
w = (X.T * X).I * X.T * y
输入:X, y
输出:权重值
"""
xMat = np.mat(data)
yMat = np.mat(result).T
xTx = xMat.T * xMat
if np.linalg.det(xTx) == 0.0:
print("矩阵为奇异矩阵,不能求逆")
return
weight = xTx.I * (xMat.T * yMat)
return weight
if __name__ == "__main__":
X, y = loadDataSet("data.txt")
plotDataSet(X, y)
weight = standRegres(X, y)
print (weight)
在这里,我们得到了X的权重值,然后我们根据权重值,绘制出预测函数:
# -*- coding: utf-8 -*- """ Created on Sat Jun 9 16:10:52 2018 函数:线性回归 @author: Administrator """ import numpy as np import matplotlib.pyplot as plt def loadDataSet(fileName): """ 功能:导入数据 输入:file 输出:X, y """ data = np.loadtxt(fileName) X = data[:,0:-1] y = data[:,-1] return X, y def plotDataSet(data, result): """ 功能 画出原始的图像 """ m = len(data) xcode = []; ycode = [] for i in range(m): xcode.append(data[i][1]) ycode.append(result[i]) plt.figure(dpi = 100) plt.subplot(111) plt.scatter(xcode, ycode, c = 'b', s = 10) plt.title('DataSet') plt.xlabel('X') plt.show() def standRegres(data, result): """ 功能:求出权重值 w = (X.T * X).I * X.T * y 输入:X, y 输出:权重值 """ xMat = np.mat(data) yMat = np.mat(result).T xTx = xMat.T * xMat if np.linalg.det(xTx) == 0.0: print("矩阵为奇异矩阵,不能求逆") return weight = xTx.I * (xMat.T * yMat) return weight def plotPreData(X, y, weight): """ 功能: 画出预测函数的线 输入:X, y, 权重 """ m = len(X) xcode = []; ycode = [] for i in range(m): xcode.append(X[i][1]) ycode.append(y[i]) xCopy = X.copy() yHat = xCopy * weight plt.figure(dpi = 100) plt.subplot(111) plt.scatter(xcode, ycode, c = 'b', s = 10) plt.plot(xCopy[:,1], yHat, c = 'r') plt.title('DataSet') plt.xlabel('X') plt.show() if __name__ == "__main__": X, y = loadDataSet("data.txt") plotDataSet(X, y) weight = standRegres(X, y) print (weight) plotPreData(X, y, weight)
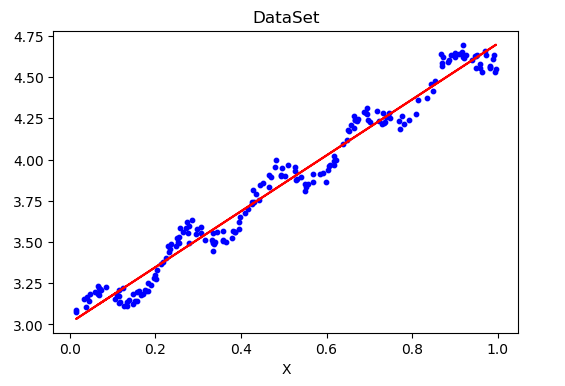
我们可以看到,在这个预测结果中,虽然预测出了结果,但是效果不太好,有一些欠拟合,如何改进,将在下一节中进行优化
参考资料: