对Ayoosh Kathuria的YOLOv3实现进行翻译和总结,原文链接如下:
https://blog.paperspace.com/how-to-implement-a-yolo-v3-object-detector-from-scratch-in-pytorch-part-3/
*首先翻译遵循不删不改的原则有一说一,对容易起到歧义的中文采取保留英文的方式。其中对原文没有删减但是略有扩充,其中某些阐释是我一句话的总结,如有错误请大家在留言区指出扶正。
这是从头开始实现YOLO v3检测器教程的第3部分。 在上一部分中,我们实现了YOLO架构中使用的层,在这一部分中,我们将在PyTorch中实现YOLO的网络架构,以便我们可以根据图像生成输出。
我们的目标是设计网络的前向传播。
我们将会使用PyTorch并基于YOLO v3来实现一个目标检测器,这是一种速度更快的目标检测算法。
本教程的代码在Python 3.5和PyTorch 0.4上运行。在这个Github repo中可以完整地找到它。
Part 1 : Understanding How YOLO works
Part 2 : Creating the layers of the network architecture
Part 3 (This one): Implementing the forward pass of the network
Part 4 : Objectness score thresholding and Non-maximum suppression
Part 5 : Designing the input and the output pipelines
1.先决条件
- 本教程的第1和第2部分。
- PyTorch的基本知识,包括如何使用nn.Module,nn.Sequential和torch.nn.parameter类创建自定义架构。
- 在PyTorch中处理图像
2.Defining The Network
如前所述,我们使用nn.Module类在PyTorch中构建自定义架构。 让我们为检测器定义一个网络。 在darknet.py文件中,添加以下类。
class Darknet(nn.Module): def __init__(self, cfgfile): super(Darknet, self).__init__() self.blocks = parse_cfg(cfgfile) self.net_info, self.module_list = create_modules(self.blocks)
在这里,我们将nn.Module类作为父类,添加名为Darknet的类作为其子类。 我们使用如下成员初始化网络,blocks、net_info、module_list。
3.Implementing the forward pass of the network
网络的前向传递是通过重写nn.Module类的forward方法来实现的。
前向传递有两个目的。 首先,计算输出值,其次,以易于处理的方式转换输出检测特征图(例如对其进行转换,以便可以连接多个比例的检测图,否则由于其具备的不同尺寸会导致无法进行处理)。
def forward(self, x, CUDA): modules = self.blocks[1:] outputs = {} #We cache the outputs for the route layer
forward接受三个参数,self,输入x和CUDA,如果为true,则将使用GPU加速前向传递。
在这里,我们迭代self.blocks [1:]而不是self.blocks,因为self.blocks的第一个元素是一个net块,它不是正向传递的一部分。
由于路径和短跳层需要先前图层的输出,我们将每层的输出特征图缓存在dict中。 键值对分别是每层的索引和特征图。
与create_modules函数一样,我们现在遍历包含网络模块的module_list。 这里要注意的是,模块的添加顺序与配置文件中的添加顺序相同。 这意味着,我们可以简单地通过每个模块运行输入以获取输出。
write = 0 #This is explained a bit later for i, module in enumerate(modules): module_type = (module["type"])
4.Convolutional and Upsample Layers
如果模块是卷积模块或上采样模块,这就是前向传递的工作方式:
if module_type == "convolutional" or module_type == "upsample": x = self.module_list[i](x)
5.Route Layer / Shortcut Layer
如果查看路径层的代码,则必须考虑两种情况(如第2部分所述)。 对于连接两个特征图的情况,我们使用torch.cat函数,第二个参数为1。这是因为我们要沿着深度将特征图串联。(在PyTorch中,卷积层的输入和输出的格式为'B x C x H x W'。深度对应于channel的大小)。
elif module_type == "route": layers = module["layers"] layers = [int(a) for a in layers] if (layers[0]) > 0: layers[0] = layers[0] - i if len(layers) == 1: x = outputs[i + (layers[0])] else: if (layers[1]) > 0: layers[1] = layers[1] - i map1 = outputs[i + layers[0]] map2 = outputs[i + layers[1]] x = torch.cat((map1, map2), 1) elif module_type == "shortcut": from_ = int(module["from"]) x = outputs[i-1] + outputs[i+from_]
6.YOLO (Detection Layer)
YOLO的输出是一个卷积特征图,其中包含沿特征图深度的边界框属性。(就是说有多少个channel就有多少个边界框属性堆叠) 单元格预测的属性边界框彼此一一堆叠。 因此,如果需要访问单元格(5,6)的第二个边界,则必须通过map [5,6,(5 + C):2 *(5 + C)]对其进行索引。 这种形式对于输出处理非常不方便,输出处理有:通过对象置信度进行阈值处理,向中心添加网格偏移,应用锚点等。
另一个问题是,由于检测是在三个尺度上进行的,因此预测图的尺寸将有所不同。 尽管三个特征图的尺寸不同,但是要在它们上进行的输出处理操作却是类似的。 所以最好在单个张量而不是三个单独的张量上执行这些操作。
为了解决这些问题,我们引入了函数predict_transform
7.Transforming the output
函数predict_transform位于文件util.py中,当在Darknet类的前向传递中使用该函数时,将导入该函数。
由于我是在jupyter notebook上面做的实验,就不另外做util.py了。直接开下一个代码块就行了,所以在最上面的导入部分添加cv2.现在所有的导入变成了:
import torch import torch.nn as nn import torch.nn.functional as F from torch.autograd import Variable import numpy as np import cv2
predict_transform接收5个参数:prediction(我们的输出),inp_dim(输入图片的维度),anchors(锚盒),num_classes(类数量),CUDA(是否使用cuda)
def predict_transform(prediction, inp_dim, anchors, num_classes, CUDA = True):
predict_transform函数获取检测特征图,并将其转换为二维张量,其中张量的每一行均按以下顺序对应于边界框的属性。
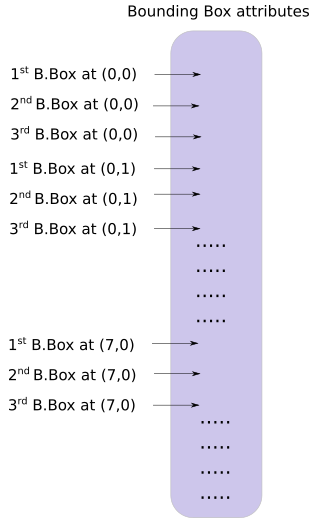
这是执行上述转化的代码:
batch_size = prediction.size(0) stride = inp_dim // prediction.size(2) grid_size = inp_dim // stride bbox_attrs = 5 + num_classes num_anchors = len(anchors) prediction = prediction.view(batch_size, bbox_attrs*num_anchors, grid_size*grid_size) prediction = prediction.transpose(1,2).contiguous() prediction = prediction.view(batch_size, grid_size*grid_size*num_anchors, bbox_attrs)
锚盒的尺寸取决于net模块的高度和宽度属性。 这些属性描述了输入图像的尺寸,该尺寸比检测图大(因为步长的因素)。 因此,我们必须将锚点除以检测特征图的步幅。
anchors = [(a[0]/stride, a[1]/stride) for a in anchors]
现在,我们需要根据第1部分中讨论的方程式转换输出。
对预测值的x,y坐标以及目标分数使用sigmoid函数压缩
prediction[:,:,0] = torch.sigmoid(prediction[:,:,0]) prediction[:,:,1] = torch.sigmoid(prediction[:,:,1]) prediction[:,:,4] = torch.sigmoid(prediction[:,:,4])
将网格偏移量添加到中心坐标预测中。
#Add the center offsets grid = np.arange(grid_size) a,b = np.meshgrid(grid, grid) x_offset = torch.FloatTensor(a).view(-1,1) y_offset = torch.FloatTensor(b).view(-1,1) if CUDA: x_offset = x_offset.cuda() y_offset = y_offset.cuda() x_y_offset = torch.cat((x_offset, y_offset), 1).repeat(1,num_anchors).view(-1,2).unsqueeze(0) prediction[:,:,:2] += x_y_offset
将锚盒应用于边界框的维度。
#log space transform height and the width anchors = torch.FloatTensor(anchors) if CUDA: anchors = anchors.cuda() anchors = anchors.repeat(grid_size*grid_size, 1).unsqueeze(0) prediction[:,:,2:4] = torch.exp(prediction[:,:,2:4])*anchors
将sigmoid函数用于激活分类分数
prediction[:,:,5: 5 + num_classes] = torch.sigmoid((prediction[:,:, 5 : 5 + num_classes]))
我们在这里要做的最后一件事是将检测图调整为输入图像的大小。 此处的边界框属性根据特征图(例如13 x 13)调整大小。 如果输入图像为416 x 416,我们将属性乘以32或步长变量。
prediction[:,:,:4] *= stride
循环主体到此结束。
在函数末尾返回预测。
return prediction
8.Detection Layer Revisited
现在我们已经转换了输出张量,我们可以将三个不同比例的检测图张量连接成一个大张量。 请注意,在我们进行转换之前这是不可能的,因为不能连接具有不同空间尺寸的张量。 但是从现在起,我们的输出张量成为了一个以边界框为行的表格,因此连接变得可行了。
我们遇到的一个障碍是无法初始化一个空的张量,然后将一个非空的(不同形状的)张量连接到它。 因此,我们延迟收集器(保存检测值的张量)的初始化,直到获得第一个检测图,然后在获得后续检测图时将其进行连接。
注意,在darknet类前向传播函数中的循环之前,有write = 0这一行。 write标志用于指示我们是否遇到了第一次检测。 如果write为0,则表示收集器尚未初始化。 如果为1,则表示收集器已初始化,我们可以将检测图进行连接。
现在,我们已经用predict_transform函数做好了准备,我们在前向传播函数中编写用于处理检测特征图的代码。
在darknet类中的forward函数中添加:
elif module_type == 'yolo': anchors = self.module_list[i][0].anchors #Get the input dimensions inp_dim = int (self.net_info["height"]) #Get the number of classes num_classes = int (module["classes"]) #Transform x = x.data x = predict_transform(x, inp_dim, anchors, num_classes, CUDA) if not write: #if no collector has been intialised. detections = x write = 1 else: detections = torch.cat((detections, x), 1) outputs[i] = x
现在只要返回detections就行了:
return detections
9.Testing the forward pass
这是一个创建虚拟输入的函数。 我们将把这个输入传递给我们的网络。 在我们编写此函数之前,请将此image保存到您的工作目录中。 如果您使用的是Linux,请输入。
{kind=link}
wget https://github.com/ayooshkathuria/pytorch-yolo-v3/raw/master/dog-cycle-car.png
原来git的路径应该挂了,用以下命令克隆:
git clone https://github.com/ayooshkathuria/YOLO_v3_tutorial_from_scratch.git
然后里面就有dog-cycle-car.png这张图片
现在,在你的网络中定义如下函数:
def get_test_input(): img = cv2.imread("dog-cycle-car.png") img = cv2.resize(img, (416,416)) #Resize to the input dimension img_ = img[:,:,::-1].transpose((2,0,1)) # BGR -> RGB | H X W C -> C X H X W img_ = img_[np.newaxis,:,:,:]/255.0 #Add a channel at 0 (for batch) | Normalise img_ = torch.from_numpy(img_).float() #Convert to float img_ = Variable(img_) # Convert to Variable return img_
然后输入以下代码进行测试:
model = Darknet("cfg/yolov3.cfg") inp = get_test_input() pred = model(inp, torch.cuda.is_available()) print(pred) print(pred.shape)
注意:原文这里有两个错误
- 请在predic_transforms函数的开头加上prediction = prediction.cuda(),因为函数内部的x,y还有anchor变量都放在了GPU上,而prediction在CPU上,不能互相操作,或者你可以把其他三个变量都放在cpu上,也可以改正错误
- 请注意get_test_input里面resize图片的大小和网络入口的图片大小不一致,检查你解析cfg文件后网络的入口参数,你会发现'width': '608', 'height': '608',所以把cv2.resize(img, (416,416))改成608,608就行了
你将会看到如下的输出:
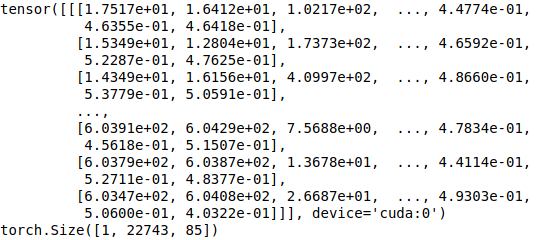
该张量的形状为1 x 22743 x85。第一个维度是批处理大小,由于我们使用了单个图像,因此批处理大小仅为1。 对于批次中的每个图像,我们都有一个22743 x 85的表。 每个表的行都表示一个边界框。 (4个bbox属性,1个物体分数和80个类分数)
在上面,我们的网络具有随机权重,因此不会产生正确的输出。 我们需要在网络中加载权重文件。 为此,我们将使用官方重量文件。
10.Downloading the Pre-trained Weights
首先下载官方的权重文件,如果你使用的是linux,可以使用wget:
wget https://pjreddie.com/media/files/yolov3.weights
吐槽一下下载的是真的慢,稍后我把下载好的权重文件放在我的git上,这样大家下载起来比较快。
11.Understanding the Weights File
官方的权重文件是二进制文件包含顺序存储的权重。
阅读权重文件时必须格外小心。 权重只是存储为浮点数,而且没有任何东西可以指导我们它们属于哪一层。 如果搞砸了,那就没有什么可以阻止比如将批处理归一层的权重加载到卷积层的权重中。 由只读取浮点数,因此无法区分哪个权重属于哪一层。 因此,我们必须了解权重的存储方式。
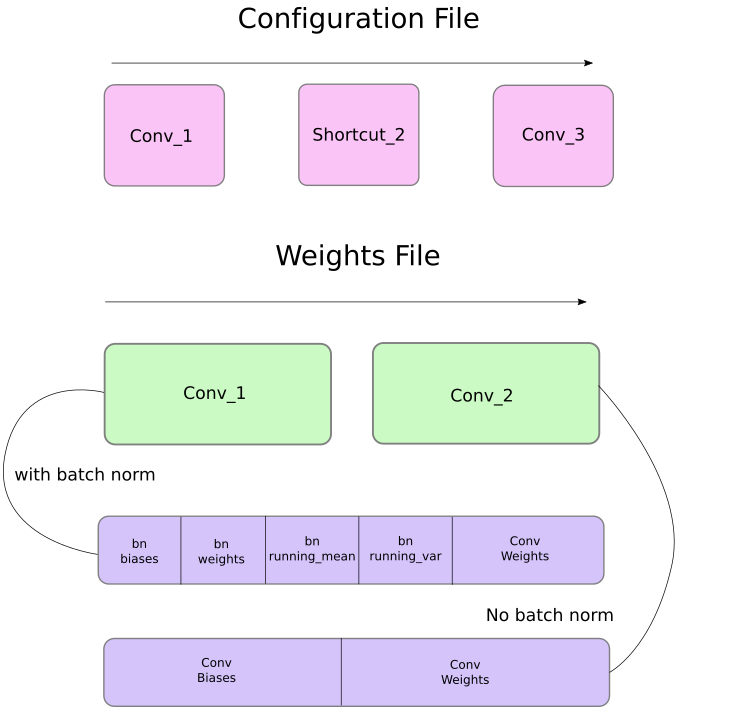
首先,权重仅属于两种类型的层,即批处理归一层或卷积层。
这些层的权重存储顺序与配置文件中出现的顺序完全相同。 因此,如果在卷积后面紧跟着一个短跳块,然后在短跳块后面紧跟着另一个卷积块,则你将期望文件包含前一个卷积块的权重,然后是后者。
当批处理归一层(BN)出现在卷积块中时,就没有偏差(b)。 但是,当没有BN块时,必须从文件中读取偏差“权重”(b)。
下图解释了权重文件如何存储权重:
12.Loading Weights
让我们写一个函数来加载权重。 这将是Darknet类的成员函数。 除了self以外,将使用一个参数,即权重文件的路径。
def load_weights(self, weightfile):
权重文件的前160个字节存储5个int32大小的值,这些值构成文件的头部。
#Open the weights file fp = open(weightfile, "rb") #The first 5 values are header information # 1. Major version number # 2. Minor Version Number # 3. Subversion number # 4,5. Images seen by the network (during training) header = np.fromfile(fp, dtype = np.int32, count = 5) self.header = torch.from_numpy(header) self.seen = self.header[3]
现在,其余比特按上述顺序表示权重。 权重存储为float32或32位浮点数。 让我们将其余权重加载到np.ndarray中。
weights = np.fromfile(fp, dtype = np.float32)
现在,我们遍历权重文件,并将权重加载到网络的模块中。
ptr = 0 for i in range(len(self.module_list)): module_type = self.blocks[i + 1]["type"] #If module_type is convolutional load weights #Otherwise ignore.
进入循环,我们首先检查卷积块是否具有BN。基于此,我们加载权重。
if module_type == "convolutional": model = self.module_list[i] try: batch_normalize = int(self.blocks[i+1]["batch_normalize"]) except: batch_normalize = 0 conv = model[0]
我们保留一个称为ptr的变量来跟踪权重数组中的位置。 现在,如果batch_normalize为True,我们将按如下方式加载权重。
if (batch_normalize): bn = model[1] #Get the number of weights of Batch Norm Layer num_bn_biases = bn.bias.numel() #Load the weights bn_biases = torch.from_numpy(weights[ptr:ptr + num_bn_biases]) ptr += num_bn_biases bn_weights = torch.from_numpy(weights[ptr: ptr + num_bn_biases]) ptr += num_bn_biases bn_running_mean = torch.from_numpy(weights[ptr: ptr + num_bn_biases]) ptr += num_bn_biases
bn_running_var = torch.from_numpy(weights[ptr: ptr + num_bn_biases]) ptr += num_bn_biases #Cast the loaded weights into dims of model weights. bn_biases = bn_biases.view_as(bn.bias.data) bn_weights = bn_weights.view_as(bn.weight.data) bn_running_mean = bn_running_mean.view_as(bn.running_mean) bn_running_var = bn_running_var.view_as(bn.running_var) #Copy the data to model bn.bias.data.copy_(bn_biases) bn.weight.data.copy_(bn_weights) bn.running_mean.copy_(bn_running_mean) bn.running_var.copy_(bn_running_var)
如果batch_norm不是true,则只需加载卷积层的偏差。
else: #Number of biases num_biases = conv.bias.numel() #Load the weights conv_biases = torch.from_numpy(weights[ptr: ptr + num_biases]) ptr = ptr + num_biases #reshape the loaded weights according to the dims of the model weights conv_biases = conv_biases.view_as(conv.bias.data) #Finally copy the data conv.bias.data.copy_(conv_biases)
最后,我们加载卷积层的权重。
#Let us load the weights for the Convolutional layers num_weights = conv.weight.numel() #Do the same as above for weights conv_weights = torch.from_numpy(weights[ptr:ptr+num_weights]) ptr = ptr + num_weights conv_weights = conv_weights.view_as(conv.weight.data) conv.weight.data.copy_(conv_weights)
我们已经完成了此功能,现在可以通过在darknet对象上调用load_weights函数来在Darknet对象中加载权重。
model = Darknet("cfg/yolov3.cfg") model.load_weights("yolov3.weights")
这就是这一部分的全部内容,通过构建模型并加载权重,我们终于可以开始检测对象了。 在下一部分中,我们将介绍使用目标置信度阈值和非最大抑制来产生最终的检测。