感谢吴恩达老师的公开课,以下图片均来自于吴恩达老师的公开课课件
为什么要进行卷积操作?
我们通过前几天的实验已经做了64*64大小的猫图片的识别。
在普通的神经网络上我们在输入层上输入的数据X的维数为(64*64*3, m) 假设第二层的节点数为1000,在全连接网络下,则W的维数为(1000, 64*64*3)。
这看起来是可以操作的,但是实际情况下的图片是更高清的,比如现在的手机已经动辄2400万像素。
在这种情况下让内存来处理很多W权重矩阵是不现实的,因此卷积神经网络就成为了计算机视觉领域的利器。
边缘检测的卷积示例
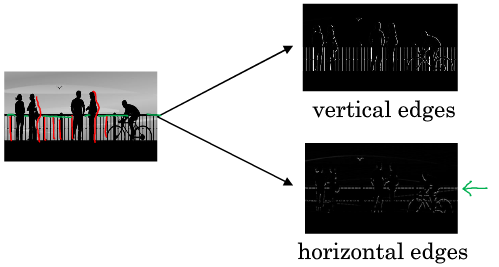
现在我们希望从上面的图片中提取纵向边缘特征,

现在我们有一个6x6的黑白图片矩阵,因为彩色图片是RGB三通道的,此时只有一个通道
我们使用了一个3x3的过滤器filter(有些文献中也称其为核kernel),用这个filter中的每个元素去和对应位置的原矩阵相乘相加,就得到了卷积后的4x4矩阵
比如最终结果第一行第一列的0 = 10x1+10x1+10x1+10x0+10x0+10x0-1x10-1x10-1x10
第一行第二列的30 = 10x1+10x1+10x1+10x0+10x0+10x0-0x10-0x10-0x10
从最终的卷积结果来看,左右两列均为0亮度最低,中间两列亮度高,所以纵向的边缘就被检测出来了。
可能从上述例子中感觉检测出的纵轴很宽,但是这只是6x6图片的卷积,如果换成维度很高像素很高的图片,就会显得很窄。
filter:
在过去,人们常常使用一些手写的过滤器来检测图像的垂直或平行边缘,比如以下的滤波器:
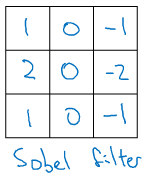
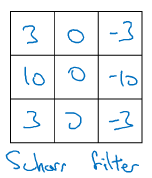
但是现在我们往往将滤波器中的九个参数设置为神经网络中可学习的W1~W9参数,来让神经网络自己找到更加复杂的边缘检测方式。具体的做法会在下一次博文中谈到。
Padding:
在上述的普通卷积操作中:
如果我们把原始图片看做n x n的,设置一个f x f的filter,我们会得到一个经过卷积后的(n - f + 1) x (n - f + 1)的图像,所以可以看到图像经过卷积后会变小
所以普通的卷积操作有两个缺点:
1.缩小输出shrinking output
2.丢失边缘信息 因为卷积操作的边缘只会被覆盖一次,而中间的区域会被多次卷积输出,所以边缘的信息可能会被丢掉
为了解决上述问题,我们可以在卷积操作前pad填充图像
举个例子:原始图像是6x6的,我们在周围填充一圈像素点,就变成了8x8的,然后经过3x3的卷积,得到了一个6x6的图像,和原图像的维度相同。
将填充padding的层数设为p,则经过填充后的结果就是(n + 2p - f + 1) x (n + 2p - f + 1)
Valid convolution and Same convolution:
valid:no padding
Same:Pad so that output size is the same as the input size
对于same卷积而言:n + 2p - f + 1 == n
所以得到:p = (f - 1) / 2,选用相应于filter的填充层数p就可以完成same卷积
注意:遵循计算机视觉的惯例一般的f为奇数,如3x3,5x5,7x7等,有时也会有1x1的过滤器
卷积步长stride:
所谓卷积步长就是一次将filter移动的步长,在上面的例子中,我们6x6图像的卷积中将3x3的filter每次移动1个步长,所以得到了4x4的卷积结果。
如果将步长设置为2,我们就会得到2x2的卷积结果,因为向下取整舍弃了没有卷积的部分,综合而言有以下公式:
python中:向下取整为floor,向上取整为ceil,四舍五入为round
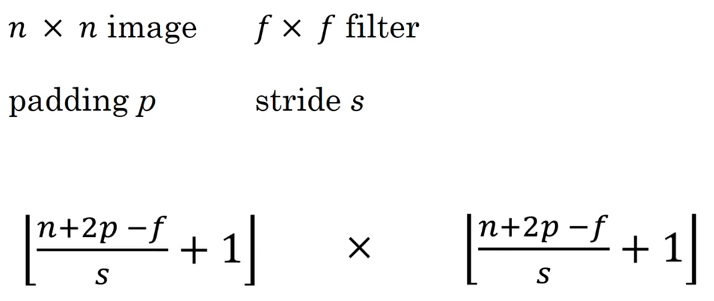
镜像翻转:
在信号学和数学领域,通常对我们上面的操作称之为cross-correlation互相关。
对filter进行顺时针旋转180°,再进行镜像的操作后才称之为卷积。这是为了满足(A*B)*C = A*(B*C)
但是在深度学习领域中,镜像翻转的操作其实并不重要,所以在一些深度学习的文献中将第一种操作直接称之为convolution卷积。
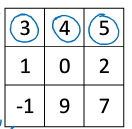
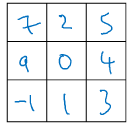
如上图,实际上分为两步:
1.顺时针旋转180°
2.镜像翻转得到右图