第九章 图论和网络爬虫
1 图论

每座桥恰巧走过一遍并回到原出发点?
关于图的最重要的一种算法是遍历算法,也就是如何通过弧访问图的各个节点。
广度优先搜索(Breadth-First Search,BFS):要尽可能‘广’地访问与每个节点直接连接的其他节点
深度优先搜索(Depth-First Search,DFS):一条路走到黑= =!
2 网络爬虫
把互联网看成一张大图,把每一个网页当作一个节点,把超链接当作连接网页的弧。
在网络爬虫中,使用一个‘散列表’(Hash Table,也叫哈希表)而不是一个记事本记录网页是否下载过的信息。
3 延伸阅读:图论的两点补充说明
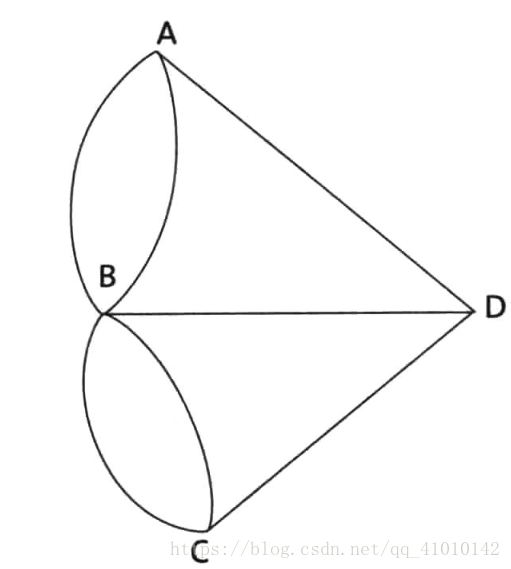
对于图中的每一个顶点,与它相连的边的数量定义为它的度(degree)
定理:如果一个图能够从一个顶点出发,每条边不重复地遍历一遍回到这个顶点,那么每一顶点的度必须是偶数。
证明:假如能够遍历图的每一条边各一次,那么对于每个顶点,需要从某条边进入顶点,同时从另一条边离开这个顶点。进入和离开顶点的次数是相同的,因此每个顶点有多少条进入的边,就有多少条出去的边。也就是说,每个顶点相连的边的数量是成对出现的,即每个顶点的度都是偶数。
3.2 构建网络爬虫的工程要点
“如何构建一个爬虫”?(我第一反应就是库啊= =!咸鱼的我)
①首先,用BFS还是DFS?
网络爬虫对网页遍历的次序不是简单的BFS或者DFS,而是有一个相对复杂的下载优先级排序的方法。在爬虫中,BFS的成分多一些。
②第二,页面的分析和URL的提取
URL的提取比以前复杂多了
③第三,记录哪些网页已经下载过的小本本——URL表
为了防止一个网页被下载多次,用散列表记录哪些网页已经下载过。难点:上千台服务器上建立和维护一张散列表就不简单了。首先,这张散列表会大到一台服务器存储不下。其次,由于每个下载服务器在开始下载前和完成下载后都要访问和维护这张表,以免不同的服务器做重复的工作,这个存储散列表的服务器的通信就成了整个爬虫系统的瓶颈。如何解决?
好的方法:明确每台服务器的分工。在此基础上判断URL是否下载就可以批处理了,比如每次向散列表(一组独立的服务器)发送一大批询问,或者每次更新一大批散列表的内容。