VisualPytorch发布域名+双服务器如下:
http://nag.visualpytorch.top/static/ (对应114.115.148.27)
http://visualpytorch.top/static/ (对应39.97.209.22)
一、快速入门
1. 界面介绍
首先打开网址,进入网站的首页。先注册登录一个账号,也是十分简便的啦,因为这样可以使用更多的功能。注册时需要提供自己的真实邮箱,我们会向邮箱中发送一份验证邮件,点击邮件中的链接即可完成注册。
页面头部有七个选项,分别为VisualPytorch, 快速入门,创建模型,模型管理,模型市场,模型推理和其他菜单,VisualPytorch就是主页面,快速入门是本网站的简单教程,在创建模型界面可以创建自己的模型,在模型管理界面可以管理自己创建的模型,在模型市场界面可以浏览其他用户分享的模型,其他菜单包括问题反馈界面和联系我们界面,以及对经典模型和网络层及参数相关内容的介绍。
2. 组件框
在VisualPytorch界面左侧有可选择的网络层,这些层就是用来搭建神经网络模型的基本组件,在网络层的下面还有训练参数配置,主要用于确定模型的全局训练参数。下面给大家简单展示一下如何拖拽和删除这些组件框,以及组件框参数的位置。在搭建模型过程中可以嵌入已有的模块,使其作为子模块。
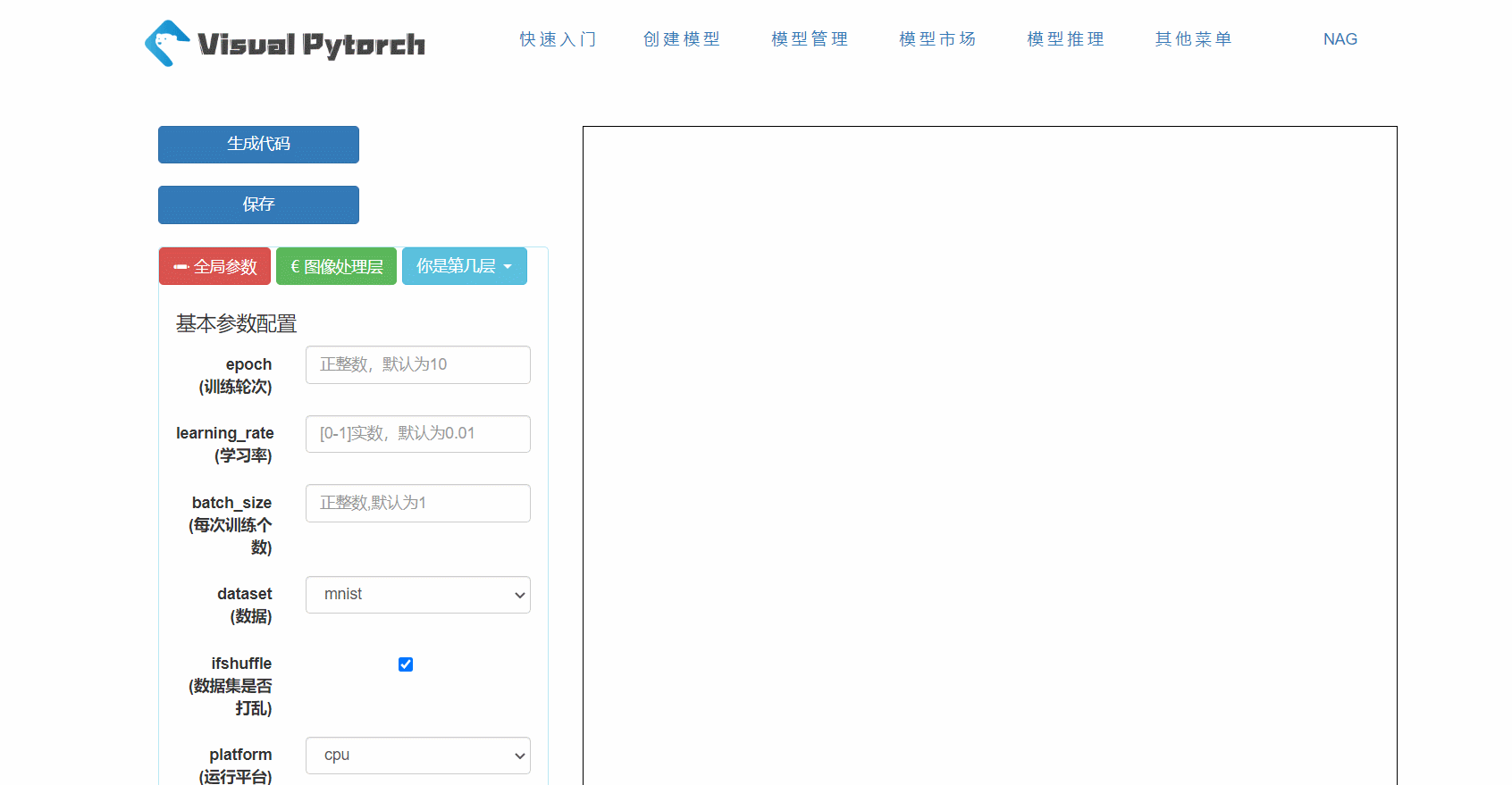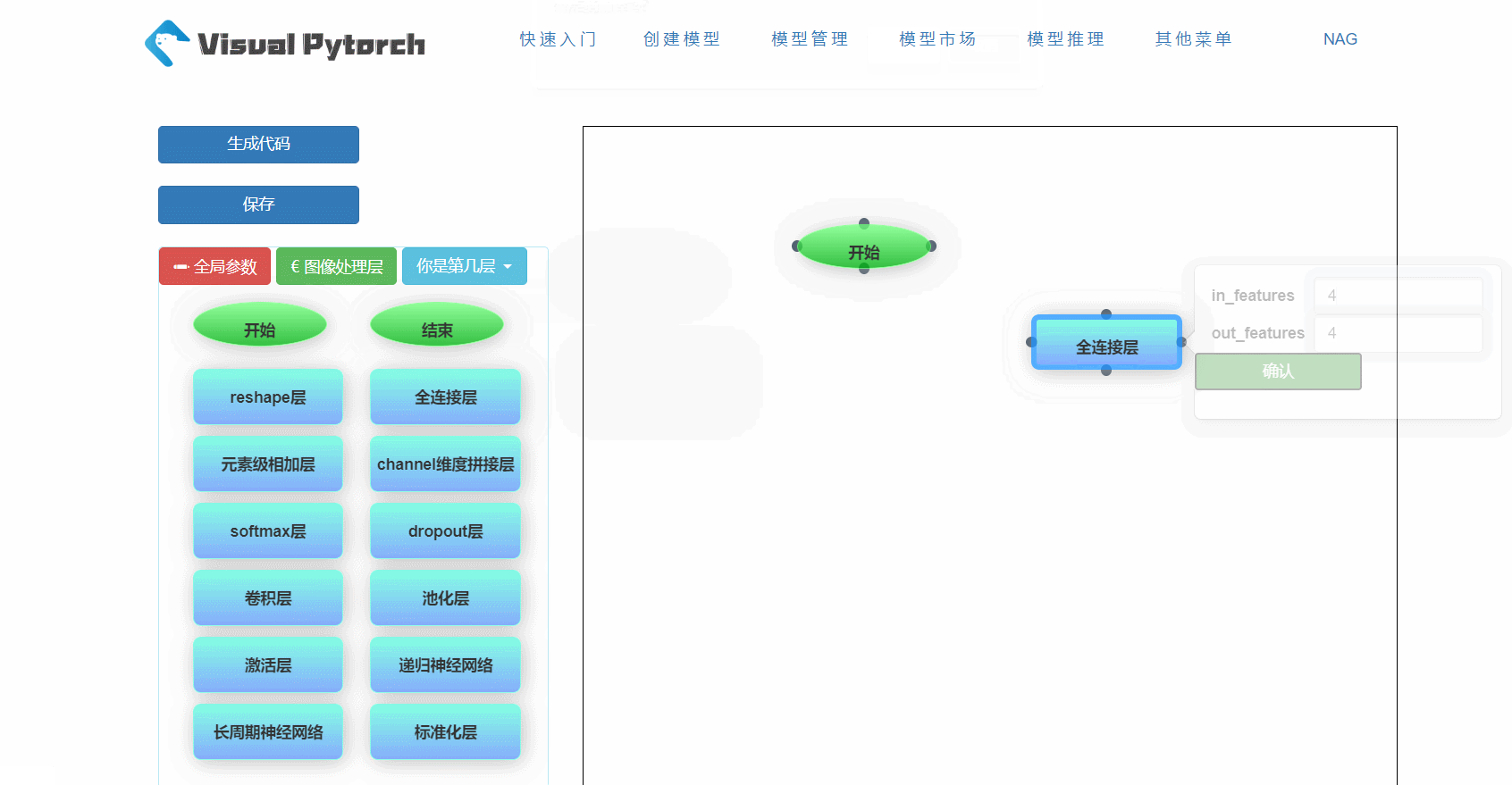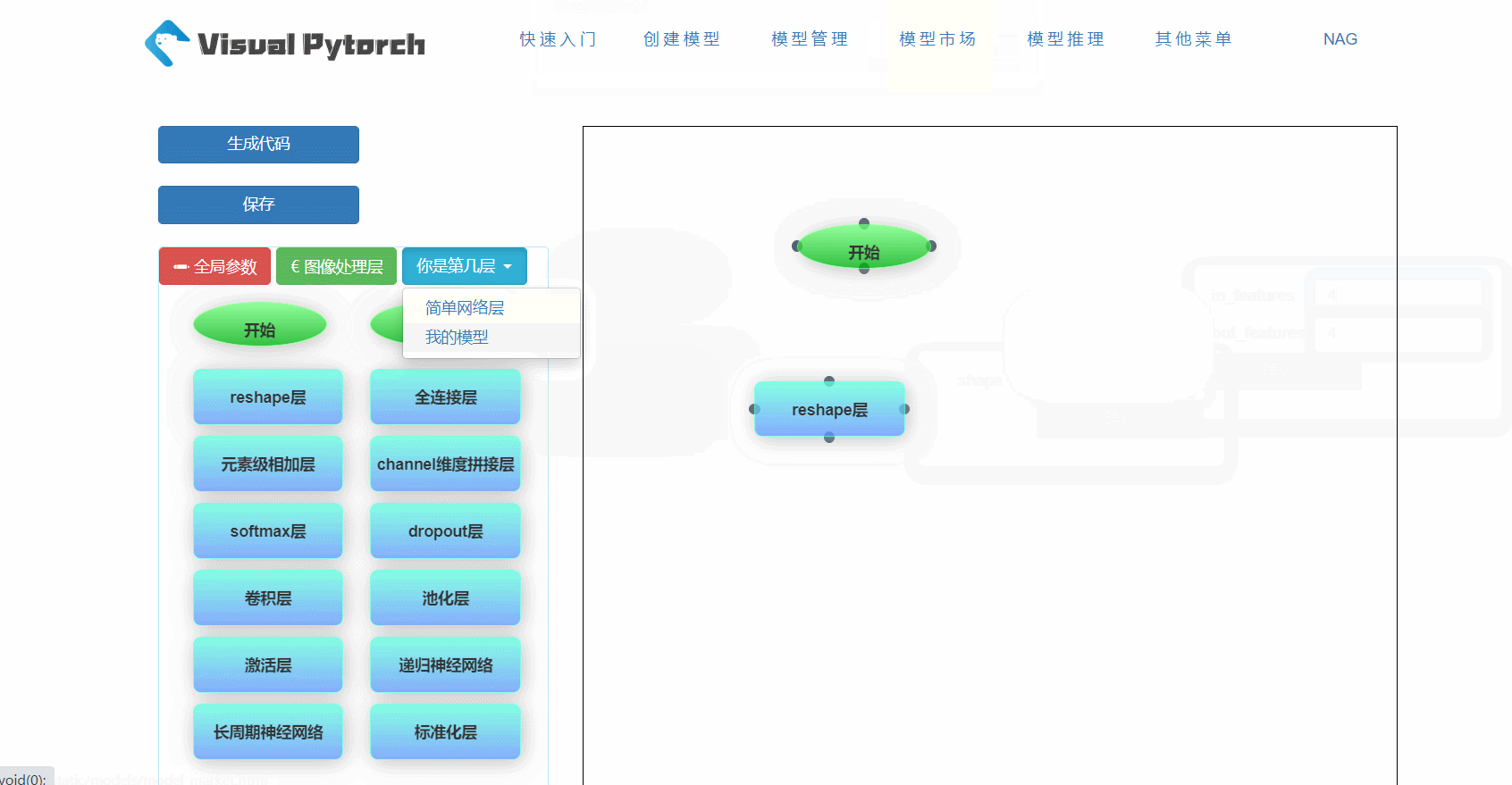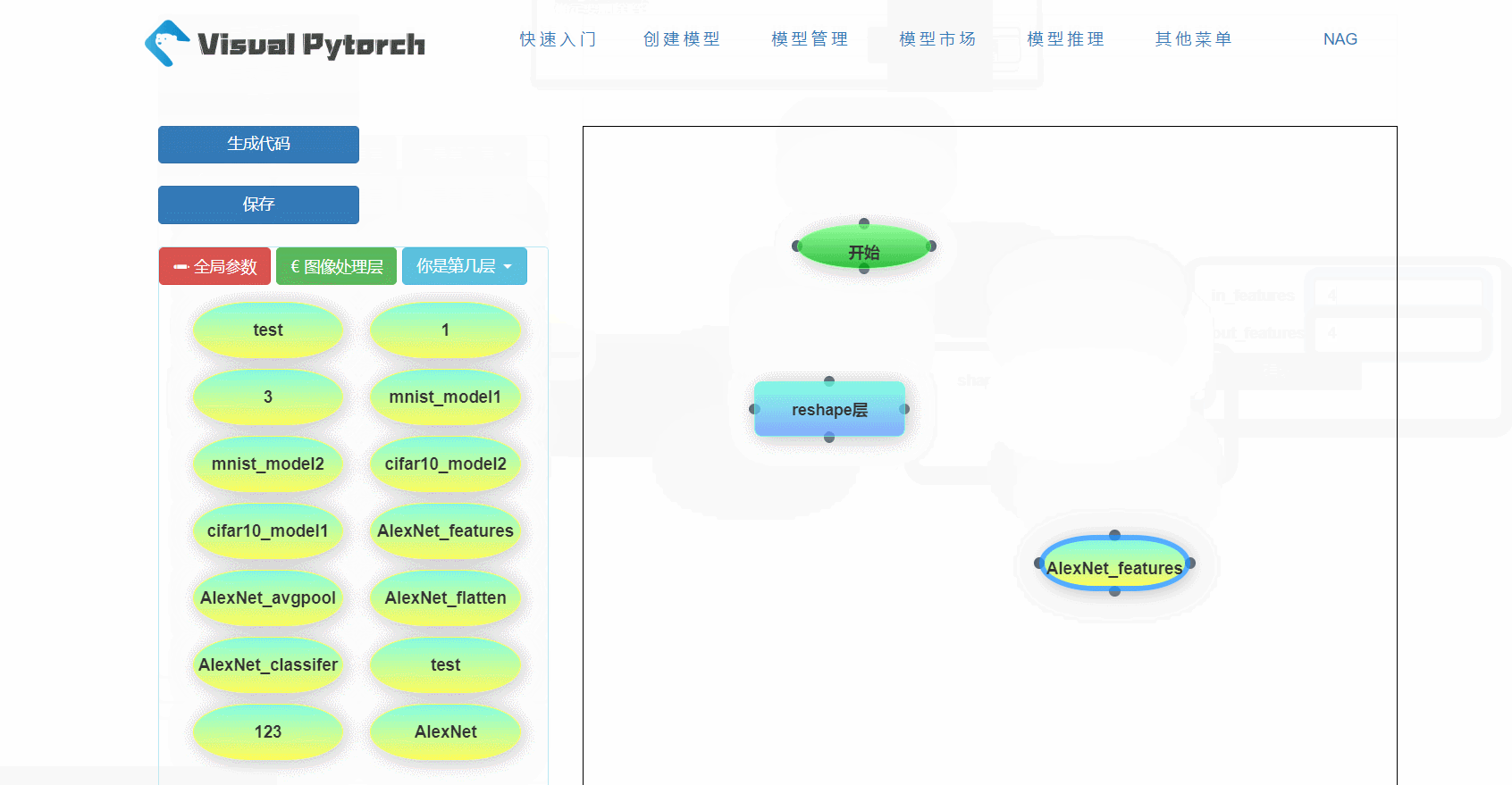
3. 生成和下载代码
在VisualPytorch界面左上角有生成代码按钮,当你搭建好自己的神经网络模型之后,就可以点击这个按钮,然后会跳转到代码页面,你也就可以看到生成的代码啦,然后再点击下载代码,就可以把代码下载到本地,畅快的玩耍一番啦。

4. 保存模型
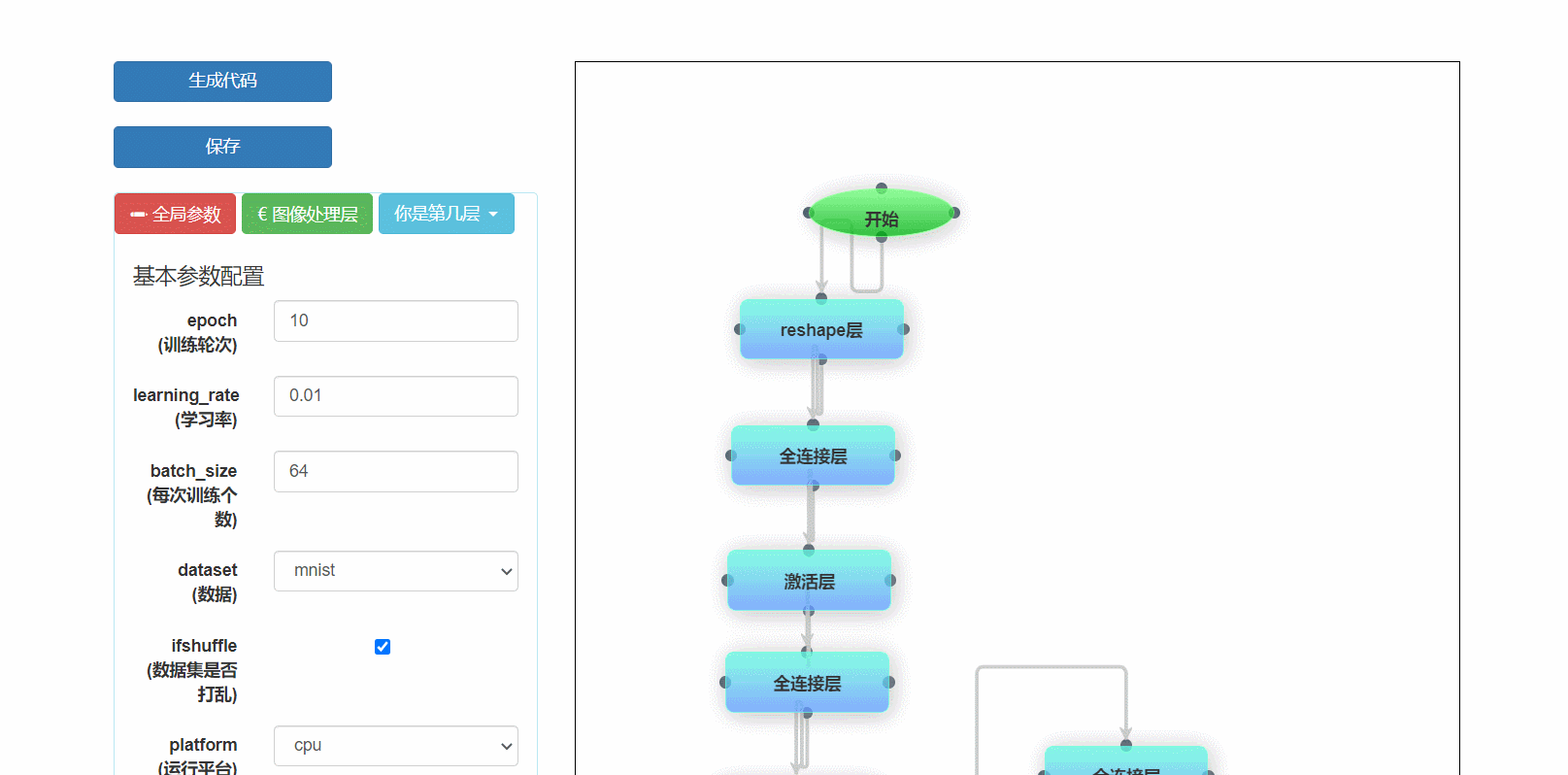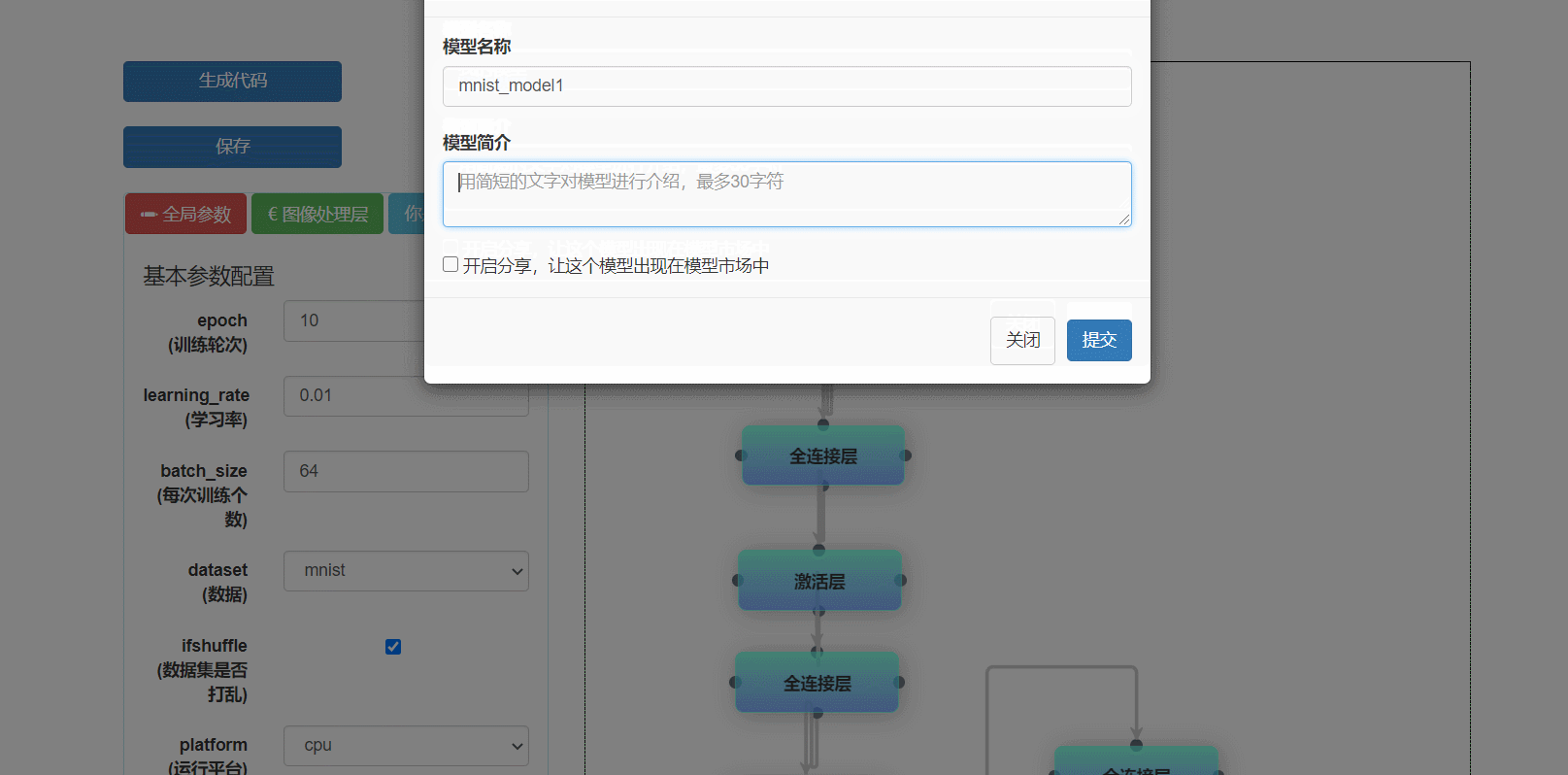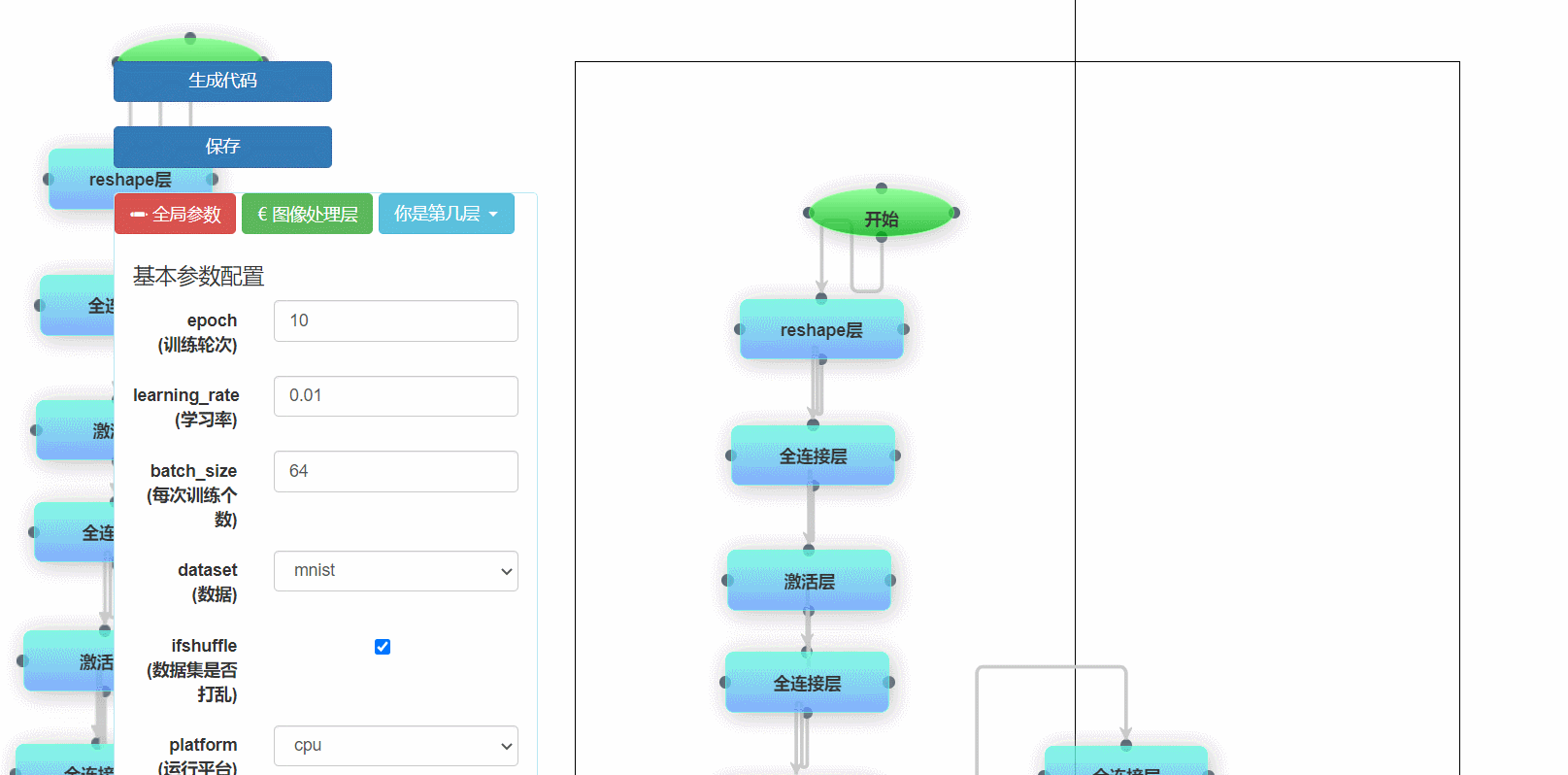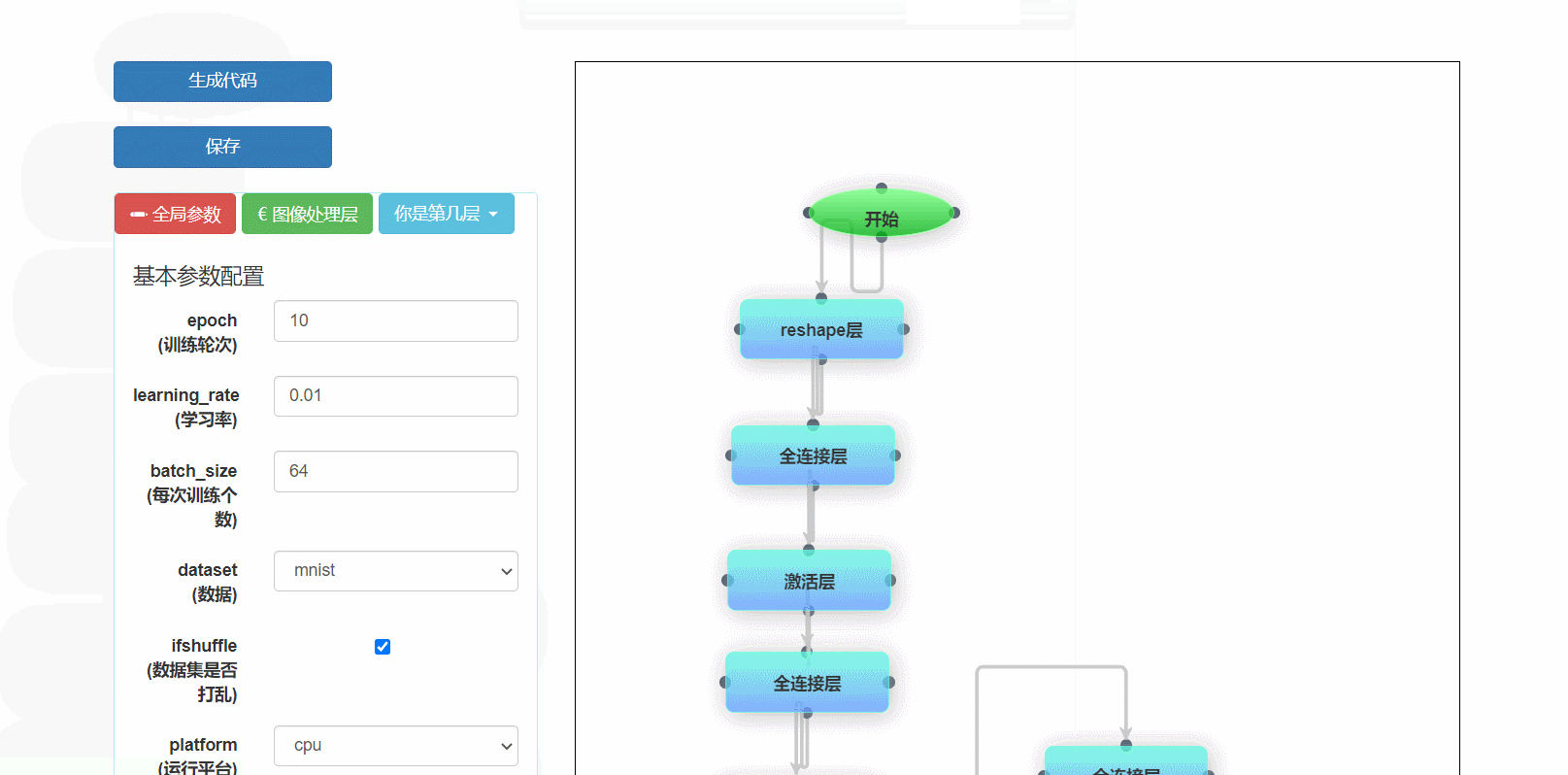
考虑到也许后续还要用自己搭建过的模型,所以我们实现了保存模型这一功能(贴心的团队,有木有),当你搭建好一个模型之后,可以直接选择保存,然后模型就会保存到你的账号啦,下次你登录还可以查看自己之前的模型。
保存模型时,可以勾选“是否分享”。如果勾选了,大家就可以在模型市场界面看到你的模型啦。
5. 模型市场
在模型市场,可以浏览大家分享的模型,还可以将其复制到自己的模型列表中。需要注意的是,复制来的模型不能再进行分享哦。

6. 模型推理
模型推理助你直观的感受诸如语言分割、目标探测的威力,并可以直接下载代码及模型进行本地运行。
二、使用说明
1. 概述
我们的网站旨在利用清晰的可视化模型来帮助热爱deep learning的你快速搭建想搭建的模型。
目前支持的神经网络层有:reshape层,全连接层,一维卷积层,二维卷积层; 这些层及其涉及的参数的具体含义都与pytorch官方文档里一致。
2. 搭建模型
模型的搭建通过将左侧的各类层模块拖入右侧画布并连线来完成。
- 首先要将左侧的 开始 按钮拖到右侧画布开始模型的搭建,然后一次将你想加入的层模块拖入到右侧画布中,之后点击模块四周的黑点并拖动至其他模块的黑点位置即可完成层模块的连接,支持层模块的并联。
- 在各个层模块中,其中一些层需要填入相应参数,需要参数的层模块在点击之后会弹出该层需要的具体参数,填写之后点击确认即可保存该层参数。参数均有输入限制,若存在不合规范的参数输入在点击确认时会显示错误提示,详细的参数要求及层的功能介绍会在下文中介绍。
- 在确认已经完成模型的搭建并填写完毕相应参数之后,可以点击 生成代码 按钮转到生成模型代码页面,若模型搭建中出现错误则无法正常生成代码并弹出错误提示。同时在完成模型搭建之后,点击 保存 按钮可以将搭建的模型保存在用户的账户中,需要注意的是,只有注册用户拥有权限保存自己搭建的模型,游客不具有保存模型的权限。
3. 生成的代码介绍
main.py里的代码主要是涉及全局的参数以及训练部分,目前该部分还有待完善。
model.py里则主要是搭建的模型代码,整个模型我们封装成了一个类,类名是 NET。
4. 模型管理
注册用户拥有保存自己搭建的模型并管理的权限,用户可以通过点击页面上显示的用户名,弹出 模型查看 和 登出 选项,点击模型查看即可进入模型管理的页面,该页面会显示用户曾搭建并保存的所有模型,每个模型都有对应的 查看 和 删除 按钮。点击查看即可进入模型搭建的页面并恢复用户曾保存的模型,用户可以对该模型进行重新编辑。点击删除即可删除相应的模型。
7. 相关的注意事项
- 搭建神经网络模块需要有显示的开始于结束节点。
- reshape层里如果有多个维度的话,不同维度之间需要以英文的逗号分开。
三、经典模型
1. VGG_16_layers
VGG卷积神经网络是牛津大学在2014年提出来的模型,它在图像分类和目标检测任务中都表现出非常好的结果。同时,VGG16模型的权重由ImageNet训练而来。
2. AlexNet
AlexNet是2012年ImageNet项目的大规模视觉识别挑战中的胜出者,该项目一种巧妙的手法打破了旧观念,开创了计算机视觉的新局面。
3. Network in Network(NIN)
一种新型的深度网络结构,它可以增强模型在感受野内对局部区域的辨别能力。
四、网络层
1. 简单网络层
reshape层
返回一个有相同数据但大小不同的tenser。返回的tenser必须有与原tenser相同的数据和相同数目的元素,但可以有不同的大小。一个tenser必须是连续的contiguous()才能被查看。
简单来看,view的参数就好比一个矩阵的行和列的值,当为一个数n的时候,则将数据大小变为1xn。
参数:
- shape <非负整数及-1序列,包括所有非负整数和-1(只有-1是例外),同维度数字之间以英文的“,”分开,例如1,2,3,4,5> 无默认值
全连接层(linear_layer)
class torch.nn.Linear(in_features, out_features, bias=True)
对输入数据做线性变换:y*=*Ax+b
参数:
- in_features<正整数> - 输入通道数 无默认值
- out_features<正整数> - 输入通道数 无默认值
形状:
- 输入: (N, in_features)
- 输出: (N, out_features)
变量:
- weight -形状为(out_features x in_features)的模块中可学习的权值
- bias -形状为(out_features)的模块中可学习的偏置
例子:
>>> m = nn.Linear(20, 30)
>>> input = autograd.Variable(torch.randn(128, 20))
>>> output = m(input)
>>> print(output.size())
元素级相加层(element_wise_add_layer)
该层不需要参数,作为几个层之间的衔接,需要注意的是,该函数的输入可以为多个向量。
channel维度拼接层(concatenate_layer)
torch.cat(inputs, dimension=0) → Tensor
在给定维度上对输入的张量序列seq 进行连接操作。
torch.cat()可以看做 torch.split() 和 torch.chunk()的反操作。 cat() 函数可以通过下面例子更好的理解。
参数:
- dim<非负整数> - 拼接维度 默认值为0
例子:
>>> x = torch.randn(2, 3)
>>> x
0.5983 -0.0341 2.4918
1.5981 -0.5265 -0.8735
[torch.FloatTensor of size 2x3]
>>> torch.cat((x, x, x), 0)
0.5983 -0.0341 2.4918
1.5981 -0.5265 -0.8735
0.5983 -0.0341 2.4918
1.5981 -0.5265 -0.8735
0.5983 -0.0341 2.4918
1.5981 -0.5265 -0.8735
[torch.FloatTensor of size 6x3]
>>> torch.cat((x, x, x), 1)
0.5983 -0.0341 2.4918 0.5983 -0.0341 2.4918 0.5983 -0.0341 2.4918
1.5981 -0.5265 -0.8735 1.5981 -0.5265 -0.8735 1.5981 -0.5265 -0.8735
[torch.FloatTensor of size 2x9]
softmax层(softmax_layer)
class torch.nn.Softmax(dim=None)
将Softmax函数应用于n维输入Tensor,对它们进行重新缩放,使得n维输出Tensor的元素位于[0,1]范围内并且总和为1。
函数表达式:
Softmax(xi)=exi∑jexjSoftmax(xi)=exi∑jexj
返回:
- 一个和输入相同尺寸和形状的张量,其值在[0,1]范围内
参数:
- dim<正整数> - 计算维度 无默认值
例子:
>>> m = nn.Softmax()
>>> input = torch.randn(2, 3)
>>> output = m(input)
dropout层(dropout_layer)
torch.nn.Dropout(p=0.5, inplace=False)
在训练期间,使用伯努利分布的样本以概率p将输入张量的某些元素随机置零。 在每次前向传播时,每个通道将独立清零。事实证明,这是一种有效的技术,可用于规范化和防止神经元的协同适应。
- type<下拉框,包括1d/2d/3d> 默认值为2d
- p<0-1间实数>:置0概率 默认值为0.5
例子:
a = torch.randn(10,1)
>>> tensor([[ 0.0684],
[-0.2395],
[ 0.0785],
[-0.3815],
[-0.6080],
[-0.1690],
[ 1.0285],
[ 1.1213],
[ 0.5261],
[ 1.1664]])
torch.nn.Dropout(0.5)(a)
>>> tensor([[ 0.0000],
[-0.0000],
[ 0.0000],
[-0.7631],
[-0.0000],
[-0.0000],
[ 0.0000],
[ 0.0000],
[ 1.0521],
[ 2.3328]])
2. 卷积层(conv_layer)
class torch.nn.Conv1d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True)
卷积神经网络中每层卷积层(Convolutional layer)由若干卷积单元组成,每个卷积单元的参数都是通过反向传播算法最佳化得到的。卷积运算的目的是提取输入的不同特征,第一层卷积层可能只能提取一些低级的特征如边缘、线条和角等层级,更多层的网路能从低级特征中迭代提取更复杂的特征。
以一维卷积层为例,输入的尺度是(N, C_in,L),输出尺度( N,C_out,L_out)的计算方式:
layer_type<下拉框二选一,conv/conv_transpose> - 分别表示卷积与反卷积 默认值为conv
conv和conv_transpose参数相同
- type:下拉框三选一,选项包括1d/2d/3d 默认值为2d
- in_channels<正整数> - 输入通道数 无默认值
- out_channels<正整数> - 输出通道数 无默认值
- kernel_size <正整数> - 卷积核的尺寸 默认值为3
- stride<正整数> - 卷积步长 默认值为1
- dilation<正整数>– 卷积核元素之间的间距,详细描述在这里 默认值为0
- padding<非负整数> - 输入的每一条边补充0的层数 默认值为0
形状:
- 输入: (N,Cin,Lin)(N,Cin,Lin)
- 输出: (N,Cout,Lout)(N,Cout,Lout)
- 输入输出的计算方式: Lout=floor(Lin+2p−d∗(k−1)−1s+1)Lout=floor(Lin+2p−d∗(k−1)−1s+1)
变量:
- weight(
tensor) - 卷积的权重,大小是(out_channels,in_channels,kernel_size) - bias(
tensor) - 卷积的偏置系数,大小是(out_channel)
例子:
>>> m = nn.Conv1d(16, 33, 3, stride=2)
>>> input = autograd.Variable(torch.randn(20, 16, 50))
>>> output = m(input)
3. 池化层(pool_layer)
在神经网络中,池化函数(Pooling Function)一般将上一层卷积函数的结果作为自己的输入。经过卷积层提取过特征之后,我们得到的通道数可能会增大很多,也就是说数据的维度会变得更高,这个时候就需要对数据进行池化操作,也就是降维操作。
池化操作是用每个矩阵的最大值或是平均值来代表这个矩阵,从而实现元素个数的减少,并且最大值和平均值操作可以使得特征提取具有“平移不变性”。
layer_type<下拉框三选一,选项包括max_pool, avg_pool, max_unpool > 默认值为max_pool
max_pool
torch.nn.functional.max_pool1d(input, kernel_size, stride=None, padding=0, dilation=1, ceil_mode=False, return_indices=False)
对由几个输入平面组成的输入信号进行最大池化。一般情况下我们只需要用到type, kernel_size, stride=None, padding=0这些参数。
参数:
- type:下拉框三选一,选项包括1d/2d/3d 默认值为2d
- kernel_size <正整数> : 卷积核的尺寸 默认值为2
- stride <正整数> : 卷积步长默认值为2
- padding <非负整数> : 补充0的层数 默认值为0
例子:
>>> # pool of square window of size=3, stride=2
>>> m = nn.MaxPool3d(3, stride=2)
>>> # pool of non-square window
>>> m = nn.MaxPool3d((3, 2, 2), stride=(2, 1, 2))
>>> input = torch.randn(20, 16, 50,44, 31)
>>> output = m(input)
avg_pool
torch.nn.functional.avg_pool1d(input, kernel_size, stride=None, padding=0, ceil_mode=False, count_include_pad=True)
对由几个输入平面组成的输入信号进行平均池化。一般情况下我们只需要用到type, kernel_size, stride=None, padding=0这些参数。
参数:
- type:下拉框三选一,选项包括1d/2d/3d 默认值为2d
- kernel_size<正整数> : 卷积核的尺寸 默认值为2
- stride<正整数> : 卷积步长 默认值为2
- padding <非负整数> : 补充0的层数 默认值为0
- ceil_mode:下拉框二选一,ceil/floor 默认值为floor
- count_include_pad(勾选框,默认为勾选,在json中为True,否则为False):平均计算中包括零填充 默认值为true
例子:
>>> # pool of square window of size=3, stride=2
>>> input = Variable(torch.Tensor([[[1,2,3,4,5,6,7]]]))
>>> F.avg_pool1d(input, kernel_size=3, stride=2)
Variable containing:
(0 ,.,.) =
2 4 6
[torch.FloatTensor of size 1x1x3]
max_unpool
torch.nn.MaxUnpool1d(kernel_size, stride=None, padding=0)
参数:
- type(下拉框三选一,选项包括1d/2d/3d) : 卷积形式 默认值为2d
- kernel_size <正整数> : 卷积核的尺寸 默认值为2
- stride<正整数> : 卷积步长 默认值为2
- padding<非负整数> : 补充0的层数 默认值为0
例子:
>>> pool = nn.MaxPool1d(2, stride=2, return_indices=True)
>>> unpool = nn.MaxUnpool1d(2, stride=2)
>>> input = torch.tensor([[[1., 2, 3, 4, 5, 6, 7, 8]]])
>>> output, indices = pool(input)
>>> unpool(output, indices)
tensor([[[ 0., 2., 0., 4., 0., 6., 0., 8.]]])
>>> # Example showcasing the use of output_size
>>> input = torch.tensor([[[1., 2, 3, 4, 5, 6, 7, 8, 9]]])
>>> output, indices = pool(input)
>>> unpool(output, indices, output_size=input.size())
tensor([[[ 0., 2., 0., 4., 0., 6., 0., 8., 0.]]])
>>> unpool(output, indices)
tensor([[[ 0., 2., 0., 4., 0., 6., 0., 8.]]])
4. 激活层(activation_layer)
激活函数作用在人工神经网络上,负责将神经元的输入映射到输出端。增加了神经网络的非线性,使得神经网络可以任意逼近任意非线性函数,从而使神经网络应用到众多的非线性模型中。
layer_type<下拉框,包括relu/sigmoid/tanh/leaky relu/PRelu/RRelu> 默认值为relu
relu
函数表达式:
(relu(x)=max(0,x))
对应图像:
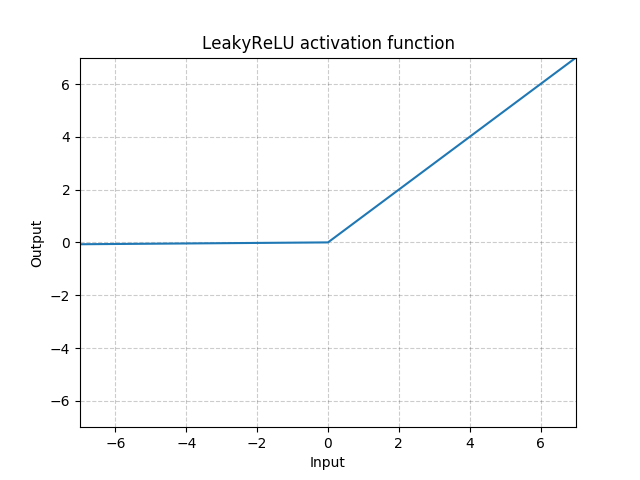
leaky relu
函数表达式:
(LeakyRelu(x)=max(x,0) + negative\_slope*min(0,x))
参数:
- negative_slope<正数> - 控制负斜率的角度 **默认值为0.01
对应图像:
sigmoid
函数表达式:
(sigmoid(x)=frac{1}{1+e^{-x}})
函数图像:

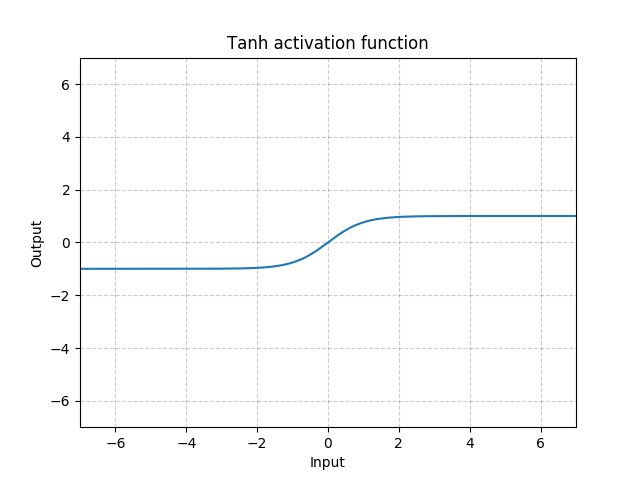
tanh
函数表达式:
(tanh(x)=frac{e^x-e^{-x}}{e^x+e^-x})
函数图像:
PRelu
torch.nn.PReLU(num_parameters=1, init=0.25)
函数表达式:PReLU(x)=max(0,x)+a∗min(0,x)
函数图像:
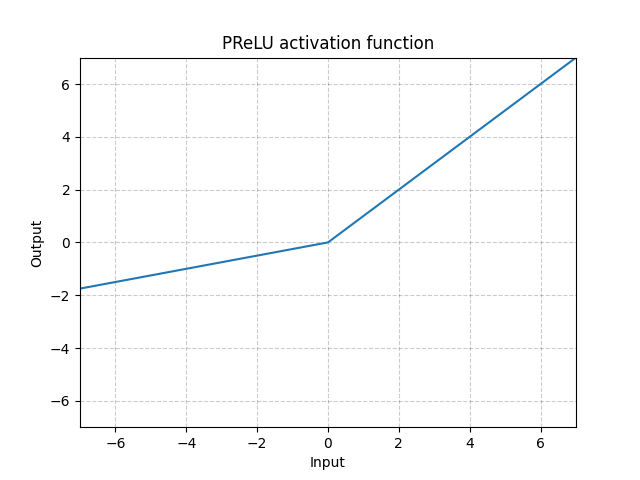
类似leaky relu, 但是负数部分斜率可学习
参数:
- weight<正数> - 权重初始化 非0正实数 默认值为0.25
RRelu
torch.nn.RReLU(lower=0.125, upper=0.3333333333333333, inplace=False)
函数表达式: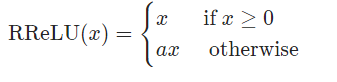
类似leaky relu, 但是负数部分斜率为随机均匀分布
参数:
- lower<正数> - 均匀分布下限 默认值为0.125
- upper<正数> - 均匀分布上限 默认值为0.333
5. 递归神经网络(RNN_layer)
torch.nn.RNN(*args, **kwargs)
RNN(Recurrent Neural Networks,循环神经网络)不仅会学习当前时刻的信息,也会依赖之前的序列信息。由于其特殊的网络模型结构解决了信息保存的问题。所以RNN对处理时间序列和语言文本序列问题有独特的优势。递归神经网络都具有一连串重复神经网络模块的形式。在标准的RNNs中,这种重复模块有一种非常简单的结构。
计算公式:
具体参数含义:ht是隐藏层在时间t时的状态,xt是时间t时的输入,h(t-1)是隐藏层在t-1时的状态。如果非线性激活函数为relu,那么tanh将用ReLU代替。
参数:
- input_size<正整数> - 输入特征数 无默认值
- hidden_size<正整数> - 隐藏层个数 无默认值
- num_layers<正整数> - 递归层层数 默认值为1
- nonlinearity<二选一,tanh/relu> - 非线性激活 默认为tanh
6. 长周期神经网络(LSTM_layer)
torch.nn.LSTM(*args, **kwargs)
Long Short Term Memory networks(以下简称LSTMs),一种特殊的RNN网络,该网络设计出来是为了解决长依赖问题。该网络由 [Hochreiter & Schmidhuber (1997)引入,并有许多人对其进行了改进和普及。他们的工作被用来解决了各种各样的问题,直到目前还被广泛应用。
LSTM的计算公式较为复杂,下图截取了pytorch官方文档中的部分内容:

参数:
- input_size<正整数> - 输入特征数 无默认值
- hidden_size<正整数> - 隐藏层个数 无默认值
- num_layers<正整数> - 递归层层数 默认值为1
7. 标准化层(norm_layer)
layer_type<下拉框,选项包括batch_norm/group_norm/instance_norm> 默认值为batch_norm
我们在对数据训练之前会对数据集进行归一化,归一化的目的归一化的目的就是使得预处理的数据被限定在一定的范围内(比如[0,1]或者[-1,1]),从而消除奇异样本数据导致的不良影响,同时便于加快训练速度。
batch_norm
torch.nn.BatchNorm1d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
计算公式:
参数:
- type<下拉框,包括1d/2d/3d> 默认值为2d
- num_features<正整数>:输入特征数 无默认值
例子:
>>> m = nn.BatchNorm1d(100)
>>> # Without Learnable Parameters
>>> m = nn.BatchNorm1d(100, affine=False)
>>> input = torch.randn(20, 100)
>>> output = m(input)
group_norm
torch.nn.GroupNorm(num_groups, num_channels, eps=1e-05, affine=True)
计算公式:
参数:
- num_groups<正整数> - input_channel分组数 无默认值
- num_channel<正整数> - input_channel个数无默认值
例子:
>>> # Separate 6 channels into 3 groups
>>> m = nn.GroupNorm(3, 6)
>>> # Separate 6 channels into 6 groups (equivalent with InstanceNorm)
>>> m = nn.GroupNorm(6, 6)
>>> # Put all 6 channels into a single group (equivalent with LayerNorm)
>>> m = nn.GroupNorm(1, 6)
>>> # Activating the module
>>> output = m(input)
instance_norm
torch.nn.InstanceNorm1d(num_features, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
计算公式:
参数:
- type<下拉框,包括1d/2d/3d> 默认值为2d
- num_features<正整数> - 输入特征数 无默认值
例子:
>>> # Without Learnable Parameters
>>> m = nn.InstanceNorm1d(100)
>>> # With Learnable Parameters
>>> m = nn.InstanceNorm1d(100, affine=True)
>>> input = torch.randn(20, 100, 40)
>>> output = m(input)
5. 参数
1. 简单参数
epoch<正整数> - 全数据集训练次数 默认值为10
当一个完整的数据集通过了神经网络一次并且返回了一次,这个过程称为一次>epoch。(也就是说,所有训练样本在神经网络中都 进行了一次正向传播 和一次反向传播 )
再通俗一点,一个Epoch就是将所有训练样本训练一次的过程。
learning_rate<0-1内实数> - 学习率 默认值为0.01
学习率(Learning rate)作为监督学习以及深度学习中重要的超参,其决定着目标函数能否收敛到局部最小值以及何时收敛到最小值。合适的学习率能够使目标函数在合适的时间内收敛到局部最小值。
batch_size<正整数> - 每次训练个数 默认值为1
当一个Epoch的样本(也就是所有的训练样本)数量可能太过庞大(对于计算机而言),就需要把它分成多个小块,也就是就是分成多个Batch 来进行训练。batch_size为每批样本的大小。
dataset<下拉框,共包含mnist,cifar10,stl10,svhn> - 训练数据集 默认值为mnist
mnist:该数据集包含60,000个用于训练的示例和10,000个用于测试的示例。这些数字已经过尺寸标准化并位于图像中心,图像是固定大小(28x28像素),其值为0到1。为简单起见,每个图像都被平展并转换为784(28 * 28)个特征的一维numpy数组。
下载链接:http://yann.lecun.com/exdb/mnist/
cifar10:该数据集共有60000张彩色图像,这些图像是32*32,分为10个类,每类6000张图。这里面有50000张用于训练,构成了5个训练批,每一批10000张图;另外10000用于测试,单独构成一批。测试批的数据里,取自10类中的每一类,每一类随机取1000张。抽剩下的就随机排列组成了训练批。注意一个训练批中的各类图像并不一定数量相同,总的来看训练批,每一类都有5000张图。
下载链接:http://www.cs.toronto.edu/~kriz/cifar-10-binary.tar.gz
stl10:STL-10 是一个图像数据集,包含 10 类物体的图片,每类 1300 张图片,500 张训练,800 张测试,每张图片分辨率为 96x96。除了具有类别标签的图片之外,还有 100000 张无类别信息的图片。
下载链接:https://cs.stanford.edu/~acoates/stl10/
svhn:SVHN(Street View House Number)Dateset 来源于谷歌街景门牌号码,原生的数据集1也就是官网的 Format 1 是一些原始的未经处理的彩色图片,如下图所示(不含有蓝色的边框),下载的数据集含有 PNG 的图像和 digitStruct.mat 的文件,其中包含了边框的位置信息,这个数据集每张图片上有好几个数字,适用于 OCR 相关方向。
下载链接:http://ufldl.stanford.edu/housenumbers/
ifshuffle<勾选框,默认为勾选,在json中为True,否则为False> - 是否打乱数据集 默认为true
platform<下拉框,共包含CPU,GPU> - 运行平台 默认CPU
2. 学习率下降(learning_rate_scheduler)
下拉框,共包括StepLR, MultiStepLR, ExponentialLR, CosineAnnealingLR,ReduceLROnPleateau,None 默认值为None
pytorch提供了几种根据epoch调整学习率的方法。
使用方法:learning_rate_scheduler应在优化器方向传播后进行应用,如下例所示:
>>> scheduler = ...
>>> for epoch in range(100):
>>> train(...)
>>> validate(...)
>>> scheduler.step()
stepLR
在每个step_size时期,通过gamma降低每个参数组的学习率。 这种衰减可能与此调度程序外部的学习速率的其他更改同时发生。 当last_epoch = -1时,将初始lr设置为lr。
- step_size<正整数> - 衰减周期 默认值为50
- gamma<0-1内实数> - 衰减幅度 默认值0.1
例子:
>>> # Assuming optimizer uses lr = 0.05 for all groups
>>> # lr = 0.05 if epoch < 30
>>> # lr = 0.005 if 30 <= epoch < 60
>>> # lr = 0.0005 if 60 <= epoch < 90
>>> # ...
>>> scheduler = StepLR(optimizer, step_size=30, gamma=0.1)
>>> for epoch in range(100):
>>> train(...)
>>> validate(...)
>>> scheduler.step()
MultiStepLR
当epoch到达milestone后,通过gamma衰减每个参数组的学习率。这种衰减可能与此调度程序外部的学习速率的其他更改同时发生。 当last_epoch = -1时,将初始lr设置为lr。
- milestones<非负整数序列,同维度数字之间以英文的“,”分开,例如1,2,3,4,5> - 衰减时间点 默认值为50
- gamma<0-1内实数> - 衰减幅度 默认值0.1
例子:
>>> # Assuming optimizer uses lr = 0.05 for all groups
>>> # lr = 0.05 if epoch < 30
>>> # lr = 0.005 if 30 <= epoch < 80
>>> # lr = 0.0005 if epoch >= 80
>>> scheduler = MultiStepLR(optimizer, milestones=[30,80], gamma=0.1)
>>> for epoch in range(100):
>>> train(...)
>>> validate(...)
>>> scheduler.step()
ExponentialLR
在每个epoch以gamma衰减每个参数组的学习率。 当last_epoch = -1时,将初始lr设置为lr。
- gamma<0-1内实数> - 衰减幅度 默认值为0.95
CosineAnnealingLR
此函数较为复杂,下图为pytorch文档中对其计算方法的相关说明:

- T_max<正整数> - 下降周期(变化的半周期)默认值为50
- eta_min<正数> - 最小学习率 默认值为0
ReduceLROnPleateau
当指标停止改善时,降低学习率。 一旦学习停滞,模型通常会受益于将学习率降低2-10倍。 该调度程序读取一个指标数量,如果在patience时期没有看到改善,则学习速度会降低。
- factor<0-1内实数> - 调整系数 默认值为0.1
- patience<正整数> -“耐心 ”,接受几次不变化 默认值为10
- cooldown<正整数> - “冷却时间”,停止监控一段时间 默认值为10
- verbose<勾选框> - 打印日志 默认勾选
- min_lr<0-1内实数> - 学习率下限 默认值为0.0001
例子:
>>> optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9)
>>> scheduler = ReduceLROnPlateau(optimizer, 'min')
>>> for epoch in range(10):
>>> train(...)
>>> val_loss = validate(...)
>>> # Note that step should be called after validate()
>>> scheduler.step(val_loss)
3. optimizer:优化器
下拉框,共包含SGD,RMSprop,Adam,Adamax,ASGD 默认值为Adam
优化器是用来计算和更新影响模型训练和输出的网络参数(w和b),从而最小化(或最大化)损失函数Loss。
优化器是求解最优解的过程,可以变相理解为求损失函数极值的问题,因变量为Loss,自变量(优化变量)为w和b,因此需要用到一阶导数(梯度),极值处其方程梯度(一阶导数)为零。有些时候会对优化变量进行约束,包括等式约束和不等式约束,定义了优化变量的可行域,如L1正则化和L2正则化。
SGD
Stochastic Gradient Descent
实现随机梯度下降(可选带动量)。
- momentum <0-1间实数> - 动量 默认值为0
- weight_decay <0-1间实数> - L2正则项系数 默认值为0
- dampening <正数> – 动量衰减 默认值为0
- nesterov (勾选框,默认为勾选,在json中为True,否则为False) – 使用Nesterov梯度加速 默认值为false
例子:
>>> optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9)
>>> optimizer.zero_grad()
>>> loss_fn(model(input), target).backward()
>>> optimizer.step()
ASGD
Averaged Stochastic Gradient Descent
实现平均随机梯度下降。
- lambd <0-1间实数> - 衰减项 默认值为0.0001
- alpha <0-1间实数> - eta更新幂 默认值为0.75
- t0 <正整数> – 开始平均的点 默认值为1000000
- weight_decay<0-1间实数> - L2正则项系数 默认值为0
Adam
实现Adam算法进行梯度下降。
Adam算法介绍:https://arxiv.org/abs/1412.6980
- beta1<0-1内实数> - 梯度移动平均值的系数 默认值为0.9
- beta2<0-1内实数> - 梯度平方移动平均值的系数 默认值为0.999
- eps <0-1内实数>- 分母稳定项 默认值为0.00000001
- weight_decay<0-1间实数> - L2正则项系数 默认值为0
- amsgrad(勾选框,默认为勾选,在json中为True,否则为False) - 使用AMSGrad变体 默认值为false
RMSprop
实现RMSprop 算法进行梯度下降。
RMSprop 算法介绍:https://arxiv.org/pdf/1308.0850v5.pdf
- momentum<0-1间实数>- 动量 默认值为0
- alpha<0-1间实数> - 平滑常数 默认值为0.99
- eps<0-1内实数> - 分母稳定项 默认值为0.00000001
- centered (勾选框,默认为勾选,在json中为True,否则为False)– 梯度通过方差归一化 默认值为flase
- weight_decay<0-1间实数> - L2正则项系数 默认值为0
Adammax
实现Adamax算法(基于无穷范数的Adam的变体)。
Adamax算法介绍:https://arxiv.org/abs/1412.6980
- beta1<0-1内实数>- 梯度移动平均值的系数 默认值为0.9
- beta2<0-1内实数>- 梯度平方移动平均值的系数 默认值为0.999
- eps<0-1内实数>- 分母稳定项 默认值为0.00000001
- weight_decay<0-1间实数> - L2正则项系数 默认值为0
4. loss_func:损失函数
下拉框,共包含MSELoss,CrossEntropyLoss,L1Loss,NLLLoss,BCELoss 默认值为MSELoss
损失函数(loss function)是用来估量你模型的预测值f(x)与真实值Y的不一致程度,它是一个非负实值函数,通常使用L(Y, f(x))来表示,损失函数越小,模型的鲁棒性就越好。
MSELoss
均方误差
pytorch文档中计算函数:

- reduction (下拉框,共包含none,mean,sum)- 输出的缩减 默认值为mean
例子:
>>> loss = nn.MSELoss()
>>> input = torch.randn(3, 5, requires_grad=True)
>>> target = torch.randn(3, 5)
>>> output = loss(input, target)
>>> output.backward()
CrossEntropyLoss
交叉熵损失
pytorch文档中计算函数:

- weight (optional, <正数序列>)- 每个分类损失的权重 默认值为None
- ignore_index (optional, <整数>)- 忽略的目标 默认值为None
- reduction (下拉框,共包含none,mean,sum)- 输出的缩减 默认值为mean
例子:
>>> loss = nn.CrossEntropyLoss()
>>> input = torch.randn(3, 5, requires_grad=True)
>>> target = torch.empty(3, dtype=torch.long).random_(5)
>>> output = loss(input, target)
>>> output.backward()
L1Loss
mean absolute error(MAE)
pytorch文档中计算函数:

- reduction (下拉框,共包含none,mean,sum)- 输出的缩减 默认值为mean
例子:
>>> loss = nn.L1Loss()
>>> input = torch.randn(3, 5, requires_grad=True)
>>> target = torch.randn(3, 5)
>>> output = loss(input, target)
>>> output.backward()
NLLLoss
negative log likelihood loss
pytorch文档中计算函数:

- weight (optional, <正数序列>)- 每个分类损失的权重 默认值为None
- ignore_index (optional, <整数>)- 忽略的目标 默认值为None
- reduction (下拉框,共包含none,mean,sum)- 输出的缩减 默认值为mean
例子:
>>> m = nn.LogSoftmax(dim=1)
>>> loss = nn.NLLLoss()
>>> # input is of size N x C = 3 x 5
>>> input = torch.randn(3, 5, requires_grad=True)
>>> # each element in target has to have 0 <= value < C
>>> target = torch.tensor([1, 0, 4])
>>> output = loss(m(input), target)
>>> output.backward()
>>>
>>>
>>> # 2D loss example (used, for example, with image inputs)
>>> N, C = 5, 4
>>> loss = nn.NLLLoss()
>>> # input is of size N x C x height x width
>>> data = torch.randn(N, 16, 10, 10)
>>> conv = nn.Conv2d(16, C, (3, 3))
>>> m = nn.LogSoftmax(dim=1)
>>> # each element in target has to have 0 <= value < C
>>> target = torch.empty(N, 8, 8, dtype=torch.long).random_(0, C)
>>> output = loss(m(conv(data)), target)
>>> output.backward()
BCELoss
Binary Cross Entropy between the target and the output
pytorch文档计算函数:

- weight (optional, <正数序列>)- 每批损失的权重 默认值为None
- reduction (下拉框,共包含none,mean,sum)- 输出的缩减 默认值为mean
例子:
>>> m = nn.Sigmoid()
>>> loss = nn.BCELoss()
>>> input = torch.randn(3, requires_grad=True)
>>> target = torch.empty(3).random_(2)
>>> output = loss(m(input), target)
>>> output.backward()
5.图像处理
图像预处理,是将每一个文字图像分检出来交给识别模块识别,这一过程称为图像预处理。在图像分析中,对输入图像进行特征抽取、分割和匹配前所进行的处理。
图像预处理的主要目的是消除图像中无关的信息,恢复有用的真实信息,增强有关信息的可检测性和最大限度地简化数据,从而改进特征抽取、图像分割、匹配和识别的可靠性。
pytorch提供了大量可用于图像处理的函数以及工具,本项目选择了其中的3项比较实用的功能,包括颜色变换(ColorJitter),边界填充(Pad)和随机切割RandomCrop(随机切割)。
ColorJitter
随机改变图像亮度、对比度和饱和度
brightness(非负浮点数):亮度值变化程度,最后生成图像的亮度值在[max(0, 1 - brightness), 1 + brightness]区间中随机选取,brightness默认值为0
contrast(非负浮点数):对比度变化程度,最后生成图像的亮度值在[max(0, 1 - contrast), 1 + contrast]区间中随机选取,contrast默认值为0
saturation(非负浮点数):饱和度变化程度,最后生成图像的亮度值在[max(0, 1 - saturation), 1 + saturation]区间中随机选取,saturation默认值为0
hue(非负浮点数且在0-0.5之间):色调值变化程度,最后生成图像的色调值在 [-hue, hue]区间中随机选取,hue默认值为0
pytorch中提供的实现函数:
torchvision.transforms.ColorJitter(brightness=0, contrast=0, saturation=0, hue=0)
Pad
通过给定的'pad'值对图像边界进行填充
padding(正整数):表示对于图片那几个位置进行填充,输入数据的个数表示填充的边数。如果输入的元组有2个元素则表示对于图像的左右边界进行填充,如果输入4个元素则表示对于上下左右四个边界进行填充
padding_mode :二选一,constant/edge ,constant表示通过padding中输入的给定值对于图像进行填充,而edge则使用图像最后一行的像素值对于图像进行填充,默认值为constant
pytorch中提供的实现函数:
torchvision.transforms.Pad(padding, padding_mode='constant')
RandomCrop
随机选取图像中的位置进行切割
size(正整数):表示输出图片的大小,最终生成图片大小为size*size
padding(正整数):表示对于图片那几个位置进行填充,输入数据的个数表示填充的边数。如果输入的元组有2个元素则表示对于图像的左右边界进行填充,如果输入4个元素则表示对于上下左右四个边界进行填充
pad_if_needed (True/False) :表示如果图片小于所需要的大小是否进行填充 ,实际操作时切割往往会导致图片变小从而导致程序报错,因此为了避免错误出现往往需要对切割掉的部分进行填充,默认值为True
padding_mode:二选一,constant/edge ,constant表示通过padding中输入的给定值对于图像进行填充,而edge则使用图像最后一行的像素值对于图像进行填充,默认值为constant
pytorch中提供的实现函数:
torchvision.transforms.RandomCrop(size, padding=None, pad_if_needed=False, padding_mode='constant')
说明
本教程部分参考了PyTorch中文手册和PyTorch官方文档,如果想要更详细深入了解的请访问该手册和文档。
若觉得官方文档较难读懂,先看以下个人博客: